Ֆիշերի չափանիշը
Ֆիշերի չափանիշն օգտագործվում է երկուսի շեղումների վարկածը ստուգելու համար ընդհանուր պոպուլյացիաներ, բաշխված նորմալ օրենքով։ Պարամետրային չափանիշ է։
Fisher F թեստը կոչվում է շեղումների հարաբերակցություն, քանի որ այն ձևավորվում է որպես համեմատվող շեղումների երկու անաչառ գնահատականների հարաբերակցություն:
Դիտարկումների արդյունքում թող երկու նմուշ ստացվի։ Նրանցից շեղումները և  ունենալով
ունենալով  Եվ
Եվ  ազատության աստիճաններ. Մենք կենթադրենք, որ առաջին նմուշը վերցված է դիսպերսիայով պոպուլյացիայից
ազատության աստիճաններ. Մենք կենթադրենք, որ առաջին նմուշը վերցված է դիսպերսիայով պոպուլյացիայից  , իսկ երկրորդը դիսպերսիայով ընդհանուր բնակչությունից է
, իսկ երկրորդը դիսպերսիայով ընդհանուր բնակչությունից է  . Առաջ է քաշվում զրոյական վարկած երկու շեղումների հավասարության մասին, այսինքն. H0:
. Առաջ է քաշվում զրոյական վարկած երկու շեղումների հավասարության մասին, այսինքն. H0:  կամ . Այս վարկածը մերժելու համար անհրաժեշտ է ապացուցել տարբերության նշանակությունը տվյալ նշանակության մակարդակում.
կամ . Այս վարկածը մերժելու համար անհրաժեշտ է ապացուցել տարբերության նշանակությունը տվյալ նշանակության մակարդակում.  .
.
Չափանիշի արժեքը հաշվարկվում է բանաձևով.
Ակնհայտ է, որ եթե շեղումները հավասար են, ապա չափանիշի արժեքը հավասար կլինի մեկի: Այլ դեպքերում այն կլինի մեկից մեծ (պակաս):
Թեստն ունի Fisher բաշխում  . Ֆիշերի թեստ - երկակի թեստ և զրոյական վարկած
. Ֆիշերի թեստ - երկակի թեստ և զրոյական վարկած  մերժվել է հօգուտ այլընտրանքի
մերժվել է հօգուտ այլընտրանքի  Եթե . Ահա, որտեղ
Եթե . Ահա, որտեղ  – համապատասխանաբար առաջին և երկրորդ նմուշների ծավալը.
– համապատասխանաբար առաջին և երկրորդ նմուշների ծավալը.
STATISTICA համակարգը իրականացնում է միակողմանի Fisher թեստ, այսինքն. առավելագույն շեղումը միշտ ընդունվում է որպես որակ: Այս դեպքում զրոյական վարկածը մերժվում է հօգուտ այլընտրանքի, եթե.
Օրինակ
Թող խնդիր դրվի համեմատել ուսանողների երկու խմբի դասավանդման արդյունավետությունը: Ձեռքբերման մակարդակը բնութագրում է ուսումնական գործընթացի կառավարման մակարդակը, իսկ դիսպերսիան ուսուցման կառավարման որակն է, ուսումնական գործընթացի կազմակերպվածության աստիճանը։ Երկու ցուցանիշներն էլ անկախ են և ընդհանուր դեպքպետք է դիտարկել միասին: Ուսանողների յուրաքանչյուր խմբի ակադեմիական կատարողականի մակարդակը (մաթեմատիկական ակնկալիքը) բնութագրվում է թվաբանական միջիններով.  և, և որակը բնութագրվում է գնահատումների համապատասխան ընտրանքային շեղումներով. և . Ներկայիս կատարողականի մակարդակը գնահատելիս պարզվեց, որ երկու ուսանողների համար էլ նույնն է.
և, և որակը բնութագրվում է գնահատումների համապատասխան ընտրանքային շեղումներով. և . Ներկայիս կատարողականի մակարդակը գնահատելիս պարզվեց, որ երկու ուսանողների համար էլ նույնն է.  = = 4.0: Նմուշի տարբերություններ.
= = 4.0: Նմուշի տարբերություններ. 
 Եվ
Եվ  . Այս գնահատականներին համապատասխանող ազատության աստիճանների քանակը.
. Այս գնահատականներին համապատասխանող ազատության աստիճանների քանակը.  Եվ
Եվ  . Այստեղից ուսուցման արդյունավետության տարբերություններ հաստատելու համար մենք կարող ենք օգտագործել ակադեմիական կատարողականի կայունությունը, այսինքն. Եկեք ստուգենք վարկածը.
. Այստեղից ուսուցման արդյունավետության տարբերություններ հաստատելու համար մենք կարող ենք օգտագործել ակադեմիական կատարողականի կայունությունը, այսինքն. Եկեք ստուգենք վարկածը.
Եկեք հաշվարկենք  (համարիչում պետք է լինի մեծ տարբերություն), . Ըստ աղյուսակների ( ՎԻՃԱԿԱԳՐՈՒԹՅՈՒՆ –
ՀավանականությունԲաշխումՀաշվիչ)
մենք գտնում ենք, որը հաշվարկվածից քիչ է, հետևաբար զրոյական վարկածը պետք է մերժվի հօգուտ այլընտրանքի: Այս եզրակացությունը կարող է չբավարարել հետազոտողին, քանի որ նրան հետաքրքրում է հարաբերակցության իրական արժեքը
(համարիչում պետք է լինի մեծ տարբերություն), . Ըստ աղյուսակների ( ՎԻՃԱԿԱԳՐՈՒԹՅՈՒՆ –
ՀավանականությունԲաշխումՀաշվիչ)
մենք գտնում ենք, որը հաշվարկվածից քիչ է, հետևաբար զրոյական վարկածը պետք է մերժվի հօգուտ այլընտրանքի: Այս եզրակացությունը կարող է չբավարարել հետազոտողին, քանի որ նրան հետաքրքրում է հարաբերակցության իրական արժեքը  (մենք միշտ ունենք համարիչի մեծ տարբերություն): Միակողմանի չափանիշը ստուգելիս մենք ստանում ենք, որ ավելի քիչ է, քան վերը հաշվարկված արժեքը: Այսպիսով, զրոյական վարկածը պետք է մերժվի հօգուտ այլընտրանքի։
(մենք միշտ ունենք համարիչի մեծ տարբերություն): Միակողմանի չափանիշը ստուգելիս մենք ստանում ենք, որ ավելի քիչ է, քան վերը հաշվարկված արժեքը: Այսպիսով, զրոյական վարկածը պետք է մերժվի հօգուտ այլընտրանքի։
Ֆիշերի թեստը STATISTICA ծրագրում Windows միջավայրում
Հիպոթեզի փորձարկման օրինակի համար (Fisher չափանիշ) մենք օգտագործում ենք (ստեղծում) ֆայլ երկու փոփոխականներով (fisher.sta).
Բրինձ. 1. Աղյուսակ երկու անկախ փոփոխականներով
Հիպոթեզը ստուգելու համար անհրաժեշտ է հիմնական վիճակագրության մեջ ( ՀիմնականՎիճակագրությունևՍեղաններ) ընտրել t-test անկախ փոփոխականների համար: ( t-test, անկախ, ըստ փոփոխականների).

Բրինձ. 2. Պարամետրային վարկածների ստուգում
Փոփոխականներ ընտրելուց և ստեղնը սեղմելուց հետո ԱմփոփումՍտանդարտ շեղումների արժեքները և Ֆիշերի չափանիշը հաշվարկված են: Բացի այդ, որոշվում է նշանակության մակարդակը էջ, որոնցում տարբերությունն աննշան է։

Բրինձ. 3. Հիպոթեզի փորձարկման արդյունքներ (F-test)
Օգտագործելով ՀավանականությունՀաշվիչև պարամետրերի արժեքները սահմանելով՝ կարող եք կառուցել Fisher բաշխման գրաֆիկ՝ նշված հաշվարկված արժեքով:

Բրինձ. 4. Հիպոթեզի ընդունման (մերժման) տարածք (F-չափանիշ)
Աղբյուրներ.
Երկու շեղումների միջև փոխհարաբերությունների վերաբերյալ վարկածների փորձարկում
URL՝ /tryfonov3/terms3/testdi.htm
Դասախոսություն 6. :8080/resources/math/mop/lections/lection_6.htm
F – Ֆիշերի չափանիշ
URL՝ /home/portal/applications/Multivariatadvisor/F-Fisher/F-Fisheer.htm
Հավանական վիճակագրական հետազոտության տեսություն և պրակտիկա.
URL՝ /active/referats/read/doc-3663-1.html
F – Ֆիշերի չափանիշ
Ֆիշերի չափանիշըթույլ է տալիս համեմատել երկու անկախ նմուշների ընտրանքային տարբերությունները: F emp-ը հաշվարկելու համար պետք է գտնել երկու նմուշների շեղումների հարաբերակցությունը, որպեսզի ավելի մեծ շեղումը լինի համարիչում, իսկ փոքրը՝ հայտարարի մեջ։ Ֆիշերի չափանիշը հաշվարկելու բանաձևը հետևյալն է.
որտեղ են համապատասխանաբար առաջին և երկրորդ նմուշների շեղումները:
Քանի որ, ըստ չափանիշի պայմանների, համարիչի արժեքը պետք է մեծ կամ հավասար լինի հայտարարի արժեքին, F emp-ի արժեքը միշտ կլինի մեկից մեծ կամ հավասար։
Ազատության աստիճանների թիվը նույնպես որոշվում է պարզապես.
կ 1 =n լ - 1 առաջին նմուշի համար (այսինքն այն նմուշի համար, որի շեղումը ավելի մեծ է) և կ 2 = n 2 - 1 երկրորդ նմուշի համար:
Հավելված 1-ում Fisher չափանիշի կրիտիկական արժեքները հայտնաբերվում են k 1 (աղյուսակի վերին տող) և k 2 (աղյուսակի ձախ սյունակ) արժեքներով:
Եթե t em >t crit, ապա զրոյական վարկածն ընդունվում է, հակառակ դեպքում՝ այլընտրանքը։
Օրինակ 3.Թեստավորումն անցկացվել է երկու երրորդ դասարաններում մտավոր զարգացումտասը ուսանող TURMSH թեստի վրա. Ստացված միջին արժեքները էականորեն չեն տարբերվել, բայց հոգեբանին հետաքրքրում է այն հարցը, թե արդյոք դասերի միջև մտավոր զարգացման ցուցանիշների միատարրության աստիճանի տարբերություններ կան:
Լուծում. Ֆիշերի թեստի համար անհրաժեշտ է համեմատել թեստի միավորների շեղումները երկու դասերում: Թեստի արդյունքները ներկայացված են աղյուսակում.
