Como ejemplo de continuo variable aleatoria Considere una variable aleatoria X distribuida uniformemente en el intervalo (a; b). Se dice que la variable aleatoria X es Distribuidos equitativamente en el intervalo (a; b), si su densidad de distribución no es constante en este intervalo:
A partir de la condición de normalización determinamos el valor de la constante c. El área bajo la curva de densidad de distribución debe ser igual a la unidad, pero en nuestro caso es el área de un rectángulo con base (b - α) y altura c (Fig. 1). 
Arroz. 1 Densidad de distribución uniforme
De aquí encontramos el valor de la constante c: ![]()
Entonces, la densidad de una variable aleatoria uniformemente distribuida es igual a 
Encontremos ahora la función de distribución usando la fórmula:
1) para ![]()
2) para
3) para 0+1+0=1.
De este modo, 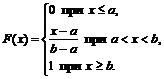
La función de distribución es continua y no disminuye (Fig. 2). 
Arroz. 2 Función de distribución de una variable aleatoria distribuida uniformemente
Lo encontraremos valor esperado variable aleatoria distribuida uniformemente según la fórmula:
Dispersión de distribución uniforme. se calcula mediante la fórmula y es igual a
Ejemplo No. 1. El valor de división de escala del dispositivo de medición es 0,2. Las lecturas del instrumento se redondean a la división entera más cercana. Encuentre la probabilidad de que se cometa un error durante el conteo: a) menos de 0,04; b) grande 0,02
Solución. El error de redondeo es una variable aleatoria distribuida uniformemente en el intervalo entre divisiones enteras adyacentes. Consideremos el intervalo (0; 0,2) como tal división (Fig. a). El redondeo se puede realizar tanto hacia el borde izquierdo - 0, como hacia la derecha - 0,2, lo que significa que se puede cometer dos veces un error menor o igual a 0,04, lo que hay que tener en cuenta a la hora de calcular la probabilidad: 

