Intensywność przepływu usług:
1. Intensywność obciążenia.
ρ = λ t obs = 120 1/60 = 2
Natężenie obciążenia ρ=2 pokazuje stopień spójności strumieni wejściowych i wyjściowych żądań kanału serwisowego i określa stabilność systemu kolejka.
3. Prawdopodobieństwo, że kanał jest wolny(procent przestoju kanału).
W rezultacie w ciągu godziny 12% kanału będzie bezczynne, czas bezczynności wynosi t pr = 7,1 min.
Prawdopodobieństwo, że usługa:
1 kanał zajęty:
p 1 = ρ 1 /1! p 0 = 2 1 /1! 0,12 = 0,24
2 kanały są zajęte:
p 2 = ρ 2 /2! p 0 = 2 2 /2! 0,12 = 0,24
3 kanały są zajęte:
p 3 = ρ 3 /3! p 0 = 2 3 /3! 0,12 = 0,16
4. Odsetek wniosków odrzuconych.
![]()
Oznacza to, że 3% otrzymanych wniosków nie zostaje przyjętych do obsługi.
5. Prawdopodobieństwo obsługi przychodzących żądań.
W systemach, w których występują awarie, zdarzenia awaryjno-obsługowe stanowią kompletną grupę zdarzeń, zatem:
p otwarte + p obs = 1
Względna przepustowość: Q = p obs.
p obs = 1 - p otwarty = 1 - 0,0311 = 0,97
Dzięki temu 97% otrzymanych wniosków zostanie obsłużonych. Akceptowalny poziom usług powinien wynosić powyżej 90%.
6. Średnia liczba kanałów zajętych przez usługę.
n з = ρ p obs = 2 0,97 = 1,9 kanałów
Średnia liczba nieaktywnych kanałów.
n pr = n - n z = 3 - 1,9 = 1,1 kanałów
7. Stopień wykorzystania kanałów usług.
![]()
W rezultacie system jest zajęty konserwacją w 60%.
8. Absolutna przepustowość.
A = p obs λ = 0,97 120 = 116,3 żądań/godz.
.
t pr = p otwarte t obs = 0,0311 0,0166 = 0 godzina.
10. Średnia liczba wniosków w kolejce.
![]()
jednostki
(średni czas oczekiwania na obsługę wniosku w kolejce). ![]() godzina.
godzina.
12. Średnia liczba obsłużonych wniosków.
L obs = ρ Q = 2 · 0,97 = 1,94 jednostki.
13. Średnia liczba aplikacji w systemie.
L CMO = Loch + L obs = 0,51 + 1,94 = 2,45 jednostki.
13. Średni czas przebywania aplikacji w CMO.
![]() godzina.
godzina.
Liczba wniosków odrzuconych w ciągu godziny: λ p 1 = 4 wnioski na godzinę.
Nominalna wydajność QS: 3 / 0,0166 = 181 zastosowań na godzinę.
Rzeczywista wydajność SMO: 116,3 / 181 = 64% wydajności nominalnej.
W dalszym ciągu będziemy stosować następujący zapis dla średniego czasu oczekiwania w kolejce żądań z klasy priorytetu P - Wp, a średni czas spędzony w systemie dla wymagań tej klasy - Tp:
Skoncentrujemy się na systemach o względnym priorytecie. Rozważmy proces od momentu nadejścia określonego żądania z klasy priorytetu P. Będziemy dalej nazywać to wymaganie etykietą. Pierwszy składnik opóźnienia oznaczonego żądania jest związany z żądaniem, które trafia na serwer. Składnik ten jest równy pozostałemu czasowi obsługi innego zgłoszenia. Oznaczmy teraz i dalej będziemy używać tego zapisu, średnie opóźnienie oznaczonego wymagania związane z obecnością innego wymagania w obsłudze W 0. Znajomość rozkładu czasu pomiędzy sąsiadującymi przyjazdami wymagania wejściowe dla każdej klasy priorytetu zawsze możesz obliczyć tę wartość. Przy założeniu prawa Poissona dla przepływu aplikacji każdej klasy możemy pisać
 .
.
Drugi składnik czasu oczekiwania na oznakowane wymaganie jest określony przez fakt, że przed oznakowanym wymaganiem obsługiwane są inne żądania, w których oznakowane wymaganie znajduje się w kolejce. Oznaczmy dalej liczbę wymagań z klasy I, który przechwycił zaznaczony wymóg w kolejce (z klasy P) i które są podawane przed nim Skakać. Średnia tej liczby określi wartość średniej tej składowej opóźnienia
Trzeci składnik opóźnienia jest związany z żądaniami, które nadeszły po nadejściu oznaczonego żądania, ale zostały obsłużone przed nim. Oznaczmy liczbę takich wymagań M ip. Średnia wartość tej składowej opóźnienia jest znajdowana podobnie i wynosi
Dodając wszystkie trzy składniki, okazuje się, że średni czas oczekiwania w kolejce na otagowane żądanie jest określony przez wzór
Oczywistym jest, że niezależnie od dyscypliny usługowej, ilość wymagań Skakać I M ip w systemie nie może być dowolna, dlatego istnieje pewien zestaw zależności łączących opóźnienia dla każdej klasy priorytetu. Znaczenie tych relacji dla QS pozwala nam nazwać je PRAWAMI OCHRONY. Podstawą praw ochrony opóźnień jest fakt, że niedokończona praca w dowolnym QS w dowolnym przedziale czasu zajętości nie zależy od kolejności usług, jeśli system jest konserwatywny (wymagania nie znikają w systemie, a serwer nie pozostaje bezczynny, gdy kolejka nie jest pusta).
Rozkład czasów oczekiwania zależy w dużej mierze od kolejności obsługi, ale jeśli dyscyplina usług wybiera wymagania niezależnie od czasu ich obsługi (lub dowolnej miary zależnej od czasu obsługi), to rozkład liczby żądań i czasu oczekiwania w system jest niezmienny pod względem kolejności doręczeń.
Dla QS typu M/G/1 można wykazać, że dla dowolnej dyscypliny usług musi być spełniona następująca ważna równość:

Ta równość oznacza, że ważona suma czasów oczekiwania nigdy się nie zmienia, niezależnie od tego, jak złożona i sprytna jest dyscyplina usług. Jeśli w przypadku niektórych wymagań można zmniejszyć opóźnienie, w przypadku innych natychmiast ono wzrośnie.
Aby uzyskać więcej wspólny system przy dowolnym rozkładzie czasu nadejścia wymagań G/G/1 prawo konserwatorskie można zapisać w postaci
![]() .
.
Ogólne znaczenie tej zależności jest takie, że suma ważona czasów opóźnienia pozostaje stała. Tyle, że po prawej stronie widnieje różnica pomiędzy średnią pracą w toku a pozostałym czasem obsługi. Jeśli założymy naturę Poissona przepływu wejściowego, wówczas wyrażenie określające pracę w toku można zapisać jako
Podstawiając je do poprzedniego wyrażenia, otrzymujemy od razu podane wcześniej prawo zachowania dla QS typu M/G/1.
Rozważmy teraz obliczenie średniego czasu oczekiwania na QS z obsługą w kolejności priorytetów określonej przez funkcję priorytetu
Rysunek 1 przedstawia schemat działania QS z taką dyscypliną usług: żądanie przychodzące jest kolejkowane po lewej stronie żądania z równym lub większym priorytetem.

Ryż. 1 CMO z usługą priorytetową.
Skorzystajmy ze wzoru na Wp. Na podstawie działającego mechanizmu możemy od razu pisać

Wszystkie zgłoszenia o wyższym priorytecie niż zaznaczony priorytet zostaną obsłużone wcześniej. Ze wzoru Little'a wynika liczba wymagań klasowych I w kolejce będzie równa:
Żądania o klasach o wyższym priorytecie, które wejdą do systemu po otagowanym żądaniu znajdującym się w kolejce, również zostaną obsłużone przed nim. Ponieważ oznaczone wymaganie będzie średnio w kolejce Wp sekund, wówczas liczba takich żądań będzie równa
Bezpośrednio ze wzoru (*) otrzymujemy:

Ten układ równań można rozwiązać rekurencyjnie, zaczynając od W 1, W 2 itp.

