फिशर मानदंडआपको दो स्वतंत्र नमूनों के नमूना भिन्नताओं की तुलना करने की अनुमति देता है। एफ एम्प की गणना करने के लिए, आपको दो नमूनों के प्रसरणों का अनुपात ज्ञात करना होगा, ताकि बड़ा प्रसरण अंश में हो, और छोटा विचरण हर में हो। फिशर मानदंड की गणना का सूत्र है:
क्रमशः पहले और दूसरे नमूनों की भिन्नताएँ कहाँ हैं।
चूँकि, मानदंड की स्थिति के अनुसार, अंश का मान हर के मान से अधिक या उसके बराबर होना चाहिए, F emp का मान हमेशा एक से अधिक या उसके बराबर होगा।
स्वतंत्रता की कोटि की संख्या भी सरलता से निर्धारित की जाती है:
के 1 =एन एल - 1 पहले नमूने के लिए (अर्थात उस नमूने के लिए जिसका विचरण बड़ा है) और के 2 = एन 2 - 1 दूसरे नमूने के लिए.
परिशिष्ट 1 में, फिशर मानदंड के महत्वपूर्ण मान k 1 (तालिका की शीर्ष पंक्ति) और k 2 (तालिका के बाएँ स्तंभ) के मानों द्वारा पाए जाते हैं।
यदि वह आलोचना करता है, तो शून्य परिकल्पना स्वीकार कर ली जाती है, अन्यथा विकल्प स्वीकार कर लिया जाता है।
उदाहरण 3.परीक्षण दो तीसरी कक्षाओं में किया गया मानसिक विकास TURMSH परीक्षा में दस छात्र। प्राप्त औसत मूल्य महत्वपूर्ण रूप से भिन्न नहीं थे, लेकिन मनोवैज्ञानिक इस सवाल में रुचि रखते हैं कि क्या कक्षाओं के बीच मानसिक विकास संकेतकों की एकरूपता की डिग्री में अंतर हैं।
समाधान। फिशर परीक्षण के लिए, दोनों वर्गों में परीक्षण अंकों के भिन्नता की तुलना करना आवश्यक है। परीक्षण के परिणाम तालिका में प्रस्तुत किए गए हैं:
टेबल तीन।
|
छात्र संख्या |
प्रथम श्रेणी |
द्वितीय श्रेणी |
चर X और Y के प्रसरणों की गणना करने पर, हम प्राप्त करते हैं:
एस एक्स 2 =572.83; एस य 2 =174,04
फिर, फिशर के एफ मानदंड का उपयोग करके गणना के लिए सूत्र (8) का उपयोग करते हुए, हम पाते हैं:
![]()
एफ मानदंड के लिए परिशिष्ट 1 की तालिका के अनुसार दोनों मामलों में स्वतंत्रता की डिग्री के = 10 - 1 = 9 के बराबर है, हम एफ क्रिट = 3.18 पाते हैं (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 गैरपैरामीट्रिक परीक्षण
किसी भी प्रभाव से पहले और बाद के परिणामों की आंखों से (प्रतिशत के आधार पर) तुलना करके, शोधकर्ता इस निष्कर्ष पर पहुंचता है कि यदि अंतर देखा जाता है, तो तुलना किए जा रहे नमूनों में भी अंतर है। यह दृष्टिकोण स्पष्ट रूप से अस्वीकार्य है, क्योंकि प्रतिशत के लिए मतभेदों में विश्वसनीयता के स्तर को निर्धारित करना असंभव है। स्वयं द्वारा लिए गए प्रतिशत सांख्यिकीय रूप से विश्वसनीय निष्कर्ष निकालना संभव नहीं बनाते हैं। किसी भी हस्तक्षेप की प्रभावशीलता को साबित करने के लिए, संकेतकों के पूर्वाग्रह (बदलाव) में सांख्यिकीय रूप से महत्वपूर्ण प्रवृत्ति की पहचान करना आवश्यक है। ऐसी समस्याओं को हल करने के लिए, एक शोधकर्ता कई भेदभाव मानदंडों का उपयोग कर सकता है। नीचे हम गैर-पैरामीट्रिक परीक्षणों पर विचार करेंगे: साइन टेस्ट और ची-स्क्वायर टेस्ट।
समग्र रूप से एकाधिक प्रतिगमन समीकरण के महत्व के साथ-साथ युग्मित प्रतिगमन में, फिशर मानदंड का उपयोग करके मूल्यांकन किया जाता है:
 ,
(2.22)
,
(2.22)
कहाँ  - स्वतंत्रता की प्रति डिग्री वर्गों का कारक योग;
- स्वतंत्रता की प्रति डिग्री वर्गों का कारक योग;  - स्वतंत्रता की प्रति डिग्री वर्गों का अवशिष्ट योग;
- स्वतंत्रता की प्रति डिग्री वर्गों का अवशिष्ट योग;  - एकाधिक निर्धारण का गुणांक (सूचकांक);
- एकाधिक निर्धारण का गुणांक (सूचकांक);  - चर के लिए मापदंडों की संख्या
- चर के लिए मापदंडों की संख्या  (रैखिक प्रतिगमन में यह मॉडल में शामिल कारकों की संख्या से मेल खाता है);
(रैखिक प्रतिगमन में यह मॉडल में शामिल कारकों की संख्या से मेल खाता है);  – अवलोकनों की संख्या.
– अवलोकनों की संख्या.
न केवल संपूर्ण समीकरण के महत्व का आकलन किया जाता है, बल्कि प्रतिगमन मॉडल में अतिरिक्त रूप से शामिल कारक का भी आकलन किया जाता है। इस तरह के मूल्यांकन की आवश्यकता इस तथ्य के कारण है कि मॉडल में शामिल प्रत्येक कारक परिणामी विशेषता में स्पष्ट भिन्नता के हिस्से को महत्वपूर्ण रूप से नहीं बढ़ा सकता है। इसके अलावा, यदि मॉडल में कई कारक हैं, तो उन्हें विभिन्न अनुक्रमों में मॉडल में दर्ज किया जा सकता है। कारकों के बीच सहसंबंध के कारण, मॉडल में इसके परिचय के अनुक्रम के आधार पर एक ही कारक का महत्व भिन्न हो सकता है। मॉडल में किसी कारक को शामिल करने का आकलन करने का उपाय निजी है  -मानदंड, यानी
-मानदंड, यानी  .
.
निजी  -मानदंड समग्र रूप से प्रतिगमन मॉडल के लिए स्वतंत्रता की एक डिग्री के अवशिष्ट फैलाव के साथ अतिरिक्त शामिल कारक के प्रभाव के कारण कारक फैलाव में वृद्धि की तुलना करने पर आधारित है। कारक के लिए सामान्य शब्दों में
-मानदंड समग्र रूप से प्रतिगमन मॉडल के लिए स्वतंत्रता की एक डिग्री के अवशिष्ट फैलाव के साथ अतिरिक्त शामिल कारक के प्रभाव के कारण कारक फैलाव में वृद्धि की तुलना करने पर आधारित है। कारक के लिए सामान्य शब्दों में  निजी
निजी  -मानदंड इस प्रकार निर्धारित किया जाएगा
-मानदंड इस प्रकार निर्धारित किया जाएगा
 ,
(2.23)
,
(2.23)
कहाँ  - कारकों के पूरे सेट वाले मॉडल के लिए एकाधिक निर्धारण का गुणांक,
- कारकों के पूरे सेट वाले मॉडल के लिए एकाधिक निर्धारण का गुणांक,  - वही संकेतक, लेकिन मॉडल में कारक को शामिल किए बिना
- वही संकेतक, लेकिन मॉडल में कारक को शामिल किए बिना  ,
, – अवलोकनों की संख्या,
– अवलोकनों की संख्या,  - मॉडल में मापदंडों की संख्या (मुक्त अवधि के बिना)।
- मॉडल में मापदंडों की संख्या (मुक्त अवधि के बिना)।
भागफल का वास्तविक मान  - महत्व के स्तर पर मानदंड की तुलना तालिका से की जाती है
- महत्व के स्तर पर मानदंड की तुलना तालिका से की जाती है  और स्वतंत्रता की डिग्री की संख्या: 1 और
और स्वतंत्रता की डिग्री की संख्या: 1 और  . यदि वास्तविक मूल्य
. यदि वास्तविक मूल्य  से अधिक है
से अधिक है  , फिर कारक का अतिरिक्त समावेशन
, फिर कारक का अतिरिक्त समावेशन  मॉडल में सांख्यिकीय रूप से उचित और शुद्ध प्रतिगमन गुणांक है
मॉडल में सांख्यिकीय रूप से उचित और शुद्ध प्रतिगमन गुणांक है  कारक पर
कारक पर  आंकड़ों की दृष्टि से महत्वपूर्ण। यदि वास्तविक मूल्य
आंकड़ों की दृष्टि से महत्वपूर्ण। यदि वास्तविक मूल्य  तालिका मान से कम है, तो मॉडल में कारक का अतिरिक्त समावेश
तालिका मान से कम है, तो मॉडल में कारक का अतिरिक्त समावेश  किसी विशेषता में स्पष्ट भिन्नता के अनुपात में उल्लेखनीय वृद्धि नहीं होती है
किसी विशेषता में स्पष्ट भिन्नता के अनुपात में उल्लेखनीय वृद्धि नहीं होती है  अत: इसे मॉडल में शामिल करना अनुचित है; इस मामले में इस कारक के लिए प्रतिगमन गुणांक सांख्यिकीय रूप से महत्वहीन है।
अत: इसे मॉडल में शामिल करना अनुचित है; इस मामले में इस कारक के लिए प्रतिगमन गुणांक सांख्यिकीय रूप से महत्वहीन है।
दो-कारक समीकरण के लिए, भागफल  -मानदंड का रूप है:
-मानदंड का रूप है:
 ,
, . (2.23ए)
. (2.23ए)
निजी का उपयोग करना  -मानदंड, कोई भी इस धारणा के तहत सभी प्रतिगमन गुणांक के महत्व की जांच कर सकता है कि प्रत्येक संबंधित कारक
-मानदंड, कोई भी इस धारणा के तहत सभी प्रतिगमन गुणांक के महत्व की जांच कर सकता है कि प्रत्येक संबंधित कारक  अंतिम बार एकाधिक प्रतिगमन समीकरण में प्रवेश किया गया।
अंतिम बार एकाधिक प्रतिगमन समीकरण में प्रवेश किया गया।
एकाधिक प्रतिगमन समीकरण के लिए छात्र परीक्षण।
निजी  -मानदंड शुद्ध प्रतिगमन गुणांक के महत्व का मूल्यांकन करता है। परिमाण जानना
-मानदंड शुद्ध प्रतिगमन गुणांक के महत्व का मूल्यांकन करता है। परिमाण जानना  , यह निर्धारित करना संभव है
, यह निर्धारित करना संभव है  -प्रतिगमन गुणांक के लिए मानदंड
-प्रतिगमन गुणांक के लिए मानदंड  -एम कारक,
-एम कारक,  , अर्थात्:
, अर्थात्:
 .