Աղյուսակ 3.
|
Ուսանողների համարներ |
Առաջին դասարան |
Երկրորդ դաս |
Հաշվարկելով X և Y փոփոխականների շեղումները՝ մենք ստանում ենք.
ս x 2 =572,83; ս y 2 =174,04
Այնուհետև, օգտագործելով (8) բանաձևը Fisher-ի F չափանիշով հաշվարկելու համար, մենք գտնում ենք.
![]()
Համաձայն Հավելված 1-ի աղյուսակի F չափանիշի ազատության աստիճաններով երկու դեպքում էլ հավասար են k = 10 - 1 = 9, մենք գտնում ենք F crit = 3.18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Ոչ պարամետրիկ թեստեր
Աչքով (տոկոսներով) համեմատելով արդյունքները ցանկացած ազդեցությունից առաջ և հետո՝ հետազոտողը գալիս է այն եզրակացության, որ եթե տարբերություններ են նկատվում, ապա համեմատվող նմուշների տարբերություն կա։ Այս մոտեցումը կտրականապես անընդունելի է, քանի որ տոկոսներով անհնար է որոշել տարբերությունների հուսալիության մակարդակը։ Ինքնուրույն վերցված տոկոսները հնարավորություն չեն տալիս վիճակագրորեն հավաստի եզրակացություններ անել։ Ցանկացած միջամտության արդյունավետությունն ապացուցելու համար անհրաժեշտ է բացահայտել ցուցանիշների կողմնակալության (հերթափոխի) վիճակագրորեն նշանակալի միտում: Նման խնդիրներ լուծելու համար հետազոտողը կարող է օգտագործել խտրականության մի շարք չափանիշներ։ Ստորև մենք կդիտարկենք ոչ պարամետրական թեստերը` նշանի թեստը և chi-square թեստը:
)φ* չափանիշի հաշվարկ
1. Որոշեք հատկանիշի այն արժեքները, որոնք չափորոշիչ կլինեն առարկաները բաժանելու համար նրանց, ովքեր «ազդեցություն ունեն» և նրանց, ովքեր «ազդեցություն չունեն»: Եթե բնութագիրը չափվում է քանակապես, ապա օգտագործեք λ չափանիշը՝ գտնելու օպտիմալ տարանջատման կետը:
2. Գծե՛ք երկու սյունակներից և երկու տողերից բաղկացած չորս բջիջներից բաղկացած աղյուսակ (հոմանիշ՝ չորս դաշտ): Առաջին սյունակը «էֆեկտ կա»; երկրորդ սյունակ - «ոչ մի ազդեցություն»; առաջին տողը վերևից - 1 խումբ (նմուշ); երկրորդ տող - խումբ 2 (նմուշ):
4. Հաշվեք առաջին նմուշի առարկաների թիվը, որոնք «ոչ մի ազդեցություն չունեն» և մուտքագրեք այս թիվը աղյուսակի վերին աջ բջիջում: Հաշվեք վերևի երկու բջիջների գումարը: Այն պետք է համընկնի առաջին խմբի առարկաների քանակի հետ:
6. Հաշվեք երկրորդ նմուշի այն առարկաների թիվը, որոնք «ոչ մի ազդեցություն» չունեն և մուտքագրեք այս թիվը աղյուսակի ստորին աջ բջիջում: Հաշվիր երկու ստորին բջիջների գումարը: Այն պետք է համընկնի երկրորդ խմբի (նմուշի) առարկաների թվի հետ:
7. Որոշեք «ազդեցություն ունեցող» առարկաների տոկոսը` նրանց թիվը կապելով տվյալ խմբի առարկաների ընդհանուր թվի հետ (նմուշ): Ստացված տոկոսները գրե՛ք աղյուսակի վերին ձախ և ներքևի ձախ վանդակներում, համապատասխանաբար փակագծերում, որպեսզի դրանք չշփոթեք բացարձակ արժեքների հետ։
8. Ստուգեք, թե արդյոք համեմատվող տոկոսներից մեկը հավասար է զրոյի: Եթե դա այդպես է, փորձեք փոխել սա՝ տեղափոխելով խմբի բաժանման կետը այս կամ այն ուղղությամբ: Եթե դա անհնար է կամ անցանկալի, հրաժարվեք φ* չափանիշից և օգտագործեք χ2 չափանիշը։
9. Որոշի՛ր ըստ աղյուսակի. XII Հավելված 1 անկյուններ φ համեմատվող տոկոսներից յուրաքանչյուրի համար:
որտեղ: φ1 - ավելի մեծ տոկոսին համապատասխանող անկյուն;
φ2 - ավելի փոքր տոկոսին համապատասխանող անկյուն;
N1 - 1-ին նմուշի դիտարկումների քանակը;
N2 - 2-րդ նմուշի դիտարկումների թիվը:
11. Ստացված φ* արժեքը համեմատե՛ք կրիտիկական արժեքների հետ՝ φ* ≤1,64 (p.<0,05) и φ* ≤2,31 (р<0,01).
Եթե φ*emp ≤φ*cr. Հ0-ն մերժվում է.
Անհրաժեշտության դեպքում որոշեք ստացված φ*emp-ի նշանակության ճշգրիտ մակարդակը՝ համաձայն Աղյուսակի: XIII Հավելված 1.
Այս մեթոդը նկարագրված է բազմաթիվ ձեռնարկներում (Plohinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992 և այլն): Այս նկարագրությունը հիմնված է մեթոդի այն տարբերակի վրա, որը մշակվել և ներկայացվել է Է.Վ. Գուբլեր.
Չափանիշի նպատակը φ*
Ֆիշերի չափանիշը նպատակ ունի համեմատել երկու նմուշներ՝ ըստ հետազոտողին հետաքրքրող էֆեկտի (ցուցանիշի) առաջացման հաճախականության: Որքան մեծ է այն, այնքան ավելի հուսալի են տարբերությունները:
Չափանիշի նկարագրությունը
Չափանիշը գնահատում է երկու նմուշների այն տոկոսների միջև եղած տարբերությունների հուսալիությունը, որոնցում գրանցվել է մեզ հետաքրքրող ազդեցությունը (ցուցանիշը): Պատկերավոր ասած, մենք համեմատում ենք 2 կարկանդակից կտրված 2 լավագույն կտորները և որոշում, թե որն է իսկապես ավելի մեծ:
Ֆիշերի անկյունային փոխակերպման էությունը տոկոսների վերածելն է կենտրոնական անկյան արժեքների, որոնք չափվում են ռադիաններով: Ավելի մեծ տոկոսը կհամապատասխանի ավելի մեծ անկյան φ, իսկ ավելի փոքր տոկոսը կհամապատասխանի ավելի փոքր անկյան, բայց այստեղ հարաբերությունները գծային չեն.
որտեղ P-ն միավորի կոտորակներով արտահայտված տոկոսն է (տես նկ. 5.1):
Ֆ անկյունների միջև աճող անհամապատասխանությամբ 1 և φ 2 իսկ նմուշների քանակն ավելացնելով՝ չափանիշի արժեքը մեծանում է։ Որքան մեծ է φ*-ի արժեքը, այնքան մեծ է հավանականությունը, որ տարբերությունները նշանակալի են:
Վարկածներ
Հ 0 : Անձանց համամասնությունը, որում դրսևորվում է ուսումնասիրված էֆեկտը, նմուշ 1-ում ավելին չկա, քան 2-րդ նմուշում:
Հ 1 Ուսումնասիրված ազդեցություն ցուցաբերած անհատների մասնաբաժինը նմուշ 1-ում ավելի մեծ է, քան նմուշ 2-ում:
Չափանիշի գրաֆիկական ներկայացում φ*
Անկյունային փոխակերպման մեթոդը որոշ չափով ավելի վերացական է, քան մյուս չափանիշները:
Ֆ-ի արժեքները հաշվարկելիս E.V. Gubler-ի հետևած բանաձևը ենթադրում է, որ 100%-ը կազմում է անկյուն φ=3,142, այսինքն՝ կլորացված արժեք π=3,14159... Սա թույլ է տալիս համեմատվող նմուշները ներկայացնել՝ երկու կիսաշրջան, որոնցից յուրաքանչյուրը խորհրդանշում է իր ընտրանքի բնակչության 100%-ը: «Էֆեկտ» ունեցող առարկաների տոկոսները կներկայացվեն որպես φ կենտրոնական անկյուններով ձևավորված հատվածներ: Նկ. Նկար 5.2-ը ցույց է տալիս օրինակ 1-ին պատկերող երկու կիսաշրջան: Առաջին նմուշում առարկաների 60%-ը լուծել է խնդիրը: Այս տոկոսը համապատասխանում է φ=1,772 անկյունին։ Երկրորդ ընտրանքում առարկաների 40%-ը լուծել է խնդիրը։ Այս տոկոսը համապատասխանում է φ =1,369 անկյունին:
Φ* չափանիշը թույլ է տալիս որոշել, թե արդյոք անկյուններից մեկն իրոք վիճակագրորեն զգալիորեն գերազանցում է մյուսին տվյալ նմուշի չափերի համար:
Չափանիշի սահմանափակումները φ*
1. Համեմատվող համամասնություններից ոչ մեկը չպետք է զրո լինի: Ֆորմալ կերպով, φ մեթոդի կիրառման խոչընդոտներ չկան այն դեպքերում, երբ նմուշներից մեկում դիտարկումների համամասնությունը հավասար է 0-ի: Այնուամենայնիվ, այս դեպքերում արդյունքը կարող է անհիմն կերպով ուռճացված լինել (Gubler E.V., 1978, p. 86):
2. Վերին φ չափանիշում սահմանափակում չկա. նմուշները կարող են լինել այնքան մեծ, որքան ցանկանում եք:
Ավելի ցածր սահմանաչափ - 2 դիտարկում նմուշներից մեկում: Այնուամենայնիվ, երկու նմուշների քանակով պետք է պահպանվեն հետևյալ հարաբերակցությունները.