Otrzymany wzór pozwala obliczyć charakterystykę jakości usług dla wszystkich klas priorytetów. Na rysunku 7.2. pokazuje, jak zmienia się znormalizowana wartość czasu oczekiwania w kolejce dla QS z pięcioma klasami priorytetów przy równym natężeniu przepływu żądań dla każdej klasy priorytetu i równym średnim czasie obsługi żądań w każdej klasie (dolny rysunek przedstawia krzywe dla niskich wartości obciążenia).

Rysunek 2. Usługa w kolejności priorytetów w przypadku priorytetów względnych (P=5, l P = l/5, ).
Szczególnym zadaniem jest określenie praw rozkładu czasu oczekiwania.
Rozważmy teraz system z priorytetami bezwzględnymi i usługą w kolejności priorytetów z usługą dodatkową. Zastosujmy podejście zupełnie podobne do tego, które omówiliśmy wcześniej. Średnie opóźnienie w systemie otagowanego wymagania również składa się z trzech składników: pierwszy składnik to średni czas obsługi, drugi to opóźnienie spowodowane obsługą żądań o równym lub wyższym priorytecie, jakie otagowane wymaganie znalazło w systemie. Trzecim składnikiem średniego opóźnienia otagowanego wymagania jest opóźnienie spowodowane wszelkimi żądaniami, które wchodzą do systemu przed opuszczeniem otagowanego wymagania i mają ściśle wyższy priorytet. Opisując wszystkie te trzy składowe całkowitego czasu spędzonego w systemie otrzymujemy
 .
.
Bardzo ciekawym zadaniem jest wybór priorytetów dla aplikacji. różne zajęcia. Ponieważ obowiązuje prawo ochrony, optymalizacja ma sens tylko przy uwzględnieniu dodatkowych atrybutów każdej klasy wymagań. Załóżmy, że każdą sekundę opóźnienia aplikacji o klasie priorytetu p można oszacować pewnym kosztem C str. Wówczas średni koszt sekundy opóźnienia dla systemu można wyrazić w postaci średniej liczby żądań każdej klasy obecnej w systemie

Rozwiążmy problem znalezienia dyscypliny usług o względnych priorytetach dla systemu M/G/1, która minimalizuje średni koszt opóźnień C. Niech tak będzie P klasy priorytetów zgłoszeń z określoną częstotliwością napływu i średnim czasem obsługi. Przejdźmy do lewa strona stała suma i ekspres prawa strona poprzez znane parametry

Zadanie polega na zminimalizowaniu sumy po prawej stronie tej równości poprzez wybór odpowiedniej dyscypliny obsługi, tj. wybór sekwencji indeksów P.
Oznaczmy

W tym zapisie problem wygląda następująco: musimy zminimalizować sumę produktów objętych
![]()
Warunek niezależności sumy funkcji g s o wyborze dyscypliny służby decyduje prawo zachowania. Innymi słowy, problem polega na minimalizacji pola pod krzywą iloczynu dwóch funkcji, pod warunkiem, że pole pod krzywą jednej z nich jest stałe.
Rozwiązaniem jest uporządkowanie najpierw sekwencji wartości f s: ![]() .
.
A potem wybieramy dla każdego f s jego znaczenie g s, tak aby zminimalizować sumę swoich produktów. Jest to intuicyjnie jasne optymalna strategia wybór polega na wyborze najniższa wartość g s dla największych f s, to dla pozostałych wartości należy postępować w ten sam sposób. Od g s=W p r str, wówczas minimalizacja sprowadza się do minimalizacji średnich wartości opóźnienia. Zatem rozwiązaniem rozważanego problemu optymalizacji jest to, że spośród wszystkich możliwych dyscyplin usług o względnym priorytecie minimalny średni koszt zapewnia dyscyplina o uporządkowanych priorytetach zgodnie z nierównościami
![]() .
.
System kolejkowy nazywany jest systemem oczekującym, jeśli żądanie stwierdzające, że wszystkie kanały są zajęte, trafia do kolejki i czeka, aż jakiś kanał stanie się wolny.
Jeżeli czas oczekiwania na wniosek w kolejce jest nieograniczony, wówczas system nazywa się „systemem czystego czekania”. Jeśli jest ograniczony pewnymi warunkami, system nazywa się „systemem typu mieszanego”. Jest to przypadek pośredni pomiędzy czystym systemem z awariami i czystym systemem z oczekiwaniem.
W praktyce największym zainteresowaniem cieszą się systemy typu mieszanego.
Mogą istnieć ograniczenia dotyczące oczekiwania różne typy. Często zdarza się, że narzucane jest ograniczenie czasu oczekiwania na wniosek w kolejce; uważa się, że jest on ograniczony z góry pewnym okresem, który może być ściśle określony lub losowy. W takim przypadku ograniczony jest jedynie czas oczekiwania w kolejce, a rozpoczęta usługa zostaje zakończona, niezależnie od tego, jak długo trwało oczekiwanie (np. klient u fryzjera, po zajęciu miejsca na krześle, zwykle nie pozostawić do końca usługi). W przypadku innych problemów bardziej naturalne jest nałożenie ograniczenia nie na czas oczekiwania w kolejce, ale na całkowity czas przebywania żądania w systemie (np. cel powietrzny może przebywać w strefie ostrzału tylko przez określony czas i opuszcza ją niezależnie od tego, czy ostrzał się skończył, czy nie). Wreszcie można rozważyć taki system mieszany (najbliższy rodzajowi przedsiębiorstw handlowych sprzedających przedmioty niepotrzebne), w którym wniosek trafia do kolejki tylko wtedy, gdy długość kolejki nie jest zbyt długa. W tym przypadku nałożone jest ograniczenie liczby wniosków w kolejce.
W systemach oczekujących znaczącą rolę odgrywa tzw. „dyscyplina kolejkowa”. Oczekujące wnioski można wezwać do obsługi na zasadzie „kto pierwszy, ten lepszy” (kto pierwszy, ten lepszy) lub w sposób losowy i niezorganizowany. Istnieją systemy kolejkowe „z zaletami”, w których niektóre żądania są obsługiwane w sposób preferencyjny w stosunku do innych („generałowie i pułkownicy poza kolejnością”).
Każdy typ systemu oczekiwania ma swoją własną charakterystykę i teoria matematyczna. Wiele z nich opisano na przykład w książce V.V. Gnedenki „Wykłady z teorii kolejkowania”.
Tutaj skupimy się tylko na najprostszym przypadku systemu mieszanego, który jest naturalnym uogólnieniem problemu Erlanga dla systemu z awariami. W tym przypadku wyprowadzimy równania różniczkowe podobne do równań Erlanga oraz wzory na prawdopodobieństwa stanów w stanie ustalonym podobne do wzorów Erlanga.
Rozważmy mieszany system kolejkowania z kanałami o godz następujące warunki. Wejście systemowe odbiera najprostszy przepływ żądań z gęstością. Czas obsługi jednego zgłoszenia jest orientacyjny, z parametrem. Żądanie, które stwierdza, że wszystkie kanały są zajęte, zostaje umieszczone w kolejce i oczekuje na obsługę; czas oczekiwania jest ograniczony do pewnego okresu; Jeżeli wniosek nie zostanie przyjęty do obsługi przed upływem tego terminu, opuszcza kolejkę i pozostaje bezobsługowy. Okres oczekiwania będzie uznawany za losowy i rozłożony zgodnie z prawem wykładniczym
gdzie parametr jest odwrotnością średniego czasu oczekiwania:
; ![]() .
.
Parametr jest całkowicie podobny do parametrów zarówno przepływu żądania, jak i „przepływu zwolnienia”. Można to interpretować jako gęstość „potoku odlotów” wniosku stojącego w kolejce. Rzeczywiście, wyobraźmy sobie aplikację, która nie robi nic innego, jak tylko dołącza do kolejki i czeka w niej, aż upłynie okres oczekiwania, po czym opuszcza i natychmiast ponownie dołącza do kolejki. Wtedy „spływ odlotów” takiego wniosku z kolejki będzie miał gęstość .
Oczywiście, gdy system typu mieszanego zamienia się w czysty system z awariami; kiedy zamienia się w czysty system z czekaniem.
Należy zauważyć, że w przypadku wykładniczego prawa rozkładu czasu oczekiwania przepustowość systemu nie zależy od tego, czy aplikacje są obsługiwane w kolejce, czy w kolejności losowej: dla każdej aplikacji prawo rozkładu pozostałego czasu oczekiwania nie zależy od tego, jak długo wniosek już znalazł się w kolejce.
Dzięki założeniu o charakterze Poissona wszelkich przepływów zdarzeń prowadzących do zmian stanów układu, zachodzący w nim proces będzie miał charakter markowski. Napiszmy równania na prawdopodobieństwa stanów układu. Aby to zrobić, przede wszystkim podajemy te stany. Będziemy je numerować nie według liczby zajętych kanałów, ale według liczby aplikacji powiązanych z systemem. Zapytanie nazwiemy „powiązanym z systemem”, jeśli jest ono w stanie konserwacji lub oczekuje w kolejce. Możliwe stany systemu będą następujące:
Żaden kanał nie jest zajęty (brak kolejki),
Dokładnie jeden kanał jest zajęty (brak kolejki),
Dokładnie kanały są zajęte (brak kolejki),
Wszystkie kanały są zajęte (brak kolejki),
Wszystkie kanały są zajęte, jedna aplikacja czeka w kolejce,
Wszystkie kanały są zajęte, wnioski czekają w kolejce,
Liczba wniosków stojących w kolejce w naszych warunkach może być dowolnie duża. Zatem system ma nieskończony (aczkolwiek przeliczalny) zbiór stanów. W związku z tym liczba osób je opisujących równania różniczkowe będzie również nieskończony.
Oczywiście pierwsze równania różniczkowe nie będą się w żaden sposób różnić od odpowiadających im równań Erlanga:

Różnica między nowymi równaniami a równaniami Erlanga zacznie się od . Rzeczywiście, system z awariami może jedynie przejść do stanu ze stanu; Jeśli chodzi o system oczekujący, może on przejść do stanu nie tylko z, ale także z (wszystkie kanały są zajęte, jedno żądanie znajduje się w kolejce).
Utwórzmy równanie różniczkowe dla . Ustalmy moment i znajdźmy prawdopodobieństwo, że system będzie w stanie w tej chwili. Można to zrobić na trzy sposoby:
1) w tej chwili system był już w stanie, ale w tym czasie go nie opuścił (nie wpłynęło ani jedno żądanie i żaden z kanałów nie stał się wolny);
2) w chwili, gdy system znajdował się w stanie, i z biegiem czasu przeszedł do stanu (nadeszły jedno żądanie);
3) w momencie, w którym system znajdował się w stanie (wszystkie kanały są zajęte, jedno żądanie znajduje się w kolejce) i w czasie, w którym do niego doszło (albo jeden kanał stał się wolny i zajęło go żądanie stojące w kolejce, albo żądanie stojąc w kolejce pozostawionej ze względu na koniec okresu).
Obliczmy teraz dla dowolnego - prawdopodobieństwo, że w danej chwili wszystkie kanały będą zajęte i dokładnie tyle wniosków będzie w kolejce. To zdarzenie może ponownie nastąpić na trzy sposoby:
1) w chwili, gdy system był już w stanie i przez ten czas stan ten nie uległ zmianie (oznacza to, że nie przyszła ani jedna aplikacja, ani jedna kropla nie została wypuszczona ani żadna z aplikacji nie stała w kolejce) lewy);
2) w chwili, gdy system był w danym stanie, a z biegiem czasu przeszedł do tego stanu (tj. nadeszło jedno żądanie);
3) w momencie, w którym system znajdował się w danym stanie, oraz w czasie, w którym przeszedł do tego stanu (w tym celu albo jeden z kanałów musi się zwolnić i wtedy zajmie go jedna z aplikacji stojących w kolejce, albo wniosków stojących w kolejce musi opuścić ze względu na koniec terminu).
Stąd:
W ten sposób otrzymaliśmy układ prawdopodobieństw stanu nieskończona liczba równania różniczkowe:
 (19.10.1)
(19.10.1)
Równania (19.10.1) są naturalnym uogólnieniem równań Erlanga na przypadek układu typu mieszanego z ograniczonym czasem oczekiwania. Parametry w tych równaniach mogą być stałe lub zmienne. Całkując układ (19.10.1) należy wziąć pod uwagę, że chociaż teoretycznie liczba możliwych stanów układu jest nieskończona, w praktyce w miarę ich wzrostu prawdopodobieństwa stają się zaniedbywalne, a odpowiadające im równania można odrzucić.
Wyprowadźmy wzory podobne do wzorów Erlanga na prawdopodobieństwa stanów systemu w trybie pracy w stanie ustalonym (at ). Z równań (19.10.1), zakładając, że wszystkie stałe i wszystkie pochodne są równe zeru, otrzymujemy układ równania algebraiczne:
 (19.10.2)
(19.10.2)
Musisz dodać do nich warunek:
Znajdźmy rozwiązanie dla systemu (19.10.2).
W tym celu stosujemy tę samą technikę, którą stosowaliśmy w przypadku układu z awariami: rozwiążmy pierwsze równanie względnie, podstawimy je do drugiego itd. Dla dowolnego , tak jak w przypadku układu z awariami, rozwiązujemy uzyskać:
Przejdźmy do równań dla ![]() . W ten sam sposób otrzymujemy:
. W ten sam sposób otrzymujemy:
 ,
,
 ,
,
i ogólnie dla każdego
 . (19.10.5)
. (19.10.5)
Obydwa wzory (19.10.4) i (19.10.5) uwzględniają prawdopodobieństwo jako czynnik. Wyznaczmy to z warunku (19.10.3). Podstawiając wyrażenia (19.10.4) i (19.10.5) za i do niego, otrzymujemy:
 ,
,
 . (19.10.6)
. (19.10.6)
Przekształćmy wyrażenia (19.10.4), (19.10.5) i (19.10.6), wprowadzając do nich zamiast gęstości „zredukowane” gęstości:
 (19.10.7)
(19.10.7)
Parametry i wyrażają odpowiednio średnią liczbę wniosków i średnią liczbę wyjść wniosku stojącego w kolejce w przeliczeniu na średni czas obsługi jednego wniosku.
W nowym zapisie wzory (19.10.4), (19.10.5) i (19.10.6) przyjmą postać:
 ; (19.10.9)
; (19.10.9)
 . (19.10.10)
. (19.10.10)
Podstawiając (19.10.10) do (19.10.8) i (19.10.9) otrzymujemy końcowe wyrażenia na prawdopodobieństwa stanów układu:
 ; (19.10.11)
; (19.10.11)
 . (19.10.12)
. (19.10.12)
Znając prawdopodobieństwa wszystkich stanów systemu, możemy łatwo określić inne interesujące nas cechy, w szczególności prawdopodobieństwo, że żądanie pozostawi system bez obsługi. Wyznaczmy to na podstawie następujących rozważań: w stanie ustalonym prawdopodobieństwo, że wniosek opuści system bez obsługi, to nic innego jak stosunek średniej liczby wniosków opuszczających kolejkę w jednostce czasu do średniej liczby wniosków wpływających na jednostkę czasu. Znajdźmy średnią liczbę wniosków opuszczających kolejkę w jednostce czasu. Aby to zrobić, najpierw obliczamy matematyczne oczekiwanie liczby aplikacji w kolejce:
 . (19.10.13)
. (19.10.13)
Aby otrzymać należy pomnożyć przez średnią „gęstość odlotów” jednego wniosku i podzielić przez średnią gęstość wniosków, czyli pomnożyć przez współczynnik
Przeanalizujmy działanie n-kanałowego (n > 1) QS z oczekiwaniem, na którego wejście odbierany jest najprostszy przepływ żądań P wejście z intensywnością. Zakłada się również, że przepływ usług w każdym kanale jest najprostszy i ma intensywność µ. Nie ma ograniczeń co do długości kolejki, jednak czas oczekiwania na każdy wniosek w kolejce jest ograniczony losowym okresem T Fajny o wartości średniej, po przekroczeniu której żądanie pozostawia system bez obsługi. Przedział czasu T Fajny jest ciągłą zmienną losową, która może przyjmować dowolną wartość dodatnią i oczekiwanie matematyczne Który.
Jeśli ten przepływ jest Poissona, to proces zachodzący w QS będzie procesem Markowskim.
Takie systemy często spotyka się w praktyce. Nazywa się je czasami „chętnymi” systemami licytacji.
Ponumerujmy stany QS liczbą aplikacji w systemie, zarówno w obsłudze, jak i w kolejce: S k (k = 0,1,…n) - k aplikacje w serwisie (k kanały są zajęte, nie ma kolejki), S n+r (r = 1,2,…) - N aplikacje w serwisie (wszystkie N kanały są zajęte) i r aplikacji w kolejce.
Zatem QS może znajdować się w jednym z nieskończonej liczby stanów.
Wykres stanu oznaczonego pokazano na rys. 1.