(2.24)
.
(2.24)
शुद्ध प्रतिगमन गुणांक के महत्व का आकलन करना  -छात्र का टी-टेस्ट आंशिक गणना के बिना किया जा सकता है
-छात्र का टी-टेस्ट आंशिक गणना के बिना किया जा सकता है  -मानदंड। इस मामले में, जोड़ीवार प्रतिगमन की तरह, प्रत्येक कारक के लिए सूत्र का उपयोग किया जाता है:
-मानदंड। इस मामले में, जोड़ीवार प्रतिगमन की तरह, प्रत्येक कारक के लिए सूत्र का उपयोग किया जाता है:
 ,
(2.25)
,
(2.25)
कहाँ  - कारक पर शुद्ध प्रतिगमन गुणांक
- कारक पर शुद्ध प्रतिगमन गुणांक  ,
, - प्रतिगमन गुणांक का माध्य वर्ग (मानक) त्रुटि
- प्रतिगमन गुणांक का माध्य वर्ग (मानक) त्रुटि  .
.
एकाधिक प्रतिगमन समीकरण के लिए, प्रतिगमन गुणांक की माध्य वर्ग त्रुटि निम्नलिखित सूत्र द्वारा निर्धारित की जा सकती है:
 ,
(2.26)
,
(2.26)
कहाँ 
 ,
, - विशेषता के लिए मानक विचलन
- विशेषता के लिए मानक विचलन  ,
, - एकाधिक प्रतिगमन समीकरण के लिए निर्धारण का गुणांक,
- एकाधिक प्रतिगमन समीकरण के लिए निर्धारण का गुणांक,  – कारक की निर्भरता के निर्धारण का गुणांक
– कारक की निर्भरता के निर्धारण का गुणांक  एकाधिक प्रतिगमन समीकरण में अन्य सभी कारकों के साथ;
एकाधिक प्रतिगमन समीकरण में अन्य सभी कारकों के साथ;  - वर्ग विचलन के अवशिष्ट योग के लिए स्वतंत्रता की डिग्री की संख्या।
- वर्ग विचलन के अवशिष्ट योग के लिए स्वतंत्रता की डिग्री की संख्या।
जैसा कि आप देख सकते हैं, इस सूत्र का उपयोग करने के लिए, आपको एक इंटरफैक्टर सहसंबंध मैट्रिक्स और इसका उपयोग करके निर्धारण के संबंधित गुणांक की गणना की आवश्यकता है  . तो, समीकरण के लिए
. तो, समीकरण के लिए  प्रतिगमन गुणांक के महत्व का आकलन
प्रतिगमन गुणांक के महत्व का आकलन  ,
, ,
, इसमें तीन इंटरफैक्टर निर्धारण गुणांक की गणना शामिल है:
इसमें तीन इंटरफैक्टर निर्धारण गुणांक की गणना शामिल है:  ,
, ,
, .
.
आंशिक सहसंबंध गुणांक के संकेतकों के बीच संबंध, आंशिक  -मानदंड और
-मानदंड और  -शुद्ध प्रतिगमन गुणांक के लिए छात्र के टी-टेस्ट का उपयोग कारक चयन प्रक्रिया में किया जा सकता है। उन्मूलन विधि द्वारा प्रतिगमन समीकरण का निर्माण करते समय कारकों का उन्मूलन व्यावहारिक रूप से न केवल आंशिक सहसंबंध गुणांक द्वारा किया जा सकता है, प्रत्येक चरण में आंशिक सहसंबंध गुणांक के सबसे छोटे महत्वहीन मूल्य वाले कारक को छोड़कर, बल्कि मूल्यों द्वारा भी
-शुद्ध प्रतिगमन गुणांक के लिए छात्र के टी-टेस्ट का उपयोग कारक चयन प्रक्रिया में किया जा सकता है। उन्मूलन विधि द्वारा प्रतिगमन समीकरण का निर्माण करते समय कारकों का उन्मूलन व्यावहारिक रूप से न केवल आंशिक सहसंबंध गुणांक द्वारा किया जा सकता है, प्रत्येक चरण में आंशिक सहसंबंध गुणांक के सबसे छोटे महत्वहीन मूल्य वाले कारक को छोड़कर, बल्कि मूल्यों द्वारा भी  और
और  .
निजी
.
निजी  -चरों को शामिल करने की विधि और चरणबद्ध प्रतिगमन विधि का उपयोग करके मॉडल का निर्माण करते समय मानदंड का व्यापक रूप से उपयोग किया जाता है।
-चरों को शामिल करने की विधि और चरणबद्ध प्रतिगमन विधि का उपयोग करके मॉडल का निर्माण करते समय मानदंड का व्यापक रूप से उपयोग किया जाता है।
मानदंड की गणना φ*
1. विशेषता के उन मूल्यों को निर्धारित करें जो विषयों को "प्रभाव डालने वाले" और "प्रभाव नहीं डालने वाले" में विभाजित करने का मानदंड होंगे। यदि विशेषता को मात्रात्मक रूप से मापा जाता है, तो इष्टतम पृथक्करण बिंदु खोजने के लिए λ मानदंड का उपयोग करें।
2. दो स्तंभों और दो पंक्तियों की एक चार-कोशिका (समानार्थी: चार-फ़ील्ड) तालिका बनाएं। पहला कॉलम है "प्रभाव है"; दूसरा कॉलम - "कोई प्रभाव नहीं"; ऊपर से पहली पंक्ति - 1 समूह (नमूना); दूसरी पंक्ति - समूह 2 (नमूना)।
4. पहले नमूने में उन विषयों की संख्या गिनें जिनका "कोई प्रभाव नहीं" है और इस संख्या को तालिका के ऊपरी दाएँ कक्ष में दर्ज करें। शीर्ष दो कोशिकाओं के योग की गणना करें। इसे पहले समूह में विषयों की संख्या के साथ मेल खाना चाहिए।
6. दूसरे नमूने में उन विषयों की संख्या गिनें जिनका "कोई प्रभाव नहीं" है और इस संख्या को तालिका के निचले दाएं कक्ष में दर्ज करें। दो निचली कोशिकाओं के योग की गणना करें। इसे दूसरे समूह (नमूना) में विषयों की संख्या से मेल खाना चाहिए।
7. किसी दिए गए समूह (नमूना) में विषयों की कुल संख्या के साथ उनकी संख्या को जोड़कर "प्रभाव डालने वाले" विषयों का प्रतिशत निर्धारित करें। परिणामी प्रतिशतों को क्रमशः तालिका के ऊपरी बाएँ और निचले बाएँ कक्षों में कोष्ठकों में लिखें, ताकि उन्हें निरपेक्ष मानों के साथ भ्रमित न किया जाए।
8. यह देखने के लिए जांचें कि क्या तुलना किए जा रहे प्रतिशतों में से एक शून्य के बराबर है। यदि यह मामला है, तो समूह पृथक्करण बिंदु को एक दिशा या दूसरी दिशा में ले जाकर इसे बदलने का प्रयास करें। यदि यह असंभव या अवांछनीय है, तो φ* मानदंड को त्यागें और χ2 मानदंड का उपयोग करें।
9. तालिका के अनुसार निर्धारित करें। प्रत्येक तुलनात्मक प्रतिशत के लिए XII परिशिष्ट 1 कोण φ।
कहा पे: φ1 - बड़े प्रतिशत के अनुरूप कोण;
φ2 - छोटे प्रतिशत के अनुरूप कोण;
एन1 - नमूना 1 में अवलोकनों की संख्या;
एन2 - नमूना 2 में अवलोकनों की संख्या।
11. प्राप्त मूल्य φ* की तुलना महत्वपूर्ण मूल्यों से करें: φ* ≤1.64 (p<0,05) и φ* ≤2,31 (р<0,01).
यदि φ*emp ≤φ*cr. H0 अस्वीकार कर दिया गया है.
यदि आवश्यक हो, तो तालिका के अनुसार परिणामी φ*emp के महत्व का सटीक स्तर निर्धारित करें। XIII परिशिष्ट 1.
इस विधि का वर्णन कई मैनुअल में किया गया है (प्लोखिंस्की एन.ए., 1970; गबलर ई.वी., 1978; इवांटर ई.वी., कोरोसोव ए.वी., 1992, आदि) यह विवरण उस विधि के संस्करण पर आधारित है जिसे ई.वी. द्वारा विकसित और प्रस्तुत किया गया था। गब्लर.