ա) եթե մեկ նմուշ ունի ընդամենը 2 դիտարկում, ապա երկրորդը պետք է ունենա առնվազն 30.
բ) եթե նմուշներից մեկն ունի ընդամենը 3 դիտարկում, ապա երկրորդը պետք է ունենա առնվազն 7.
գ) եթե նմուշներից մեկն ունի ընդամենը 4 դիտարկում, ապա երկրորդը պետք է ունենա առնվազն 5.
դ) ժամըn 1 , n 2 ≥ 5 Հնարավոր են ցանկացած համեմատություն։
Սկզբունքորեն կարելի է նաև համեմատել այս պայմանին չբավարարող նմուշները, օրինակ, հարաբերության հետn 1 =2, n 2 = 15, սակայն այս դեպքերում հնարավոր չի լինի բացահայտել էական տարբերությունները:
φ* չափանիշն այլ սահմանափակումներ չունի։
Դիտարկենք մի քանի օրինակ՝ հնարավորությունները լուսաբանելու համարչափանիշ φ*.
Օրինակ 1. նմուշների համեմատություն ըստ որակապես սահմանված բնութագրի:
Օրինակ 2. նմուշների համեմատություն ըստ քանակական չափված բնութագրի:
Օրինակ 3. Նմուշների համեմատությունը և ըստ մակարդակի, և ըստ բնութագրիչի բաշխման:
Օրինակ 4. Օգտագործելով φ* չափանիշը չափանիշի հետ համատեղX Կոլմոգորով-Սմիրնով՝ առավել ճշգրիտ արդյունքի հասնելու համար։
Օրինակ 1 - նմուշների համեմատություն ըստ որակապես որոշված բնութագրի
Չափանիշի այս կիրառման ժամանակ մենք համեմատում ենք մի ընտրանքի առարկաների տոկոսը, որը բնութագրվում է որոշակի որակով, մյուս ընտրանքում նույն որակով բնութագրվող առարկաների տոկոսի հետ:
Ենթադրենք, մեզ հետաքրքրում է, թե արդյո՞ք ուսանողների երկու խմբերը տարբերվում են իրենց հաջողությամբ նոր փորձարարական խնդրի լուծման հարցում։ Առաջին 20 հոգանոց խմբում դրան դիմակայել է 12 հոգի, իսկ 25 հոգուց բաղկացած երկրորդ ընտրանքում՝ 10։ Առաջին դեպքում խնդիրը լուծողների տոկոսը կկազմի 12/20·100%=60%։ իսկ երկրորդում 10/25·100%= 40%. Արդյո՞ք այս տոկոսները էապես տարբերվում են՝ հաշվի առնելով տվյալները:n 1 Եվn 2 ?
Թվում է, թե նույնիսկ «աչքով» կարելի է որոշել, որ 60%-ը զգալիորեն բարձր է 40%-ից։ Սակայն, ըստ էության, այդ տարբերությունները, հաշվի առնելով տվյալներըn 1 , n 2 անվստահելի.
Եկեք ստուգենք այն: Քանի որ մեզ հետաքրքրում է խնդրի լուծման փաստը, փորձարարական խնդրի լուծման հաջողությունը մենք կդիտարկենք որպես «էֆեկտ», իսկ ձախողումը դրա լուծման մեջ որպես էֆեկտի բացակայություն:
Ձևակերպենք վարկածներ.
Հ 0 : Անձանց համամասնությունըԱռաջին խմբում առաջադրանքն ավարտածներն ավելի շատ չեն եղել, քան երկրորդ խմբում:
Հ 1 Առաջին խմբում առաջադրանքն ավարտած մարդկանց մասնաբաժինը ավելի մեծ է, քան երկրորդ խմբում:
Հիմա եկեք կառուցենք այսպես կոչված չորս բջիջ կամ չորս դաշտային աղյուսակ, որն իրականում էմպիրիկ հաճախականությունների աղյուսակ է հատկանիշի երկու արժեքների համար. «էֆեկտ կա» - «էֆեկտ չկա»:
Աղյուսակ 5.1
Չորս բջջային աղյուսակ՝ չափանիշը հաշվարկելու համար առարկաների երկու խմբերը համեմատելիս՝ ըստ խնդիրը լուծողների տոկոսի։
Խմբեր | «Ազդեցություն կա». խնդիրը լուծված է | «Ոչ մի էֆեկտ». խնդիրը լուծված չէ | Գումարներ |
||||
Քանակ առարկաներ | % կիսվել | Քանակ առարկաներ | % բաժնեմաս | ||||
1 խումբ | (60%) | (40%) | |||||
2-րդ խումբ | (40%) | (60%) | |||||
Գումարներ | |||||||
Չորս բջիջներից բաղկացած աղյուսակում, որպես կանոն, վերևում նշվում են «Կա էֆեկտ» և «Ոչ մի էֆեկտ» սյունակները, իսկ ձախում՝ «Խումբ 1» և «Խումբ 2» տողերը: Փաստորեն, համեմատությունների մեջ ներգրավված են միայն A և B դաշտերը (բջիջները), այսինքն՝ տոկոսները «Ազդեցություն կա» սյունակում:
Աղյուսակի համաձայն.XIIՀավելված 1-ը սահմանում է φ-ի արժեքները, որոնք համապատասխանում են խմբերից յուրաքանչյուրի տոկոսային բաժիններին:
Հիմա եկեք հաշվարկենք φ*-ի էմպիրիկ արժեքը՝ օգտագործելով բանաձևը.
որտեղ φ 1 - ավելի մեծ տոկոս մասնաբաժինին համապատասխանող անկյուն;
φ 2 - ավելի փոքր տոկոս մասնաբաժինին համապատասխանող անկյուն;
n 1 - Նմուշ 1-ում դիտարկումների քանակը;
n 2 - 2-րդ նմուշի դիտարկումների քանակը:
Այս դեպքում:
Աղյուսակի համաձայն.XIIIՀավելված 1-ում մենք որոշում ենք, թե նշանակության ինչ մակարդակ է համապատասխանում φ* em=1,34:
p=0.09
Հնարավոր է նաև սահմանել φ*-ի կրիտիկական արժեքներ, որոնք համապատասխանում են հոգեբանության մեջ ընդունված մակարդակներին վիճակագրական նշանակություն:
Կառուցենք «նշանակության առանցք».
Ստացված φ* էմպիրիկ արժեքը գտնվում է աննշանության գոտում։
Պատասխան. Հ 0 ընդունված. Մարդկանց տոկոսը, ովքեր կատարել են առաջադրանքըՎառաջին խմբում ոչ ավելի, քան երկրորդ խմբում:
Կարելի է միայն համակրել մի հետազոտողի, ով 20% և նույնիսկ 10% տարբերությունները էական է համարում` չստուգելով դրանց հուսալիությունը` օգտագործելով φ* չափանիշը: Այս դեպքում, օրինակ, էական կլիներ միայն առնվազն 24,3 տոկոսի տարբերությունը։
Թվում է, թե երբ համեմատում ենք երկու նմուշ ցանկացած որակական հիմքի վրա, φ չափանիշը կարող է մեզ ավելի շուտ տխրեցնել, քան ուրախացնել: Այն, ինչ նշանակալի էր թվում, վիճակագրական տեսակետից կարող է այդպես չլինել:
Ֆիշերի չափանիշը շատ ավելի մեծ հնարավորություններ ունի հաճեցնելու հետազոտողին, երբ մենք համեմատում ենք երկու նմուշներ՝ ըստ քանակական չափված բնութագրերի և կարող է փոփոխել «ազդեցությունը»:
Օրինակ 2 - երկու նմուշների համեմատություն ըստ քանակական չափված բնութագրի
Չափանիշի այս կիրառման ժամանակ մենք համեմատում ենք մի նմուշի այն առարկաների տոկոսը, ովքեր հասնում են հատկանիշի արժեքի որոշակի մակարդակի, այն առարկաների տոկոսի հետ, ովքեր հասնում են այս մակարդակին մեկ այլ նմուշում:
Տլեգենովայի (1990) ուսումնասիրության մեջ 14-ից 16 տարեկան մասնագիտական դպրոցի 70 երիտասարդ ուսանողներից արդյունքների հիման վրա ընտրվել են ագրեսիվության սանդղակով բարձր գնահատականներով 10 առարկաներ և ագրեսիայի սանդղակով ցածր միավորներով 11 առարկաներ: Ֆրայբուրգի Անհատականության Հարցաթերթիկի օգտագործմամբ հարցում: Պետք է պարզել, թե արդյոք ագրեսիվ և ոչ ագրեսիվ երիտասարդների խմբերը տարբերվում են համակուրսեցիների հետ զրույցի ընթացքում ինքնաբուխ ընտրած հեռավորության առումով: Գ.Ա.Տլեգենովայի տվյալները ներկայացված են Աղյուսակում: 5.2. Դուք կարող եք նկատել, որ ագրեսիվ երիտասարդներն ավելի հաճախ ընտրում են 50 հեռավորությունսմ կամ նույնիսկ ավելի քիչ, մինչդեռ ոչ ագրեսիվ տղաներն ավելի հաճախ ընտրում են 50 սմ-ից մեծ հեռավորություն։
Այժմ մենք կարող ենք 50 սմ հեռավորությունը համարել կրիտիկական և ենթադրել, որ եթե առարկայի ընտրած հեռավորությունը փոքր է կամ հավասար է 50 սմ-ին, ապա «էֆեկտ կա», և եթե ընտրված հեռավորությունը 50 սմ-ից մեծ է, ապա. «Ոչ մի ազդեցություն չկա». Մենք տեսնում ենք, որ ագրեսիվ երիտասարդների խմբում էֆեկտը նկատվում է 10-ից 7-ի դեպքում, այսինքն՝ դեպքերի 70%-ում, իսկ ոչ ագրեսիվ երիտասարդների խմբում՝ 11-ից 2-ում, այսինքն՝ դեպքերի 18,2%-ում։ . Այս տոկոսները կարելի է համեմատել՝ օգտագործելով φ* մեթոդը՝ դրանց միջև եղած տարբերությունների նշանակությունը հաստատելու համար:
Աղյուսակ 5.2
Ագրեսիվ և ոչ ագրեսիվ երիտասարդների կողմից ընտրված հեռավորության ցուցիչները (սմ-ով)՝ ընկերակցի հետ զրույցում (ըստ Գ.Ա. Տլեգենովայի, 1990 թ.)
Խումբ 1. Ագրեսիայի սանդղակով բարձր միավորներ ունեցող տղաներFPI- Ռ (n 1 =10) | Խումբ 2. ագրեսիայի սանդղակի ցածր արժեք ունեցող տղաներFPI- Ռ (n 2 =11) |
|||
դ (ք մ ) | % բաժնեմաս | դ (ք Մ ) | % բաժնեմաս |
|
«Կերեք Էֆեկտ» դ≤50 սմ | ||||
18,2% |
||||
«Ոչ ազդեցություն» դ> 50սմ | ||||
80 QO | 81,8% |
|||
Գումարներ | 100% | 100% |
||
Միջին | 5b:o | 77.3 | ||
Ձևակերպենք վարկածներ.
Հ 0 դ ≤ 50 սմ, ագրեսիվ տղաների խմբում չկա ավելին, քան ոչ ագրեսիվ տղաների խմբում։
Հ 1 Մարդկանց համամասնությունը, ովքեր ընտրում են հեռավորությունըդ≤ 50 սմ, ավելի շատ ագրեսիվ երիտասարդների խմբում, քան ոչ ագրեսիվ երիտասարդների խմբում։ Հիմա եկեք կառուցենք այսպես կոչված չորս բջիջների աղյուսակ:
Աղյուսակ 53
Չորս բջջային աղյուսակ՝ φ* չափանիշը ագրեսիվների խմբերը համեմատելու համար (nf=10) և ոչ ագրեսիվ երիտասարդ տղամարդիկ (n2=11)
Խմբեր | «Ազդեցություն կա». դ≤50 | «Ոչ մի ազդեցություն». դ>50 | Գումարներ |
||||
Առարկաների թիվը | (% մասնաբաժին) | Առարկաների թիվը | (% մասնաբաժին) | ||||
Խումբ 1 - ագրեսիվ երիտասարդներ | (70%) | (30%) | |||||
Խումբ 2 - ոչ ագրեսիվ երիտասարդներ | (180%) | (81,8%) | |||||
Գումար | |||||||
Աղյուսակի համաձայն.XIIՀավելված 1-ը սահմանում է φ-ի արժեքները, որոնք համապատասխանում են խմբերից յուրաքանչյուրում «ազդեցության» տոկոսային բաժիններին:
Ստացված φ* էմպիրիկ արժեքը գտնվում է նշանակության գոտում։
Պատասխան. Հ 0 մերժվել է. Ընդունված էՀ 1 . Մարդկանց մասնաբաժինը, ովքեր զրույցի ընթացքում ընտրում են 50 սմ-ից պակաս կամ հավասար հեռավորություն, ավելի մեծ է ագրեսիվ երիտասարդների խմբում, քան ոչ ագրեսիվ երիտասարդների խմբում:
Ստացված արդյունքների հիման վրա կարող ենք եզրակացնել, որ ավելի ագրեսիվ երիտասարդներն ավելի հաճախ ընտրում են կես մետրից պակաս հեռավորություն, իսկ ոչ ագրեսիվ երիտասարդներն ավելի հաճախ՝ կես մետրից ավելի: Մենք տեսնում ենք, որ ագրեսիվ երիտասարդները իրականում շփվում են ինտիմ (0-46 սմ) և անձնական (46 սմ-ից) գոտիների սահմանին: Այնուամենայնիվ, մենք հիշում ենք, որ գործընկերների միջև ինտիմ հեռավորությունը ոչ միայն մտերիմ, լավ հարաբերությունների, այլև արտոնությունն է.Եվձեռնամարտ (ԴահլիճԵ. Տ., 1959).
Օրինակ 3 - նմուշների համեմատություն և ըստ մակարդակի, և ըստ բնութագրի բաշխման:
Օգտագործման այս դեպքում մենք կարող ենք նախ ստուգել, թե արդյոք խմբերը տարբերվում են որոշ հատկանիշի մակարդակներում, ապա համեմատել հատկանիշի բաշխվածությունը երկու նմուշներում: Նման առաջադրանքը կարող է տեղին լինել ցանկացած նոր տեխնիկայի օգտագործմամբ առարկաների կողմից ստացված գնահատականների բաշխման միջակայքերի կամ ձևի տարբերությունները վերլուծելիս:
Ռ. Տ. Չիրկինայի (1995 թ.) կատարած ուսումնասիրության մեջ առաջին անգամ օգտագործվել է հարցաթերթ, որն ուղղված է եղել անձնական, ընտանեկան և մասնագիտական բարդույթների պատճառով հիշողությամբ ճնշելու փաստերը, անունները, մտադրությունները և գործողությունների մեթոդները ճնշելու միտումը: Հարցաթերթիկը ստեղծվել է Է.Վ.Սիդորենկոյի մասնակցությամբ՝ հիմնվելով 3. Ֆրեյդի «Առօրյա կյանքի հոգեախտաբանություն» գրքի նյութերի վրա: Մանկավարժական ինստիտուտի չամուսնացած, առանց երեխաների, 17-ից 20 տարեկան 50 ուսանողների ընտրանքը հետազոտվել է այս հարցաշարի, ինչպես նաև Menester-Corzini տեխնիկայի միջոցով՝ պարզելու անձնական անբավարարության զգացողության ինտենսիվությունը,կամ"անլիարժեքության կոմպլեքս" (ՄանասթերԳ. Ջ., ԿորսինիՌ. Ջ., 1982).
Հարցման արդյունքները ներկայացված են Աղյուսակում: 5.4.
Կարելի՞ է ասել, որ կա որևէ էական կապ հարցաթերթիկի միջոցով ախտորոշված ռեպրեսիոն էներգիայի ցուցիչի և սեփական անբավարարության զգացողության ինտենսիվության ցուցիչների միջև:
Աղյուսակ 5.4
Անձնական անբավարարության զգացումների ինտենսիվության ցուցիչները ուսանողների խմբերում բարձր (ժ=18) և ցածր (n2=24) տեղաշարժման էներգիա
Խումբ 1. տեղաշարժման էներգիա 19-ից մինչև 31 միավոր (n 1 =181 | Խումբ 2. տեղաշարժի էներգիա 7-ից 13 բալ (n 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
Գումարներ Միջին | 26,11 | 15,42 |
Չնայած այն հանգամանքին, որ ավելի էներգետիկ ռեպրեսիաներ ունեցող խմբում միջին արժեքը ավելի բարձր է, դրանում նկատվում է նաև 5 զրոյական արժեք։ Եթե համեմատենք երկու նմուշներում վարկանիշների բաշխման հիստոգրամները, ապա նրանց միջև բացահայտվում է ապշեցուցիչ հակադրություն (նկ. 5.3):
Երկու բաշխումները համեմատելու համար մենք կարող ենք կիրառել թեստըχ 2 կամ չափանիշλ , բայց դրա համար մենք պետք է ընդլայնենք շարքերը, և բացի այդ, երկու նմուշներում էլn <30.
Φ* չափանիշը թույլ կտա մեզ ստուգել գրաֆիկում նկատված երկու բաշխումների միջև անհամապատասխանության ազդեցությունը, եթե համաձայնվենք ենթադրել, որ «էֆեկտ կա», եթե անբավարարության զգացողության ցուցանիշը կա՛մ շատ ցածր է (0), կա՛մ հակառակը։ , շատ բարձր արժեքներ (Ս30), և որ «ոչ մի ազդեցություն չկա», եթե անբավարարության զգացողության ցուցանիշը միջին արժեքներ է ստանում՝ 5-ից մինչև 25:
Ձևակերպենք վարկածներ.
Հ 0 : Ավելի էներգետիկ ռեպրեսիա ունեցող խմբում անբավարարության ինդեքսի ծայրահեղ արժեքները (կամ 0 կամ 30 կամ ավելի) ավելի տարածված չեն, քան ավելի քիչ էներգետիկ ռեպրեսիա ունեցող խմբում:
Հ 1 : Անբավարարության ինդեքսի ծայրահեղ արժեքները (կամ 0 կամ 30 կամ ավելի) ավելի էներգետիկ ռեպրեսիա ունեցող խմբում ավելի տարածված են, քան ավելի քիչ էներգետիկ ռեպրեսիա ունեցող խմբում:
Եկեք ստեղծենք չորս բջիջներից բաղկացած աղյուսակ, որը հարմար է φ* չափանիշի հետագա հաշվարկի համար։
Աղյուսակ 5.5
Չորս բջջային աղյուսակ՝ φ* չափանիշը հաշվարկելու համար, երբ համեմատում ենք ավելի բարձր և ցածր ռեպրեսիոն էներգիայով խմբերը՝ հիմնված անբավարարության ցուցանիշների հարաբերակցության վրա
Խմբեր | «Ազդեցություն կա». դեֆիցիտի ցուցանիշը 0 է կամ >30 | «Ոչ մի ազդեցություն»՝ ձախողման ինդեքսը 5-ից 25 | Գումարներ |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
Գումարներ | |||||
Աղյուսակի համաձայն.XIIՀավելված 1-ում մենք որոշում ենք φ-ի արժեքները, որոնք համապատասխանում են համեմատվող տոկոսներին.
Եկեք հաշվարկենք φ*-ի էմպիրիկ արժեքը.
φ*-ի կրիտիկական արժեքները ցանկացածի համարn 1 , n 2 , ինչպես հիշում ենք նախորդ օրինակից, հետևյալն են.
ԱղյուսակXIIIՀավելված 1-ը թույլ է տալիս ավելի ճշգրիտ որոշել ստացված արդյունքի նշանակալիության մակարդակը՝ p<0,001.