Ryż. 1.
QS przechodzi od stanu do stanu od lewej do prawej pod wpływem tego samego przychodzącego przepływu aplikacji P wejście z intensywnością. W konsekwencji gęstości prawdopodobieństwa tych przejść
k-1,k = , k = 1,2,… (1)
Przejście QS ze stanu bez kolejki S k , k = 1,…,n, do stanu sąsiadującego z lewą stroną S k-1 , (k = 1,…,n)(w którym również nie będzie kolejki) następuje pod wpływem całkowitego przepływu składającego się z k potoków usług zajętych kanałów, których natężenie, będące sumą natężeń zsumowanych potoków usług, jest równe kµ. Dlatego pod strzałkami po lewej stronie od stanu sn do stanu s 0 wskazane są gęstości prawdopodobieństwa przejścia
k, k-1 =kµ, k = 1,…,n (2)
W systemie w stanie z kolejką S n+r , r = 1,2,…, obowiązuje przepływ całkowity – wynik superpozycji n przepływów usług i R strumienie opieki. Zatem natężenie przepływu całkowitego jest równe sumie natężeń przepływów składowych nµ+rш. Ten całkowity przepływ generuje przejście QS od prawej do lewej strony stanu S n+r ,(r = 1,2,…) do średniej S n+r-1 ,(r = 1,2,…) i tym samym
k, k-1 =nµ+(k-n)ш, k =n+1,n+2,… (3)
Zatem gęstości prawdopodobieństwa przejść układu od prawej do lewej, biorąc pod uwagę (2) i (3), można zapisać w postaci połączonej
Struktura wykresu sugeruje, że proces zachodzący w QS jest procesem śmierci i reprodukcji.
Podstawmy (1) i (4) za k=1,…,n+m do wzoru

Wprowadźmy pod uwagę wartość, którą można nazwać zmniejszonym natężeniem potoku odjazdów i która pokazuje średnią liczbę odejścia z kolejki nieobsłużonych wniosków przez średni czas obsługi jednego wniosku. Podstawiając do (5) otrzymujemy:
Ponieważ w rozpatrywanym QS nie ma ograniczeń co do długości kolejki, wniosek otrzymany w strumieniu przychodzącym zostanie zaakceptowany; do systemu, tj. Wniosek nie jest odrzucany przez system. Zatem dla QS z „niecierpliwymi” aplikacjami prawdopodobieństwo przyjęcia do systemu wynosi P s =1, oraz prawdopodobieństwo odmowy przyjęcia do systemu P Otwarte =0 . Pojęcia „nieprzyjęcia do systemu” nie należy mylić z pojęciem „odmowy obsługi”, gdyż ze względu na „niecierpliwość” nie każdy wniosek otrzymany (zaakceptowany) do systemu zostanie obsłużony. Dlatego warto mówić o prawdopodobieństwie opuszczenia aplikacji przez kolejkę P xy i prawdopodobieństwa doręczenia wniosku, P o. Jednocześnie prawdopodobieństwo P o reprezentuje względną przepustowość Q I P xy =1- str o .
Obliczmy średnią liczbę wniosków w kolejce. Aby to zrobić, rozważ dyskretną zmienną losową N bardzo dobry reprezentującą liczbę aplikacji w kolejce. Zmienna losowa N bardzo dobry może przyjąć dowolną nieujemną wartość całkowitą, a jego prawo dystrybucji ma postać
|
N bardzo dobry |
||||||
|
P n+1 |
P n+2 |
P n+r |
Gdzie p= p 0 +str 1 +…+ str N. Stąd,
lub zastępując (7) tutaj, otrzymujemy
Każde żądanie w kolejce podlega strumieniowi „odlotów” Puchatka z intensywnością Przeciętna kolejka złożona z wniosków będzie podlegać całkowitemu przepływowi składającemu się z potoków „odjazdów” i mającym intensywność. Oznacza to, że ze średniej liczby wniosków znajdujących się w kolejce średnio wnioski w jednostce czasu wyjdą bez oczekiwania na obsługę, a pozostałe wnioski zostaną obsłużone. W efekcie średnia liczba wniosków obsłużonych w jednostce czasu, tj. absolutna pojemność QS
Następnie, z definicji pojemności względnej,
Q = A/ = (-)/ = 1 - (w/),
gdzie u/ = pokazuje średnią liczbę opuszczeń kolejki nieobsłużonych wniosków dla średniego czasu pomiędzy napływami dwóch sąsiednich wniosków w strumieniu przychodzącym P wejście .
Średnią liczbę zajętych kanałów (średnią liczbę żądań w ramach obsługi) można otrzymać jako stosunek bezwzględnej przepustowości A do wydajności jednego kanału µ. Korzystając z równości (11) będziemy mieli:
Średnią liczbę zajętych kanałów można obliczyć niezależnie od średniej liczby żądań w kolejce, a mianowicie jako matematyczne oczekiwanie dyskretnego zmienna losowa DO, który reprezentuje liczbę zajętych kanałów, których prawo dystrybucji ma postać
|
P 0 |
P 1 |
P 2 |
P n-1 |
Gdzie p = p N +str n+1 +…+ str n+1+…. Ale ponieważ zdarzenie, w którym wszystkie n kanałów jest zajęte, jest odwrotne do zdarzenia, w którym nie wszystkie n kanałów jest zajęte, i prawdopodobieństwo ostatnie wydarzenie równy
P 0 +str 1 +str 2 +…+ str n-1, To p = 1 - (str 0 +str 1 +str 2 +…+ str n-1) .
Ale wtedy z (11) otrzymujemy:
Korzystając ze wzorów (11) i (13) otrzymujemy wzór na średnią liczbę aplikacji w systemie:
Wyprowadźmy wzór na średni czas oczekiwania na wniosek w kolejce. Będzie to zależeć od podanego średniego czasu ograniczającego czas przebywania wniosku w kolejce, przez który albo
albo będzie liczba naturalna i > 2 takie, że
Mnożąc nierówności (14) i (15) przez otrzymujemy odpowiednio nierówności
Rozważmy przypadek (14) i niespójne hipotezy polegające na tym, że układ jest w stanie. Prawdopodobieństwa tych hipotez
Jeżeli wniosek wpłynie do CMO na podstawie hipotetycznej.e. gdy system znajdzie się w jednym ze stanów, w którym nie wszystkie kanały są zajęte, wówczas żądanie nie będzie musiało czekać w kolejce – od razu trafi w zakres obsługi wolnego kanału. Zatem warunkowe oczekiwanie matematyczne losowej wartości czasu oczekiwania na wniosek w kolejce objętej hipotezą, czyli średni czas oczekiwania na wniosek w kolejce objętej hipotezą, jest równe zeru:
Jeżeli wniosek trafi do systemu pod hipotetką.e. gdy QS jest w jednym ze stanów, w których wszystko N k-str aplikacje (jeśli Do= N w kolejce nie ma żadnych aplikacji), to średni czas zwolnienia jednej z nich N zajęte kanały są równe, a średni czas obsługi k-str wniosków stojących w kolejce przed wnioskiem otrzymanym w systemie jest równe Zatem średni czas potrzebny na obsługę wniosku przychodzącego w kolejce jest równy Ponieważ, ze względu na odpowiednią nierówność (14),
Tym samym średni czas potrzebny na przyjęcie wniosku w systemie do obsługi jest większy niż czas oczekiwania wniosku w kolejce. Tym samym otrzymany wniosek będzie średnio opóźniony w kolejce i pozostawi system bez obsługi. W konsekwencji warunkowe matematyczne oczekiwanie wartości w ramach hipotezy

