ObliczmySMPRZEWYŻSZAĆwariancja i odchylenie standardowe próbki. Obliczmy także wariancję zmienna losowa, jeżeli znane jest jego rozmieszczenie.
Najpierw rozważmy dyspersja, Następnie odchylenie standardowe.
Odchylenie próbki
Odchylenie próbki (wariancja próbki,próbkazmienność) charakteryzuje rozrzut wartości w tablicy względem .
Wszystkie 3 wzory są matematycznie równoważne.
Z pierwszego wzoru wynika, że wariancja próbki jest sumą kwadratów odchyleń każdej wartości w tablicy od średniej podzielone przez wielkość próby minus 1.
odchylenia próbki używana jest funkcja DISP(), angielski. nazwa VAR, tj. Zmienność. Od wersji MS EXCEL 2010 zaleca się używanie jego analogowego DISP.V(), w języku angielskim. nazwa VARS, tj. Przykładowa zmienność. Dodatkowo począwszy od wersji MS EXCEL 2010 dostępna jest funkcja DISP.Г(), w języku angielskim. nazwa VARP, tj. Wariancja populacji, która oblicza dyspersja Dla populacja . Cała różnica sprowadza się do mianownika: zamiast n-1, jak DISP.V(), DISP.G() ma w mianowniku tylko n. Przed wersją MS EXCEL 2010 do obliczania wariancji populacji używano funkcji VAR().
Odchylenie próbki
=QUADROTCL(Próbka)/(LICZBA(Próbka)-1)
=(SUMA(Próbka)-LICZBA(Próbka)*ŚREDNIA(Próbka)^2)/ (LICZBA(Próbka)-1)– zwykła formuła
=SUMA((Próbka -ŚREDNIA(Próbka))^2)/ (LICZBA(Próbka)-1) –
Odchylenie próbki jest równy 0, tylko wtedy, gdy wszystkie wartości są sobie równe i odpowiednio równe Średnia wartość. Zwykle im większa wartość odchylenia, tym większy jest rozrzut wartości w tablicy.
Odchylenie próbki Jest Punktowe oszacowanie odchylenia rozkład zmiennej losowej, z której został utworzony próbka. O budowie przedziały ufności podczas oceniania odchylenia można przeczytać w artykule.
Wariancja zmiennej losowej
Liczyć dyspersja zmienna losowa, musisz ją znać.
Dla odchylenia zmienna losowa X jest często oznaczana jako Var(X). Dyspersja równy kwadratowi odchylenia od średniej E(X): Var(X)=E[(X-E(X)) 2 ]
dyspersja obliczane według wzoru:

gdzie x i to wartość, jaką może przyjąć zmienna losowa, a μ to wartość średnia (), p(x) to prawdopodobieństwo, że zmienna losowa przyjmie wartość x.
Jeśli zmienna losowa ma , to dyspersja obliczane według wzoru:

Wymiar odchylenia odpowiada kwadratowi jednostki miary wartości pierwotnych. Na przykład, jeśli wartości w próbce reprezentują pomiary masy części (w kg), wówczas wymiarem wariancji będzie kg 2 . Może to być trudne do zinterpretowania, aby scharakteryzować rozrzut wartości, wartość równą pierwiastkowi kwadratowemu odchylenia – odchylenie standardowe.
Niektóre właściwości odchylenia:
Var(X+a)=Var(X), gdzie X jest zmienną losową, a a jest stałą.
Var(aХ)=a 2 Var(X)
Var(X)=E[(X-E(X)) 2 ]=E=E(X 2)-E(2*X*E(X))+(E(X)) 2 =E(X 2)- 2*E(X)*E(X)+(E(X)) 2 =E(X 2)-(E(X)) 2
Ta właściwość dyspersji jest wykorzystywana w artykuł o regresji liniowej.
Var(X+Y)=Var(X) + Var(Y) + 2*Cov(X;Y), gdzie X i Y to zmienne losowe, Cov(X;Y) to kowariancja tych zmiennych losowych.
Jeśli zmienne losowe są niezależne, to tak kowariancja jest równe 0, a zatem Var(X+Y)=Var(X)+Var(Y). Ta właściwość dyspersji jest wykorzystywana w wyprowadzaniu.
Pokażmy to dla niezależne ilości Var(X-Y)=Var(X+Y). Rzeczywiście, Var(X-Y)= Var(X-Y)= Var(X+(-Y))= Var(X)+Var(-Y)= Var(X)+Var(-Y)= Var( X)+(- 1) 2 Var(Y)= Var(X)+Var(Y)= Var(X+Y). Ta właściwość dyspersji jest używana do konstruowania .
Odchylenie standardowe próbki
Odchylenie standardowe próbki jest miarą tego, jak bardzo rozproszone są wartości w próbce w stosunku do ich wartości.
A-przeorat, odchylenie standardowe równy pierwiastkowi kwadratowemu z odchylenia:

Odchylenie standardowe nie bierze pod uwagę wielkości wartości w próbka, a jedynie stopień rozproszenia wartości wokół nich przeciętny. Aby to zilustrować, podamy przykład.
Obliczmy odchylenie standardowe dla 2 próbek: (1; 5; 9) i (1001; 1005; 1009). W obu przypadkach s=4. Oczywiste jest, że stosunek odchylenia standardowego do wartości tablicy różni się znacznie pomiędzy próbkami. W takich przypadkach się go stosuje Współczynnik zmienności(Współczynnik zmienności, CV) - stosunek Odchylenie standardowe do średniej arytmetyka, wyrażona w procentach.
W MS EXCEL 2007 i wcześniejszych wersjach do obliczeń Odchylenie standardowe próbki używana jest funkcja =STDEVAL(), angielski. nazwa STDEV, tj. Odchylenie standardowe. Od wersji MS EXCEL 2010 zaleca się stosowanie jego odpowiednika =STDEV.B() , angielskiego. nazwa STDEV.S, tj. Odchylenie standardowe próbki.
Dodatkowo począwszy od wersji MS EXCEL 2010 dostępna jest funkcja STANDARDEV.G(), angielska. nazwa STDEV.P, tj. Odchylenie standardowe populacji, które oblicza odchylenie standardowe Dla populacja. Cała różnica sprowadza się do mianownika: zamiast n-1 jak w mianowniku STANDARDEVAL.V(), STANDARDEVAL.Г() ma w mianowniku tylko n.
Odchylenie standardowe można również obliczyć bezpośrednio za pomocą poniższych wzorów (patrz przykładowy plik)
=ROOT(QUADROTCL(próbka)/(LICZBA(próbka)-1))
=ROOT((SUMA(Próbka)-LICZ(Próbka)*ŚREDNIA(Próbka)^2)/(LICZBA(Próbka)-1))
Inne miary rozproszenia
Funkcja SQUADROTCL() wykonuje obliczenia za pomocą suma kwadratów odchyleń wartości od ich przeciętny. Ta funkcja zwróci taki sam wynik jak formuła =DISP.G( Próbka)*SPRAWDZAĆ( Próbka) , Gdzie Próbka- odwołanie do zakresu zawierającego tablicę przykładowych wartości (). Obliczenia w funkcji QUADROCL() wykonujemy według wzoru:

Funkcja SROTCL() jest także miarą rozproszenia zbioru danych. Funkcja SROTCL() oblicza średnią Wartości bezwzględne odchylenia wartości od przeciętny. Ta funkcja zwróci taki sam wynik jak formuła =SUMAPRODUKT(ABS(Próbka-ŚREDNIA(Próbka)))/LICZBA(Próbka), Gdzie Próbka- link do zakresu zawierającego tablicę przykładowych wartości.
Obliczenia w funkcji SROTCL() wykonujemy według wzoru:

 .
.
I odwrotnie, jeśli jest nieujemnym a.e. funkcjonować tak, że  , to istnieje absolutnie ciągła miara prawdopodobieństwa taka, że jest to jej gęstość.
, to istnieje absolutnie ciągła miara prawdopodobieństwa taka, że jest to jej gęstość.
Zastąpienie miary w całce Lebesgue’a:
 ,
,
gdzie jest dowolną funkcją borelowską całkowalną względem miary prawdopodobieństwa.
Dyspersja, rodzaje i właściwości dyspersji. Pojęcie dyspersji
Rozproszenie w statystyce oblicza się jako odchylenie standardowe poszczególnych wartości cechy do kwadratu od średniej arytmetycznej. W zależności od danych początkowych wyznacza się ją za pomocą prostych i ważonych wzorów na wariancję:
1. Prosta różnica(dla danych niezgrupowanych) oblicza się ze wzoru:
![]()
2. Wariancja ważona (dla serii zmian):

gdzie n to częstotliwość (powtarzalność współczynnika X)
Przykład znajdowania wariancji
Na tej stronie opisano standardowy przykład znajdowania wariancji. Możesz także przyjrzeć się innym problemom związanym ze znalezieniem wariancji
Przykład 1. Wyznaczanie wariancji grupowej, średniej grupowej, międzygrupowej i całkowitej
Przykład 2. Znajdowanie wariancji i współczynnika zmienności w tabeli grupującej
Przykład 3. Znajdowanie wariancji w dyskretna seria
Przykład 4. Poniższe dane są dostępne dla grupy 20 uczniów Dział korespondencyjny. Trzeba budować seria interwałowa rozkład cechy, obliczyć średnią wartość cechy i zbadać jej wariancję

Zbudujmy grupowanie interwałowe. Wyznaczmy zakres przedziału korzystając ze wzoru:
![]()
gdzie X max jest maksymalną wartością cechy grupującej; X min – minimalna wartość cechy grupującej; n – liczba przedziałów:
Przyjmujemy n=5. Krok wynosi: h = (192 - 159)/ 5 = 6,6
Utwórzmy grupowanie interwałowe

Do dalszych obliczeń zbudujemy tabelę pomocniczą:

X"i – środek przedziału. (np. środek przedziału 159 – 165,6 = 162,3)
Średni wzrost uczniów określamy za pomocą wzoru na średnią ważoną arytmetyczną:

Wyznaczmy wariancję korzystając ze wzoru:
Formułę można przekształcić w następujący sposób:

Z tego wzoru wynika, że wariancja jest równa różnica między średnią kwadratów opcji a kwadratem i średnią.
Różnica w seria odmian Z w równych odstępach metodą momentów można obliczyć w następujący sposób, korzystając z drugiej właściwości dyspersji (dzielenie wszystkich opcji przez wartość przedziału). Określanie wariancji, obliczony metodą momentów, przy zastosowaniu poniższego wzoru jest mniej pracochłonny:

gdzie i jest wartością przedziału; A jest konwencjonalnym zerem, dla którego wygodnie jest użyć środka przedziału o najwyższej częstotliwości; m1 jest kwadratem momentu pierwszego rzędu; m2 - moment drugiego rzędu
Alternatywna wariancja cechy (jeżeli w populacji statystycznej cecha zmienia się w taki sposób, że istnieją tylko dwie wzajemnie wykluczające się opcje, to taką zmienność nazywamy alternatywną) można obliczyć ze wzoru:

Podstawiając q = 1- p do tego wzoru na dyspersję, otrzymujemy:

Rodzaje wariancji
Całkowita rozbieżność mierzy zmienność cechy w całej populacji jako całości pod wpływem wszystkich czynników powodujących tę zmienność. Jest równy średniemu kwadratowi odchyleń poszczególnych wartości cechy x od ogólnej średniej wartości x i można go zdefiniować jako wariancję prostą lub wariancję ważoną.
Wariancja wewnątrzgrupowa charakteryzuje się zmiennością losową, tj. część zmienności, która wynika z wpływu nieuwzględnionych czynników i nie zależy od atrybutu czynnika, który stanowi podstawę grupy. Rozrzut taki jest równy średniemu kwadratowi odchyleń poszczególnych wartości atrybutu w obrębie grupy X od średniej arytmetycznej grupy i można go obliczyć jako rozproszenie proste lub rozproszenie ważone.
Zatem, miary wariancji wewnątrzgrupowej zmienność cechy w obrębie grupy i określa się ją według wzoru:

gdzie xi jest średnią grupy; ni to liczba jednostek w grupie.
Na przykład wariancje wewnątrzgrupowe, które należy określić w zadaniu badania wpływu kwalifikacji pracowników na poziom wydajności pracy w warsztacie, pokazują zróżnicowanie wydajności w każdej grupie spowodowane wszystkimi możliwymi czynnikami (stan techniczny sprzętu, dostępność narzędzia i materiały, wiek pracowników, pracochłonność itp.), z wyjątkiem różnic w kategorii kwalifikacji (w obrębie grupy wszyscy pracownicy mają takie same kwalifikacje).
Średnia wariancji wewnątrzgrupowych odzwierciedla wariancję losową, czyli tę część wariancji, która wystąpiła pod wpływem wszystkich pozostałych czynników, z wyjątkiem czynnika grupującego. Oblicza się go za pomocą wzoru:

Wariancja międzygrupowa charakteryzuje systematyczną zmienność wynikowej cechy, która wynika z wpływu czynnika-atrybutu, który stanowi podstawę grupy. Jest równy średniemu kwadratowi odchyleń średnich grupowych od średniej ogólnej. Wariancję międzygrupową oblicza się za pomocą wzoru:

Ta strona opisuje standardowy przykład znajdując wariancję, możesz także przyjrzeć się innym problemom, aby ją znaleźć
Przykład 1. Wyznaczanie wariancji grupowej, średniej grupowej, międzygrupowej i całkowitej
Przykład 2. Znajdowanie wariancji i współczynnika zmienności w tabeli grupującej
Przykład 3. Znajdowanie wariancji w szeregu dyskretnym
Przykład 4. Poniższe dane są dostępne dla grupy 20 studentów korespondencyjnych. Należy skonstruować szereg przedziałowy rozkładu cechy, obliczyć średnią wartość cechy i zbadać jej rozproszenie
Zbudujmy grupowanie interwałowe. Wyznaczmy zakres przedziału korzystając ze wzoru:
![]()
gdzie X max jest maksymalną wartością cechy grupującej;
X min – minimalna wartość cechy grupującej;
n – liczba przedziałów:
Przyjmujemy n=5. Krok wynosi: h = (192 - 159)/ 5 = 6,6
Utwórzmy grupowanie interwałowe

Do dalszych obliczeń zbudujemy tabelę pomocniczą:

X"i – środek przedziału. (np. środek przedziału 159 – 165,6 = 162,3)
Średni wzrost uczniów określamy za pomocą wzoru na średnią ważoną arytmetyczną:

Wyznaczmy wariancję korzystając ze wzoru:
Formułę można przekształcić w następujący sposób:

Z tego wzoru wynika, że wariancja jest równa różnica między średnią kwadratów opcji a kwadratem i średnią.
Dyspersja w szeregach wariacyjnych o równych odstępach metodą momentów można obliczyć w następujący sposób, korzystając z drugiej właściwości dyspersji (dzielenie wszystkich opcji przez wartość przedziału). Określanie wariancji, obliczony metodą momentów, przy zastosowaniu poniższego wzoru jest mniej pracochłonny:

gdzie i jest wartością przedziału;
A jest konwencjonalnym zerem, dla którego wygodnie jest użyć środka przedziału o najwyższej częstotliwości;
m1 jest kwadratem momentu pierwszego rzędu;
m2 - moment drugiego rzędu
Alternatywna wariancja cechy (jeżeli w populacji statystycznej cecha zmienia się w taki sposób, że istnieją tylko dwie wzajemnie wykluczające się opcje, to taką zmienność nazywamy alternatywną) można obliczyć ze wzoru:

Podstawiając q = 1- p do tego wzoru na dyspersję, otrzymujemy:

Rodzaje wariancji
Całkowita rozbieżność mierzy zmienność cechy w całej populacji jako całości pod wpływem wszystkich czynników powodujących tę zmienność. Jest równy średniemu kwadratowi odchyleń poszczególnych wartości cechy x od ogólnej średniej wartości x i można go zdefiniować jako wariancję prostą lub wariancję ważoną.
Wariancja wewnątrzgrupowa charakteryzuje się zmiennością losową, tj. część zmienności, która wynika z wpływu nieuwzględnionych czynników i nie zależy od atrybutu czynnika, który stanowi podstawę grupy. Rozrzut taki jest równy średniemu kwadratowi odchyleń poszczególnych wartości atrybutu w obrębie grupy X od średniej arytmetycznej grupy i można go obliczyć jako rozproszenie proste lub rozproszenie ważone.
Zatem, miary wariancji wewnątrzgrupowej zmienność cechy w obrębie grupy i określa się ją według wzoru:

gdzie xi jest średnią grupy;
ni to liczba jednostek w grupie.
Na przykład wariancje wewnątrzgrupowe, które należy określić w problematyce badania wpływu kwalifikacji pracowników na poziom wydajności pracy w warsztacie, pokazują różnice w produkcji w każdej grupie spowodowane przez wszystkie możliwe czynniki(stan techniczny sprzętu, dostępność narzędzi i materiałów, wiek pracowników, intensywność pracy itp.), z wyjątkiem różnic w kategorii kwalifikacji (w obrębie grupy wszyscy pracownicy mają takie same kwalifikacje).
Oprócz badania zmienności cechy w całej populacji często konieczne jest prześledzenie zmian ilościowych cechy w grupach, na które podzielona jest populacja, a także między grupami. Badanie zmienności przeprowadza się poprzez obliczenia i analizy różne rodzaje odchylenia.
Wyróżnia się wariancje całkowite, międzygrupowe i wewnątrzgrupowe.
Całkowita wariancja σ 2 mierzy zmienność cechy w całej populacji pod wpływem wszystkich czynników, które tę zmienność spowodowały.
Wariancja międzygrupowa (δ) charakteryzuje zmienność systematyczną, tj. różnice w wartości badanej cechy powstające pod wpływem czynnika-cechy stanowiącej podstawę grupy. Oblicza się go za pomocą wzoru: 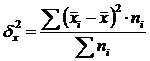 .
.
Wariancja wewnątrzgrupowa (σ) odzwierciedla zmienność losową, tj. część zmienności, która pojawia się pod wpływem nieuwzględnionych czynników i nie zależy od atrybutu czynnika, który stanowi podstawę grupy. Oblicza się go według wzoru: 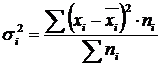 .
.
Średnia wariancji wewnątrzgrupowych:  .
.
Istnieje prawo łączące 3 rodzaje dyspersji. Całkowita wariancja jest równa sumie średniej wariancji wewnątrzgrupowej i międzygrupowej: ![]() .
.
Ten stosunek nazywa się zasada dodawania wariancji.
Szeroko stosowanym wskaźnikiem w analizie jest proporcja wariancji międzygrupowej w wariancji całkowitej. To jest nazwane empiryczny współczynnik determinacji (η 2): .
Nazywa się pierwiastkiem kwadratowym empirycznego współczynnika determinacji empiryczny współczynnik korelacji (η):
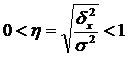 .
.
Charakteryzuje wpływ cechy stanowiącej podstawę grupy na zmienność wynikowej cechy. Empiryczny współczynnik korelacji waha się od 0 do 1.
Zademonstrujmy jego praktyczne zastosowanie na poniższym przykładzie (tabela 1).
Przykład nr 1. Tabela 1 - Wydajność pracy dwóch grup pracowników w jednym z warsztatów NPO Cyclone
Obliczmy średnie i wariancje ogólne i grupowe:
Wstępne dane do obliczenia średniej wariancji wewnątrzgrupowej i międzygrupowej przedstawiono w tabeli. 2.
Tabela 2
Obliczenia i δ 2 dla dwóch grup pracowników.
|
Grupy robotnicze | Liczba pracowników, osób | Średnia, dzieci/zmiana | Dyspersja |
| Ukończone szkolenie techniczne | 5 | 95 | 42,0 |
| Osoby, które nie ukończyły szkolenia technicznego | 5 | 81 | 231,2 |
| Wszyscy pracownicy | 10 | 88 | 185,6 |
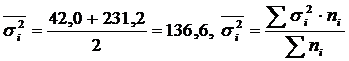 .
.
Wariancja międzygrupowa
Całkowita wariancja:
Zatem empiryczny współczynnik korelacji: .
Oprócz różnic w cechach ilościowych można zaobserwować również różnice w cechach jakościowych. Badanie zmienności osiąga się poprzez obliczenie następujących typów wariancji:
Wewnątrzgrupowe rozproszenie udziału określa wzór
Gdzie n ja– liczba jednostek w oddzielnych grupach.Udział badanej cechy w całej populacji, który określa się wzorem:
Te trzy typy wariancji są ze sobą powiązane w następujący sposób:
Ta relacja wariancji nazywa się twierdzeniem o dodawaniu wariancji udziału cechy.
Jednak sama ta cecha nie wystarczy do badania zmiennej losowej. Wyobraźmy sobie dwóch strzelców strzelających do celu. Jeden strzela celnie i trafia blisko środka, a drugi... po prostu się bawi i nawet nie celuje. Ale najśmieszniejsze jest to, że on przeciętny wynik będzie dokładnie taki sam jak pierwszego strzelca! Sytuację tę tradycyjnie ilustrują następujące zmienne losowe:
Oczekiwanie matematyczne „snajpera” jest jednak równe , dla „osoby interesującej”: – także wynosi zero!
Należy zatem określić ilościowo, jak daleko rozsiany pociski (wartości zmiennych losowych) względem środka celu ( oczekiwanie matematyczne). dobrze więc rozpraszanie przetłumaczone z łaciny nie jest niczym innym jak dyspersja .