P = 0,2 + 0,2 = 0,4
Para el segundo caso, el valor del error también puede exceder 0,02 en ambos límites de división, es decir, puede ser mayor que 0,02 o menor que 0,18. 
Entonces la probabilidad de un error como este:
Ejemplo No. 2. Se asumió que la estabilidad de la situación económica del país (ausencia de guerras, desastres naturales, etc.) durante los últimos 50 años puede juzgarse por la naturaleza de la distribución de la población por edades: en una situación de calma debería ser uniforme. Como resultado del estudio, se obtuvieron los siguientes datos para uno de los países.
¿Hay alguna razón para creer que hubo inestabilidad en el país?Realizamos la solución utilizando una calculadora.Prueba de hipótesis.. Tabla de cálculo de indicadores.
| Grupos | Punto medio del intervalo, x i | Cantidad, f i | x i * f i | Frecuencia acumulada, S | |x - x av |*f | (x - x promedio) 2 *f | Frecuencia, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Peso promedio
Indicadores de variación.
variaciones absolutas.
El rango de variación es la diferencia entre los valores máximo y mínimo de la característica de la serie primaria.
R = X máx - X mín
R = 70 - 0 = 70
Dispersión- caracteriza la medida de dispersión alrededor de su valor promedio (una medida de dispersión, es decir, desviación del promedio).
Desviación Estándar.
Cada valor de la serie difiere del valor promedio de 43 en no más de 23,92
Probar hipótesis sobre el tipo de distribución..
4. Probar la hipótesis sobre distribución uniforme población general.
Para probar la hipótesis sobre la distribución uniforme de X, es decir según la ley: f(x) = 1/(b-a) en el intervalo (a,b)
necesario:
1. Estime los parámetros a y b, los extremos del intervalo en el que valores posibles X, según las fórmulas (el signo * indica estimaciones de parámetros):
2. Encuentre la densidad de probabilidad de la distribución esperada f(x) = 1/(b * - a *)
3. Encuentra las frecuencias teóricas:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(x i - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Comparar frecuencias empíricas y teóricas utilizando el criterio de Pearson, tomando el número de grados de libertad k = s-3, donde s es el número de intervalos de muestreo iniciales; Si se realizó una combinación de frecuencias pequeñas y, por tanto, de los intervalos mismos, entonces s es el número de intervalos que quedan después de la combinación.
Solución:
1. Encuentre estimaciones de los parámetros a * y b * de la distribución uniforme utilizando las fórmulas:
2. Encuentre la densidad de la distribución uniforme supuesta:
f(x) = 1/(b * - a *) = 1/(84,42 - 1,58) = 0,0121
3. Encontremos las frecuencias teóricas:
n 1 = n*f(x)(x 1 - a *) = 1 * 0,0121(10-1,58) = 0,1
n 8 = n*f(x)(b * - x 7) = 1 * 0,0121(84,42-70) = 0,17
Los n s restantes serán iguales a:
n s = n*f(x)(x i - x i-1)
| i | n yo | negro | n yo - n * yo | (n yo - n* yo) 2 | (n yo - n * yo) 2 /norte * yo |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Total | 1 | 0.0532 |
Por lo tanto, la región crítica para esta estadística es siempre diestra: si su densidad de probabilidad es constante en este segmento y fuera de él es igual a 0 (es decir, una variable aleatoria X concentrado en el segmento [ a, b], sobre el cual tiene una densidad constante). Por esta definición densidad distribuida uniformemente en el segmento [ a, b] variable aleatoria X tiene la forma:
Dónde Con hay un número determinado. Sin embargo, es fácil de encontrar utilizando la propiedad de densidad de probabilidad para variables aleatorias concentradas en el segmento [ a,
b]:
 . Resulta que
. Resulta que  , dónde
, dónde  . Por lo tanto, la densidad distribuida uniformemente en el segmento [ a,
b] variable aleatoria X tiene la forma:
. Por lo tanto, la densidad distribuida uniformemente en el segmento [ a,
b] variable aleatoria X tiene la forma:
 .
.
Juzgue la uniformidad de distribución de n.s.v. X posible a partir de las siguientes consideraciones. Una variable aleatoria continua tiene distribución uniforme en el segmento [ a, b], si toma valores solo de este segmento, y cualquier número de este segmento no tiene ventaja sobre otros números de este segmento en el sentido de poder ser un valor de esta variable aleatoria.
Las variables aleatorias que tienen una distribución uniforme incluyen valores tales como el tiempo de espera del transporte en una parada (con un intervalo de tráfico constante, la duración de la espera se distribuye uniformemente en este intervalo), el error al redondear un número a un número entero (uniformemente distribuido en [−0,5 , 0.5 ]) y otros.
Tipo de función de distribución F(X)
a,
b] variable aleatoria X buscado por densidad de probabilidad conocida F(X)
usando la fórmula para su conexión  . Como resultado de los cálculos correspondientes, obtenemos la siguiente fórmula para la función de distribución F(X)
segmento distribuido uniformemente [ a,
b] variable aleatoria X
:
. Como resultado de los cálculos correspondientes, obtenemos la siguiente fórmula para la función de distribución F(X)
segmento distribuido uniformemente [ a,
b] variable aleatoria X
:
 .
.
Las figuras muestran gráficos de densidad de probabilidad. F(X) y funciones de distribución F(X) segmento distribuido uniformemente [ a, b] variable aleatoria X :


Expectativa, varianza, desviación estándar, moda y mediana de un segmento distribuido uniformemente [ a, b] variable aleatoria X calculado por densidad de probabilidad F(X) de la forma habitual (y simplemente porque tipo simple F(X) ). El resultado son las siguientes fórmulas:
y la moda d(X) es cualquier número en el intervalo [ a, b].
Encontremos la probabilidad de golpear un segmento distribuido uniformemente [ a,
b] variable aleatoria X en el intervalo  , completamente acostado dentro [ a,
b]. Teniendo en cuenta la forma conocida de la función de distribución, obtenemos:
, completamente acostado dentro [ a,
b]. Teniendo en cuenta la forma conocida de la función de distribución, obtenemos:
Por tanto, la probabilidad de golpear un segmento distribuido uniformemente [ a,
b] variable aleatoria X en el intervalo  , completamente acostado dentro [ a,
b], no depende de la posición de este intervalo, sino que depende únicamente de su longitud y es directamente proporcional a esta longitud.
, completamente acostado dentro [ a,
b], no depende de la posición de este intervalo, sino que depende únicamente de su longitud y es directamente proporcional a esta longitud.
Ejemplo. El intervalo del autobús es de 10 minutos. ¿Cuál es la probabilidad de que un pasajero que llega a una parada de autobús espere menos de 3 minutos por el autobús? ¿Cuál es el tiempo promedio de espera de un autobús?
Distribución normal
Esta distribución se encuentra con mayor frecuencia en la práctica y desempeña un papel excepcional en la teoría de la probabilidad y la estadística matemática y sus aplicaciones, ya que muchas variables aleatorias en las ciencias naturales, la economía, la psicología, la sociología, las ciencias militares, etc., tienen dicha distribución. Esta distribución es una ley limitante, a la que se acercan muchas otras leyes de distribución (bajo ciertas condiciones naturales). Utilizando la ley de distribución normal, también se describen fenómenos que están sujetos a la acción de muchos factores aleatorios independientes de cualquier naturaleza y cualquier ley de su distribución. Pasemos a las definiciones.
Una variable aleatoria continua se llama distribuida sobre ley normal (o ley de Gauss), si su densidad de probabilidad tiene la forma:
 ,
,
donde estan los numeros A Y σ (σ>0 ) son los parámetros de esta distribución.
Como ya se mencionó, la ley de distribución de variables aleatorias de Gauss tiene numerosas aplicaciones. Según esta ley, se distribuyen los errores de medición por instrumentos, la desviación del centro del objetivo al disparar, las dimensiones de las piezas fabricadas, el peso y altura de las personas, la precipitación anual, el número de recién nacidos y mucho más.
La fórmula dada para la densidad de probabilidad de una variable aleatoria distribuida normalmente contiene, como se dijo, dos parámetros A Y σ , y por tanto define una familia de funciones que varían dependiendo de los valores de estos parámetros. Si aplicamos los métodos habituales de análisis matemático para estudiar funciones y trazar gráficos a la densidad de probabilidad de una distribución normal, podemos sacar las siguientes conclusiones.