मानदंड का उद्देश्य φ*
फिशर का मानदंड शोधकर्ता की रुचि के प्रभाव (संकेतक) की घटना की आवृत्ति के अनुसार दो नमूनों की तुलना करने के लिए डिज़ाइन किया गया है। यह जितना बड़ा होगा, अंतर उतना ही अधिक विश्वसनीय होगा।
कसौटी का वर्णन
मानदंड दो नमूनों के उन प्रतिशतों के बीच अंतर की विश्वसनीयता का मूल्यांकन करता है जिसमें हमारे लिए रुचि का प्रभाव (संकेतक) दर्ज किया गया था। लाक्षणिक रूप से बोलते हुए, हम 2 पाई से काटे गए 2 सर्वोत्तम टुकड़ों की तुलना करते हैं और निर्णय लेते हैं कि कौन सा वास्तव में बड़ा है।
फिशर कोणीय परिवर्तन का सार प्रतिशत को केंद्रीय कोण मानों में परिवर्तित करना है, जिन्हें रेडियन में मापा जाता है। एक बड़ा प्रतिशत एक बड़े कोण φ के अनुरूप होगा, और एक छोटा प्रतिशत एक छोटे कोण के अनुरूप होगा, लेकिन यहां संबंध रैखिक नहीं हैं:
जहां P एक इकाई के अंशों में व्यक्त प्रतिशत है (चित्र 5.1 देखें)।
कोणों के बीच बढ़ती विसंगति के साथ φ 1 और φ 2 और नमूनों की संख्या बढ़ने से मानदंड का मूल्य बढ़ जाता है। φ* का मान जितना बड़ा होगा, अंतर महत्वपूर्ण होने की संभावना उतनी ही अधिक होगी।
परिकल्पना
एच 0 : व्यक्तियों का अनुपात, जिसमें अध्ययन किया गया प्रभाव स्वयं प्रकट होता है, नमूना 2 की तुलना में नमूना 1 में और कुछ नहीं हैं।
एच 1 : अध्ययन किए गए प्रभाव को प्रदर्शित करने वाले व्यक्तियों का अनुपात नमूना 2 की तुलना में नमूना 1 में अधिक है।
मानदंड का चित्रमय प्रतिनिधित्व φ*
कोणीय परिवर्तन विधि अन्य मानदंडों की तुलना में कुछ हद तक अधिक सारगर्भित है।
φ के मानों की गणना करते समय ई.वी. गुबलर द्वारा अपनाया गया सूत्र मानता है कि 100% एक कोण बनाता है φ=3.142, यानी एक गोल मान π=3.14159... यह हमें तुलना किए गए नमूनों को इस रूप में प्रस्तुत करने की अनुमति देता है दो अर्धवृत्त, जिनमें से प्रत्येक अपने नमूने की 100% जनसंख्या का प्रतीक है। "प्रभाव" वाले विषयों के प्रतिशत को केंद्रीय कोण φ द्वारा गठित क्षेत्रों के रूप में दर्शाया जाएगा। चित्र में. चित्र 5.2 उदाहरण 1 को दर्शाने वाले दो अर्धवृत्त दिखाता है। पहले नमूने में, 60% विषयों ने समस्या का समाधान किया। यह प्रतिशत कोण φ=1.772 से मेल खाता है। दूसरे नमूने में, 40% विषयों ने समस्या हल कर दी। यह प्रतिशत कोण φ =1.369 से मेल खाता है।
φ* मानदंड आपको यह निर्धारित करने की अनुमति देता है कि दिए गए नमूना आकारों के लिए कोणों में से एक वास्तव में दूसरे से सांख्यिकीय रूप से काफी बेहतर है या नहीं।
मानदंड की सीमाएँ φ*
1. तुलना किया जा रहा कोई भी अनुपात शून्य नहीं होना चाहिए। औपचारिक रूप से, उन मामलों में φ विधि का उपयोग करने में कोई बाधा नहीं है जहां नमूनों में से किसी एक में अवलोकनों का अनुपात 0 के बराबर है। हालांकि, इन मामलों में, परिणाम अनुचित रूप से बढ़ा हुआ हो सकता है (गुबलर ई.वी., 1978, पी) .86).
2. ऊपरी φ मानदंड में कोई सीमा नहीं है - नमूने इच्छानुसार बड़े हो सकते हैं।
निचला सीमा - एक नमूने में 2 अवलोकन। हालाँकि, दो नमूनों की संख्या में निम्नलिखित अनुपात अवश्य देखा जाना चाहिए:
ए) यदि एक नमूने में केवल 2 अवलोकन हैं, तो दूसरे में कम से कम 30 होने चाहिए:
बी) यदि नमूनों में से एक में केवल 3 अवलोकन हैं, तो दूसरे में कम से कम 7 होने चाहिए:
ग) यदि एक नमूने में केवल 4 अवलोकन हैं, तो दूसरे में कम से कम 5 होने चाहिए:
घ)परएन 1 , एन 2 ≥ 5 कोई भी तुलना संभव है.
सिद्धांत रूप में, उन नमूनों की तुलना करना भी संभव है जो इस शर्त को पूरा नहीं करते हैं, उदाहरण के लिए, संबंध के साथएन 1 =2, एन 2 = 15, लेकिन इन मामलों में महत्वपूर्ण अंतर की पहचान करना संभव नहीं होगा।
φ* मानदंड पर कोई अन्य प्रतिबंध नहीं है।
आइए संभावनाओं को स्पष्ट करने के लिए कुछ उदाहरण देखेंमानदंड φ*.
उदाहरण 1: गुणात्मक रूप से परिभाषित विशेषता के अनुसार नमूनों की तुलना।
उदाहरण 2: मात्रात्मक रूप से मापी गई विशेषता के अनुसार नमूनों की तुलना।
उदाहरण 3: किसी विशेषता के स्तर और वितरण दोनों के आधार पर नमूनों की तुलना।
उदाहरण 4: मानदंड के साथ संयोजन में φ* मानदंड का उपयोग करनाएक्स सबसे सटीक परिणाम प्राप्त करने के लिए कोलमोगोरोव-स्मिरनोव।
उदाहरण 1 - गुणात्मक रूप से निर्धारित विशेषता के अनुसार नमूनों की तुलना
मानदंड के इस उपयोग में, हम एक नमूने में कुछ गुणवत्ता वाले विषयों के प्रतिशत की तुलना उसी गुणवत्ता वाले दूसरे नमूने में विषयों के प्रतिशत से करते हैं।
मान लीजिए कि हम इस बात में रुचि रखते हैं कि क्या छात्रों के दो समूह एक नई प्रयोगात्मक समस्या को हल करने में उनकी सफलता में भिन्न हैं। 20 लोगों के पहले समूह में, 12 लोगों ने इसका सामना किया, और 25 लोगों के दूसरे नमूने में - 10। पहले मामले में, समस्या को हल करने वालों का प्रतिशत 12/20·100%=60% होगा, और दूसरे में 10/25·100%=40%। क्या डेटा को देखते हुए ये प्रतिशत काफी भिन्न हैं?एन 1 औरएन 2 ?
ऐसा प्रतीत होता है कि "आंख से" भी कोई यह निर्धारित कर सकता है कि 60% 40% से काफी अधिक है। हालाँकि, वास्तव में, ये अंतर, डेटा को देखते हुएएन 1 , एन 2 अविश्वसनीय.
आइये इसकी जाँच करें। चूँकि हम किसी समस्या को हल करने के तथ्य में रुचि रखते हैं, इसलिए हम प्रायोगिक समस्या को हल करने में सफलता को "प्रभाव" के रूप में मानेंगे, और इसे हल करने में विफलता को प्रभाव की अनुपस्थिति के रूप में मानेंगे।
आइए परिकल्पनाएँ बनाएँ।
एच 0 : व्यक्तियों का अनुपातदूसरे समूह की तुलना में पहले समूह में कार्य पूरा करने वाले अधिक लोग नहीं थे।
एच 1 : पहले समूह में कार्य पूरा करने वाले लोगों का अनुपात दूसरे समूह की तुलना में अधिक है।
आइए अब एक तथाकथित चार-सेल, या चार-फ़ील्ड तालिका बनाएं, जो वास्तव में विशेषता के दो मानों के लिए अनुभवजन्य आवृत्तियों की एक तालिका है: "एक प्रभाव है" - "कोई प्रभाव नहीं है।"
तालिका 5.1
समस्या को हल करने वालों के प्रतिशत के अनुसार विषयों के दो समूहों की तुलना करते समय मानदंड की गणना के लिए चार-सेल तालिका।
समूह | "प्रभाव है": समस्या हल हो गई है | "कोई प्रभाव नहीं": समस्या हल नहीं हुई है | राशियाँ |
||||
मात्रा विषयों | % शेयर करना | मात्रा विषयों | % शेयर करना | ||||
1 समूह | (60%) | (40%) | |||||
दूसरा समूह | (40%) | (60%) | |||||
राशियाँ | |||||||
चार-सेल तालिका में, एक नियम के रूप में, कॉलम "एक प्रभाव है" और "कोई प्रभाव नहीं" शीर्ष पर चिह्नित हैं, और पंक्तियाँ "समूह 1" और "समूह 2" बाईं ओर हैं। वास्तव में, केवल फ़ील्ड (कोशिकाएं) ए और बी तुलना में शामिल हैं, यानी, "प्रभाव है" कॉलम में प्रतिशत।
तालिका के अनुसार.बारहवींपरिशिष्ट 1 प्रत्येक समूह में प्रतिशत शेयरों के अनुरूप φ का मान निर्धारित करता है।
आइए अब सूत्र का उपयोग करके φ* के अनुभवजन्य मूल्य की गणना करें:
कहां φ 1 - बड़े% शेयर के अनुरूप कोण;
φ 2 - छोटे% शेयर के अनुरूप कोण;
एन 1 - नमूना 1 में प्रेक्षणों की संख्या;