Պատասխան. Հ 0 մերժվել է. Ընդունված էՀ 1 . Ավելի մեծ ռեպրեսիոն էներգիա ունեցող խմբում դեֆիցիտի ինդեքսի ծայրահեղ արժեքները (կամ 0 կամ 30 կամ ավելի) տեղի են ունենում ավելի հաճախ, քան ավելի քիչ ռեպրեսիոն էներգիա ունեցող խմբում:
Այսպիսով, ավելի մեծ ռեպրեսիոն էներգիա ունեցող սուբյեկտները կարող են ունենալ սեփական անբավարարության զգացման և՛ շատ բարձր (30 և ավելի), և՛ շատ ցածր (զրո) ցուցանիշներ։ Կարելի է ենթադրել, որ նրանք ճնշում են ինչպես իրենց դժգոհությունը, այնպես էլ կյանքում հաջողության հասնելու անհրաժեշտությունը։ Այս ենթադրությունները լրացուցիչ փորձարկման կարիք ունեն:
Ստացված արդյունքը, անկախ իր մեկնաբանությունից, հաստատում է φ* չափանիշի հնարավորությունները երկու նմուշներում հատկանիշի բաշխման ձևի տարբերությունները գնահատելու հարցում։
Նախնական ընտրանքում կար 50 մարդ, սակայն նրանցից 8-ը բացառվեցին որպես ռեպրեսիոն աներգիայի ինդեքսի միջին գնահատական (14-15): Անբավարարության զգացումների ինտենսիվության նրանց ցուցանիշները նույնպես միջին են՝ 6 արժեք՝ յուրաքանչյուրը 20 միավորով և 2 արժեք՝ յուրաքանչյուրը 25 միավոր։
φ* չափանիշի հզոր հնարավորությունները կարելի է ստուգել՝ հաստատելով բոլորովին այլ վարկած այս օրինակի նյութերը վերլուծելիս։ Մենք կարող ենք ապացուցել, օրինակ, որ ավելի մեծ ռեպրեսիոն էներգիա ունեցող խմբում անբավարարության մակարդակը դեռ ավելի բարձր է, չնայած այս խմբում դրա բաշխման պարադոքսալ բնույթին:
Ձևակերպենք նոր վարկածներ.
Հ 0 Ավելի մեծ ռեպրեսիոն էներգիա ունեցող խմբում դեֆիցիտի ինդեքսի ամենաբարձր արժեքները (30 և ավելի) ավելի տարածված չեն, քան ավելի քիչ ռեպրեսիոն էներգիա ունեցող խմբում:
Հ 1 : Ավելի մեծ ռեպրեսիոն էներգիա ունեցող խմբում դեֆիցիտի ինդեքսի ամենաբարձր արժեքները (30 և ավելի) տեղի են ունենում ավելի հաճախ, քան ավելի քիչ ռեպրեսիոն էներգիա ունեցող խմբում: Եկեք կառուցենք չորս դաշտային աղյուսակ՝ օգտագործելով Աղյուսակի տվյալները: 5.4.
Աղյուսակ 5.6
Չորս բջջային աղյուսակ՝ φ* չափանիշը հաշվարկելու համար՝ ըստ անբավարարության ցուցիչի մակարդակի, ավելի մեծ և փոքր ռեպրեսիոն էներգիա ունեցող խմբերը համեմատելու համար
Խմբեր | «Ազդեցություն կա»* ձախողման ցուցիչը մեծ է կամ հավասար է 30-ի | «Ոչ մի ազդեցություն». ձախողման մակարդակն ավելի ցածր է 30 | Գումարներ |
||
Խումբ 1 - ավելի մեծ տեղաշարժի էներգիայով | (61,1%) | (38.9%) | |||
Խումբ 2 - ավելի ցածր տեղաշարժի էներգիայով | (25.0%) | (75.0%) | |||
Գումարներ | |||||
Աղյուսակի համաձայն.XIIIՀավելված 1-ում մենք որոշում ենք, որ այս արդյունքը համապատասխանում է p = 0,008 նշանակության մակարդակին:
Պատասխան. Բայց դա մերժվում է։ Ընդունված էՀժԹերիության ամենաբարձր ցուցանիշները (30 և ավելի միավոր) խմբումՀետավելի մեծ տեղաշարժի էներգիայով տեղի են ունենում ավելի հաճախ, քան ավելի քիչ տեղաշարժման էներգիա ունեցող խմբում (p = 0,008):
Այսպիսով, մենք կարողացանք դա ապացուցելՎխումբՀետավելի էներգետիկ ռեպրեսիաների դեպքում գերակշռում են անբավարարության ցուցիչի ծայրահեղ արժեքները, և այն, որ այս ցուցանիշը գերազանցում է իր արժեքները.հասնում էհենց այս խմբում:
Այժմ մենք կարող ենք փորձել ապացուցել, որ ավելի բարձր ռեպրեսիոն էներգիա ունեցող խմբում ավելի տարածված են անբավարարության ինդեքսի ավելի ցածր արժեքները, չնայած այն հանգամանքին, որ միջին արժեքըՎ այս խումբն ունի ավելի շատ (26.11՝ խմբում 15.42-ի դիմացՀետ ավելի քիչ տեղաշարժ):
Ձևակերպենք վարկածներ.
Հ 0 Խմբում անբավարարության ամենացածր ցուցանիշները (զրո):Հետ ավելի մեծ էներգիայով ռեպրեսիաները ավելի տարածված չեն, քան խմբումՀետ ավելի քիչ տեղաշարժի էներգիա:
Հ 1 Անբավարարության ամենացածր ցուցանիշները (զրո):Վ ավելի մեծ ռեպրեսիայի էներգիա ունեցող խումբ ավելի հաճախ, քան խմբումՀետ ավելի քիչ էներգետիկ ռեպրեսիա: Եկեք խմբավորենք տվյալները նոր չորս բջջային աղյուսակի մեջ:
Աղյուսակ 5.7
Չորս բջջային աղյուսակ՝ տարբեր ռեպրեսիոն էներգիայով խմբերի համեմատության համար՝ հիմնված անբավարարության ցուցիչի զրոյական արժեքների հաճախականության վրա
Խմբեր | «Ազդեցություն կա». ձախողման ցուցիչը 0 է | Անբավարարության «ոչ մի ազդեցություն». | ցուցանիշը հավասար չէ 0-ի | Գումարներ |
|
Խումբ 1 - ավելի մեծ տեղաշարժի էներգիայով | (27,8%) | (72,2%) | |||
1 խումբ - ավելի քիչ տեղաշարժի էներգիայով | (8,3%) | (91,7%) | |||
Գումարներ | |||||
Մենք որոշում ենք φ-ի արժեքները և հաշվարկում ենք φ*-ի արժեքը.
Պատասխան. Հ 0 մերժվել է. Անբավարարության ամենացածր ցուցանիշները (զրո) ավելի մեծ ռեպրեսիոն էներգիա ունեցող խմբում ավելի տարածված են, քան ավելի քիչ ռեպրեսիոն էներգիա ունեցող խմբում (p.<0,05).
Ընդհանուր առմամբ, ստացված արդյունքները կարելի է համարել որպես Ս. Ֆրեյդի և Ա. Ադլերի բարդ հասկացությունների մասնակի համընկնման վկայություն:
Հատկանշական է, որ ռեպրեսիոն էներգիայի ցուցիչի և ամբողջ նմուշում սեփական անբավարարության զգացողության ինտենսիվության ցուցիչի միջև ստացվել է դրական գծային հարաբերակցություն (p = +0.491, p.<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Օրինակ 4 - օգտագործելով φ* չափանիշը չափանիշի հետ համատեղ λ Կոլմոգորով-Սմիրնով առավելագույնին հասնելու համար ճշգրիտարդյունք
Եթե նմուշները համեմատվում են ըստ քանակական չափված որևէ ցուցիչի, խնդիր է առաջանում որոշել բաշխման կետը, որը կարող է օգտագործվել որպես կրիտիկական կետ՝ բոլոր առարկաները «ազդեցություն ունեցողների» և «ոչ ազդեցություն ունեցողների» բաժանելու համար:
Սկզբունքորեն, այն կետը, երբ մենք խումբը կբաժանենք ենթախմբերի, որտեղ կա ազդեցություն և որտեղ չկա ազդեցություն, կարող է ընտրվել միանգամայն կամայական: Մեզ կարող է հետաքրքրել ցանկացած էֆեկտ, և, հետևաբար, մենք կարող ենք ցանկացած պահի երկու նմուշները բաժանել երկու մասի, քանի դեռ դա որոշակի իմաստ ունի:
Ֆ* թեստի հզորությունը առավելագույնի հասցնելու համար, այնուամենայնիվ, անհրաժեշտ է ընտրել այն կետը, որտեղ համեմատվող երկու խմբերի միջև տարբերություններն ամենամեծն են։ Առավել ճշգրիտ, մենք կարող ենք դա անել՝ օգտագործելով չափանիշը հաշվարկելու ալգորիթմըλ , որը թույլ է տալիս բացահայտել երկու նմուշների միջև առավելագույն անհամապատասխանության կետը:
Չափանիշների համադրման հնարավորությունը φ* ևλ նկարագրված Է.Վ. Գուբլեր (1978, էջ 85-88): Փորձենք օգտագործել այս մեթոդը հետևյալ խնդրի լուծման համար.
Համատեղ ուսումնասիրության մեջ Մ.Ա. Կուրոչկինա, Է.Վ. Սիդորենկոն և Յու.Ա. Չուրակովը (1992 թ.) Մեծ Բրիտանիայում անցկացրեց երկու կատեգորիաների անգլիացի ընդհանուր բժիշկների հարցում. բ) բժիշկները, որոնց կաբինետները դեռևս չունեն սեփական միջոցներ և ամբողջությամբ ապահովված են պետական բյուջեից: Հարցաթերթիկներ են ուղարկվել 200 բժիշկների ընտրանքին՝ անգլիացի բժիշկների ընդհանուր բնակչության ներկայացուցիչներին՝ տարբեր սեռի, տարիքի, ստաժի և աշխատանքի վայրի մարդկանց ներկայացվածության առումով՝ խոշոր քաղաքներում կամ մարզերում:
Հարցաշարին պատասխանել է 78 բժիշկ, որից 50-ը աշխատել են ֆոնդով սպասասրահներում, իսկ 28-ը՝ առանց ֆինանսավորման սպասասրահներում։ Բժիշկներից յուրաքանչյուրը պետք է գուշակեր, թե ինչ մասնաբաժին կունենան միջոցներով ընդունելությունները հաջորդ տարում՝ 1993թ. Պատասխաններ ուղարկած 78 բժիշկներից միայն 70-ն են պատասխանել այս հարցին։ Նրանց կանխատեսումների բաշխումը ներկայացված է Աղյուսակում: 5.8 առանձին` դրամական միջոցներ ունեցող բժիշկների խմբի և առանց դրամական բժիշկների խմբի համար:
Ինչ-որ կերպ տարբերվու՞մ են ֆոնդ ունեցող բժիշկների և առանց դրամական բժիշկների կանխատեսումները։
Աղյուսակ 5.8
Ընդհանուր պրակտիկայով զբաղվող բժիշկների կանխատեսումների բաշխումն այն մասին, թե որքան է լինելու շտապ օգնության սենյակների մասնաբաժինը միջոցներով 1993թ.