son sus puntos de inflexión.
A partir de la información recibida, construimos un gráfico de densidad de probabilidad. F(X) distribución normal (se llama curva gaussiana - figura).

Descubramos cómo afecta el cambio de parámetros. A Y σ a la forma de la curva gaussiana. Es obvio (esto se puede ver en la fórmula de la densidad de distribución normal) que un cambio en el parámetro A no cambia la forma de la curva, solo conduce a su desplazamiento hacia la derecha o hacia la izquierda a lo largo del eje X. Dependencia σ más difícil. Del estudio anterior queda claro cómo el valor del máximo y las coordenadas de los puntos de inflexión dependen del parámetro σ . Además, debemos tener en cuenta que para cualquier parámetro A Y σ el área bajo la curva gaussiana sigue siendo igual a 1 (ésta es una propiedad general de la densidad de probabilidad). De lo anterior se deduce que con un parámetro creciente σ la curva se vuelve más plana y se extiende a lo largo del eje X. La figura muestra curvas gaussianas para diferentes valores del parámetro. σ (σ 1 < σ< σ 2 ) y el mismo valor de parámetro A.

Descubramos el significado probabilístico de los parámetros. A Y σ
distribución normal. Ya por la simetría de la curva gaussiana con respecto a la línea vertical que pasa por el número A en el eje X está claro que el valor promedio (es decir, la expectativa matemática M(X)) de una variable aleatoria distribuida normalmente es igual a A. Por las mismas razones, la moda y la mediana también deben ser iguales al número a. Cálculos precisos que utilizan las fórmulas adecuadas lo confirman. Si utilizamos la expresión escrita arriba para F(X)
sustituir en la fórmula de la varianza  , luego de un cálculo (bastante complicado) de la integral obtenemos el número en la respuesta σ
2
. Por tanto, para una variable aleatoria X, distribuidas según la ley normal, se obtuvieron las siguientes características numéricas principales:
, luego de un cálculo (bastante complicado) de la integral obtenemos el número en la respuesta σ
2
. Por tanto, para una variable aleatoria X, distribuidas según la ley normal, se obtuvieron las siguientes características numéricas principales:
Por tanto, el significado probabilístico de los parámetros de la distribución normal. A Y σ próximo. Si r.v. XA Y σ A σ.
Encontremos ahora la función de distribución. F(X)
para una variable aleatoria X, distribuido según la ley normal, utilizando la expresión anterior para la densidad de probabilidad F(X)
y fórmula  . Al sustituir F(X)
el resultado es una integral "no tomada". Todo lo que se pueda hacer para simplificar la expresión para F(X),
Esta es la representación de esta función como:
. Al sustituir F(X)
el resultado es una integral "no tomada". Todo lo que se pueda hacer para simplificar la expresión para F(X),
Esta es la representación de esta función como:
 ,
,
Dónde F(x)− llamado función de Laplace, que tiene la forma
 .
.
La integral a través de la cual se expresa la función de Laplace tampoco se toma (pero para cada X esta integral se puede calcular aproximadamente con cualquier precisión predeterminada). Sin embargo, no es necesario calcularlo, ya que al final de cualquier libro de texto sobre teoría de la probabilidad hay una tabla para determinar los valores de la función. F(x) a un valor dado X. En lo que sigue necesitaremos la propiedad de rareza de la función de Laplace: Ф(−х)=−F(x) para todos los números X.
Encontremos ahora la probabilidad de que un r.v. distribuido normalmente. X tomará un valor del intervalo numérico especificado (α, β) . De las propiedades generales de la función de distribución. Р(α< X< β)= F(β) − F(α) . Sustituyendo α Y β en la expresión anterior para F(X) , obtenemos
 .
.
Como se indicó anteriormente, si r.v. X distribuido normalmente con parámetros A Y σ , entonces su valor promedio es A, y la desviación estándar es igual a σ. Es por eso promedio desviación de los valores de este r.v. cuando se prueba desde el número A es igual σ. Pero esta es la desviación promedio. Por tanto, son posibles desviaciones mayores. Averigüemos qué tan posibles son ciertas desviaciones del valor promedio. Encontremos la probabilidad de que el valor de una variable aleatoria se distribuya según la ley normal. X desviarse de su valor promedio M(X)=a menos que por un cierto número δ, es decir R(| X− a|<δ ): . De este modo,
 .
.