Zobaczmy, jak wyznacza się tę charakterystykę liczbową na jednym z przykładów z pierwszej części lekcji: 
Tam znaleźliśmy rozczarowujące oczekiwania matematyczne dla tej gry, a teraz musimy obliczyć jej wariancję, która oznaczony przez Poprzez .
Dowiedzmy się, jak bardzo wygrane/przegrane są „rozproszone” w stosunku do wartości średniej. Oczywiście w tym celu musimy obliczyć różnice między losowe wartości zmiennych i jej oczekiwanie matematyczne:
–5 – (–0,5) = –4,5
2,5 – (–0,5) = 3
10 – (–0,5) = 10,5
Teraz wydaje się, że trzeba podsumować wyniki, ale ten sposób nie jest odpowiedni - z tego powodu, że wahania w lewo znoszą się wzajemnie z wahaniami w prawo. Na przykład strzelanka „amatorska”. (przykład powyżej) różnice będą ![]() , a po dodaniu dadzą zero, więc nie otrzymamy żadnego oszacowania rozrzutu jego strzału.
, a po dodaniu dadzą zero, więc nie otrzymamy żadnego oszacowania rozrzutu jego strzału.
Aby obejść ten problem, możesz rozważyć moduły różnice, ale z powodów technicznych podejście zakorzeniło się, gdy je podniesiemy do kwadratu. Wygodniej jest sformułować rozwiązanie w tabeli: 
I tu aż prosi się o kalkulację Średnia ważona wartość kwadratów odchyleń. Co to jest? To jest ich wartość oczekiwana, który jest miarą rozproszenia:
![]() – definicja odchylenia. Z definicji od razu wynika, że wariancja nie może być ujemna– uwaga do ćwiczeń!
– definicja odchylenia. Z definicji od razu wynika, że wariancja nie może być ujemna– uwaga do ćwiczeń!
Pamiętajmy, jak znaleźć wartość oczekiwaną. Pomnóż kwadraty różnic przez odpowiednie prawdopodobieństwa (kontynuacja tabeli):
– w przenośni jest to „siła uciągu”,
i podsumuj wyniki:
Nie sądzicie, że w porównaniu do wygranych wynik okazał się za duży? Zgadza się – podnieśliśmy to do kwadratu i wracając do wymiaru naszej gry, musimy wyciągnąć Pierwiastek kwadratowy. Ta ilość nazywa się odchylenie standardowe
i jest oznaczony grecką literą „sigma”:
Ta wartość jest czasami nazywana odchylenie standardowe .
Jakie jest jego znaczenie? Jeśli odejdziemy od oczekiwań matematycznych w lewo i w prawo o odchylenie standardowe: ![]()
– wówczas najbardziej prawdopodobne wartości zmiennej losowej zostaną „skoncentrowane” na tym przedziale. Co faktycznie obserwujemy:
Tak się jednak składa, że analizując rozpraszanie, prawie zawsze operujemy pojęciem dyspersji. Zastanówmy się, co to oznacza w odniesieniu do gier. Jeśli w przypadku strzał mówimy o „celności” trafień względem środka celu, to tutaj rozrzut charakteryzuje się dwiema rzeczami:
Po pierwsze, oczywiste jest, że wraz ze wzrostem zakładów zwiększa się również rozrzut. Tak więc, jeśli na przykład zwiększymy 10 razy, to oczekiwanie matematyczne wzrośnie 10 razy, a wariancja wzrośnie 100 razy (ponieważ jest to wielkość kwadratowa). Pamiętaj jednak, że same zasady gry się nie zmieniły! Zmieniły się tylko stawki, z grubsza mówiąc, zanim postawiliśmy 10 rubli, teraz jest 100.
Drugą, bardziej interesującą kwestią jest to, że styl gry charakteryzuje się wariancją. Napraw psychicznie zakłady na grę na pewnym poziomie i zobaczmy co jest co:
Gra o niskiej wariancji jest grą ostrożną. Gracz ma tendencję do wybierania najbardziej niezawodnych schematów, na których nie traci/nie wygrywa za jednym razem. Na przykład system czerwony/czarny w ruletce (patrz przykład 4 artykułu Zmienne losowe) .
Gra o dużej wariancji. Często jest nazywana dyspersyjny gra. Jest to ryzykowny lub agresywny styl gry, w którym gracz wybiera schematy „adrenaliny”. Przynajmniej pamiętajmy „Martyngał”, w którym stawki są o rząd wielkości większe niż „cicha” gra z poprzedniego punktu.
Sytuacja w pokerze jest orientacyjna: istnieją tzw obcisły graczy, którzy wydają się być ostrożni i „niepewni” w stosunku do swoich zawodników środki do gier (forsa). Nic dziwnego, że ich bankroll nie podlega znaczącym wahaniom (niska wariancja). I odwrotnie, jeśli gracz ma dużą wariancję, jest agresorem. Często podejmuje ryzyko, dokonuje dużych zakładów i może albo rozbić ogromny bank, albo przegrać w drobny mak.
To samo dzieje się na rynku Forex i tak dalej – przykładów jest mnóstwo.
Co więcej, we wszystkich przypadkach nie ma znaczenia, czy gra się za grosze, czy o tysiące dolarów. Każdy poziom ma swoich graczy o niskim i wysokim rozproszeniu. Cóż, dla średnie wygrane, jak pamiętamy, „odpowiedzi” wartość oczekiwana.
Prawdopodobnie zauważyłeś, że znajdowanie wariancji jest długim i żmudnym procesem. Ale matematyka jest hojna:
Wzór na znalezienie wariancji
Ta formuła wynika bezpośrednio z definicji wariancji i od razu ją stosujemy. Skopiuję znak z naszą grą na górze: 
i znalezione oczekiwanie matematyczne.
Obliczmy wariancję w drugi sposób. Najpierw znajdźmy oczekiwanie matematyczne – kwadrat zmiennej losowej. Przez wyznaczanie oczekiwań matematycznych:
Zatem zgodnie ze wzorem:
Jak to mówią, poczuj różnicę. A w praktyce oczywiście lepiej zastosować wzór (chyba że warunek wymaga inaczej).
Opanujemy technikę rozwiązywania i projektowania:
Przykład 6