Rozważmy teraz te same hipotezy w przypadku (15). W tym przypadku obowiązują także równości (16).
Jeżeli wniosek trafi do systemu w ramach jednej z hipotez, czyli gdy QS znajduje się w jednym ze stanów, w których wszystkie N kanały są zajęte, a przed odebraną aplikacją są już kolejki k-str aplikacje (jeśli Do- n nie ma żadnych wniosków w kolejce), to analogicznie jak w przypadku (14) średni czas potrzebny na realizację kolejki tego żądania jest równy limitowi czasu oczekiwania wniosku. Zatem w jakiś sposób, ze względu na lewą nierówność (15),
Tym samym średni czas potrzebny na przyjęcie wniosku do systemu do obsługi nie przekracza średniego czasu oczekiwania wniosku w kolejce. Zatem otrzymany wniosek nie opuści kolejki i będzie oczekiwał na przyjęcie do obsługi, spędzając średni czas oczekiwania w kolejce. Zatem warunkowe oczekiwanie matematyczne zmiennej losowej Toch mieści się w hipotezie
Niech teraz aplikacja wejdzie do systemu w ramach jednej z hipotez N ty k = n+i- tj. gdy QS był w jednym ze stanów..., w którym wszystko N kanały są zajęte i już stoją w kolejce k-str aplikacje. Ponieważ wynika to z nierówności (15):
i dlatego przychodzący wniosek będzie opóźniony w kolejce o średni czas. Zatem warunkowe oczekiwanie matematyczne zmiennej losowej Toch jest zgodne z hipotezą
Korzystając ze wzoru na całkowite oczekiwanie matematyczne, otrzymujemy:

W przypadku (15) otrzymany wniosek zostanie przyjęty do obsługi, jeżeli tylko w chwili jego otrzymania QS będzie w jednym ze stanów, wówczas prawdopodobieństwo, że wniosek zostanie obsłużony wynosi
Gdy / = 1, wzór (25) zamienia się w (24), więc na prawdopodobieństwo usługi możemy zapisać jeden wzór:
Znając prawdopodobieństwo obsługi, możesz obliczyć prawdopodobieństwo pozostawienia żądania bez obsługi w kolejce:
Średni czas przebywania aplikacji w systemie można obliczyć korzystając ze wzoru
gdzie to średni czas obsługi jednego wniosku, odnoszący się do wszystkich wniosków, zarówno obsłużonych, jak i tych, które opuściły kolejkę, co można obliczyć korzystając ze wzoru
6. Budowa i analiza modelu systemów kolejkowych
Rozważmy praktyczny problem wykorzystania QS bez ograniczenia długości kolejki, ale z ograniczeniem czasu oczekiwania w kolejce.
W celu zwiększenia zasięgu lotów bez przesiadek samoloty tankują w powietrzu. W miejscu tankowania stale pełnią służbę dwa samoloty tankujące. Tankowanie jednego samolotu trwa średnio około 10 minut. Jeśli oba tankujące samoloty są zajęte, statek powietrzny wymagający tankowania może „czekać” (latać w kółko w obszarze tankowania) przez jakiś czas. Średni czas oczekiwania to 20 minut. Samolot, który nie mógł doczekać się zatankowania, zmuszony jest wylądować na innym lotnisku. Intensywność lotów jest taka, że średnio co godzinę na miejsce tankowania przylatuje 12 samolotów. Określić:
Prawdopodobieństwo, że samolot zostanie zatankowany.
Średnia liczba zatrudnionych tankowców.
Średnia liczba samolotów w kolejce.
Średnia liczba samolotów w służbie.
Konieczne jest obliczenie głównych cech wydajności tego QS, pod warunkiem określenia następujących parametrów wejściowych:
- · liczba kanałów obsługi;
- · intensywność napływu wniosków;
- · intensywność przepływu usług;
- · średni czas ograniczający oczekiwanie wniosków w kolejce.
QS, o którym mowa, to systemie wielokanałowym stanie w kolejce bez ograniczenia długości kolejki, ale z ograniczeniem czasu oczekiwania. Określana jest liczba kanałów, intensywność napływu żądań, intensywność przepływu usług oraz liczba miejsc w kolejce.
W tym QS każdy kanał obsługuje jedno żądanie za każdym razem. Jeśli w momencie otrzymania nowego żądania co najmniej jeden kanał jest wolny, wówczas przychodzące żądanie zostanie odebrane w celu obsługi; jeśli nie ma żadnych żądań, system jest bezczynny.
Ustalmy, co się stanie, gdy do czasu nadejścia żądania wszystkie kanały będą zajęte - trafi do kolejki i czeka, aż jeden z kanałów stanie się wolny. Jeżeli w momencie wpływu wniosku wszystkie miejsca w kolejce są zajęte, wówczas wniosek ten opuszcza system.
Kryteria efektywności funkcjonowania QS:
- · Prawdopodobieństwo przestoju systemu;
- · Prawdopodobieństwo awarii systemu;
- · Względna przepustowość.
- · Średni czas, jaki aplikacja spędza w kolejce.
System ten jest modelowany jako wielokanałowy QS z „niecierpliwymi” żądaniami.
Parametry systemu:
liczba kanałów obsługi n=2;
intensywność napływu wniosków = 12 (samoloty na godzinę);
intensywność przepływu usług μ = 6(samoloty na godzinę);
średni czas oczekiwania wniosku w kolejce, zatem natężenie przepływu odlotów = 1/= 3 (samolot) na godzinę.
Obliczenia wykonano za pomocą programu opracowanego w Turbo Pascalu. Język Turbo-Pascal jest jednym z najpopularniejszych języków programowania komputerów. Do istotnych zalet języka Turbo-Pascal należą: mały rozmiar kompilatora, duża prędkość Tłumaczenie programów, kompilacja i montaż. Ponadto wygoda i wysoka jakość konstrukcja powłoki okna dialogowego sprawia, że pisanie i debugowanie programów jest wygodniejsze w porównaniu z alternatywnymi językami nowej generacji.
Aby przeanalizować działanie QS, konieczne jest zbadanie zachowania tego systemu dla różnych parametrów wejściowych.
W pierwszej wersji l=12, µ=6, n=3, liczba kanałów n=2.
W drugim wariancie l=12, µ=6, n=3, liczba kanałów n=3.
W wariancie trzecim l=12, µ=6, n=4, liczba kanałów n=2.
Wszystkie wyniki obliczeń podano w Załączniku 2.
W wyniku analizy uzyskanych danych (załącznik nr 2) wyciągnięto następujące wnioski.
Wraz ze wzrostem liczby kanałów prawdopodobieństwo przestoju systemu i prawdopodobieństwo zatankowania wzrasta o 50%.
Przy zmianie jedynie czasu przebywania żądania w kolejce, bez zwiększania liczby kanałów, zmieniało się natężenie potoku odlotów, w efekcie zmniejszała się liczba obsłużonych samolotów i zmniejszała się liczba samolotów w kolejce.
Moim zdaniem konieczna jest dodatkowa rekrutacja i szkolenie personel serwisowy, w celu zwiększenia intensywności przepływu odlotów, skróci się czas przestojów tankowców i nie będzie potrzeby tworzenia dodatkowego kanału.
Choć przy wyborze najbardziej optymalnych parametrów, przy których funkcjonowanie służby zdrowia będzie najbardziej efektywne, należy wziąć pod uwagę także czynniki techniczne i ekonomiczne, gdyż pozyskanie dodatkowego kanału świadczenia usług czy zmiana intensywności przepływu opieki wymaga pewnych kosztów materiałowych i kosztów szkolenia personelu.
1. Jednokanałowy QS z oczekiwaniem i ograniczeniem długości kolejki. W praktyce dość powszechne są jednokanałowe podmioty świadczące usługi medyczne z kolejką (lekarz obsługujący pacjentów, kasjer wystawiający pensje). W teorii kolejkowania jednokanałowe QS z kolejką również zajmują szczególne miejsce: większość otrzymanych dotychczas wzorów analitycznych dla systemów innych niż Markowa należy do takich QS.
Rozważmy jednokanałowy QS, na którego wejście odbierany jest najprostszy przepływ żądań z intensywnością λ . Załóżmy, że przepływ usług jest również najprostszy pod względem intensywności μ . Oznacza to, że stale zajęty kanał obsługuje średnio μ aplikacji w jednostce czasu. Żądanie otrzymane przez QS w czasie, gdy kanał jest zajęty, w przeciwieństwie do QS z awariami, nie opuszcza systemu, lecz trafia do kolejki i oczekuje na obsługę.
Zakładamy ponadto, że w tym systemie istnieje ograniczenie długości kolejki, przez co rozumiemy maksymalną liczbę miejsc w kolejce, czyli zakładamy, że maksymalnie może być M≥1 aplikacji. Zatem aplikacja, która trafia na wejście do QS, w momencie, gdy w kolejce są już osoby Mżądania, są odrzucane i pozostawiają system bezobsługowy.
Zatem rozważany QS należy do systemów typu mieszanego z ograniczeniem długości kolejki.
Ponumerujmy stany QS według liczby aplikacji w systemie, czyli tzw. w serwisie i w kolejce:
S 0 – kanał jest bezpłatny (dlatego nie ma kolejki);
S 1 – kanał jest zajęty i nie ma kolejki, tj. w CMO znajduje się jedna aplikacja (w trakcie obsługi);
S 2 – kanał jest zajęty i w kolejce znajduje się jedno żądanie;
……………………………………………………..
S M +1 – kanał jest zajęty i znajduje się w kolejce M aplikacje.
Wykres stanu tego QS pokazano na ryc. 6 i pokrywa się z wykresem opisującym proces śmierci i reprodukcji, z tą różnicą, że w przypadku tylko jednego kanału obsługi, wszystkie natężenia przepływu usług są równe μ .
Ryż. 6. Diagram stanu w systemie jednokanałowym z kolejką
Aby opisać ograniczający tryb pracy QS, możesz użyć podanych zasad i wzorów. Zapiszmy od razu wyrażenia określające prawdopodobieństwa graniczne stanów:
 Gdzie ρ = λ/μ
– intensywność obciążenia kanału.
Gdzie ρ = λ/μ
– intensywność obciążenia kanału.
Jeśli λ = μ , wtedy otrzymamy .
Niech to teraz  . Wyrażenie dla P 0
możliwe w w tym przypadkuŁatwiej napisać, korzystając z faktu, że w mianowniku znajduje się suma M+ 2
członkowie postęp geometryczny z mianownikiem ρ
:
. Wyrażenie dla P 0
możliwe w w tym przypadkuŁatwiej napisać, korzystając z faktu, że w mianowniku znajduje się suma M+ 2
członkowie postęp geometryczny z mianownikiem ρ
:
 .
.
Zwróć uwagę, kiedy M= 0 Przechodzimy do rozważanego już jednokanałowego QS z awariami. W tym przypadku.
Określmy główne cechy jednokanałowego QS z oczekiwaniem: przepustowość względną i bezwzględną, prawdopodobieństwo awarii, a także średnią długość kolejki i średni czas oczekiwania na aplikację w kolejce.
Wniosek otrzymany na wejście QS zostaje odrzucony wtedy i tylko wtedy, gdy kanał jest zajęty i oczekuje w kolejce. M aplikacje, tj. gdy system jest w stanie S M +1 . Dlatego prawdopodobieństwo awarii określa się na podstawie prawdopodobieństwa wystąpienia warunku S M +1 :
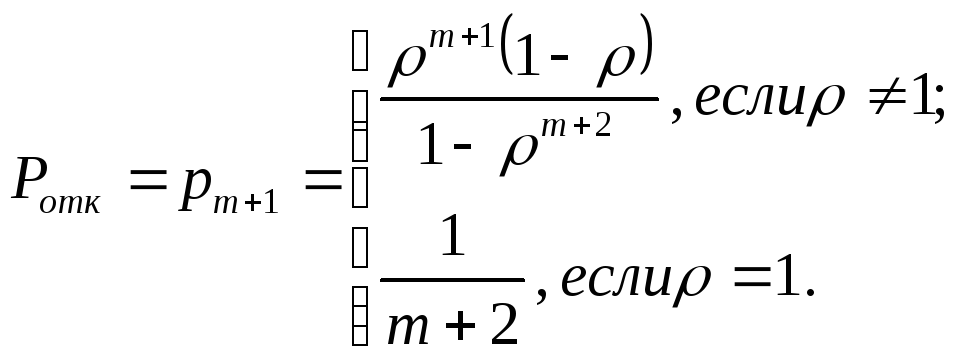
Względną przepustowość, czyli udział obsłużonych żądań przychodzących w jednostce czasu, określa się za pomocą wyrażenia:

Należy pamiętać, że względna przepustowość Q pokrywa się ze średnim udziałem wniosków przyjętych (tj. nie odrzuconych) do systemu wśród wszystkich otrzymanych, gdyż wniosek, który trafi do kolejki, z pewnością zostanie obsłużony.
Absolutna przepustowość systemu
 .
.
Średnia liczba aplikacji L bardzo dobry kolejkowanie do obsługi definiuje się jako matematyczne oczekiwanie na dyskretną zmienną losową k– liczba wniosków w kolejce:
 .
.
Zmienna losowa k przyjmuje wartości 0, 1, 2, …, M, którego prawdopodobieństwa wyznaczają prawdopodobieństwa stanów układu P k . Zatem prawo dystrybucji dyskretnej zmiennej losowej k ma następującą postać:
Zatem definiując oczekiwanie matematyczne dyskretnej zmiennej losowej (z uwzględnieniem wzorów na prawdopodobieństwa stanu) otrzymujemy:
 (16)
(16)
Załóżmy, że ρ ≠ 1 . Oczywiście mamy:

Ale ilość  jest sumą pierwszego M elementy postępu geometrycznego
jest sumą pierwszego M elementy postępu geometrycznego
 .
(17)
.
(17)
Podstawiając wyrażenie (17) do (16) otrzymujemy:
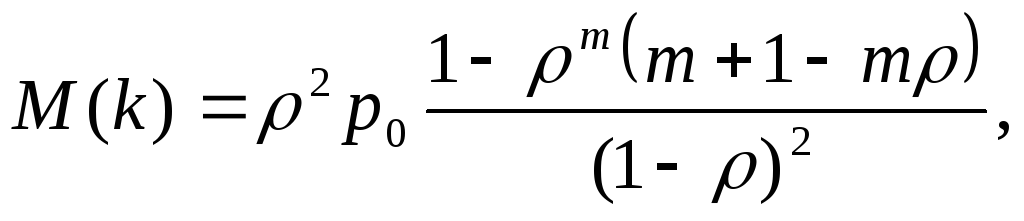
lub używając równości  (otrzymane z ρ ≠
1
), mamy
(otrzymane z ρ ≠
1
), mamy