Sustituyendo en esta igualdad δ=3σ, obtenemos la probabilidad de que el valor de r.v. X(en una prueba) se desviará del valor promedio en menos del triple del valor σ (con la desviación media, como recordamos, igual a σ ): (significado F(3) tomado de la tabla de valores de funciones de Laplace). Casi 1 ! Entonces la probabilidad del evento opuesto (que el valor se desvíe en no menos de 3σ) es igual a 1 −0.997=0.003 , que está muy cerca de 0 . Por tanto, este evento es “casi imposible” − ocurre muy raramente (en promedio 3 se acabó el tiempo 1000 ). Este razonamiento es el fundamento de la conocida "regla tres sigma".
regla tres sigma. Variable aleatoria normalmente distribuida en una sola prueba prácticamente no se desvía de su promedio más allá de 3σ.
Recalquemos una vez más que estamos hablando de una prueba. Si hay muchas pruebas de una variable aleatoria, entonces es muy posible que algunos de sus valores se alejen más del promedio que 3σ. Esto lo confirma lo siguiente
Ejemplo. ¿Cuál es la probabilidad de que en 100 ensayos de una variable aleatoria distribuida normalmente X¿Se desviará al menos uno de sus valores del promedio en más del triple de la desviación estándar? ¿Qué pasa con 1000 pruebas?
Solución. deja que el evento A significa que al probar una variable aleatoria X su valor se desvió del promedio en más de 3σ. Como se acaba de aclarar, la probabilidad de este evento p=P(A)=0,003. Se llevaron a cabo 100 pruebas de este tipo. Necesitamos encontrar la probabilidad de que el evento A sucedió al menos veces, es decir vino de 1 antes 100 una vez. Este es un problema típico del circuito de Bernoulli con parámetros norte=100 (número de ensayos independientes), p=0,003(probabilidad de evento A en un ensayo) q=1− pag=0.997 . Necesito encontrar R 100 (1≤ k≤100) . EN en este caso Por supuesto, es más fácil encontrar primero la probabilidad del evento opuesto. R 100 (0) − probabilidad de que el evento A no sucedió ni una sola vez (es decir, sucedió 0 veces). Teniendo en cuenta la conexión entre las probabilidades del evento en sí y su opuesto, obtenemos:
No tan poco. Es muy posible que esto suceda (ocurre en promedio en una de cada cuatro series de pruebas de este tipo). En 1000 pruebas utilizando el mismo esquema, se puede obtener que la probabilidad de al menos una desviación es mayor que 3σ, es igual a: . Por lo tanto, podemos esperar con gran confianza al menos una desviación de este tipo.
Ejemplo. La altura de los hombres de un determinado grupo de edad se distribuye normalmente con expectativa matemática. a y desviación estándar σ . ¿Qué proporción de trajes? k El crecimiento debe incluirse en la producción total para un grupo de edad determinado si k El crecimiento está determinado por los siguientes límites:
1 altura : 158 − 164cm2 altura : 164 - 170 cm 3 altura : 170 - 176cm 4 altura : 176 - 182cm
Solución. Resolvamos el problema con los siguientes valores de parámetros: a = 178,σ=6,k=3
. Dejemos que r.v. X
−
la altura de un hombre seleccionado al azar (se distribuye normalmente con los parámetros dados). Encontremos la probabilidad de que un hombre elegido al azar necesite 3
-ésima altura. Usando la rareza de la función de Laplace F(x) y una tabla de sus valores: P(170
Esta cuestión se ha estudiado en detalle durante mucho tiempo, y el método más utilizado es el método de coordenadas polares, propuesto por George Box, Mervyn Muller y George Marsaglia en 1958. Este método le permite obtener un par de variables aleatorias independientes distribuidas normalmente con expectativa matemática 0 y varianza 1 de la siguiente manera:
Donde Z 0 y Z 1 son los valores deseados, s = u 2 + v 2, y u y v son variables aleatorias distribuidas uniformemente en el intervalo (-1, 1), seleccionadas de tal manera que se cumple la condición 0.< s < 1.
Muchas personas utilizan estas fórmulas sin siquiera pensarlo, y muchas ni siquiera sospechan de su existencia, ya que utilizan implementaciones ya preparadas. Pero hay gente que tiene dudas: “¿De dónde viene esta fórmula? ¿Y por qué recibes un par de cantidades a la vez? A continuación intentaré dar una respuesta clara a estas preguntas.
Para empezar, déjame recordarte qué son la densidad de probabilidad, la función de distribución de una variable aleatoria y la función inversa. Supongamos que existe una determinada variable aleatoria, cuya distribución está especificada por la función de densidad f(x), que tiene la siguiente forma:

Esto significa que la probabilidad de que el valor de una determinada variable aleatoria esté en el intervalo (A, B) es igual al área del área sombreada. Y como consecuencia, el área de toda el área sombreada debe ser igual a uno, ya que en cualquier caso el valor de la variable aleatoria caerá en el dominio de definición de la función f.
La función de distribución de una variable aleatoria es la integral de la función de densidad. Y en este caso su aspecto aproximado será así:

El significado aquí es que el valor de la variable aleatoria será menor que A con probabilidad B. Y como consecuencia, la función nunca disminuye y sus valores se encuentran en el intervalo.
Una función inversa es una función que devuelve un argumento a la función original si se le pasa el valor de la función original. Por ejemplo, para la función x 2 la inversa es la función de extraer la raíz, para sin(x) es arcsin(x), etc.
Dado que la mayoría de los generadores de números pseudoaleatorios sólo producen una distribución uniforme como salida, a menudo es necesario convertirla en otra distribución. En este caso, al gaussiano normal:

La base de todos los métodos para transformar una distribución uniforme en cualquier otra es el método de transformación inversa. Funciona de la siguiente manera. Se encuentra una función que es inversa a la función de la distribución requerida y se le pasa como argumento una variable aleatoria distribuida uniformemente en el intervalo (0, 1). En la salida obtenemos un valor con la distribución requerida. Para mayor claridad, proporciono la siguiente imagen.

De este modo, un segmento uniforme se extiende, por así decirlo, según la nueva distribución, y se proyecta sobre otro eje mediante una función inversa. Pero el problema es que la integral de la densidad de una distribución gaussiana no es fácil de calcular, por lo que los científicos mencionados anteriormente tuvieron que hacer trampa.
Existe una distribución chi-cuadrado (distribución de Pearson), que es la distribución de la suma de cuadrados de k variables aleatorias normales independientes. Y en el caso de que k = 2, esta distribución es exponencial.

Esto significa que si un punto en un sistema de coordenadas rectangular tiene coordenadas aleatorias X e Y distribuidas normalmente, luego de convertir estas coordenadas al sistema polar (r, θ), el cuadrado del radio (la distancia desde el origen al punto) se distribuirá según la ley exponencial, ya que el cuadrado del radio es la suma de los cuadrados de las coordenadas (según la ley de Pitágoras). La densidad de distribución de dichos puntos en el plano se verá así:


Como es igual en todas las direcciones, el ángulo θ tendrá una distribución uniforme en el rango de 0 a 2π. Lo contrario también es cierto: si defines un punto en el sistema de coordenadas polares usando dos variables aleatorias independientes (un ángulo distribuido uniformemente y un radio distribuido exponencialmente), entonces las coordenadas rectangulares de este punto serán variables aleatorias normales independientes. Y es mucho más fácil obtener una distribución exponencial a partir de una uniforme utilizando el mismo método de transformación inversa. Ésta es la esencia del método polar de Box-Muller.
Ahora derivemos las fórmulas.
![]() (1)
(1)
Para obtener r y θ, es necesario generar dos variables aleatorias distribuidas uniformemente en el intervalo (0, 1) (llamémoslas u y v), cuya distribución de una de las cuales (digamos v) debe convertirse a exponencial a obtener el radio. La función de distribución exponencial se ve así:
Su función inversa es:
![]()
Dado que la distribución uniforme es simétrica, la transformación funcionará de manera similar con la función
![]()
De la fórmula de distribución chi-cuadrado se deduce que λ = 0,5. Sustituye λ, v en esta función y obtienes el cuadrado del radio, y luego el radio mismo:

Obtenemos el ángulo estirando el segmento unitario a 2π:
Ahora sustituimos r y θ en las fórmulas (1) y obtenemos:
 (2)
(2)
Estas fórmulas ya están listas para usar. X e Y serán independientes y se distribuirán normalmente con una varianza de 1 y una expectativa matemática de 0. Para obtener una distribución con otras características, basta con multiplicar el resultado de la función por la desviación estándar y sumar la expectativa matemática.
Pero es posible deshacerse de las funciones trigonométricas especificando el ángulo no directamente, sino indirectamente a través de las coordenadas rectangulares de un punto aleatorio en el círculo. Luego, a través de estas coordenadas, será posible calcular la longitud del radio vector, y luego encontrar el coseno y el seno dividiendo x e y por él, respectivamente. ¿Cómo y por qué funciona?
Elijamos un punto aleatorio entre los distribuidos uniformemente en un círculo de radio unitario y denotemos el cuadrado de la longitud del vector de radio de este punto con la letra s:

La selección se realiza especificando coordenadas rectangulares aleatorias x e y, distribuidas uniformemente en el intervalo (-1, 1), y descartando los puntos que no pertenecen al círculo, así como el punto central en el que se forma el ángulo del vector radio. no está definido. Es decir, se debe cumplir la condición 0.< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Obtenemos las fórmulas como al principio del artículo. La desventaja de este método es que descarta puntos que no están incluidos en el círculo. Es decir, utilizando sólo el 78,5% de las variables aleatorias generadas. En las computadoras más antiguas, la falta de funciones trigonométricas seguía siendo una gran ventaja. Ahora, cuando un comando de procesador calcula tanto el seno como el coseno en un instante, creo que estos métodos aún pueden competir.
Personalmente todavía tengo dos preguntas:
- ¿Por qué el valor de s se distribuye uniformemente?
- ¿Por qué la suma de los cuadrados de dos variables aleatorias normales está distribuida exponencialmente?

Si se realiza una transformación similar para una variable aleatoria normal, entonces la función de densidad de su cuadrado resultará similar a una hipérbola. Y la suma de dos cuadrados de variables aleatorias normales es un proceso mucho más complejo asociado con la doble integración. Y el hecho de que el resultado será una distribución exponencial, personalmente solo tengo que comprobarlo mediante un método práctico o aceptarlo como axioma. Y para aquellos que estén interesados, les sugiero que analicen más de cerca el tema, adquiriendo conocimientos de estos libros:
- Ventzel E.S. Teoría de probabilidad
- Knut D.E. El arte de programar, volumen 2
En conclusión, aquí hay un ejemplo de implementación de un generador de números aleatorios distribuidos normalmente en JavaScript:
Función Gauss() ( var listo = falso; var segundo = 0.0; this.next = función(media, dev) ( media = media == indefinido ? 0.0: media; dev = dev == indefinido ? 1.0: dev; if ( this.ready) ( this.ready = false; devuelve this.segundo * dev + media; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. aleatorio() - 1,0; s = u * u + v * v; ) mientras (s > 1,0 || s == 0,0); var r = Math.sqrt(-2,0 * Math.log(s) / s); this.segundo = r * u; this.ready = verdadero; devolver r * v * dev + media; ) ); ) g = nuevo Gauss(); // crea un objeto a = g.next(); // genera un par de valores y obtiene el primero b = g.next(); // obtenemos el segundo c = g.next(); // generamos un par de valores nuevamente y obtenemos el primero
Los parámetros media (expectativa matemática) y dev (desviación estándar) son opcionales. Llamo su atención sobre el hecho de que el logaritmo es natural.

 Eco HSG permeabilidad tubárica")