एन 2 - नमूना 2 में अवलोकनों की संख्या।
इस मामले में:
तालिका के अनुसार.तेरहवेंपरिशिष्ट 1 में हम यह निर्धारित करते हैं कि महत्व का कौन सा स्तर φ* से मेल खाता है ईएम=1,34:
पी=0.09
मनोविज्ञान में स्वीकृत सांख्यिकीय महत्व के स्तरों के अनुरूप φ* के महत्वपूर्ण मान स्थापित करना भी संभव है:
आइए एक "महत्व अक्ष" बनाएं।
प्राप्त अनुभवजन्य मूल्य φ* महत्वहीनता के क्षेत्र में है।
उत्तर: एच 0 स्वीकृत। कार्य पूरा करने वाले लोगों का प्रतिशतवीपहला समूह दूसरे समूह से अधिक नहीं है।
कोई केवल उस शोधकर्ता के प्रति सहानुभूति रख सकता है जो φ* मानदंड का उपयोग करके उनकी विश्वसनीयता की जांच किए बिना 20% और यहां तक कि 10% के अंतर को भी महत्वपूर्ण मानता है। इस मामले में, उदाहरण के लिए, कम से कम 24.3% का अंतर ही महत्वपूर्ण होगा।
ऐसा लगता है कि किसी भी गुणात्मक आधार पर दो नमूनों की तुलना करते समय, φ मानदंड हमें खुश करने के बजाय दुखी कर सकता है। जो महत्वपूर्ण लग रहा था वह सांख्यिकीय दृष्टिकोण से उतना महत्वपूर्ण नहीं हो सकता है।
जब हम मात्रात्मक रूप से मापी गई विशेषताओं के अनुसार दो नमूनों की तुलना करते हैं और "प्रभाव" को भिन्न कर सकते हैं, तो फिशर मानदंड में शोधकर्ता को खुश करने के बहुत अधिक अवसर होते हैं।
उदाहरण 2 - मात्रात्मक रूप से मापी गई विशेषता के अनुसार दो नमूनों की तुलना
मानदंड के इस उपयोग में, हम एक नमूने में उन विषयों के प्रतिशत की तुलना करते हैं जो एक निश्चित स्तर की विशेषता मान प्राप्त करते हैं, उन विषयों के प्रतिशत के साथ जो दूसरे नमूने में इस स्तर को प्राप्त करते हैं।
जी. ए. टलगेनोवा (1990) के एक अध्ययन में, 14 से 16 वर्ष की आयु के 70 युवा व्यावसायिक स्कूल के छात्रों में से, आक्रामकता पैमाने पर उच्च स्कोर वाले 10 विषयों और आक्रामकता पैमाने पर कम स्कोर वाले 11 विषयों को परिणामों के आधार पर चुना गया था। फ़्रीबर्ग व्यक्तित्व प्रश्नावली का उपयोग करते हुए एक सर्वेक्षण का। यह निर्धारित करना आवश्यक है कि क्या आक्रामक और गैर-आक्रामक युवाओं के समूह उस दूरी के संदर्भ में भिन्न हैं जो वे किसी साथी छात्र के साथ बातचीत में अनायास चुनते हैं। G. A. Tlegenova का डेटा तालिका में प्रस्तुत किया गया है। 5.2. आप देख सकते हैं कि आक्रामक युवा अक्सर 50 की दूरी चुनते हैंसेमी या उससे भी कम, जबकि गैर-आक्रामक लड़के अक्सर 50 सेमी से अधिक की दूरी चुनते हैं।
अब हम 50 सेमी की दूरी को महत्वपूर्ण मान सकते हैं और मान सकते हैं कि यदि विषय द्वारा चुनी गई दूरी 50 सेमी से कम या उसके बराबर है, तो "प्रभाव होता है," और यदि चयनित दूरी 50 सेमी से अधिक है, तो "कोई प्रभाव नहीं है।" हम देखते हैं कि आक्रामक युवा पुरुषों के समूह में 10 में से 7, यानी 70% मामलों में, और गैर-आक्रामक युवा पुरुषों के समूह में - 11 में से 2, यानी 18.2% मामलों में प्रभाव देखा जाता है। . इन प्रतिशतों की तुलना उनके बीच के अंतर के महत्व को स्थापित करने के लिए φ* विधि का उपयोग करके की जा सकती है।
तालिका 5.2
एक साथी छात्र के साथ बातचीत में आक्रामक और गैर-आक्रामक युवा पुरुषों द्वारा चुनी गई दूरी के संकेतक (सेमी में) (जी.ए. टेलगेनोवा के अनुसार, 1990)
समूह 1: आक्रामकता पैमाने पर उच्च अंक वाले लड़केएफपीआई- आर (एन 1 =10) | समूह 2: आक्रामकता पैमाने पर कम मूल्य वाले लड़केएफपीआई- आर (एन 2 =11) |
|||
डी(सी एम ) | % शेयर करना | डी(सी एम ) | % शेयर करना |
|
"खाओ प्रभाव" डी≤50 सेमी | ||||
18,2% |
||||
"नहीं प्रभाव" डी>50सेमी | ||||
80 QO | 81,8% |
|||
राशियाँ | 100% | 100% |
||
औसत | 5बी:ओ | 77.3 | ||
आइए परिकल्पनाएँ बनाएँ।
एच 0 डी ≤ 50 सेमी, आक्रामक लड़कों के समूह में गैर-आक्रामक लड़कों के समूह से अधिक नहीं हैं।
एच 1 : दूरी चुनने वाले लोगों का अनुपातडी≤ 50 सेमी, गैर-आक्रामक युवा पुरुषों के समूह की तुलना में आक्रामक युवा पुरुषों के समूह में अधिक। आइए अब एक तथाकथित चार-सेल तालिका बनाएं।
तालिका 53
आक्रामक समूहों की तुलना करते समय φ* मानदंड की गणना के लिए चार-सेल तालिका (एनएफ=10) और गैर-आक्रामक युवा पुरुष (n2=11)
समूह | "वहाँ एक प्रभाव है": डी≤50 | "कोई असर नहीं।" डी>50 | राशियाँ |
||||
विषयों की संख्या | (% शेयर करना) | विषयों की संख्या | (% शेयर करना) | ||||
समूह 1 - आक्रामक युवा पुरुष | (70%) | (30%) | |||||
समूह 2 - गैर-आक्रामक युवा पुरुष | (180%) | (81,8%) | |||||
जोड़ | |||||||
तालिका के अनुसार.बारहवींपरिशिष्ट 1 प्रत्येक समूह में "प्रभाव" के प्रतिशत शेयरों के अनुरूप φ का मान निर्धारित करता है।
प्राप्त अनुभवजन्य मूल्य φ* महत्व के क्षेत्र में है।
उत्तर: एच 0 अस्वीकार कर दिया। स्वीकृतएच 1 . बातचीत के दौरान 50 सेमी से कम या उसके बराबर दूरी चुनने वाले लोगों का अनुपात गैर-आक्रामक युवा पुरुषों के समूह की तुलना में आक्रामक युवा पुरुषों के समूह में अधिक है।
प्राप्त परिणामों के आधार पर, हम यह निष्कर्ष निकाल सकते हैं कि अधिक आक्रामक युवा पुरुष अक्सर आधे मीटर से कम की दूरी चुनते हैं, जबकि गैर-आक्रामक युवा अक्सर आधे मीटर से अधिक की दूरी चुनते हैं। हम देखते हैं कि आक्रामक युवा वास्तव में अंतरंग (0-46 सेमी) और व्यक्तिगत क्षेत्र (46 सेमी से) के बीच की सीमा पर संवाद करते हैं। हालाँकि, हमें याद है कि भागीदारों के बीच अंतरंग दूरी न केवल करीबी, अच्छे रिश्तों का विशेषाधिकार है, बल्किऔरकाम दायरे में दो लोगो की लड़ाई (बड़ा कमराई. टी., 1959).
उदाहरण 3 - विशेषता के स्तर और वितरण दोनों के आधार पर नमूनों की तुलना।
इस उपयोग के मामले में, हम पहले परीक्षण कर सकते हैं कि क्या समूह किसी विशेषता के स्तर में भिन्न हैं और फिर दो नमूनों में विशेषता के वितरण की तुलना कर सकते हैं। किसी नई तकनीक का उपयोग करके विषयों द्वारा प्राप्त मूल्यांकन के वितरण की सीमा या आकार में अंतर का विश्लेषण करते समय ऐसा कार्य प्रासंगिक हो सकता है।
आर. टी. चिरकिना (1995) के एक अध्ययन में, पहली बार व्यक्तिगत, पारिवारिक और व्यावसायिक जटिलताओं के कारण स्मृति से तथ्यों, नामों, इरादों और कार्रवाई के तरीकों को दबाने की प्रवृत्ति की पहचान करने के उद्देश्य से एक प्रश्नावली का उपयोग किया गया था। प्रश्नावली 3. फ्रायड की "साइकोपैथोलॉजी ऑफ एवरीडे लाइफ" पुस्तक की सामग्री के आधार पर ई.वी. सिडोरेंको की भागीदारी से बनाई गई थी। इस प्रश्नावली का उपयोग करके, साथ ही व्यक्तिगत अपर्याप्तता की भावना की तीव्रता की पहचान करने के लिए मेनेस्टर-कोर्ज़िनी तकनीक का उपयोग करके, 17 से 20 वर्ष की आयु के, अविवाहित, बिना बच्चों वाले, पेडागोगिकल इंस्टीट्यूट के 50 छात्रों के एक नमूने की जांच की गई।या"हीन भावना" (मनैस्टरजी. जे., कोर्सिनीआर. जे., 1982).
सर्वेक्षण के परिणाम तालिका में प्रस्तुत किए गए हैं। 5.4.
क्या यह कहना संभव है कि प्रश्नावली का उपयोग करके निदान किए गए दमन ऊर्जा के संकेतक और तीव्रता के संकेतक, किसी की स्वयं की अपर्याप्तता की भावना के बीच कोई महत्वपूर्ण संबंध हैं?
तालिका 5.4
उच्च स्तर वाले छात्रों के समूहों में व्यक्तिगत अपर्याप्तता की भावनाओं की तीव्रता के संकेतक (न्यू जर्सी=18) और निम्न (n2=24) विस्थापन ऊर्जा
समूह 1: विस्थापन ऊर्जा 19 से 31 अंक तक (एन 1 =181 | समूह 2: विस्थापन ऊर्जा 7 से 13 अंक तक (एन 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
राशियाँ औसत | 26,11 | 15,42 |
इस तथ्य के बावजूद कि अधिक ऊर्जावान दमन वाले समूह में औसत मूल्य अधिक है, इसमें 5 शून्य मान भी देखे गए हैं। यदि हम दो नमूनों में रेटिंग के वितरण के हिस्टोग्राम की तुलना करते हैं, तो उनके बीच एक आश्चर्यजनक विरोधाभास सामने आता है (चित्र 5.3)।
दो वितरणों की तुलना करने के लिए हम परीक्षण लागू कर सकते हैंχ 2 या कसौटीλ , लेकिन इसके लिए हमें अंकों को बड़ा करना होगा, और इसके अलावा, दोनों नमूनों में भीएन <30.
φ* मानदंड हमें ग्राफ़ में देखे गए दो वितरणों के बीच विसंगति के प्रभाव की जांच करने की अनुमति देगा यदि हम यह मानने के लिए सहमत हैं कि "प्रभाव है" यदि अपर्याप्तता की भावनाओं का संकेतक या तो बहुत कम (0) लेता है या, इसके विपरीत , बहुत उच्च मूल्य (एस30), और यह कि "कोई प्रभाव नहीं पड़ता" यदि अपर्याप्तता की भावनाओं का संकेतक 5 से 25 तक औसत मान लेता है।
आइए परिकल्पनाएँ बनाएँ।
एच 0 : अधिक ऊर्जावान दमन वाले समूह में कमी सूचकांक (या तो 0 या 30 या अधिक) के चरम मूल्य कम ऊर्जावान दमन वाले समूह की तुलना में अधिक सामान्य नहीं हैं।
एच 1 : अधिक ऊर्जावान दमन वाले समूह में कमी सूचकांक (या तो 0 या 30 या अधिक) के चरम मूल्य कम ऊर्जावान दमन वाले समूह की तुलना में अधिक आम हैं।
आइए φ* मानदंड की आगे की गणना के लिए सुविधाजनक चार-सेल तालिका बनाएं।
तालिका 5.5
अपर्याप्तता संकेतकों के अनुपात के आधार पर उच्च और निम्न दमन ऊर्जा वाले समूहों की तुलना करते समय φ* मानदंड की गणना के लिए चार-सेल तालिका
समूह | "प्रभाव है": कमी सूचक 0 या >30 है | "कोई प्रभाव नहीं": विफलता सूचकांक 5 से 25 तक | राशियाँ |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
राशियाँ | |||||
तालिका के अनुसार.बारहवींपरिशिष्ट 1 में हम तुलनात्मक प्रतिशत के अनुरूप φ का मान निर्धारित करते हैं:
आइए φ* के अनुभवजन्य मूल्य की गणना करें:
किसी के लिए φ* के महत्वपूर्ण मानएन 1 , एन 2 , जैसा कि हमें पिछले उदाहरण से याद है, ये हैं:
मेज़तेरहवेंपरिशिष्ट 1 हमें प्राप्त परिणाम के महत्व के स्तर को अधिक सटीक रूप से निर्धारित करने की अनुमति देता है: पी<0,001.
उत्तर: एच 0 अस्वीकार कर दिया। स्वीकृतएच 1 . अधिक दमन ऊर्जा वाले समूह में कमी सूचकांक (या तो 0 या 30 या अधिक) के चरम मूल्य कम दमन ऊर्जा वाले समूह की तुलना में अधिक बार होते हैं।
इसलिए, अधिक दमन ऊर्जा वाले विषयों में अपनी अपर्याप्तता की भावना के बहुत अधिक (30 या अधिक) और बहुत कम (शून्य) दोनों संकेतक हो सकते हैं। यह माना जा सकता है कि वे अपने असंतोष और जीवन में सफलता की आवश्यकता दोनों को दबा रहे हैं। इन धारणाओं को और अधिक परीक्षण की आवश्यकता है।
प्राप्त परिणाम, इसकी व्याख्या की परवाह किए बिना, दो नमूनों में किसी विशेषता के वितरण के आकार में अंतर का आकलन करने में φ* मानदंड की क्षमताओं की पुष्टि करता है।
मूल नमूने में 50 लोग थे, लेकिन उनमें से 8 को दमन ऊर्जा सूचकांक (14-15) पर औसत स्कोर होने के कारण विचार से बाहर रखा गया था। अपर्याप्तता की भावनाओं की तीव्रता के उनके संकेतक भी औसत हैं: प्रत्येक 20 अंक के 6 मान और 25 अंक के 2 मान।
इस उदाहरण की सामग्रियों का विश्लेषण करते समय φ* मानदंड की शक्तिशाली क्षमताओं को एक पूरी तरह से अलग परिकल्पना की पुष्टि करके सत्यापित किया जा सकता है। उदाहरण के लिए, हम साबित कर सकते हैं कि अधिक दमन ऊर्जा वाले समूह में अपर्याप्तता की दर अभी भी अधिक है, इस समूह में इसके वितरण की विरोधाभासी प्रकृति के बावजूद।
आइए नई परिकल्पनाएँ बनाएँ।
एच 0 अधिक दमन ऊर्जा वाले समूह में कमी सूचकांक (30 या अधिक) के उच्चतम मान कम दमन ऊर्जा वाले समूह की तुलना में अधिक सामान्य नहीं हैं।
एच 1 : अधिक दमन ऊर्जा वाले समूह में कमी सूचकांक (30 या अधिक) के उच्चतम मान कम दमन ऊर्जा वाले समूह की तुलना में अधिक बार होते हैं। आइए तालिका में डेटा का उपयोग करके एक चार-फ़ील्ड तालिका बनाएं। 5.4.
तालिका 5.6
अपर्याप्तता संकेतक के स्तर के अनुसार अधिक और कम दमन ऊर्जा वाले समूहों की तुलना करते समय φ* मानदंड की गणना के लिए चार-सेल तालिका
समूह | "प्रभाव है"* विफलता सूचक 30 से अधिक या उसके बराबर है | "कोई प्रभाव नहीं": विफलता दर कम है 30 | राशियाँ |
||
समूह 1 - अधिक विस्थापन ऊर्जा के साथ | (61,1%) | (38.9%) | |||
समूह 2 - कम विस्थापन ऊर्जा के साथ | (25.0%) | (75.0%) | |||
राशियाँ | |||||
तालिका के अनुसार.तेरहवेंपरिशिष्ट 1 में हम निर्धारित करते हैं कि यह परिणाम p = 0.008 के महत्व स्तर से मेल खाता है।
उत्तर: लेकिन इसे खारिज कर दिया गया है. स्वीकृतहज: समूह में कमी के उच्चतम संकेतक (30 या अधिक अंक)।साथअधिक विस्थापन ऊर्जा वाले समूह में कम विस्थापन ऊर्जा वाले समूह की तुलना में अधिक बार होता है (पी = 0.008)।
इसलिए, हम यह साबित करने में सक्षम थेवीसमूहसाथअधिक ऊर्जावान दमन के साथ, अपर्याप्तता संकेतक के चरम मूल्य प्रबल होते हैं, और तथ्य यह है कि यह संकेतक अपने मूल्यों से अधिक हैपहुँचता हैबिल्कुल इसी समूह में.
अब हम यह सिद्ध करने का प्रयास कर सकते हैं कि उच्च दमन ऊर्जा वाले समूह में अपर्याप्तता सूचकांक के निम्न मान अधिक सामान्य हैं, इस तथ्य के बावजूद कि औसत मूल्यवी इस समूह में अधिक (26.11 बनाम 15.42) हैंसाथ कम विस्थापन)।
आइए परिकल्पनाएँ बनाएँ।
एच 0 : समूह में सबसे कम कमी दर (शून्य)।साथ अधिक ऊर्जा वाले दमन समूह की तुलना में अधिक सामान्य नहीं हैंसाथ कम विस्थापन ऊर्जा.
एच 1 : कमी की दर सबसे कम (शून्य) होती हैवी समूह की अपेक्षा अधिक दमन ऊर्जा वाला समूहसाथ कम ऊर्जावान दमन. आइए डेटा को एक नई चार-सेल तालिका में समूहित करें।
तालिका 5.7
कमी सूचक के शून्य मानों की आवृत्ति के आधार पर विभिन्न दमन ऊर्जा वाले समूहों की तुलना करने के लिए चार-सेल तालिका
समूह | "वहाँ एक प्रभाव है": विफलता सूचक 0 है | अपर्याप्तता का "कोई प्रभाव नहीं"। | सूचक 0 के बराबर नहीं है | राशियाँ |
|
समूह 1 - अधिक विस्थापन ऊर्जा के साथ | (27,8%) | (72,2%) | |||
1 समूह - कम विस्थापन ऊर्जा के साथ | (8,3%) | (91,7%) | |||
राशियाँ | |||||
हम φ के मान निर्धारित करते हैं और φ* के मान की गणना करते हैं:
उत्तर: एच 0 अस्वीकार कर दिया। अधिक दमन ऊर्जा वाले समूह में अपर्याप्तता (शून्य) के सबसे कम सूचकांक कम दमन ऊर्जा वाले समूह की तुलना में अधिक आम हैं (पी)<0,05).