Jeśli ρ =
1
, to z równości (16)  i biorąc to pod uwagę w tym przypadku
i biorąc to pod uwagę w tym przypadku  I
I  (suma M w kategoriach postępu arytmetycznego), w końcu otrzymujemy
(suma M w kategoriach postępu arytmetycznego), w końcu otrzymujemy

 .
.
Następnie średnia liczba wniosków w kolejce
 (18)
(18)
Ważną cechą QS z oczekiwaniem jest średni czas oczekiwania na wniosek w kolejce  . Pozwalać T bardzo dobry
– ciągła zmienna losowa reprezentująca czas oczekiwania na wniosek w kolejce. Średni czas oczekiwania na wniosek w kolejce obliczamy jako matematyczne oczekiwanie tej zmiennej losowej:
. Pozwalać T bardzo dobry
– ciągła zmienna losowa reprezentująca czas oczekiwania na wniosek w kolejce. Średni czas oczekiwania na wniosek w kolejce obliczamy jako matematyczne oczekiwanie tej zmiennej losowej:
 .
.
Aby obliczyć oczekiwanie matematyczne, używamy wzoru na całkowite oczekiwanie matematyczne: jeśli możemy uwzględnić warunki eksperymentu N(parami) niespójne hipotezy  następnie całkowite oczekiwanie matematyczne zmiennej losowej X można obliczyć za pomocą wzoru
następnie całkowite oczekiwanie matematyczne zmiennej losowej X można obliczyć za pomocą wzoru