Znajdź jego matematyczne oczekiwanie, wariancję i odchylenie standardowe.
To zadanie można znaleźć wszędzie i z reguły nie ma znaczącego znaczenia.
Można sobie wyobrazić kilka żarówek z liczbami, które zapalają się w domu wariatów z pewnym prawdopodobieństwem :)
Rozwiązanie: Wygodnie jest podsumować podstawowe obliczenia w tabeli. Najpierw zapisujemy dane początkowe w dwóch górnych wierszach. Następnie obliczamy iloczyny, a na koniec sumy w prawej kolumnie: 
Właściwie prawie wszystko jest gotowe. Trzecia linia pokazuje gotowe oczekiwanie matematyczne: ![]() .
.
Wariancję obliczamy korzystając ze wzoru:
I na koniec odchylenie standardowe:
– Osobiście zazwyczaj zaokrąglam liczbę do 2 miejsc po przecinku.
Wszystkie obliczenia można przeprowadzić na kalkulatorze, a jeszcze lepiej - w Excelu:
Trudno się tu pomylić :)
Odpowiedź:
Ci, którzy chcą, mogą jeszcze bardziej uprościć swoje życie i skorzystać z mojego kalkulator (próbny), które nie tylko natychmiast rozwiążą to zadanie, ale także zbuduje grafika tematyczna (wkrótce tam dotrzemy). Program może być pobrać z biblioteki– jeśli pobrałeś przynajmniej jeden materiał edukacyjny lub uzyskać Inny sposób. Dziękujemy za wsparcie projektu!
Kilka zadań dot niezależna decyzja:
Przykład 7
Oblicz wariancję zmiennej losowej z poprzedniego przykładu z definicji.
I podobny przykład:
Przykład 8
Dyskretna zmienna losowa jest określona przez prawo dystrybucji:

Tak, wartości zmiennych losowych mogą być dość duże (przykład z prawdziwej pracy), a tutaj, jeśli to możliwe, użyj Excela. Swoją drogą, jak w przykładzie 7 – jest szybciej, pewniej i przyjemniej.
Rozwiązania i odpowiedzi na dole strony.
Pod koniec drugiej części lekcji przyjrzymy się jeszcze jednemu typowe zadanie, można nawet powiedzieć, mały rebus:
Przykład 9
Dyskretna zmienna losowa może przyjmować tylko dwie wartości: i , oraz . Znane jest prawdopodobieństwo, oczekiwanie matematyczne i wariancja.
Rozwiązanie: Zacznijmy od nieznanego prawdopodobieństwa. Ponieważ zmienna losowa może przyjmować tylko dwie wartości, suma prawdopodobieństw odpowiednich zdarzeń wynosi:
i od tego czasu .
Pozostaje tylko znaleźć..., łatwo powiedzieć :) No ale cóż, zaczynamy. Z definicji oczekiwań matematycznych: ![]() – zastąpić znane ilości:
– zastąpić znane ilości:
![]() – i nic więcej nie da się wycisnąć z tego równania, poza tym, że można je przepisać w zwykłym kierunku:
– i nic więcej nie da się wycisnąć z tego równania, poza tym, że można je przepisać w zwykłym kierunku: ![]()

Lub: ![]()
O dalsze działania, myślę, że możesz się domyślić. Skomponujmy i rozwiążmy system: 
Dziesiętne- to oczywiście całkowita hańba; pomnóż oba równania przez 10: 
i podziel przez 2: 
To jest lepsze. Z pierwszego równania wyrażamy: ![]() (to jest łatwiejszy sposób)– podstawiamy do drugiego równania:
(to jest łatwiejszy sposób)– podstawiamy do drugiego równania:
![]()
Budujemy do kwadratu i dokonaj uproszczeń: 
Pomnożyć przez: 
Rezultat był równanie kwadratowe, znajdujemy jego wyróżnik:
- Świetnie!
i otrzymujemy dwa rozwiązania:
1) jeśli ![]() , To
, To ![]() ;
;
2) jeśli ![]() , To .
, To .
Pierwsza para wartości spełnia warunek. Z dużym prawdopodobieństwem wszystko się zgadza, ale mimo to zapiszmy prawo dystrybucji: 
i wykonaj sprawdzenie, a mianowicie znajdź oczekiwanie:







