Kriteria Fisher
Kriteria Fisher digunakan untuk menguji hipotesis bahawa varians dua populasi umum, diedarkan mengikut undang-undang biasa. Ia adalah kriteria parametrik.
Ujian F Fisher dipanggil nisbah varians kerana ia dibentuk sebagai nisbah dua anggaran tidak berat sebelah varians yang dibandingkan.
Biarkan dua sampel diperoleh hasil daripada pemerhatian. Daripada mereka varians dan  mempunyai
mempunyai  Dan
Dan  darjah kebebasan. Kami akan menganggap bahawa sampel pertama diambil daripada populasi dengan varians
darjah kebebasan. Kami akan menganggap bahawa sampel pertama diambil daripada populasi dengan varians  , dan yang kedua adalah daripada populasi umum dengan varians
, dan yang kedua adalah daripada populasi umum dengan varians  . Hipotesis nol dikemukakan tentang kesamaan dua varians, i.e. H0:
. Hipotesis nol dikemukakan tentang kesamaan dua varians, i.e. H0:  atau . Untuk menolak hipotesis ini, adalah perlu untuk membuktikan kepentingan perbezaan pada tahap keertian tertentu.
atau . Untuk menolak hipotesis ini, adalah perlu untuk membuktikan kepentingan perbezaan pada tahap keertian tertentu.  .
.
Nilai kriteria dikira menggunakan formula:
Jelas sekali, jika varians adalah sama, nilai kriteria akan sama dengan satu. Dalam kes lain ia akan menjadi lebih besar (kurang) daripada satu.
Ujian ini mempunyai taburan Fisher  . Ujian Fisher - ujian dua hujung, dan hipotesis nol
. Ujian Fisher - ujian dua hujung, dan hipotesis nol  ditolak memihak kepada alternatif
ditolak memihak kepada alternatif  Jika . Di sini di mana
Jika . Di sini di mana  – isipadu sampel pertama dan kedua, masing-masing.
– isipadu sampel pertama dan kedua, masing-masing.
Sistem STATISTICA melaksanakan ujian Fisher sebelah, i.e. varians maksimum sentiasa diambil sebagai kualiti. Dalam kes ini, hipotesis nol ditolak memihak kepada alternatif jika.
Contoh
Biarkan tugasan ditetapkan untuk membandingkan keberkesanan pengajaran dua kumpulan pelajar. Tahap prestasi akademik mencirikan tahap pengurusan proses pembelajaran, dan penyebaran adalah kualiti pengurusan pembelajaran, tahap organisasi proses pembelajaran. Kedua-dua penunjuk adalah bebas dan kes am mesti difikirkan bersama. Tahap prestasi akademik (jangkaan matematik) setiap kumpulan pelajar dicirikan oleh purata aritmetik  dan , dan kualiti dicirikan oleh varians sampel anggaran yang sepadan: dan . Apabila menilai tahap prestasi semasa, ternyata ia adalah sama untuk kedua-dua pelajar:
dan , dan kualiti dicirikan oleh varians sampel anggaran yang sepadan: dan . Apabila menilai tahap prestasi semasa, ternyata ia adalah sama untuk kedua-dua pelajar:  = = 4.0. Varian sampel:
= = 4.0. Varian sampel: 
 Dan
Dan  . Bilangan darjah kebebasan yang sepadan dengan anggaran ini:
. Bilangan darjah kebebasan yang sepadan dengan anggaran ini:  Dan
Dan  . Dari sini, untuk mewujudkan perbezaan dalam keberkesanan pembelajaran, kita boleh menggunakan kestabilan prestasi akademik, i.e. Mari kita uji hipotesis.
. Dari sini, untuk mewujudkan perbezaan dalam keberkesanan pembelajaran, kita boleh menggunakan kestabilan prestasi akademik, i.e. Mari kita uji hipotesis.
Jom kira  (perlu ada varians yang besar dalam pengangka), . Mengikut jadual ( STATISTIKA –
KebarangkalianPengagihanKalkulator)
kita dapati , yang kurang daripada dikira, oleh itu hipotesis nol harus ditolak memihak kepada alternatif. Kesimpulan ini mungkin tidak memuaskan hati penyelidik, kerana dia berminat dengan nilai sebenar nisbah
(perlu ada varians yang besar dalam pengangka), . Mengikut jadual ( STATISTIKA –
KebarangkalianPengagihanKalkulator)
kita dapati , yang kurang daripada dikira, oleh itu hipotesis nol harus ditolak memihak kepada alternatif. Kesimpulan ini mungkin tidak memuaskan hati penyelidik, kerana dia berminat dengan nilai sebenar nisbah  (kami sentiasa mempunyai varians yang besar dalam pengangka). Apabila menyemak kriteria sebelah pihak, kami mendapati ia adalah kurang daripada nilai yang dikira di atas. Jadi, hipotesis nol mesti ditolak memihak kepada alternatif.
(kami sentiasa mempunyai varians yang besar dalam pengangka). Apabila menyemak kriteria sebelah pihak, kami mendapati ia adalah kurang daripada nilai yang dikira di atas. Jadi, hipotesis nol mesti ditolak memihak kepada alternatif.
Ujian Fisher dalam program STATISTICA dalam persekitaran Windows
Untuk contoh menguji hipotesis (kriteria Fisher), kami menggunakan (membuat) fail dengan dua pembolehubah (fisher.sta):
nasi. 1. Jadual dengan dua pembolehubah tidak bersandar
Untuk menguji hipotesis adalah perlu dalam statistik asas ( asasPerangkaandanMeja) pilih ujian-t untuk pembolehubah bebas. ( ujian-t, bebas, mengikut pembolehubah).

nasi. 2. Menguji hipotesis parametrik
Selepas memilih pembolehubah dan menekan kekunci Ringkasan Nilai sisihan piawai dan kriteria Fisher dikira. Di samping itu, tahap keertian ditentukan hlm, di mana perbezaannya tidak ketara.

nasi. 3. Keputusan ujian hipotesis (Ujian-F)
menggunakan KebarangkalianKalkulator dan dengan menetapkan nilai parameter, anda boleh membina graf taburan Fisher dengan tanda nilai yang dikira.

nasi. 4. Kawasan penerimaan (penolakan) hipotesis (Kriteria F)
Sumber.
Menguji hipotesis tentang hubungan antara dua varians
URL: /tryfonov3/terms3/testdi.htm
Kuliah 6. :8080/resources/math/mop/lections/lection_6.htm
F – Ujian Fisher
URL: /home/portal/applications/Multivariatadvisor/F-Fisher/F-Fisheer.htm
Teori dan amalan penyelidikan probabilistik dan statistik.