Նախատեսված մասնաբաժինը | |||
միջոցներով ընդունելությունների սենյակներ | ֆոնդով բժիշկներ (n 1 =45) | բժիշկներ առանց ֆոնդի (n 2 =25) | Գումարներ |
1. 0-ից մինչև 20% | 4 | 5 | 9 |
2. 21-ից մինչև 40% | 15 | ԵՎ | 26 |
3. 41-ից մինչև 60% | 18 | 5 | 23 |
4. 61-ից մինչև 80% | 7 | 4 | ԵՎ |
5. 81-ից մինչև 100% | 1 | 0 | 1 |
Գումարներ | 45 | 25 | 70 |
Եկեք որոշենք պատասխանների երկու բաշխումների միջև առավելագույն անհամապատասխանության կետը՝ օգտագործելով Ալգորիթմ 15-ը 4.3 կետից (տես Աղյուսակ 5.9):
Աղյուսակ 5.9
Երկու խմբերի բժիշկների կանխատեսումների բաշխման մեջ կուտակված հաճախականությունների առավելագույն տարբերության հաշվարկ
Ընդունելությունների կանխատեսվող մասնաբաժինը միջոցներով (%) | Ընտրության էմպիրիկ հաճախականություններ տվյալ պատասխանի կատեգորիայի համար | Էմպիրիկ հաճախականություններ | Կուտակային էմպիրիկ հաճախականություններ | Տարբերություն (դ) |
|||
բժիշկները ֆոնդով(n 1 =45) | բժիշկներ առանց ֆոնդի (n 2 =25) | զ* հա 1 | զ* ա2 | ∑զ* e1 | ∑զ* ա1 |
||
1. 0-ից մինչև 20% 2. 21-ից մինչև 40% 3. 41-ից մինչև 60% 4. 61-ից մինչև 80% 5. 81-ից մինչև 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
Երկու կուտակված էմպիրիկ հաճախականությունների միջև հայտնաբերված առավելագույն տարբերությունն է0,218.
Այս տարբերությունը, պարզվում է, կուտակված է կանխատեսման երկրորդ կատեգորիայում։ Փորձենք օգտագործել այս կատեգորիայի վերին սահմանը որպես չափանիշ երկու նմուշները բաժանելու ենթախմբի, որտեղ «էֆեկտ կա» և ենթախմբի, որտեղ «էֆեկտ չկա»: Մենք կենթադրենք, որ կա «էֆեկտ», եթե տվյալ բժիշկը կանխատեսի 41-ից մինչև 100% ընդունելությունները՝ միջոցներով.1993 տարի, և որ «ոչ մի էֆեկտ» չկա, եթե տվյալ բժիշկը կանխատեսում է 0-ից մինչև 40% ընդունելությունների ֆոնդով.1993 տարին։ Մենք միավորում ենք կանխատեսման 1-ին և 2-րդ կատեգորիաները, մյուս կողմից՝ 3-րդ, 4-րդ և 5-րդ կատեգորիաները: Կանխատեսումների արդյունքում բաշխվածությունը ներկայացված է Աղյուսակում: 5.10.
Աղյուսակ 5.10
Կանխատեսումների բաշխում ֆոնդով բժիշկների և առանց միջոցների բժիշկների համար
Ընդունելությունների կանխատեսվող մասնաբաժինը միջոցներով (%1 | Կանխատեսման տվյալ կատեգորիա ընտրելու էմպիրիկ հաճախականություններ | Գումարներ |
|
բժիշկները ֆոնդով(n 1 =45) | բժիշկներ առանց ֆոնդի(n 2 =25) |
||
1. 0-ից մինչև 40% | 19 | 16 | 35 |
2. 41-ից մինչև 100% | 26 | 9 | 35 |
Գումարներ | 45 | 25 | 70 |
Մենք կարող ենք օգտագործել ստացված աղյուսակը (Աղյուսակ 5.10) տարբեր վարկածներ ստուգելու համար՝ համեմատելով դրա ցանկացած երկու բջիջ: Մենք հիշում ենք, որ սա, այսպես կոչված, չորս բջիջ կամ չորս դաշտային աղյուսակ է:
Այստեղ մեզ հետաքրքրում է, թե արդյոք բժիշկները, ովքեր արդեն ունեն միջոցներ, կանխատեսում են այս շարժման ավելի մեծ ապագա աճ, քան այն բժիշկները, ովքեր միջոցներ չունեն: Հետևաբար, մենք պայմանականորեն համարում ենք, որ «էֆեկտ կա», երբ կանխատեսումը ընկնում է 41-ից մինչև 100% կատեգորիայի մեջ: Հաշվարկները պարզեցնելու համար մենք այժմ պետք է պտտենք աղյուսակը 90°՝ պտտելով այն ժամացույցի սլաքի ուղղությամբ: Դուք նույնիսկ կարող եք դա անել բառացիորեն՝ պտտելով գիրքը սեղանի հետ միասին: Այժմ մենք կարող ենք անցնել φ* չափանիշի հաշվարկման աշխատանքային թերթիկին՝ Fisher's Angular Transform-ը։
Աղյուսակ 5.11
Ֆիշերի φ* թեստը հաշվարկելու չորս բջիջների աղյուսակ՝ ընդհանուր բժիշկների երկու խմբերի կանխատեսումների տարբերությունները պարզելու համար
Խումբ | Կա ազդեցություն՝ կանխատեսում 41-ից մինչև 100% | Ոչ մի ազդեցություն - կանխատեսում 0-ից 40% | Ընդամենը |
Իխումբ՝ ֆոնդ վերցրած բժիշկներ | 26 (57.8%) | 19 (42.2%) | 45 |
IIխումբ՝ ֆոնդ չվերցրած բժիշկներ | 9 (36.0%) | 16 (64.0%) | 25 |
Ընդամենը | 35 | 35 | 70 |
Ձևակերպենք վարկածներ.
Հ 0 Մարդկանց համամասնությունըկանխատեսելով միջոցների տարածում բոլոր բժիշկների կաբինետների 41%-100%-ի վրա, դրամական միջոցներ ունեցող բժիշկների խմբում չկա ավելին, քան առանց միջոցների բժիշկների խմբում։
Հ 1 Ֆոնդերի տարածում կանխատեսող մարդկանց մասնաբաժինը բոլոր ընդունելությունների 41%-100%-ին ավելի մեծ է դրամական միջոցներ ունեցող բժիշկների խմբում, քան առանց միջոցների բժիշկների խմբում:
φ-ի արժեքների որոշում 1 և φ 2 ըստ աղյուսակիXIIՀավելված 1. Հիշեցնենք, որ φ 1 միշտ ավելի մեծ տոկոսին համապատասխանող անկյունն է:
Այժմ որոշենք φ* չափանիշի էմպիրիկ արժեքը.
Աղյուսակի համաձայն.XIIIՀավելված 1-ում մենք որոշում ենք, թե այս արժեքը ինչ մակարդակի է համապատասխանում՝ p = 0,039:
Օգտագործելով Հավելված 1-ի նույն աղյուսակը, կարող եք որոշել φ* չափանիշի կրիտիկական արժեքները.
Պատասխան. Բայց մերժվում է (p=0.039)։ Մարդկանց մասնաբաժինը, որոնք կանխատեսում են միջոցների տարածումը դեպի41-100 % Ֆոնդը վերցրած բժիշկների խմբի բոլոր ընդունելությունները գերազանցում են ֆոնդը չվերցրած բժիշկների խմբի այս տեսակարար կշիռը:
Այլ կերպ ասած, բժիշկները, ովքեր արդեն աշխատում են իրենց սպասասրահներում առանձին բյուջեով, այս տարի այս պրակտիկայի ավելի լայն տարածում են կանխատեսում, քան այն բժիշկները, ովքեր դեռ չեն համաձայնել անցնել անկախ բյուջեին։ Այս արդյունքի բազմաթիվ մեկնաբանություններ կան: Օրինակ, կարելի է ենթադրել, որ յուրաքանչյուր խմբի բժիշկները ենթագիտակցորեն իրենց պահվածքն ավելի բնորոշ են համարում։ Սա կարող է նաև նշանակել, որ բժիշկները, ովքեր արդեն իսկ ընդունել են ինքնաֆինանսավորումը, հակված են ուռճացնելու այս շարժման շրջանակը, քանի որ նրանք պետք է հիմնավորեն իրենց որոշումը: Հայտնաբերված տարբերությունները կարող են նաև նշանակել մի բան, որը լիովին դուրս է հետազոտության մեջ առաջադրված հարցերի շրջանակից: Օրինակ, որ անկախ բյուջեով աշխատող բժիշկների գործունեությունը նպաստում է երկու խմբերի դիրքորոշումների տարբերությունների սրմանը։ Նրանք ավելի ակտիվ էին, երբ համաձայնեցին վերցնել միջոցները, ավելի ակտիվ էին, երբ դժվարացան պատասխանել փոստի հարցաշարին. նրանք ավելի ակտիվ են, երբ կանխատեսում են, որ այլ բժիշկներ ավելի ակտիվ կլինեն միջոցներ ստանալու հարցում:
Այսպես թե այնպես, մենք կարող ենք վստահ լինել, որ վիճակագրական տարբերությունների հայտնաբերված մակարդակը առավելագույն հնարավորն է այս իրական տվյալների համար։ Մենք սահմանեցինք՝ օգտագործելով չափանիշըλ երկու բաշխումների միջև առավելագույն շեղման կետը, և հենց այս պահին նմուշները բաժանվեցին երկու մասի:
Ձեր նշանը:
FISCHER ֆունկցիան վերադարձնում է արգումենտների Fisher փոխակերպումը X-ի: Այս փոխակերպումը առաջացնում է ֆունկցիա, որն ունի նորմալ, այլ ոչ թե շեղ բաշխում: FISCHER ֆունկցիան օգտագործվում է վարկածը ստուգելու համար՝ օգտագործելով հարաբերակցության գործակիցը:
FISCHER ֆունկցիայի նկարագրությունը Excel-ում
Այս ֆունկցիայի հետ աշխատելիս պետք է սահմանել փոփոխականի արժեքը։ Հարկ է անմիջապես նշել, որ կան իրավիճակներ, երբ այս գործառույթը արդյունք չի տա: Դա հնարավոր է, եթե փոփոխականը.