Gdzie M (X | H k ) – warunkowe matematyczne oczekiwanie wartości X w ramach hipotezy H k .
Rozważmy M+ 2 niespójne hipotezy H k , k= 0,1,..., M+ 1 , polegające na tym, że QS znajduje się odpowiednio w stanach S k , k= 0,1,..., M+ 1 . Prawdopodobieństwa tych hipotez P (H k ) = P k , k= 0,1,..., M+1 .
Jeśli wniosek dotrze do QS zgodnie z hipotezą H 0
S 0
, w którym kanał jest wolny, wówczas żądanie nie będzie musiało stać w kolejce, a zatem warunkowe oczekiwanie matematyczne M
( |
H 0
)
zmienna losowa
|
H 0
)
zmienna losowa  w ramach hipotezy H 0
, pokrywający się ze średnim czasem oczekiwania na wniosek w kolejce w ramach hipotezy H 0
, równa się zero.
w ramach hipotezy H 0
, pokrywający się ze średnim czasem oczekiwania na wniosek w kolejce w ramach hipotezy H 0
, równa się zero.
Dla wniosku otrzymanego przez QS w ramach hipotezy H 1
, tj. gdy QS jest w stanie S 1
, w którym kanał jest zajęty, ale nie ma kolejki, warunkowe oczekiwanie matematyczne M
(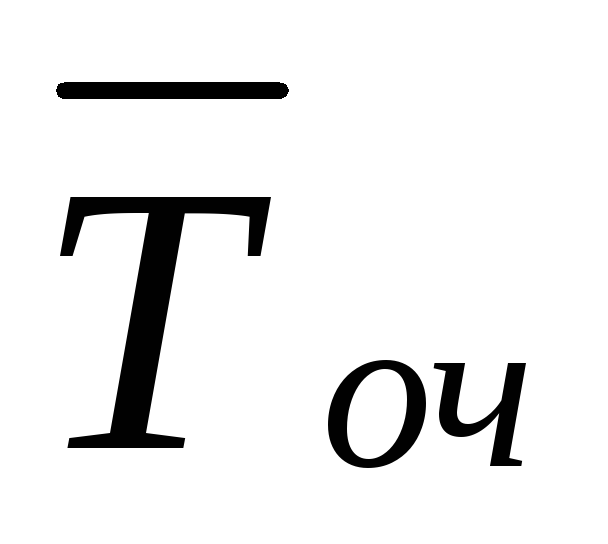 | H 1
)
zmienna losowa
| H 1
)
zmienna losowa  w ramach hipotezy H 1
, pokrywający się ze średnim czasem oczekiwania na wniosek w kolejce w ramach hipotezy H 1
, będzie równy średniemu czasowi obsługi jednego zgłoszenia
w ramach hipotezy H 1
, pokrywający się ze średnim czasem oczekiwania na wniosek w kolejce w ramach hipotezy H 1
, będzie równy średniemu czasowi obsługi jednego zgłoszenia  .
.
Warunkowe oczekiwanie matematyczne M
( | H 2
)
zmienna losowa
| H 2
)
zmienna losowa  w ramach hipotezy H 2
, tj. pod warunkiem otrzymania wniosku przez OZZ, który znajduje się w stanie S 2
, w którym kanał jest zajęty i jedno żądanie już czeka w kolejce, jest równe 2/
μ
(dwukrotny średni czas obsługi, gdyż trzeba obsłużyć dwa żądania: to, które jest w kanale obsługi i to, które oczekuje w kolejce). I tak dalej.
w ramach hipotezy H 2
, tj. pod warunkiem otrzymania wniosku przez OZZ, który znajduje się w stanie S 2
, w którym kanał jest zajęty i jedno żądanie już czeka w kolejce, jest równe 2/
μ
(dwukrotny średni czas obsługi, gdyż trzeba obsłużyć dwa żądania: to, które jest w kanale obsługi i to, które oczekuje w kolejce). I tak dalej.
Jeśli wniosek trafi do systemu zgodnie z hipotezą H M, tj. gdy kanał jest zajęty i czekają w kolejce M−
1
aplikacje, zatem M
(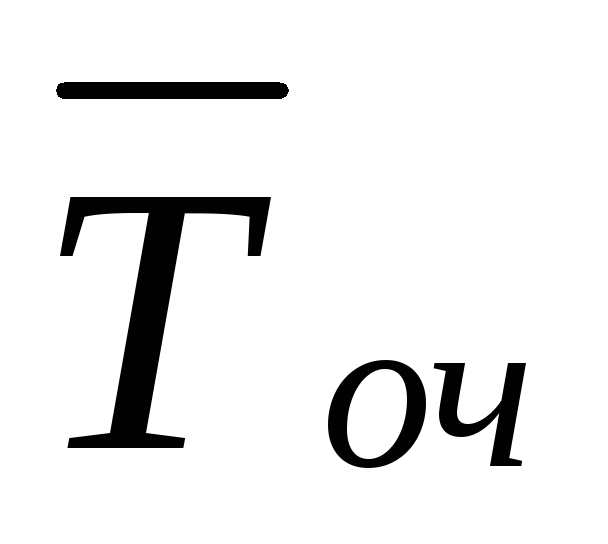 | H M).
| H M).
Wreszcie aplikacja, która trafiła do QS w ramach hipotezy H M +1
, tj. gdy kanał jest zajęty, M wnioski znajdują się w kolejce, a w kolejce nie ma już wolnych miejsc, zostają odrzucone i opuszczają system. Dlatego w tym przypadku M
(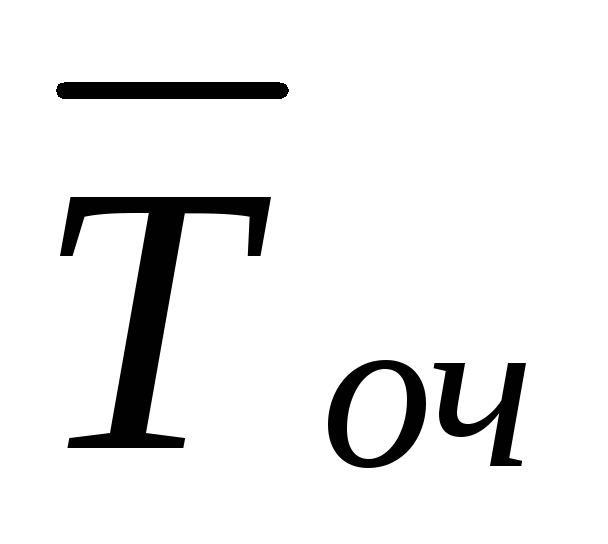 | H M +1
)
= 0.
| H M +1
)
= 0.
Zatem zgodnie ze wzorem na całkowite oczekiwanie matematyczne średni czas oczekiwania na wniosek w kolejce wynosi
Zastępując tutaj wyrażenia na prawdopodobieństwa P k
(k=1,2,...,M), otrzymujemy:  (19)
(19)
Jeśli intensywność obciążenia kanału ρ ≠ 1 , to z równości (19) biorąc pod uwagę wzory (17), (18) oraz wyrażenie na P 0 znajdujemy:
Jeśli ρ =
1
, następnie podstawiając do równości (19) wyrażenie P 0
= 1/(M+2), wartość kwoty 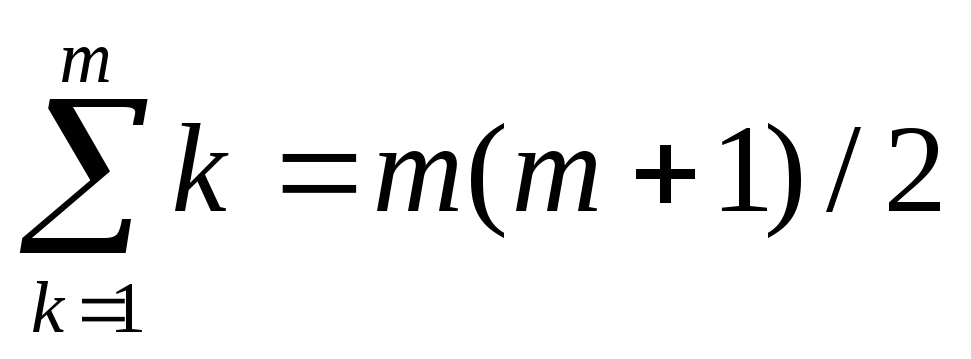 , korzystając ze wzoru (18) z ρ
=
1
i biorąc to pod uwagę w tym przypadku μ
= λ
, będziemy mieli
, korzystając ze wzoru (18) z ρ
=
1
i biorąc to pod uwagę w tym przypadku μ
= λ
, będziemy mieli 
Zatem dla dowolnego ρ otrzymujemy wzór na średni czas przebywania aplikacji w kolejce, który nazywamy wzorem Little’a:  te. średni czas oczekiwania na wniosek w kolejce
te. średni czas oczekiwania na wniosek w kolejce
 równa średniej liczbie wniosków w kolejce L bardzo dobry podzielone przez intensywność
λ przychodzący przepływ żądań .
równa średniej liczbie wniosków w kolejce L bardzo dobry podzielone przez intensywność
λ przychodzący przepływ żądań .
Przykład. Na stacji benzynowej (stacji benzynowej) znajduje się jedna pompa. Na obszarze stacji, na którym samochody oczekują na tankowanie, mogą znajdować się jednocześnie nie więcej niż trzy samochody; jeżeli jest zajęty, następny samochód przyjeżdżający na stację nie ustawia się w kolejce, lecz udaje się na sąsiednią stację benzynową. Samochody przyjeżdżają na stację średnio co 2 minuty. Proces tankowania jednego samochodu trwa średnio 2,5 minuty. Określ główne cechy systemu.
Rozwiązanie. Model matematyczny tej stacji benzynowej to jednokanałowy QS z oczekiwaniem i ograniczeniem długości kolejki ( M= 3). Zakłada się, że przepływ samochodów zbliżających się do stacji benzynowej w celu zatankowania oraz przepływ usług jest prosty.
Ponieważ samochody przyjeżdżają średnio co 2 minuty, natężenie napływu jest równe λ
=1/2 = 0,5 (maszyny na minutę). Średni czas obsługi maszyny 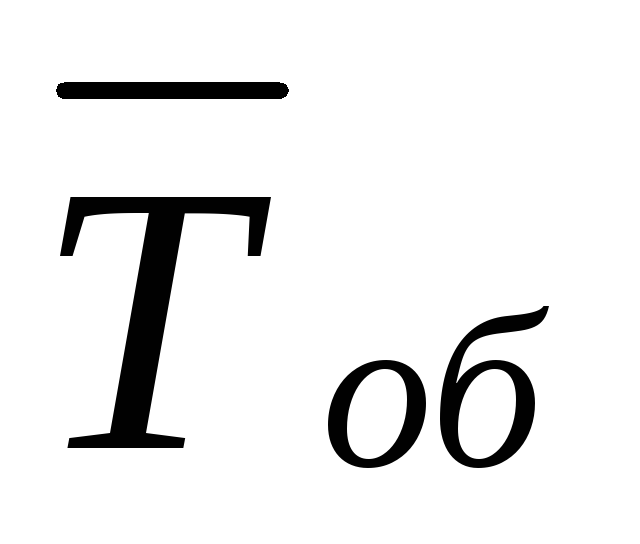 = 2,5 min, zatem natężenie przepływu usług μ
=1/2,5 = 0,4 (samochody na minutę).
= 2,5 min, zatem natężenie przepływu usług μ
=1/2,5 = 0,4 (samochody na minutę).
Określamy intensywność obciążenia kanału: ρ = λ/ μ = 0,5/0,4 = 1,25.
Obliczanie prawdopodobieństwa awarii  skąd pochodzi względna przepustowość?
i absolutną przepustowość A= λ
Q≈ 0,5⋅0,703
≈ 0,352.
skąd pochodzi względna przepustowość?
i absolutną przepustowość A= λ
Q≈ 0,5⋅0,703
≈ 0,352.
Średnia liczba samochodów oczekujących w kolejce do tankowania
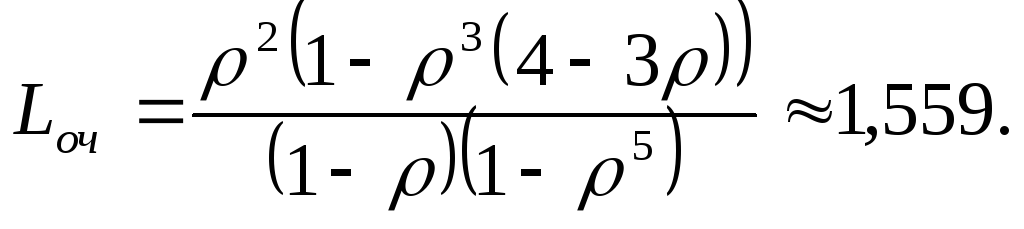
Średni czas oczekiwania na samochód w kolejce obliczamy korzystając ze wzoru Little’a 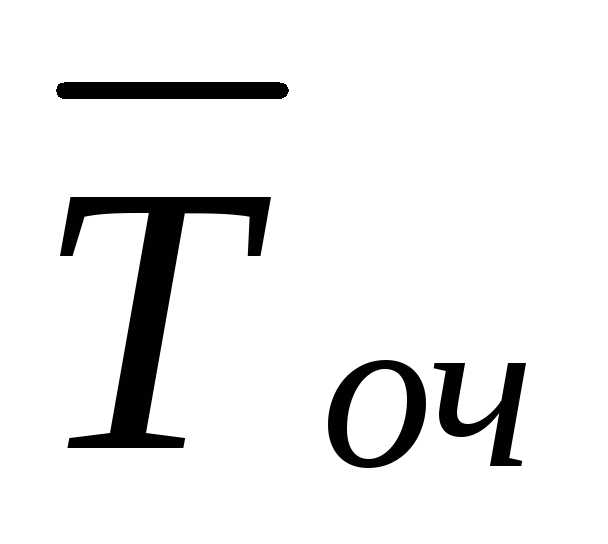 = L bardzo dobry/λ ≈1,559/0,5 = 3,118.
= L bardzo dobry/λ ≈1,559/0,5 = 3,118.
Zatem z analizy działania QS wynika, że na każde 100 podjeżdżających samochodów 30 zostaje odrzuconych ( P Otwarte≈ 29,7%), tj. Obsługiwanych jest 2/3 wniosków. Należy zatem albo skrócić czas obsługi jednej maszyny (zwiększyć intensywność obsługi), albo zwiększyć liczbę pomp, albo zwiększyć powierzchnię oczekiwania.