URL: /active/referats/read/doc-3663-1.html
F – Ujian Fisher
Kriteria Fisher membolehkan anda membandingkan varians sampel dua sampel bebas. Untuk mengira F emp, anda perlu mencari nisbah varians dua sampel, supaya varians yang lebih besar berada dalam pengangka, dan yang lebih kecil berada dalam penyebut. Formula untuk mengira kriteria Fisher ialah:
di manakah varians bagi sampel pertama dan kedua, masing-masing.
Oleh kerana, mengikut syarat kriteria, nilai pengangka mestilah lebih besar daripada atau sama dengan nilai penyebut, nilai F emp akan sentiasa lebih besar daripada atau sama dengan satu.
Bilangan darjah kebebasan juga ditentukan dengan mudah:
k 1 =n l - 1 untuk sampel pertama (iaitu untuk sampel yang variansnya lebih besar) dan k 2 = n 2 - 1 untuk sampel kedua.
Dalam Lampiran 1, nilai kritikal bagi kriteria Fisher ditemui oleh nilai k 1 (baris atas jadual) dan k 2 (lajur kiri jadual).
Jika t em >t crit, maka hipotesis nol diterima, sebaliknya alternatif diterima.
Contoh 3. Ujian telah dijalankan dalam dua gred ketiga perkembangan mental sepuluh pelajar dalam ujian TURMSH. Nilai purata yang diperolehi tidak berbeza dengan ketara, tetapi ahli psikologi berminat dengan persoalan sama ada terdapat perbezaan dalam tahap kehomogenan penunjuk perkembangan mental antara kelas.
Penyelesaian. Untuk ujian Fisher, adalah perlu untuk membandingkan varians markah ujian dalam kedua-dua kelas. Keputusan ujian dibentangkan dalam jadual:
Jadual 3.
|
Bilangan pelajar |
Gred pertama |
Kelas kedua |
Setelah mengira varians untuk pembolehubah X dan Y, kami memperoleh:
s x 2 =572.83; s y 2 =174,04
Kemudian, menggunakan formula (8) untuk pengiraan menggunakan kriteria F Fisher, kita dapati:
![]()
Menurut jadual dari Lampiran 1 untuk kriteria F dengan darjah kebebasan dalam kedua-dua kes bersamaan dengan k = 10 - 1 = 9, kita dapati F crit = 3.18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Ujian bukan parametrik
Dengan membandingkan mengikut mata (mengikut peratusan) keputusan sebelum dan selepas sebarang kesan, pengkaji membuat kesimpulan bahawa jika perbezaan diperhatikan, maka terdapat perbezaan dalam sampel yang dibandingkan. Pendekatan ini secara kategorinya tidak boleh diterima, kerana untuk peratusan adalah mustahil untuk menentukan tahap kebolehpercayaan dalam perbezaan. Peratusan yang diambil sendiri tidak memungkinkan untuk membuat kesimpulan yang boleh dipercayai secara statistik. Untuk membuktikan keberkesanan sebarang campur tangan, adalah perlu untuk mengenal pasti arah aliran yang signifikan secara statistik dalam bias (anjakan) penunjuk. Untuk menyelesaikan masalah tersebut, seseorang penyelidik boleh menggunakan beberapa kriteria diskriminasi. Di bawah ini kita akan mempertimbangkan ujian bukan parametrik: ujian tanda dan ujian khi kuasa dua.
)Pengiraan kriteria φ*
1. Tentukan nilai-nilai atribut yang akan menjadi kriteria untuk membahagikan subjek kepada mereka yang "mempunyai kesan" dan mereka yang "tidak mempunyai kesan." Jika ciri diukur secara kuantitatif, gunakan kriteria λ untuk mencari titik pemisahan yang optimum.
2. Lukis jadual empat sel (sinonim: empat medan) dua lajur dan dua baris. Lajur pertama ialah "ada kesan"; lajur kedua - "tiada kesan"; baris pertama dari atas - 1 kumpulan (sampel); baris kedua - kumpulan 2 (sampel).
4. Kira bilangan subjek dalam sampel pertama yang mempunyai "tiada kesan" dan masukkan nombor ini dalam sel kanan atas jadual. Kira jumlah dua sel teratas. Ia sepatutnya bertepatan dengan bilangan subjek dalam kumpulan pertama.
6. Kira bilangan subjek dalam sampel kedua yang mempunyai "tiada kesan" dan masukkan nombor ini dalam sel sebelah kanan bawah jadual. Kira jumlah dua sel yang lebih rendah. Ia sepatutnya bertepatan dengan bilangan subjek dalam kumpulan kedua (sampel).
7. Tentukan peratusan subjek yang "mempunyai kesan" dengan mengaitkan bilangan mereka dengan jumlah bilangan subjek dalam kumpulan tertentu (sampel). Tulis peratusan yang terhasil dalam sel kiri atas dan kiri bawah jadual dalam kurungan, masing-masing, supaya tidak mengelirukan mereka dengan nilai mutlak.
8. Semak untuk melihat sama ada satu daripada peratusan yang dibandingkan adalah sama dengan sifar. Jika ini berlaku, cuba ubah ini dengan mengalihkan titik pemisahan kumpulan ke satu arah atau yang lain. Jika ini mustahil atau tidak diingini, tinggalkan kriteria φ* dan gunakan kriteria χ2.
9. Tentukan mengikut Jadual. XII Lampiran 1 sudut φ bagi setiap peratusan yang dibandingkan.
di mana: φ1 - sudut sepadan dengan peratusan yang lebih besar;
φ2 - sudut sepadan dengan peratusan yang lebih kecil;
N1 - bilangan pemerhatian dalam sampel 1;
N2 - bilangan pemerhatian dalam sampel 2.
11. Bandingkan nilai yang diperolehi φ* dengan nilai kritikal: φ* ≤1.64 (p<0,05) и φ* ≤2,31 (р<0,01).
Jika φ*emp ≤φ*cr. H0 ditolak.
Jika perlu, tentukan tahap keertian yang tepat bagi φ*emp yang terhasil mengikut Jadual. XIII Lampiran 1.
Kaedah ini diterangkan dalam banyak manual (Plokhinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992, dll.) Penerangan ini berdasarkan versi kaedah yang dibangunkan dan dibentangkan oleh E.V. Gubler.