- թիվ չէ։ Նման իրավիճակում FISCHER ֆունկցիան կվերադարձնի սխալի արժեքը #VALUE!;
- ունի -1-ից փոքր կամ 1-ից մեծ արժեք: Այս դեպքում FISCHER ֆունկցիան կվերադարձնի սխալի արժեքը #NUM!:
FISCHER ֆունկցիան մաթեմատիկորեն նկարագրելու համար օգտագործվող հավասարումը հետևյալն է.
Z"=1/2*ln(1+x)/(1-x)
Դիտարկենք այս ֆունկցիայի օգտագործումը՝ օգտագործելով 3 կոնկրետ օրինակ։
Շահույթի և ծախսերի միջև կապի գնահատում FISHER ֆունկցիայի միջոցով
Օրինակ 1. Օգտագործելով առևտրային կազմակերպությունների գործունեության վերաբերյալ տվյալները, պահանջվում է գնահատել շահույթի Y (միլիոն ռուբլի) և X (միլիոն ռուբլի) ծախսերը, որոնք օգտագործվում են արտադրանքի մշակման համար (ցուցված է Աղյուսակ 1-ում):
Աղյուսակ 1 – Սկզբնական տվյալներ.
| № | X | Յ |
| 1 | 210,000,000.00 RUR | 95,000,000.00 RUR |
| 2 | 1,068,000,000,00 ռուբլի | 76,000,000.00 RUR |
| 3 | 1,005,000,000,00 ռուբլի | 78,000,000.00 RUR |
| 4 | 610,000,000.00 RUR | 89,000,000.00 RUR |
| 5 | 768,000,000.00 RUR | 77,000,000.00 RUR |
| 6 | 799,000,000.00 RUR | 85,000,000.00 RUR |
Նման խնդիրների լուծման սխեման հետևյալն է.
- Հաշվարկված գծային գործակիցհարաբերակցություններ r xy;
- Գծային հարաբերակցության գործակցի նշանակությունը ստուգվում է Student-ի t-թեստի հիման վրա։ Այս դեպքում առաջ է քաշվում և փորձարկվում վարկած, որ հարաբերակցության գործակիցը հավասար է զրոյի։ Այս վարկածը ստուգելու համար օգտագործվում է t-վիճակագրությունը: Եթե վարկածը հաստատվի, t-վիճակագրությունը ունի Student բաշխում: Եթե հաշվարկված արժեքը t p > t cr, ապա հիպոթեզը մերժվում է, որը ցույց է տալիս գծային հարաբերակցության գործակցի նշանակությունը, հետևաբար՝ X և Y հարաբերությունների վիճակագրական նշանակությունը.
- Միջակայքի գնահատումը որոշվում է վիճակագրորեն նշանակալի գծային հարաբերակցության գործակցի համար:
- Գծային հարաբերակցության գործակցի միջակայքի գնահատումը որոշվում է հակադարձ Fisher z-տրանսֆորմի հիման վրա.
- Հաշվարկվում է գծային հարաբերակցության գործակցի ստանդարտ սխալը:
Excel-ում օգտագործվող գործառույթներով այս խնդրի լուծման արդյունքները ներկայացված են Նկար 1-ում:
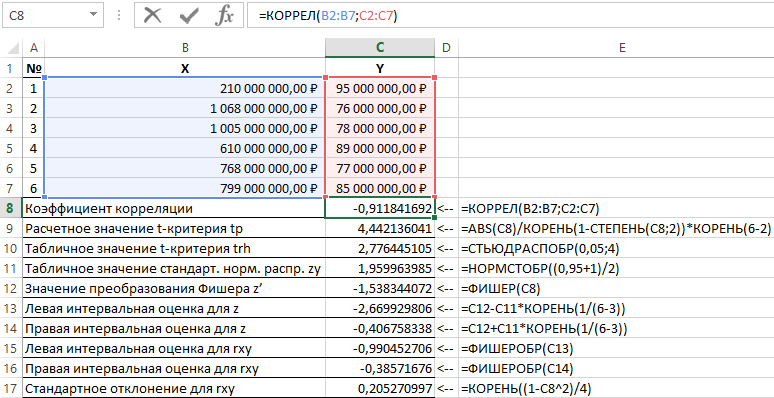
Նկար 1 – Հաշվարկների օրինակ:
| Ոչ | Ցուցանիշի անվանումը | Հաշվարկի բանաձև |
| 1 | Հարաբերակցության գործակից | =CORREL(B2:B7,C2:C7) |
| 2 | Հաշվարկված t-test արժեքը tp | =ABS(C8)/SQRT(1-POWER(C8,2))*SQRT(6-2) |
| 3 | T-test trh-ի աղյուսակի արժեքը | =STUDISCOVER (0.05,4) |
| 4 | Ստանդարտի աղյուսակի արժեքը նորմալ բաշխում zy | =NORMSIV ((0.95+1)/2) |
| 5 | Fisher z' փոխակերպման արժեքը | =FISHER(C8) |
| 6 | Ձախ միջակայքի գնահատում z-ի համար | =C12-C11*ROOT(1/(6-3)) |
| 7 | Ճիշտ միջակայքի գնահատում z-ի համար | =C12+C11*ROOT(1/(6-3)) |
| 8 | Ձախ միջակայքի գնահատում rxy-ի համար | = FISHEROBR (C13) |
| 9 | Ճիշտ միջակայքի գնահատում rxy-ի համար | = FISHEROBR (C14) |
| 10 | Ստանդարտ շեղում rxy-ի համար | =ROOT ((1-C8^2)/4) |
Այսպիսով, 0,95 հավանականությամբ, գծային հարաբերակցության գործակիցը գտնվում է (–0,386)–ից (–0,990) միջակայքում՝ 0,205 ստանդարտ սխալով։
Ստուգելով ռեգրեսիայի վիճակագրական նշանակությունը FASTER ֆունկցիայի միջոցով
Օրինակ 2. Ստուգեք հավասարման վիճակագրական նշանակությունը բազմակի ռեգրեսիաՕգտագործելով Ֆիշերի F թեստը՝ եզրակացություններ արեք։
Որպես ամբողջության հավասարման նշանակությունը ստուգելու համար մենք առաջ ենք քաշում H 0 վարկածը որոշման գործակցի վիճակագրական աննշանության մասին և հակառակ վարկածը H 1 որոշման գործակցի վիճակագրական նշանակության մասին.
H 1: R 2 ≠ 0:
Փորձարկենք վարկածները՝ օգտագործելով Ֆիշերի F թեստը: Ցուցանիշները ներկայացված են Աղյուսակ 2-ում:
Աղյուսակ 2 - Սկզբնական տվյալներ
Դա անելու համար մենք օգտագործում ենք գործառույթը Excel-ում.
ԱՎԵԼԻ ԱՐԱԳ (α;p;n-p-1)
- α-ն տվյալ բաշխման հետ կապված հավանականությունն է.
- p և n-ը համապատասխանաբար ազատության աստիճանների համարիչն ու հայտարարն են։
Իմանալով, որ α = 0,05, p = 2 և n = 53, մենք ստանում ենք հետևյալ արժեքը F crit-ի համար (տես նկար 2):
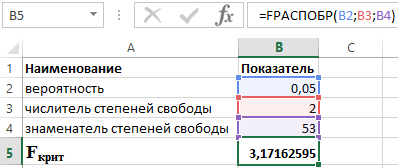
Նկար 2 – Հաշվարկների օրինակ:
Այսպիսով, մենք կարող ենք ասել, որ F-ը հաշվարկված է > F կրիտիկական: Արդյունքում ընդունվում է որոշման գործակցի վիճակագրական նշանակության մասին H 1 վարկածը։
Excel-ում հարաբերակցության ցուցիչի արժեքի հաշվարկ
Օրինակ 3. Օգտագործելով 23 ձեռնարկությունների տվյալները հետևյալի մասին. X-ը A ապրանքի գինն է, հազար ռուբլի; Y-ն առևտրային ձեռնարկության շահույթն է, միլիոն ռուբլի, դրանց կախվածությունը ուսումնասիրվում է: Դասարան ռեգրեսիոն մոդելտվել է հետևյալը. ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. Ի՞նչ հարաբերակցության ցուցանիշ կարելի է որոշել այս տվյալների հիման վրա: Հաշվեք հարաբերակցության ցուցիչի արժեքը և, օգտագործելով Ֆիշերի չափանիշը, եզրակացություն արեք ռեգրեսիոն մոդելի որակի մասին։
Եկեք որոշենք F կրիտը արտահայտությունից.
F հաշվարկված = R 2 /23*(1-R 2)
որտեղ R որոշման գործակիցը հավասար է 0,67:
Այսպիսով, հաշվարկված արժեքը F calc = 46:
F crit-ը որոշելու համար մենք օգտագործում ենք Fisher բաշխումը (տես Նկար 3):

Նկար 3 – Հաշվարկների օրինակ:
Այսպիսով, ռեգրեսիայի հավասարման արդյունքում ստացված գնահատումը հուսալի է:
Բազմակի ռեգրեսիայի հավասարման նշանակությունը որպես ամբողջություն, ինչպես նաև զուգակցված ռեգրեսիայում, գնահատվում է Ֆիշերի չափանիշի միջոցով.
 ,
(2.22)
,
(2.22)
Որտեղ  – քառակուսիների գումարը ազատության աստիճանի համար.
– քառակուսիների գումարը ազատության աստիճանի համար.  - քառակուսիների մնացորդային գումարը ազատության աստիճանի համար.
- քառակուսիների մնացորդային գումարը ազատության աստիճանի համար.  – բազմակի որոշման գործակից (ինդեքս);
– բազմակի որոշման գործակից (ինդեքս);  - փոփոխականների համար պարամետրերի քանակը
- փոփոխականների համար պարամետրերի քանակը  (Վ գծային ռեգրեսիահամընկնում է մոդելում ներառված գործոնների քանակի հետ);
(Վ գծային ռեգրեսիահամընկնում է մոդելում ներառված գործոնների քանակի հետ);  - դիտարկումների քանակը.
- դիտարկումների քանակը.