कुल मिलाकर, प्राप्त परिणामों को एस. फ्रायड और ए. एडलर में कॉम्प्लेक्स की अवधारणाओं के आंशिक संयोग का प्रमाण माना जा सकता है।
यह महत्वपूर्ण है कि दमन ऊर्जा के संकेतक और समग्र रूप से नमूने में किसी की स्वयं की अपर्याप्तता की भावना की तीव्रता के संकेतक के बीच एक सकारात्मक रैखिक सहसंबंध प्राप्त किया गया था (पी = +0.491, पी<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
उदाहरण 4 - मानदंड के साथ संयोजन में φ* मानदंड का उपयोग करना λ अधिकतम प्राप्त करने के लिए कोलमोगोरोव-स्मिरनोव शुद्धपरिणाम
यदि नमूनों की तुलना किसी मात्रात्मक रूप से मापे गए संकेतक के अनुसार की जाती है, तो वितरण बिंदु की पहचान करने में समस्या उत्पन्न होती है जिसका उपयोग सभी विषयों को "प्रभाव डालने वाले" और "प्रभाव नहीं डालने वाले" में विभाजित करने में एक महत्वपूर्ण बिंदु के रूप में किया जा सकता है।
सिद्धांत रूप में, वह बिंदु जिस पर हम समूह को उपसमूहों में विभाजित करेंगे जहां प्रभाव है और जहां कोई प्रभाव नहीं है, उसे काफी मनमाने ढंग से चुना जा सकता है। हमें किसी भी प्रभाव में रुचि हो सकती है और इसलिए, हम किसी भी बिंदु पर दोनों नमूनों को दो भागों में विभाजित कर सकते हैं, जब तक कि इसमें कुछ अर्थ हो।
हालाँकि, φ* परीक्षण की शक्ति को अधिकतम करने के लिए, उस बिंदु का चयन करना आवश्यक है जिस पर दो तुलनात्मक समूहों के बीच अंतर सबसे बड़ा है। सबसे सटीक रूप से, हम मानदंड की गणना के लिए एक एल्गोरिदम का उपयोग करके ऐसा कर सकते हैंλ , आपको दो नमूनों के बीच अधिकतम विसंगति के बिंदु का पता लगाने की अनुमति देता है।
मानदंड φ* और के संयोजन की संभावनाλ ई.वी. द्वारा वर्णित गब्लर (1978, पृ. 85-88)। आइए निम्नलिखित समस्या को हल करने में इस विधि का उपयोग करने का प्रयास करें।
एम.ए. द्वारा एक संयुक्त अध्ययन में कुरोचकिना, ई.वी. सिडोरेंको और यू.ए. यूके में चुराकोव (1992) ने दो श्रेणियों के अंग्रेजी सामान्य चिकित्सकों का एक सर्वेक्षण किया: ए) डॉक्टर जिन्होंने चिकित्सा सुधार का समर्थन किया और पहले से ही अपने रिसेप्शन कार्यालयों को अपने स्वयं के बजट के साथ फंड-होल्डिंग संगठनों में बदल दिया था; बी) डॉक्टर जिनके कार्यालयों के पास अभी भी अपना धन नहीं है और पूरी तरह से राज्य के बजट द्वारा प्रदान किया जाता है। बड़े शहरों या प्रांतों में विभिन्न लिंग, आयु, सेवा की अवधि और कार्य स्थान के लोगों के प्रतिनिधित्व के संदर्भ में अंग्रेजी डॉक्टरों की सामान्य आबादी के प्रतिनिधि 200 डॉक्टरों के नमूने के लिए प्रश्नावली भेजी गईं।
78 डॉक्टरों ने प्रश्नावली का उत्तर दिया, जिनमें से 50 ने धन के साथ प्रतीक्षा कक्षों में काम किया और 28 ने बिना धन के प्रतीक्षा कक्षों में काम किया। प्रत्येक डॉक्टर को यह अनुमान लगाना था कि अगले वर्ष, 1993 में धन के साथ प्रवेश का हिस्सा क्या होगा। जवाब भेजने वाले 78 में से केवल 70 डॉक्टरों ने ही इस सवाल का जवाब दिया. उनके पूर्वानुमानों का वितरण तालिका में प्रस्तुत किया गया है। 5.8 धन वाले डॉक्टरों के समूह और वित्त रहित डॉक्टरों के समूह के लिए अलग से।
क्या धन वाले डॉक्टरों और बिना धन वाले डॉक्टरों की भविष्यवाणियाँ किसी भी तरह से भिन्न हैं?
तालिका 5.8
1993 में धन के साथ आपातकालीन कक्षों की हिस्सेदारी क्या होगी, इसके बारे में सामान्य चिकित्सकों से पूर्वानुमान का वितरण
प्रक्षेपित शेयर | |||
धन के साथ स्वागत कक्ष | फंड वाले डॉक्टर (एन 1 =45) | बिना फंड के डॉक्टर (एन 2 =25) | राशियाँ |
1. 0 से 20% तक | 4 | 5 | 9 |
2. 21 से 40% तक | 15 | और | 26 |
3. 41 से 60% तक | 18 | 5 | 23 |
4. 61 से 80% तक | 7 | 4 | और |
5. 81 से 100% तक | 1 | 0 | 1 |
राशियाँ | 45 | 25 | 70 |
आइए खंड 4.3 से एल्गोरिदम 15 का उपयोग करके उत्तरों के दो वितरणों के बीच अधिकतम विसंगति का बिंदु निर्धारित करें (तालिका 5.9 देखें)।
तालिका 5.9
दो समूहों के डॉक्टरों के पूर्वानुमान के वितरण में संचित आवृत्तियों में अधिकतम अंतर की गणना
धनराशि के साथ प्रवेश का अनुमानित हिस्सा (%) | किसी दी गई प्रतिक्रिया श्रेणी के लिए पसंद की अनुभवजन्य आवृत्तियाँ | अनुभवजन्य आवृत्तियाँ | संचयी अनुभवजन्य आवृत्तियाँ | अंतर (डी) |
|||
डॉक्टर फंड के साथ(एन 1 =45) | बिना फंड के डॉक्टर (एन 2 =25) | एफ* उह 1 | एफ* ए2 | ∑एफ* ई 1 | ∑एफ* ए 1 |
||
1. 0 से 20% तक 2. 21 से 40% तक 3. 41 से 60% तक 4. 61 से 80% तक 5. 81 से 100% तक | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
दो संचित अनुभवजन्य आवृत्तियों के बीच पाया गया अधिकतम अंतर है0,218.
यह अंतर पूर्वानुमान की दूसरी श्रेणी में संचित हो जाता है। आइए इस श्रेणी की ऊपरी सीमा को दोनों नमूनों को एक उपसमूह में विभाजित करने के लिए एक मानदंड के रूप में उपयोग करने का प्रयास करें जहां "एक प्रभाव है" और एक उपसमूह जहां "कोई प्रभाव नहीं है।" हम मान लेंगे कि एक "प्रभाव" है यदि कोई डॉक्टर धन के साथ 41 से 100% प्रवेश की भविष्यवाणी करता है1993 वर्ष, और यदि कोई डॉक्टर धन के साथ 0 से 40% प्रवेश की भविष्यवाणी करता है तो "कोई प्रभाव नहीं" पड़ता है1993 वर्ष। हम एक ओर पूर्वानुमान श्रेणियों 1 और 2 को जोड़ते हैं, और दूसरी ओर पूर्वानुमान श्रेणियों 3, 4 और 5 को जोड़ते हैं। पूर्वानुमानों का परिणामी वितरण तालिका में प्रस्तुत किया गया है। 5.10.
तालिका 5.10
धन वाले डॉक्टरों और बिना धन वाले डॉक्टरों के लिए पूर्वानुमानों का वितरण
निधि के साथ प्रवेश का अनुमानित हिस्सा (%1 | किसी दिए गए पूर्वानुमान श्रेणी को चुनने के लिए अनुभवजन्य आवृत्तियाँ | राशियाँ |
|
डॉक्टर फंड के साथ(एन 1 =45) | बिना फंड के डॉक्टर(एन 2 =25) |
||
1. 0 से 40% तक | 19 | 16 | 35 |
2. 41 से 100% तक | 26 | 9 | 35 |
राशियाँ | 45 | 25 | 70 |
हम परिणामी तालिका (तालिका 5.10) का उपयोग इसकी किन्हीं दो कोशिकाओं की तुलना करके विभिन्न परिकल्पनाओं का परीक्षण करने के लिए कर सकते हैं। हमें याद है कि यह तथाकथित चार-सेल, या चार-फ़ील्ड, तालिका है।
यहां, हम इस बात में रुचि रखते हैं कि क्या जिन चिकित्सकों के पास पहले से ही धन है, वे भविष्यवाणी करते हैं कि भविष्य में आंदोलन उन चिकित्सकों की तुलना में बड़ा होगा जिनके पास धन नहीं है। इसलिए, हम सशर्त रूप से मानते हैं कि "प्रभाव होता है" जब पूर्वानुमान 41 से 100% की श्रेणी में आता है। गणनाओं को सरल बनाने के लिए, अब हमें तालिका को दक्षिणावर्त दिशा में घुमाते हुए 90° घुमाने की आवश्यकता है। आप टेबल के साथ-साथ किताब को पलट कर भी ऐसा शाब्दिक रूप से कर सकते हैं। अब हम φ* मानदंड - फिशर एंगुलर ट्रांसफॉर्म की गणना के लिए वर्कशीट पर आगे बढ़ सकते हैं।
मेज़ 5.11
सामान्य चिकित्सकों के दो समूहों के पूर्वानुमानों में अंतर की पहचान करने के लिए फिशर के φ* परीक्षण की गणना के लिए चार-सेल तालिका
समूह | असर है - 41 से 100% तक पूर्वानुमान | कोई प्रभाव नहीं - 0 से 40% तक पूर्वानुमान | कुल |
मैंसमूह - डॉक्टर जिन्होंने फंड लिया | 26 (57.8%) | 19 (42.2%) | 45 |
द्वितीयग्रुप - जिन डॉक्टरों ने फंड नहीं लिया | 9 (36.0%) | 16 (64.0%) | 25 |
कुल | 35 | 35 | 70 |
आइए परिकल्पनाएँ बनाएँ।