Tujuan kriteria φ*
Kriteria Fisher direka untuk membandingkan dua sampel mengikut kekerapan berlakunya kesan (indicator) yang diminati oleh penyelidik. Lebih besar ia, lebih dipercayai perbezaannya.
Penerangan tentang kriteria
Kriteria menilai kebolehpercayaan perbezaan antara peratusan dua sampel di mana kesan (penunjuk) minat kepada kami telah direkodkan. Secara kiasan, kami membandingkan 2 keping terbaik yang dipotong daripada 2 pai dan memutuskan mana yang benar-benar lebih besar.
Intipati penjelmaan sudut Fisher adalah untuk menukar peratusan kepada nilai sudut pusat, yang diukur dalam radian. Peratusan yang lebih besar akan sepadan dengan sudut yang lebih besar φ, dan peratusan yang lebih kecil akan sepadan dengan sudut yang lebih kecil, tetapi hubungan di sini tidak linear:
di mana P ialah peratusan yang dinyatakan dalam pecahan unit (lihat Rajah 5.1).
Dengan percanggahan yang semakin meningkat antara sudut φ 1 dan φ 2 dan menambah bilangan sampel, nilai kriteria meningkat. Semakin besar nilai φ*, semakin besar kemungkinan perbezaannya adalah ketara.
Hipotesis
H 0 : Bahagian orang, di mana kesan yang dikaji menunjukkan dirinya, tidak ada lebih dalam sampel 1 daripada sampel 2.
H 1 : Perkadaran individu yang mempamerkan kesan yang dikaji adalah lebih besar dalam sampel 1 daripada sampel 2.
Perwakilan grafik bagi kriteria φ*
Kaedah transformasi sudut agak lebih abstrak daripada kriteria lain.
Formula yang diikuti oleh E.V. Gubler apabila mengira nilai φ mengandaikan bahawa 100% membentuk sudut φ=3.142, iaitu nilai bulat π=3.14159... Ini membolehkan kita membentangkan sampel yang dibandingkan dalam bentuk dua separuh bulatan, setiap satu melambangkan 100% populasi sampelnya. Peratusan subjek dengan "kesan" akan diwakili sebagai sektor yang dibentuk oleh sudut pusat φ. Dalam Rajah. Rajah 5.2 menunjukkan dua separuh bulatan yang menggambarkan Contoh 1. Dalam sampel pertama, 60% subjek menyelesaikan masalah. Peratusan ini sepadan dengan sudut φ=1.772. Dalam sampel kedua, 40% subjek menyelesaikan masalah. Peratusan ini sepadan dengan sudut φ =1.369.
Kriteria φ* membolehkan anda menentukan sama ada satu daripada sudut itu secara statistik lebih unggul daripada sudut yang lain untuk saiz sampel yang diberikan.
Had kriteria φ*
1. Tiada satu pun perkadaran yang dibandingkan harus sifar. Secara formal, tiada halangan untuk menggunakan kaedah φ dalam kes-kes di mana perkadaran pemerhatian dalam salah satu sampel adalah sama dengan 0. Walau bagaimanapun, dalam kes-kes ini, hasilnya mungkin berubah secara tidak wajar (Gubler E.V., 1978, p. . 86).
2. Atas tiada had dalam kriteria φ - sampel boleh menjadi sebesar yang dikehendaki.
Lebih rendah had - 2 pemerhatian dalam salah satu sampel. Walau bagaimanapun, nisbah berikut dalam bilangan dua sampel mesti diperhatikan:
a) jika satu sampel hanya mempunyai 2 pemerhatian, maka yang kedua mesti mempunyai sekurang-kurangnya 30:
b) jika satu daripada sampel hanya mempunyai 3 pemerhatian, maka yang kedua mesti mempunyai sekurang-kurangnya 7:
c) jika satu daripada sampel hanya mempunyai 4 pemerhatian, maka yang kedua mesti mempunyai sekurang-kurangnya 5:
d) padan 1 , n 2 ≥ 5 Sebarang perbandingan boleh dilakukan.
Pada dasarnya, ia juga mungkin untuk membandingkan sampel yang tidak memenuhi syarat ini, sebagai contoh, dengan hubungann 1 =2, n 2 = 15, tetapi dalam kes ini adalah mustahil untuk mengenal pasti perbezaan yang ketara.
Kriteria φ* tidak mempunyai sekatan lain.
Mari kita lihat beberapa contoh untuk menggambarkan kemungkinankriteria φ*.
Contoh 1: perbandingan sampel mengikut ciri yang ditentukan secara kualitatif.
Contoh 2: perbandingan sampel mengikut ciri yang diukur secara kuantitatif.
Contoh 3: perbandingan sampel mengikut tahap dan taburan ciri.
Contoh 4: Menggunakan kriteria φ* dalam kombinasi dengan kriteriaX Kolmogorov-Smirnov untuk mencapai hasil yang paling tepat.
Contoh 1 - perbandingan sampel mengikut ciri yang ditentukan secara kualitatif
Dalam penggunaan kriteria ini, kami membandingkan peratusan subjek dalam satu sampel yang dicirikan oleh beberapa kualiti dengan peratusan subjek dalam sampel lain yang dicirikan oleh kualiti yang sama.
Katakan kami berminat sama ada dua kumpulan pelajar berbeza dalam kejayaan mereka dalam menyelesaikan masalah eksperimen baharu. Dalam kumpulan pertama 20 orang, 12 orang mengatasinya, dan dalam sampel kedua 25 orang - 10. Dalam kes pertama, peratusan mereka yang menyelesaikan masalah akan menjadi 12/20·100%=60%, dan dalam 10/25 kedua·100%= 40%. Adakah peratusan ini berbeza dengan ketara berdasarkan data?n 1 Dann 2 ?
Nampaknya walaupun "dengan mata" seseorang boleh menentukan bahawa 60% adalah jauh lebih tinggi daripada 40%. Walau bagaimanapun, sebenarnya, perbezaan ini, memandangkan datan 1 , n 2 tidak boleh dipercayai.
Jom semak. Oleh kerana kami berminat dengan fakta menyelesaikan masalah, kami akan menganggap kejayaan dalam menyelesaikan masalah eksperimen sebagai "kesan", dan kegagalan dalam menyelesaikannya sebagai ketiadaan kesan.
Mari kita rumuskan hipotesis.
H 0 : Bahagian orangTiada lagi orang yang menyelesaikan tugasan dalam kumpulan pertama berbanding kumpulan kedua.
H 1 : Peratusan orang yang menyelesaikan tugasan dalam kumpulan pertama adalah lebih besar daripada kumpulan kedua.