Գնահատվում է ոչ միայն հավասարման ընդհանուր նշանակությունը, այլ նաև ռեգրեսիոն մոդելում լրացուցիչ ներառված գործոնը: Նման գնահատման անհրաժեշտությունը պայմանավորված է նրանով, որ մոդելում ներառված ոչ բոլոր գործոնները կարող են էապես մեծացնել բացատրված տատանումների մասնաբաժինը ստացված հատկանիշում: Բացի այդ, եթե մոդելում կան մի քանի գործոններ, դրանք կարող են մուտքագրվել մոդելի մեջ տարբեր հաջորդականությամբ: Գործոնների միջև հարաբերակցության պատճառով նույն գործոնի նշանակությունը կարող է տարբեր լինել՝ կախված մոդելում դրա ներմուծման հաջորդականությունից: Մոդելում գործոնի ընդգրկման գնահատման միջոցը մասնավորն է  - չափանիշ, այսինքն.
- չափանիշ, այսինքն.  .
.
Մասնավոր  -չափանիշը հիմնված է հավելյալ ներառված գործոնի ազդեցության հետևանքով գործոնի շեղումների աճի համեմատության վրա՝ որպես ամբողջություն ռեգրեսիոն մոդելի ազատության մեկ աստիճանի դիմաց մնացորդային շեղման հետ: IN ընդհանուր տեսարանգործոնի համար
-չափանիշը հիմնված է հավելյալ ներառված գործոնի ազդեցության հետևանքով գործոնի շեղումների աճի համեմատության վրա՝ որպես ամբողջություն ռեգրեսիոն մոդելի ազատության մեկ աստիճանի դիմաց մնացորդային շեղման հետ: IN ընդհանուր տեսարանգործոնի համար  մասնավոր
մասնավոր  - չափանիշը կորոշվի այսպես
- չափանիշը կորոշվի այսպես
 ,
(2.23)
,
(2.23)
Որտեղ  - բազմակի որոշման գործակիցը գործոնների ամբողջական փաթեթով մոդելի համար,
- բազմակի որոշման գործակիցը գործոնների ամբողջական փաթեթով մոդելի համար,  – նույն ցուցանիշը, բայց առանց մոդելի գործոնը ներառելու
– նույն ցուցանիշը, բայց առանց մոդելի գործոնը ներառելու  ,
, - դիտարկումների քանակը,
- դիտարկումների քանակը,  – մոդելի պարամետրերի քանակը (առանց ազատ ժամկետի):
– մոդելի պարամետրերի քանակը (առանց ազատ ժամկետի):
Գործակիցի իրական արժեքը  - չափանիշը համեմատվում է աղյուսակի հետ նշանակության մակարդակով
- չափանիշը համեմատվում է աղյուսակի հետ նշանակության մակարդակով  և ազատության աստիճանների թիվը՝ 1 և
և ազատության աստիճանների թիվը՝ 1 և  . Եթե իրական արժեքը
. Եթե իրական արժեքը  գերազանցում է
գերազանցում է  , ապա գործոնի լրացուցիչ ներառումը
, ապա գործոնի լրացուցիչ ներառումը  մոդելի մեջ վիճակագրորեն հիմնավորված է և մաքուր ռեգրեսիայի գործակիցը
մոդելի մեջ վիճակագրորեն հիմնավորված է և մաքուր ռեգրեսիայի գործակիցը  գործոնով
գործոնով  վիճակագրորեն նշանակալի. Եթե իրական արժեքը
վիճակագրորեն նշանակալի. Եթե իրական արժեքը  փոքր է աղյուսակի արժեքից, այնուհետև գործոնի լրացուցիչ ներառումը մոդելում
փոքր է աղյուսակի արժեքից, այնուհետև գործոնի լրացուցիչ ներառումը մոդելում  էապես չի մեծացնում հատկանիշի բացատրված տատանումների համամասնությունը
էապես չի մեծացնում հատկանիշի բացատրված տատանումների համամասնությունը  , հետևաբար, անտեղի է այն ներառել մոդելի մեջ. Այս գործոնի ռեգրեսիայի գործակիցն այս դեպքում վիճակագրորեն աննշան է:
, հետևաբար, անտեղի է այն ներառել մոդելի մեջ. Այս գործոնի ռեգրեսիայի գործակիցն այս դեպքում վիճակագրորեն աննշան է:
Երկգործոն հավասարման համար, քանորդները  -չափանիշներն ունեն հետևյալ ձևը.
-չափանիշներն ունեն հետևյալ ձևը.
 ,
, . (2.23a)
. (2.23a)
Օգտագործելով մասնավոր  -չափանիշ, կարելի է ստուգել բոլոր ռեգրեսիոն գործակիցների նշանակությունը՝ ենթադրելով, որ յուրաքանչյուր համապատասխան գործոն
-չափանիշ, կարելի է ստուգել բոլոր ռեգրեսիոն գործակիցների նշանակությունը՝ ենթադրելով, որ յուրաքանչյուր համապատասխան գործոն  վերջին մտել է բազմակի ռեգրեսիայի հավասարման մեջ:
վերջին մտել է բազմակի ռեգրեսիայի հավասարման մեջ:
-Աշակերտական թեստ բազմակի ռեգրեսիայի հավասարման համար:
Մասնավոր  -չափանիշը գնահատում է մաքուր ռեգրեսիոն գործակիցների նշանակությունը: Իմանալով մեծությունը
-չափանիշը գնահատում է մաքուր ռեգրեսիոն գործակիցների նշանակությունը: Իմանալով մեծությունը  , հնարավոր է որոշել
, հնարավոր է որոշել  - ռեգրեսիայի գործակցի չափանիշը
- ռեգրեսիայի գործակցի չափանիշը  - մ գործոն,
- մ գործոն,  , այսինքն:
, այսինքն:
 .
(2.24)
.
(2.24)
Մաքուր ռեգրեսիոն գործակիցների նշանակությունը գնահատելով ըստ  -Ուսանողի t-թեստը կարող է իրականացվել առանց մասնակի հաշվարկի
-Ուսանողի t-թեստը կարող է իրականացվել առանց մասնակի հաշվարկի  - չափորոշիչներ. Այս դեպքում, ինչպես զույգ ռեգրեսիայի դեպքում, յուրաքանչյուր գործոնի համար օգտագործվում է բանաձևը.
- չափորոշիչներ. Այս դեպքում, ինչպես զույգ ռեգրեսիայի դեպքում, յուրաքանչյուր գործոնի համար օգտագործվում է բանաձևը.
 ,
(2.25)
,
(2.25)
Որտեղ  – զուտ ռեգրեսիայի գործակիցը գործոնում
– զուտ ռեգրեսիայի գործակիցը գործոնում  ,
, – ռեգրեսիայի գործակցի միջին քառակուսի (ստանդարտ) սխալ
– ռեգրեսիայի գործակցի միջին քառակուսի (ստանդարտ) սխալ  .
.
Բազմակի ռեգրեսիայի հավասարման համար ռեգրեսիայի գործակցի միջին քառակուսի սխալը կարող է որոշվել հետևյալ բանաձևով.
 ,
(2.26)
,
(2.26)
Որտեղ 
 ,
, - բնութագրի ստանդարտ շեղում
- բնութագրի ստանդարտ շեղում  ,
, - բազմակի ռեգրեսիայի հավասարման որոշման գործակիցը,
- բազմակի ռեգրեսիայի հավասարման որոշման գործակիցը,  – գործակիցի կախվածության որոշման գործակիցը
– գործակիցի կախվածության որոշման գործակիցը  բազմակի ռեգրեսիայի հավասարման բոլոր այլ գործոնների հետ;
բազմակի ռեգրեսիայի հավասարման բոլոր այլ գործոնների հետ;  – քառակուսի շեղումների մնացորդային գումարի ազատության աստիճանների թիվը:
– քառակուսի շեղումների մնացորդային գումարի ազատության աստիճանների թիվը:
Ինչպես տեսնում եք, այս բանաձևն օգտագործելու համար ձեզ անհրաժեշտ է միջֆակտորային հարաբերակցության մատրիցա և դրա միջոցով որոշման համապատասխան գործակիցների հաշվարկ:  . Այսպիսով, հավասարման համար
. Այսպիսով, հավասարման համար  ռեգրեսիոն գործակիցների նշանակության գնահատում
ռեգրեսիոն գործակիցների նշանակության գնահատում  ,
, ,
, ներառում է ինտերֆակտորի որոշման երեք գործակիցների հաշվարկ.
ներառում է ինտերֆակտորի որոշման երեք գործակիցների հաշվարկ.  ,
, ,
, .
.
Մասնակի հարաբերակցության գործակցի ցուցիչների հարաբերությունը, մասնակի  -չափանիշներ և
-չափանիշներ և  -Մաքուր ռեգրեսիոն գործակիցների համար ուսանողի t-թեստը կարող է օգտագործվել գործոնների ընտրության ընթացակարգում: Վերացման մեթոդով ռեգրեսիոն հավասարումը կառուցելիս գործոնների վերացումը գործնականում կարող է իրականացվել ոչ միայն մասնակի հարաբերակցության գործակիցներով, յուրաքանչյուր քայլում բացառելով մասնակի հարաբերակցության գործակցի ամենափոքր աննշան արժեք ունեցող գործակիցը, այլև արժեքները:
-Մաքուր ռեգրեսիոն գործակիցների համար ուսանողի t-թեստը կարող է օգտագործվել գործոնների ընտրության ընթացակարգում: Վերացման մեթոդով ռեգրեսիոն հավասարումը կառուցելիս գործոնների վերացումը գործնականում կարող է իրականացվել ոչ միայն մասնակի հարաբերակցության գործակիցներով, յուրաքանչյուր քայլում բացառելով մասնակի հարաբերակցության գործակցի ամենափոքր աննշան արժեք ունեցող գործակիցը, այլև արժեքները:  Եվ
Եվ  .
Մասնավոր
.
Մասնավոր  -չափանիշը լայնորեն կիրառվում է մոդելի կառուցման ժամանակ՝ օգտագործելով փոփոխականների ընդգրկման մեթոդը և փուլային ռեգրեսիայի մեթոդը:
-չափանիշը լայնորեն կիրառվում է մոդելի կառուցման ժամանակ՝ օգտագործելով փոփոխականների ընդգրկման մեթոդը և փուլային ռեգրեսիայի մեթոդը:





. «Ես աղոթում եմ, որ Տերը շնորհի ինձ սեր Ջերոմ Շուրիգինի կենսագրությունը")