एच 0 : व्यक्तियों का अनुपातसभी डॉक्टरों के कार्यालयों में 41%-100% तक धन के प्रसार की भविष्यवाणी करते हुए, धन वाले डॉक्टरों के समूह में धन रहित डॉक्टरों के समूह से अधिक कुछ नहीं है।
एच 1 : सभी रिसेप्शन के 41%-100% तक धन के प्रसार की भविष्यवाणी करने वाले लोगों का अनुपात धन वाले डॉक्टरों के समूह में धन रहित डॉक्टरों के समूह की तुलना में अधिक है।
φ का मान निर्धारित करना 1 और φ 2 तालिका के अनुसारबारहवींपरिशिष्ट 1. याद रखें कि φ 1 हमेशा बड़े प्रतिशत के अनुरूप कोण होता है।
आइए अब मानदंड φ* का अनुभवजन्य मान निर्धारित करें:
तालिका के अनुसार.तेरहवेंपरिशिष्ट 1 में हम यह निर्धारित करते हैं कि यह मान किस स्तर के महत्व से मेल खाता है: पी = 0.039।
परिशिष्ट 1 में उसी तालिका का उपयोग करके, मानदंड φ* के महत्वपूर्ण मान निर्धारित किए जा सकते हैं:
उत्तर: लेकिन इसे अस्वीकार कर दिया गया है (पी=0.039)। धन के प्रसार की भविष्यवाणी करने वाले लोगों का हिस्सा41-100 % फंड लेने वाले डॉक्टरों के समूह में सभी रिसेप्शन का हिस्सा उन डॉक्टरों के समूह में इस शेयर से अधिक है जिन्होंने फंड नहीं लिया।
दूसरे शब्दों में, जो डॉक्टर पहले से ही एक अलग बजट पर अपने प्रतीक्षा कक्षों में काम करते हैं, वे उन डॉक्टरों की तुलना में इस वर्ष इस अभ्यास के व्यापक प्रसार की भविष्यवाणी करते हैं जो अभी तक एक स्वतंत्र बजट पर स्विच करने के लिए सहमत नहीं हुए हैं। इस परिणाम की कई व्याख्याएँ हैं। उदाहरण के लिए, यह माना जा सकता है कि प्रत्येक समूह के डॉक्टर अवचेतन रूप से अपने व्यवहार को अधिक विशिष्ट मानते हैं। इसका मतलब यह भी हो सकता है कि जो डॉक्टर पहले से ही स्व-वित्तपोषण अपना चुके हैं, वे इस आंदोलन के दायरे को बढ़ा-चढ़ाकर पेश करते हैं, क्योंकि उन्हें अपने निर्णय को उचित ठहराने की आवश्यकता होती है। पहचाने गए मतभेदों का मतलब कुछ ऐसा भी हो सकता है जो अध्ययन में पूछे गए प्रश्नों के दायरे से पूरी तरह परे है। उदाहरण के लिए, स्वतंत्र बजट पर काम करने वाले डॉक्टरों की गतिविधि दोनों समूहों की स्थिति में अंतर को तेज करने में योगदान करती है। जब वे धनराशि लेने के लिए सहमत हुए तो वे अधिक सक्रिय थे; जब उन्होंने मेल प्रश्नावली का उत्तर देने में परेशानी उठाई तो वे अधिक सक्रिय थे; वे तब अधिक सक्रिय होते हैं जब वे भविष्यवाणी करते हैं कि अन्य डॉक्टर धन प्राप्त करने में अधिक सक्रिय होंगे।
किसी भी तरह, हम यह सुनिश्चित कर सकते हैं कि सांख्यिकीय अंतर का पता लगाया गया स्तर इन वास्तविक डेटा के लिए अधिकतम संभव है। हमने मानदंड का उपयोग करके स्थापित कियाλ दो वितरणों के बीच अधिकतम विचलन का बिंदु, और इसी बिंदु पर नमूनों को दो भागों में विभाजित किया गया था।
आपकी रेटिंग.
इस उदाहरण में, हम इस बात पर विचार करेंगे कि परिणामी प्रतिगमन समीकरण की विश्वसनीयता का आकलन कैसे किया जाता है। उसी परीक्षण का उपयोग इस परिकल्पना का परीक्षण करने के लिए किया जाता है कि प्रतिगमन गुणांक एक साथ शून्य, a=0, b=0 के बराबर हैं। दूसरे शब्दों में, गणना का सार प्रश्न का उत्तर देना है: क्या इसका उपयोग आगे के विश्लेषण और पूर्वानुमान के लिए किया जा सकता है?
यह निर्धारित करने के लिए कि दो नमूनों में भिन्नताएं समान हैं या भिन्न हैं, इस टी-परीक्षण का उपयोग करें।
तो, विश्लेषण का उद्देश्य कुछ अनुमान प्राप्त करना है जिसके साथ यह कहा जा सकता है कि α के एक निश्चित स्तर पर परिणामी प्रतिगमन समीकरण सांख्यिकीय रूप से विश्वसनीय है। इसके लिए निर्धारण गुणांक आर 2 का उपयोग किया जाता है.
प्रतिगमन मॉडल के महत्व का परीक्षण फिशर के एफ परीक्षण का उपयोग करके किया जाता है, जिसकी गणना मूल्य अध्ययन किए जा रहे संकेतक की टिप्पणियों की मूल श्रृंखला के विचरण के अनुपात और अवशिष्ट अनुक्रम के विचरण के निष्पक्ष अनुमान के रूप में पाया जाता है। इस मॉडल के लिए.
यदि k 1 =(m) और k 2 =(n-m-1) स्वतंत्रता की डिग्री के साथ परिकलित मान किसी दिए गए महत्व स्तर पर सारणीबद्ध मान से अधिक है, तो मॉडल को महत्वपूर्ण माना जाता है।
जहाँ m मॉडल में कारकों की संख्या है।
युग्मित रैखिक प्रतिगमन के सांख्यिकीय महत्व का आकलन निम्नलिखित एल्गोरिदम का उपयोग करके किया जाता है:
1. एक शून्य परिकल्पना प्रस्तुत की गई है कि समग्र रूप से समीकरण सांख्यिकीय रूप से महत्वहीन है: एच 0: आर 2 = 0 महत्व स्तर α पर।
2. अगला, एफ-मानदंड का वास्तविक मूल्य निर्धारित करें: ![]()
![]()
जहाँ जोड़ीवार प्रतिगमन के लिए m=1 है।
3. सारणीबद्ध मान किसी दिए गए महत्व स्तर के लिए फिशर वितरण तालिकाओं से निर्धारित किया जाता है, यह ध्यान में रखते हुए कि वर्गों के कुल योग (बड़े विचरण) के लिए स्वतंत्रता की डिग्री की संख्या 1 है और शेष के लिए स्वतंत्रता की डिग्री की संख्या है रैखिक प्रतिगमन में वर्गों का योग (छोटा विचरण) n-2 है (या एक्सेल फ़ंक्शन FRIST(संभावना,1,n-2) के माध्यम से)।
एफ तालिका स्वतंत्रता की दी गई डिग्री और महत्व स्तर α के साथ यादृच्छिक कारकों के प्रभाव में मानदंड का अधिकतम संभव मूल्य है। महत्व स्तर α सही परिकल्पना को अस्वीकार करने की संभावना है, बशर्ते कि यह सत्य हो। आमतौर पर α को 0.05 या 0.01 माना जाता है।
4. यदि एफ-परीक्षण का वास्तविक मूल्य तालिका मूल्य से कम है, तो वे कहते हैं कि शून्य परिकल्पना को अस्वीकार करने का कोई कारण नहीं है।
अन्यथा, शून्य परिकल्पना को अस्वीकार कर दिया जाता है और समग्र रूप से समीकरण के सांख्यिकीय महत्व के बारे में वैकल्पिक परिकल्पना को संभाव्यता (1-α) के साथ स्वीकार किया जाता है।
स्वतंत्रता की डिग्री के साथ मानदंड का तालिका मूल्य k 1 =1 और k 2 =48, F तालिका = 4
निष्कर्ष: वास्तविक मान F > F तालिका के बाद से, निर्धारण का गुणांक सांख्यिकीय रूप से महत्वपूर्ण है ( पाया गया प्रतिगमन समीकरण अनुमान सांख्यिकीय रूप से विश्वसनीय है) .
विचरण का विश्लेषण
.प्रतिगमन समीकरण गुणवत्ता संकेतक
उदाहरण। कुल 25 व्यापारिक उद्यमों के आधार पर, निम्नलिखित विशेषताओं के बीच संबंध का अध्ययन किया जाता है: एक्स - उत्पाद ए की कीमत, हजार रूबल; Y एक व्यापारिक उद्यम का लाभ है, मिलियन रूबल। प्रतिगमन मॉडल का आकलन करते समय, निम्नलिखित मध्यवर्ती परिणाम प्राप्त हुए: ∑(y i -y x) 2 = 46000; ∑(y i -y avg) 2 = 138000। इन आंकड़ों से कौन सा सहसंबंध संकेतक निर्धारित किया जा सकता है? इस परिणाम और उपयोग के आधार पर इस सूचक के मूल्य की गणना करें फिशर एफ परीक्षणप्रतिगमन मॉडल की गुणवत्ता के बारे में निष्कर्ष निकालें।
समाधान। इन आंकड़ों से हम अनुभवजन्य सहसंबंध अनुपात निर्धारित कर सकते हैं:  , जहां ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
, जहां ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
η 2 = 92,000/138000 = 0.67, η = 0.816 (0.7< η < 0.9 - связь между X и Y высокая).
फिशर एफ परीक्षण: एन = 25, एम = 1.
आर 2 = 1 - 46000/138000 = 0.67, एफ = 0.67/(1-0.67)x(25 - 1 - 1) = 46। एफ तालिका (1; 23) = 4.27
चूँकि वास्तविक मान F > Ftable, प्रतिगमन समीकरण का पाया गया अनुमान सांख्यिकीय रूप से विश्वसनीय है।
प्रश्न: प्रतिगमन मॉडल के महत्व का परीक्षण करने के लिए किन आंकड़ों का उपयोग किया जाता है?