Sekarang mari kita bina apa yang dipanggil jadual empat sel, atau empat medan, yang sebenarnya merupakan jadual frekuensi empirikal untuk dua nilai atribut: "ada kesan" - "tidak ada kesan."
Jadual 5.1
Jadual empat sel untuk mengira kriteria apabila membandingkan dua kumpulan subjek mengikut peratusan mereka yang menyelesaikan masalah.
Kumpulan | "Ada kesan": masalah diselesaikan | "Tiada kesan": masalah tidak diselesaikan | Jumlah |
||||
Kuantiti mata pelajaran | % kongsi | Kuantiti mata pelajaran | % bahagian | ||||
1 kumpulan | (60%) | (40%) | |||||
kumpulan ke-2 | (40%) | (60%) | |||||
Jumlah | |||||||
Dalam jadual empat sel, sebagai peraturan, lajur "Terdapat kesan" dan "Tiada kesan" ditandakan di bahagian atas dan baris "Kumpulan 1" dan "Kumpulan 2" berada di sebelah kiri. Malah, hanya medan (sel) A dan B yang terlibat dalam perbandingan, iaitu bahagian peratusan dalam lajur "Terdapat kesan".
Mengikut JadualXIILampiran 1 menentukan nilai φ sepadan dengan peratusan bahagian dalam setiap kumpulan.
Sekarang mari kita hitung nilai empirikal φ* menggunakan formula:
di mana φ 1 - sudut sepadan dengan bahagian % yang lebih besar;
φ 2 - sudut sepadan dengan bahagian % yang lebih kecil;
n 1 - bilangan pemerhatian dalam sampel 1;
n 2 - bilangan pemerhatian dalam sampel 2.
Dalam kes ini:
Mengikut JadualXIIIDalam Lampiran 1 kita menentukan tahap keertian yang sepadan dengan φ* em=1,34:
p=0.09
Ia juga mungkin untuk mewujudkan nilai kritikal φ* yang sepadan dengan tahap yang diterima dalam psikologi kepentingan statistik:
Mari kita bina "paksi kepentingan".
Nilai empirikal φ* yang diperoleh adalah dalam zon tidak signifikan.
Jawapan: H 0 diterima. Peratusan orang yang menyelesaikan tugasVdalam kumpulan pertama tidak lebih daripada kumpulan kedua.
Seseorang hanya boleh bersimpati dengan penyelidik yang menganggap perbezaan 20% malah 10% ketara tanpa menyemak kebolehpercayaannya menggunakan kriteria φ*. Dalam kes ini, sebagai contoh, hanya perbezaan sekurang-kurangnya 24.3% boleh dipercayai.
Nampaknya apabila membandingkan dua sampel pada mana-mana asas kualitatif, kriteria φ boleh membuat kita sedih dan bukannya gembira. Perkara yang kelihatan penting mungkin tidak begitu dari sudut pandangan statistik.
Lebih banyak peluang untuk menggembirakan penyelidik muncul dengan kriteria Fisher apabila kami membandingkan dua sampel mengikut ciri yang diukur secara kuantitatif dan boleh mengubah "kesan".
Contoh 2 - perbandingan dua sampel mengikut ciri yang diukur secara kuantitatif
Dalam penggunaan kriteria ini, kami membandingkan peratusan subjek dalam satu sampel yang mencapai tahap nilai atribut tertentu dengan peratusan subjek yang mencapai tahap ini dalam sampel lain.
Dalam kajian oleh G. A. Tlegenova (1990), daripada 70 pelajar sekolah vokasional muda berumur 14 hingga 16 tahun, 10 subjek dengan skor tinggi pada skala Agresi dan 11 subjek dengan skor rendah pada skala Agresi dipilih berdasarkan keputusan daripada tinjauan menggunakan Soal Selidik Personaliti Freiburg. Adalah perlu untuk menentukan sama ada kumpulan lelaki muda yang agresif dan tidak agresif berbeza dari segi jarak yang mereka pilih secara spontan dalam perbualan dengan rakan pelajar. Data G. A. Tlegenova dibentangkan dalam Jadual. 5.2. Anda boleh perhatikan bahawa lelaki muda yang agresif lebih kerap memilih jarak 50cm atau kurang, manakala kanak-kanak lelaki yang tidak agresif lebih kerap memilih jarak lebih daripada 50 cm.
Sekarang kita boleh menganggap jarak 50 cm sebagai kritikal dan menganggap bahawa jika jarak yang dipilih oleh subjek kurang daripada atau sama dengan 50 cm, maka "terdapat kesan," dan jika jarak yang dipilih lebih besar daripada 50 cm, maka "tiada kesan." Kami melihat bahawa dalam kumpulan lelaki muda yang agresif kesannya diperhatikan dalam 7 daripada 10, iaitu dalam 70% kes, dan dalam kumpulan lelaki muda yang tidak agresif - dalam 2 daripada 11, iaitu dalam 18.2% kes . Peratusan ini boleh dibandingkan menggunakan kaedah φ* untuk menentukan kepentingan perbezaan antara mereka.
Jadual 5.2
Penunjuk jarak (dalam cm) yang dipilih oleh lelaki muda yang agresif dan tidak agresif dalam perbualan dengan rakan pelajar (menurut G.A. Tlegenova, 1990)
Kumpulan 1: budak lelaki dengan markah tinggi pada skala AgresiFPI- R (n 1 =10) | Kumpulan 2: kanak-kanak lelaki dengan nilai rendah pada skala KeagresifanFPI- R (n 2 =11) |
|||
d(c m ) | % bahagian | d(c M ) | % bahagian |
|
“Makan Kesan" d≤50 sm | ||||
18,2% |
||||
"Tidak kesan" d>50 cm | ||||
80 QO | 81,8% |
|||
Jumlah | 100% | 100% |
||
Purata | 5b:o | 77.3 | ||
Mari kita rumuskan hipotesis.
H 0 d ≤ 50 cm, dalam kumpulan kanak-kanak lelaki yang agresif tidak lebih daripada kumpulan lelaki yang tidak agresif.
H 1 : Peratusan orang yang memilih jarakd≤ 50 cm, lebih banyak dalam kumpulan lelaki muda yang agresif daripada kumpulan lelaki muda yang tidak agresif. Sekarang mari kita bina apa yang dipanggil jadual empat sel.
Jadual 53
Jadual empat sel untuk mengira kriteria φ* apabila membandingkan kumpulan agresif (nf=10) dan lelaki muda yang tidak agresif (n2=11)
Kumpulan | "Ada kesan": d≤50 | "Tiada kesan." d>50 | Jumlah |
||||
Bilangan mata pelajaran | (% bahagian) | Bilangan mata pelajaran | (% bahagian) | ||||
Kumpulan 1 - lelaki muda yang agresif | (70%) | (30%) | |||||
Kumpulan 2 - lelaki muda yang tidak agresif | (180%) | (81,8%) | |||||
Jumlah | |||||||
Mengikut JadualXIILampiran 1 menentukan nilai φ yang sepadan dengan bahagian peratusan "kesan" dalam setiap kumpulan.
Nilai empirikal φ* yang diperoleh adalah dalam zon keertian.
Jawapan: H 0 ditolak. DiterimaH 1 . Perkadaran orang yang memilih jarak dalam perbualan kurang daripada atau sama dengan 50 cm adalah lebih besar dalam kumpulan lelaki muda yang agresif berbanding kumpulan lelaki muda yang tidak agresif
Berdasarkan keputusan yang diperoleh, kita boleh membuat kesimpulan bahawa lelaki muda yang lebih agresif lebih kerap memilih jarak kurang daripada setengah meter, manakala lelaki muda tidak agresif lebih kerap memilih jarak lebih daripada setengah meter. Kami melihat bahawa lelaki muda yang agresif sebenarnya berkomunikasi di sempadan antara zon intim (0-46 cm) dan peribadi (dari 46 cm). Walau bagaimanapun, kami ingat bahawa jarak intim antara pasangan adalah hak prerogatif bukan sahaja hubungan yang rapat dan baik, tetapiDanpertempuran tangan (DewanE. T., 1959).
Contoh 3 - perbandingan sampel mengikut tahap dan taburan ciri.
Dalam kes penggunaan ini, mula-mula kita boleh menguji sama ada kumpulan berbeza dalam tahap beberapa sifat dan kemudian membandingkan taburan sifat dalam dua sampel. Tugas sedemikian mungkin relevan apabila menganalisis perbezaan dalam julat atau bentuk taburan penilaian yang diperolehi oleh subjek menggunakan sebarang teknik baharu.
Dalam kajian oleh R. T. Chirkina (1995), buat pertama kalinya, soal selidik digunakan bertujuan untuk mengenal pasti kecenderungan untuk menindas fakta, nama, niat dan kaedah tindakan daripada ingatan kerana kompleks peribadi, keluarga dan profesional. Soal selidik itu dibuat dengan penyertaan E.V. Sidorenko berdasarkan bahan dari buku 3. Freud "Psychopathology of Everyday Life". Sampel 50 pelajar Institut Pedagogi, belum berkahwin, tanpa anak, berumur 17 hingga 20 tahun, telah diperiksa menggunakan soal selidik ini, serta teknik Menester-Corzini untuk mengenal pasti intensiti perasaan kekurangan peribadi,atau"rasa rendah diri" (PengurusG. J., CorsiniR. J., 1982).
Keputusan tinjauan dibentangkan dalam Jadual. 5.4.
Adakah mungkin untuk mengatakan bahawa terdapat sebarang hubungan yang signifikan antara penunjuk tenaga penindasan, yang didiagnosis menggunakan soal selidik, dan penunjuk keamatan perasaan kekurangan diri sendiri?
Jadual 5.4
Petunjuk keamatan perasaan kekurangan diri dalam kumpulan pelajar yang tinggi (nj=18) dan tenaga sesaran rendah (n2=24).
Kumpulan 1: tenaga sesaran dari 19 hingga 31 mata (n 1 =181 | Kumpulan 2: tenaga sesaran dari 7 hingga 13 mata (n 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
Jumlah Purata | 26,11 | 15,42 |
Walaupun fakta bahawa nilai purata dalam kumpulan dengan penindasan yang lebih bertenaga adalah lebih tinggi, 5 nilai sifar juga diperhatikan di dalamnya. Jika kita membandingkan histogram taburan penarafan dalam kedua-dua sampel, kontras yang ketara ditunjukkan di antara mereka (Rajah 5.3).
Untuk membandingkan dua taburan kita boleh menggunakan ujianχ 2 atau kriteriaλ , tetapi untuk ini kita perlu membesarkan digit, dan sebagai tambahan, dalam kedua-dua sampeln <30.
Kriteria φ* akan membolehkan kita menyemak kesan percanggahan antara dua taburan yang diperhatikan dalam graf jika kita bersetuju untuk menganggap bahawa "terdapat kesan" jika penunjuk perasaan tidak mencukupi mengambil masa sama ada sangat rendah (0) atau, sebaliknya , nilai yang sangat tinggi (S30), dan "tiada kesan" jika penunjuk perasaan tidak mencukupi mengambil nilai purata, dari 5 hingga 25.
Mari kita rumuskan hipotesis.
H 0 : Nilai ekstrem indeks kekurangan (sama ada 0 atau 30 atau lebih) dalam kumpulan dengan penindasan yang lebih bertenaga tidak lebih biasa daripada dalam kumpulan dengan penindasan yang kurang bertenaga.
H 1 : Nilai ekstrem indeks kekurangan (sama ada 0 atau 30 atau lebih) dalam kumpulan dengan penindasan yang lebih bertenaga adalah lebih biasa daripada dalam kumpulan dengan penindasan yang kurang bertenaga.
Mari kita cipta jadual empat sel yang sesuai untuk pengiraan selanjutnya bagi kriteria φ*.
Jadual 5.5
Jadual empat sel untuk mengira kriteria φ* apabila membandingkan kumpulan dengan tenaga penindasan yang lebih tinggi dan lebih rendah berdasarkan nisbah penunjuk ketidakcukupan
Kumpulan | “Terdapat kesan”: penunjuk kekurangan ialah 0 atau >30 | "Tiada kesan": indeks kegagalan dari 5 hingga 25 | Jumlah |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
Jumlah | |||||
Mengikut JadualXIIDalam Lampiran 1 kami menentukan nilai φ sepadan dengan peratusan yang dibandingkan:
Mari kita hitung nilai empirikal φ*:
Nilai kritikal φ* untuk mana-manan 1 , n 2 , seperti yang kita ingat dari contoh sebelumnya, ialah:
JadualXIIILampiran 1 membolehkan kita menentukan dengan lebih tepat tahap kepentingan keputusan yang diperolehi: p<0,001.
Jawapan: H 0 ditolak. DiterimaH 1 . Nilai ekstrem indeks kekurangan (sama ada 0 atau 30 atau lebih) dalam kumpulan dengan tenaga penindasan yang lebih besar berlaku lebih kerap daripada dalam kumpulan yang kurang tenaga penindasan.
Jadi, subjek dengan tenaga penindasan yang lebih besar boleh mempunyai kedua-dua penunjuk yang sangat tinggi (30 atau lebih) dan sangat rendah (sifar) tentang perasaan kekurangan mereka sendiri. Ia boleh diandaikan bahawa mereka sedang menindas kedua-dua ketidakpuasan hati mereka dan keperluan untuk berjaya dalam hidup. Andaian ini memerlukan ujian lanjut.
Keputusan yang diperoleh, tanpa mengira tafsirannya, mengesahkan keupayaan kriteria φ* dalam menilai perbezaan dalam bentuk taburan sifat dalam dua sampel.
Sampel asal termasuk 50 orang, tetapi 8 daripada mereka dikecualikan daripada pertimbangan sebagai mempunyai skor purata pada indeks anergi penindasan (14-15). Penunjuk mereka tentang keamatan perasaan tidak mencukupi juga adalah purata: 6 nilai 20 mata setiap satu dan 2 nilai 25 mata setiap satu.
Keupayaan kuat bagi kriteria φ* boleh disahkan dengan mengesahkan hipotesis yang sama sekali berbeza apabila menganalisis bahan contoh ini. Kita boleh membuktikan, sebagai contoh, bahawa dalam kumpulan yang mempunyai tenaga penindasan yang lebih besar kadar ketidakcukupan masih lebih tinggi, walaupun sifat paradoks pengedarannya dalam kumpulan ini.
Mari kita rumuskan hipotesis baru.
H 0 Nilai indeks kekurangan tertinggi (30 atau lebih) dalam kumpulan dengan tenaga penindasan yang lebih besar adalah tidak lebih biasa daripada dalam kumpulan dengan tenaga penindasan yang kurang.
H 1 : Nilai indeks kekurangan tertinggi (30 atau lebih) dalam kumpulan dengan tenaga penindasan yang lebih besar berlaku lebih kerap daripada dalam kumpulan yang kurang tenaga penindasan. Mari bina jadual empat medan menggunakan data dalam Jadual. 5.4.
Jadual 5.6
Jadual empat sel untuk mengira kriteria φ* apabila membandingkan kumpulan dengan tenaga penindasan yang lebih besar dan lebih kecil mengikut penunjuk tahap ketidakcukupan
Kumpulan | “Ada kesan”* penunjuk kegagalan lebih besar daripada atau sama dengan 30 | "Tiada kesan": kadar kegagalan adalah kurang 30 | Jumlah |
||
Kumpulan 1 - dengan tenaga sesaran yang lebih besar | (61,1%) | (38.9%) | |||
Kumpulan 2 - dengan tenaga sesaran yang lebih rendah | (25.0%) | (75.0%) | |||
Jumlah | |||||
Mengikut JadualXIIIDalam Lampiran 1 kami menentukan bahawa keputusan ini sepadan dengan tahap keertian p = 0.008.
Jawapan: Tetapi ia ditolak. DiterimaHj: Penunjuk kekurangan tertinggi (30 atau lebih mata) dalam kumpulanDengandengan tenaga sesaran yang lebih besar berlaku lebih kerap berbanding kumpulan dengan tenaga sesaran yang kurang (p = 0.008).
Jadi, kami dapat membuktikannyaVkumpulanDengandengan penindasan yang lebih bertenaga, nilai ekstrem penunjuk ketidakcukupan mendominasi, dan fakta bahawa penunjuk ini melebihi nilainyamencapaibetul-betul dalam kumpulan ini.
Sekarang kita boleh cuba membuktikan bahawa dalam kumpulan dengan tenaga penindasan yang lebih tinggi, nilai indeks kekurangan yang lebih rendah adalah lebih biasa, walaupun pada hakikatnya nilai purataV kumpulan ini mempunyai lebih banyak (26.11 berbanding 15.42 dalam kumpulanDengan kurang anjakan).
Mari kita rumuskan hipotesis.
H 0 : Kadar kekurangan terendah (sifar) dalam kumpulanDengan penindasan dengan tenaga yang lebih besar tidak lebih biasa daripada dalam kumpulanDengan kurang tenaga sesaran.
H 1 : Kadar kekurangan yang paling rendah (sifar) berlakuV kumpulan dengan tenaga penindasan yang lebih besar lebih kerap daripada dalam kumpulanDengan penindasan yang kurang bertenaga. Mari kumpulkan data ke dalam jadual empat sel baharu.
Jadual 5.7
Jadual empat sel untuk membandingkan kumpulan dengan tenaga penindasan yang berbeza berdasarkan kekerapan nilai sifar penunjuk kekurangan
Kumpulan | "Terdapat kesan": penunjuk kegagalan ialah 0 | "Tiada kesan" kekurangan | penunjuk tidak sama dengan 0 | Jumlah |
|
Kumpulan 1 - dengan tenaga sesaran yang lebih besar | (27,8%) | (72,2%) | |||
1 kumpulan - dengan kurang tenaga sesaran | (8,3%) | (91,7%) | |||
Jumlah | |||||
Kami menentukan nilai φ dan mengira nilai φ*:
Jawapan: H 0 ditolak. Indeks ketidakcukupan terendah (sifar) dalam kumpulan dengan tenaga penindasan yang lebih besar adalah lebih biasa daripada kumpulan dengan tenaga penindasan yang kurang (p<0,05).
Secara keseluruhan, keputusan yang diperoleh boleh dianggap sebagai bukti kebetulan separa konsep kompleks dalam S. Freud dan A. Adler.
Adalah penting bahawa korelasi linear positif diperolehi antara penunjuk tenaga penindasan dan penunjuk keamatan perasaan ketidakcukupan sendiri dalam sampel secara keseluruhan (p = +0.491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Contoh 4 - menggunakan kriteria φ* dalam kombinasi dengan kriteria λ Kolmogorov-Smirnov untuk mencapai maksimum tepathasil
Jika sampel dibandingkan mengikut mana-mana penunjuk yang diukur secara kuantitatif, masalah timbul untuk mengenal pasti titik pengedaran yang boleh digunakan sebagai titik kritikal dalam membahagikan semua subjek kepada mereka yang "mempunyai kesan" dan mereka yang "tidak mempunyai kesan."
Pada dasarnya, titik di mana kita akan membahagikan kumpulan kepada subkumpulan di mana terdapat kesan dan di mana tiada kesan boleh dipilih dengan sewenang-wenangnya. Kami boleh berminat dengan sebarang kesan dan, oleh itu, kami boleh membahagikan kedua-dua sampel kepada dua bahagian pada bila-bila masa, asalkan ia masuk akal.
Untuk memaksimumkan kuasa ujian φ*, bagaimanapun, adalah perlu untuk memilih titik di mana perbezaan antara dua kumpulan yang dibandingkan adalah paling besar. Paling tepat, kita boleh melakukan ini menggunakan algoritma untuk mengira kriteriaλ , membolehkan anda mengesan titik percanggahan maksimum antara dua sampel.
Kemungkinan menggabungkan kriteria φ* danλ diterangkan oleh E.V. Gubler (1978, hlm. 85-88). Mari cuba gunakan kaedah ini dalam menyelesaikan masalah berikut.
Dalam kajian bersama oleh M.A. Kurochkina, E.V. Sidorenko dan Yu.A. Churakov (1992) di UK menjalankan tinjauan ke atas pengamal am Inggeris bagi dua kategori: a) doktor yang menyokong pembaharuan perubatan dan telah menukar pejabat penerimaan mereka menjadi organisasi pegangan dana dengan bajet mereka sendiri; b) doktor yang pejabatnya masih tidak mempunyai dana sendiri dan disediakan sepenuhnya oleh belanjawan negara. Soal selidik telah dihantar kepada sampel 200 doktor, mewakili populasi umum doktor Inggeris dari segi perwakilan orang yang berlainan jantina, umur, tempoh perkhidmatan dan tempat kerja - di bandar besar atau di wilayah.
78 doktor menjawab soal selidik, di mana 50 daripadanya bekerja di bilik menunggu dengan dana dan 28 dari bilik menunggu tanpa dana. Setiap doktor perlu meramalkan berapa bahagian kemasukan dengan dana pada tahun hadapan, 1993. Hanya 70 doktor daripada 78 yang menghantar jawapan menjawab soalan ini. Taburan ramalan mereka dibentangkan dalam Jadual. 5.8 secara berasingan untuk kumpulan doktor dengan dana dan kumpulan doktor tanpa dana.
Adakah prognosis doktor dengan dana dan doktor tanpa dana berbeza dalam apa cara sekalipun?
Jadual 5.8
Pengagihan ramalan daripada pengamal am tentang bahagian bilik kecemasan dengan dana pada tahun 1993
Bahagian yang diunjurkan | |||
bilik penerimaan dengan dana | doktor dengan dana (n 1 =45) | doktor tanpa dana (n 2 =25) | Jumlah |
1. daripada 0 hingga 20% | 4 | 5 | 9 |
2. daripada 21 hingga 40% | 15 | DAN | 26 |
3. daripada 41 hingga 60% | 18 | 5 | 23 |
4. daripada 61 hingga 80% | 7 | 4 | DAN |
5. daripada 81 hingga 100% | 1 | 0 | 1 |
Jumlah | 45 | 25 | 70 |
Mari kita tentukan titik percanggahan maksimum antara dua taburan tindak balas menggunakan Algoritma 15 daripada klausa 4.3 (lihat Jadual 5.9).
Jadual 5.9
Pengiraan perbezaan maksimum dalam kekerapan terkumpul dalam pengagihan ramalan doktor dua kumpulan
Unjuran bahagian kemasukan dengan dana (%) | Frekuensi empirikal pilihan untuk kategori tindak balas yang diberikan | Frekuensi empirikal | Kekerapan empirikal kumulatif | Beza (d) |
|||
doktor dengan dana itu(n 1 =45) | doktor tanpa dana (n 2 =25) | f* eh 1 | f* a2 | ∑f* e1 | ∑f* a1 |
||
1. daripada 0 hingga 20% 2. daripada 21 hingga 40% 3. daripada 41 hingga 60% 4. daripada 61 hingga 80% 5. daripada 81 hingga 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
Perbezaan maksimum yang dikesan antara dua frekuensi empirikal terkumpul ialah0,218.
Perbezaan ini ternyata terkumpul dalam kategori kedua ramalan. Mari cuba gunakan had atas kategori ini sebagai kriteria untuk membahagikan kedua-dua sampel kepada subkumpulan yang "ada kesan" dan subkumpulan yang "tiada kesan." Kami akan menganggap bahawa terdapat "kesan" jika doktor tertentu meramalkan dari 41 hingga 100% kemasukan dengan dana dalam1993 tahun, dan "tiada kesan" jika doktor tertentu meramalkan dari 0 hingga 40% kemasukan dengan dana dalam1993 tahun. Kami menggabungkan kategori ramalan 1 dan 2 di satu pihak, dan ramalan kategori 3, 4 dan 5 di pihak yang lain. Taburan ramalan yang terhasil dibentangkan dalam Jadual. 5.10.
Jadual 5.10
Pengagihan ramalan untuk doktor dengan dana dan doktor tanpa dana
Unjuran bahagian kemasukan dengan dana (%1 | Kekerapan empirikal untuk memilih kategori ramalan yang diberikan | Jumlah |
|
doktor dengan dana itu(n 1 =45) | doktor tanpa dana(n 2 =25) |
||
1. dari 0 hingga 40% | 19 | 16 | 35 |
2. daripada 41 hingga 100% | 26 | 9 | 35 |
Jumlah | 45 | 25 | 70 |
Kita boleh menggunakan jadual yang terhasil (Jadual 5.10) untuk menguji hipotesis yang berbeza dengan membandingkan mana-mana dua selnya. Kami ingat bahawa ini adalah apa yang dipanggil empat sel, atau empat medan, jadual.
Di sini, kami berminat sama ada doktor yang sudah mempunyai dana meramalkan pertumbuhan masa depan pergerakan ini yang lebih besar daripada doktor yang tidak mempunyai dana. Oleh itu, kami secara bersyarat menganggap bahawa "terdapat kesan" apabila ramalan jatuh ke dalam kategori dari 41 hingga 100%. Untuk memudahkan pengiraan, kita kini perlu memutarkan jadual 90°, memutarkannya mengikut arah jam. Anda juga boleh melakukan ini secara literal dengan memusingkan buku bersama-sama dengan meja. Sekarang kita boleh beralih ke lembaran kerja untuk mengira kriteria φ* - Transformasi Sudut Fisher.