उत्तर: समग्र रूप से संपूर्ण मॉडल के महत्व के लिए, एफ-सांख्यिकी (फिशर परीक्षण) का उपयोग किया जाता है।
दो सामान्य रूप से वितरित आबादी की तुलना करने के लिए जिनके नमूने में कोई अंतर नहीं है, लेकिन भिन्नताओं में अंतर है, इसका उपयोग करें फिशर परीक्षण. वास्तविक मानदंड की गणना सूत्र का उपयोग करके की जाती है:
जहां अंश नमूना विचरण का बड़ा मान है, और हर छोटा है। नमूनों के बीच अंतर की विश्वसनीयता का निष्कर्ष निकालने के लिए, उपयोग करें बुनियादी सिद्धांत
सांख्यिकीय परिकल्पनाओं का परीक्षण। के लिए महत्वपूर्ण बिंदु  तालिका में समाहित हैं। वास्तविक मान होने पर शून्य परिकल्पना अस्वीकृत कर दी जाती है
तालिका में समाहित हैं। वास्तविक मान होने पर शून्य परिकल्पना अस्वीकृत कर दी जाती है 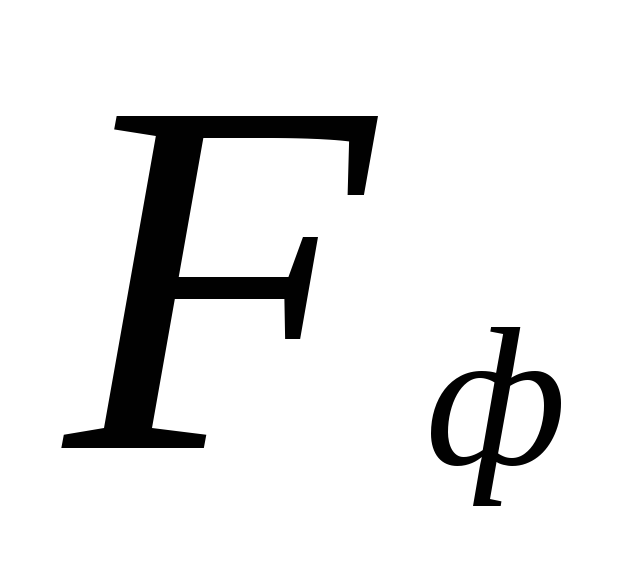 क्रिटिकल (मानक) मान से अधिक या उसके बराबर होगा
क्रिटिकल (मानक) मान से अधिक या उसके बराबर होगा  स्वीकृत महत्व स्तर के लिए यह मान
और स्वतंत्रता की डिग्री की संख्या के
1
=
एन
बड़ा
-1
;
के
2
=
एन
छोटे
-1
.
स्वीकृत महत्व स्तर के लिए यह मान
और स्वतंत्रता की डिग्री की संख्या के
1
=
एन
बड़ा
-1
;
के
2
=
एन
छोटे
-1
.
उदाहरण: बीज के अंकुरण की दर पर एक निश्चित दवा के प्रभाव का अध्ययन करते समय, यह पाया गया कि बीजों के प्रायोगिक बैच और नियंत्रण में, औसत अंकुरण दर समान है, लेकिन भिन्नताओं में अंतर है।  =1250,
=1250, =417. नमूना आकार समान और 20 के बराबर हैं।
=417. नमूना आकार समान और 20 के बराबर हैं। 
 =2.12. अतः शून्य परिकल्पना अस्वीकार की जाती है।
=2.12. अतः शून्य परिकल्पना अस्वीकार की जाती है।
सहसंबंध निर्भरता. सहसंबंध गुणांक और उसके गुण। प्रतिगमन समीकरण.
कामसहसंबंध विश्लेषण नीचे आता है:
विशेषताओं के बीच संबंध की दिशा और रूप स्थापित करना;
इसकी जकड़न को मापना.
कार्यात्मक परिवर्तनीय मात्राओं के बीच एक स्पष्ट संबंध तब कहलाता है जब एक (स्वतंत्र) चर का एक निश्चित मान होता है एक्स , जिसे तर्क कहा जाता है, दूसरे (आश्रित) चर के एक निश्चित मान से मेल खाता है पर , एक फ़ंक्शन कहा जाता है। ( उदाहरण: तापमान पर रासायनिक प्रतिक्रिया की दर की निर्भरता; आकर्षित करने वाले पिंडों के द्रव्यमान और उनके बीच की दूरी पर आकर्षण बल की निर्भरता)।
सह - संबंध चर के बीच एक संबंध है जो प्रकृति में सांख्यिकीय है, जब एक विशेषता का एक निश्चित मान (एक स्वतंत्र चर के रूप में माना जाता है) किसी अन्य विशेषता के संख्यात्मक मानों की एक पूरी श्रृंखला से मेल खाता है। ( उदाहरण: फसल और वर्षा के बीच संबंध; ऊंचाई और वजन आदि के बीच)।
सहसंबंध क्षेत्र बिंदुओं के एक समूह का प्रतिनिधित्व करता है जिनके निर्देशांक प्रयोगात्मक रूप से प्राप्त चर मानों के जोड़े के बराबर हैं एक्स और पर .
सहसंबंध क्षेत्र के प्रकार से कोई कनेक्शन और उसके प्रकार की उपस्थिति या अनुपस्थिति का न्याय कर सकता है।




कनेक्शन कहा जाता है सकारात्मक , यदि एक चर बढ़ने पर दूसरा चर बढ़ता है।
कनेक्शन कहा जाता है नकारात्मक , यदि एक चर बढ़ने पर दूसरा चर घटता है।
कनेक्शन कहा जाता है रेखीय
, यदि इसे विश्लेषणात्मक रूप से प्रस्तुत किया जा सके 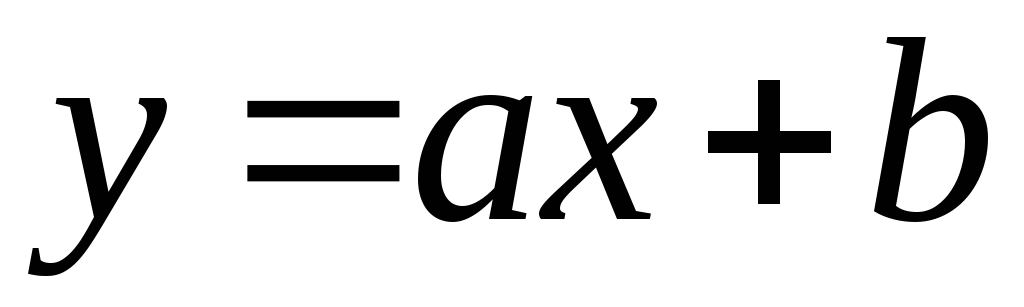 .
.
कनेक्शन की निकटता का सूचक है सहसंबंध गुणांक . अनुभवजन्य सहसंबंध गुणांक द्वारा दिया गया है:

सहसंबंध गुणांक से होता है -1 को 1 और मात्राओं के बीच निकटता की डिग्री को दर्शाता है एक्स और य . अगर:

विशेषताओं के बीच सहसंबंध को विभिन्न तरीकों से वर्णित किया जा सकता है। विशेष रूप से, कनेक्शन के किसी भी रूप को सामान्य रूप के समीकरण द्वारा व्यक्त किया जा सकता है 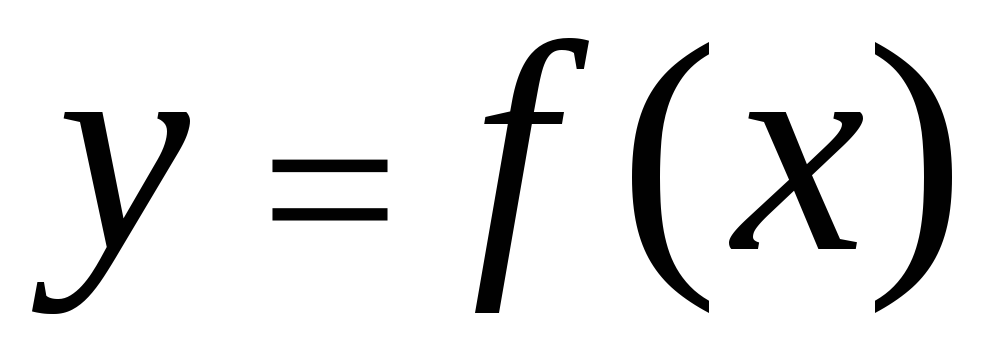 . रूप का समीकरण
. रूप का समीकरण  और
और 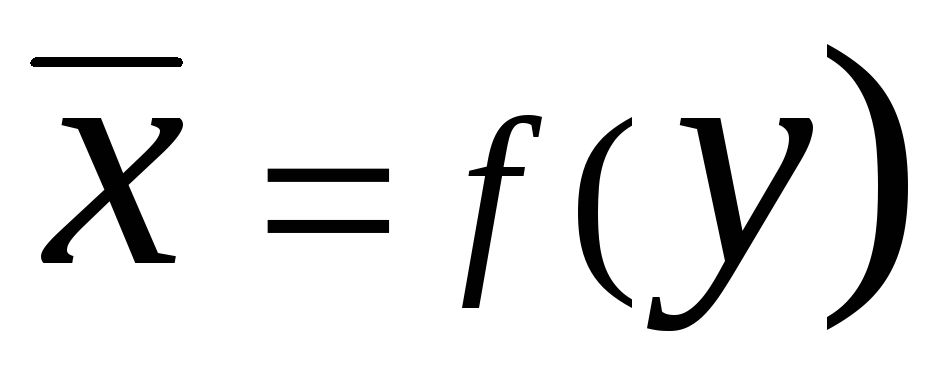 कहा जाता है प्रतिगमन
. फॉरवर्ड रिग्रेशन समीकरण पर
पर एक्स
सामान्य स्थिति में प्रपत्र में लिखा जा सकता है
कहा जाता है प्रतिगमन
. फॉरवर्ड रिग्रेशन समीकरण पर
पर एक्स
सामान्य स्थिति में प्रपत्र में लिखा जा सकता है

फॉरवर्ड रिग्रेशन समीकरण एक्स पर पर सामान्य तौर पर ऐसा दिखता है

सर्वाधिक संभावित गुणांक मान एऔर वी, साथऔर डीउदाहरण के लिए, न्यूनतम वर्ग विधि का उपयोग करके गणना की जा सकती है।