Jadual 5.11
Jadual empat sel untuk mengira kriteria φ* Fisher untuk mengenal pasti perbezaan dalam ramalan dua kumpulan pengamal am
Kumpulan | Terdapat kesan - ramalan dari 41 hingga 100% | Tiada kesan - ramalan dari 0 hingga 40% | Jumlah |
sayakumpulan - doktor yang mengambil dana | 26 (57.8%) | 19 (42.2%) | 45 |
IIkumpulan - doktor yang tidak mengambil dana | 9 (36.0%) | 16 (64.0%) | 25 |
Jumlah | 35 | 35 | 70 |
Mari kita rumuskan hipotesis.
H 0 : Peratusan orangmeramalkan penyebaran dana kepada 41%-100% daripada semua pejabat doktor, dalam kumpulan doktor dengan dana tidak lebih daripada dalam kumpulan doktor tanpa dana.
H 1 : Perkadaran orang yang meramalkan penyebaran dana kepada 41%-100% daripada semua kemasukan adalah lebih besar dalam kumpulan doktor dengan dana berbanding kumpulan doktor tanpa dana.
Menentukan nilai φ 1 dan φ 2 mengikut JadualXIILampiran 1. Ingat bahawa φ 1 sentiasa sudut sepadan dengan peratusan yang lebih besar.
Sekarang mari kita tentukan nilai empirikal bagi kriteria φ*:
Mengikut JadualXIIIDalam Lampiran 1 kita menentukan tahap keertian nilai ini sepadan dengan: p = 0.039.
Menggunakan jadual yang sama dalam Lampiran 1, anda boleh menentukan nilai kritikal bagi kriteria φ*:
Jawapan: Tetapi ia ditolak (p=0.039). Bahagian orang yang meramalkan penyebaran dana kepada41-100 % daripada semua resepsi dalam kumpulan doktor yang mengambil dana melebihi bahagian ini dalam kumpulan doktor yang tidak mengambil dana.
Dalam erti kata lain, doktor yang sudah bekerja di bilik menunggu mereka dengan bajet yang berasingan meramalkan penyebaran amalan ini yang lebih luas tahun ini berbanding doktor yang belum bersetuju untuk beralih kepada belanjawan bebas. Terdapat pelbagai tafsiran hasil ini. Sebagai contoh, boleh diandaikan bahawa doktor dalam setiap kumpulan secara tidak sedar menganggap tingkah laku mereka lebih tipikal. Ini juga mungkin bermakna bahawa doktor yang telah menerima pakai pembiayaan sendiri cenderung untuk membesar-besarkan skop pergerakan ini, kerana mereka perlu mewajarkan keputusan mereka. Perbezaan yang dikenal pasti juga mungkin bermakna sesuatu yang benar-benar di luar skop soalan yang dikemukakan dalam kajian. Sebagai contoh, bahawa aktiviti doktor bekerja pada belanjawan bebas menyumbang kepada menajamkan perbezaan dalam kedudukan kedua-dua kumpulan. Mereka lebih aktif apabila mereka bersetuju untuk mengambil dana mereka lebih aktif apabila mereka bersusah payah menjawab soal selidik mel; mereka lebih aktif apabila mereka meramalkan bahawa doktor lain akan lebih aktif dalam menerima dana.
Satu cara atau yang lain, kita boleh yakin bahawa tahap perbezaan statistik yang dikesan adalah maksimum yang mungkin untuk data sebenar ini. Kami menubuhkan menggunakan kriteriaλ titik perbezaan maksimum antara dua taburan, dan pada ketika inilah sampel dibahagikan kepada dua bahagian.
Tanda awak.
Fungsi FISCHER mengembalikan transformasi Fisher bagi argumen kepada X . Transformasi ini menghasilkan fungsi yang mempunyai taburan normal dan bukannya serong. Fungsi FISCHER digunakan untuk menguji hipotesis menggunakan pekali korelasi.
Penerangan tentang fungsi FISCHER dalam Excel
Apabila bekerja dengan fungsi ini, anda mesti menetapkan nilai pembolehubah. Perlu diperhatikan dengan segera bahawa terdapat beberapa situasi di mana fungsi ini tidak akan menghasilkan hasil. Ini mungkin jika pembolehubah:
- bukan nombor. Dalam keadaan sedemikian, fungsi FISCHER akan mengembalikan nilai ralat #VALUE!;
- mempunyai nilai sama ada kurang daripada -1 atau lebih besar daripada 1. Dalam kes ini, fungsi FISCHER akan mengembalikan nilai ralat #NUM!.
Persamaan yang digunakan untuk menerangkan fungsi FISCHER secara matematik ialah:
Z"=1/2*ln(1+x)/(1-x)
Mari kita lihat penggunaan fungsi ini menggunakan 3 contoh khusus.
Anggaran hubungan antara keuntungan dan kos menggunakan fungsi FISHER
Contoh 1. Menggunakan data mengenai aktiviti organisasi komersial, ia dikehendaki membuat penilaian tentang hubungan antara keuntungan Y (juta rubel) dan kos X (juta rubel) yang digunakan untuk pembangunan produk (ditunjukkan dalam Jadual 1).
Jadual 1 – Data awal:
| № | X | Y |
| 1 | 210,000,000.00 RUR | 95,000,000.00 RUR |
| 2 | RUB 1,068,000,000.00 | 76,000,000.00 RUR |
| 3 | RUB 1,005,000,000.00 | 78,000,000.00 RUR |
| 4 | 610,000,000.00 RUR | 89,000,000.00 RUR |
| 5 | 768,000,000.00 RUR | 77,000,000.00 RUR |
| 6 | 799,000,000.00 RUR | 85,000,000.00 RUR |
Skim untuk menyelesaikan masalah tersebut adalah seperti berikut:
- Dikira pekali linear korelasi r xy ;
- Kepentingan pekali korelasi linear disemak berdasarkan ujian-t Pelajar. Dalam kes ini, hipotesis dikemukakan dan diuji bahawa pekali korelasi adalah sama dengan sifar. Statistik-t digunakan untuk menguji hipotesis ini. Jika hipotesis disahkan, statistik-t mempunyai taburan Pelajar. Jika nilai yang dikira t p > t cr, maka hipotesis ditolak, yang menunjukkan kepentingan pekali korelasi linear, dan oleh itu kepentingan statistik hubungan antara X dan Y;
- Anggaran selang untuk pekali korelasi linear yang signifikan secara statistik ditentukan.
- Anggaran selang untuk pekali korelasi linear ditentukan berdasarkan perubahan Fisher z songsang;
- Ralat piawai bagi pekali korelasi linear dikira.
Keputusan penyelesaian masalah ini dengan fungsi yang digunakan dalam Excel ditunjukkan dalam Rajah 1.
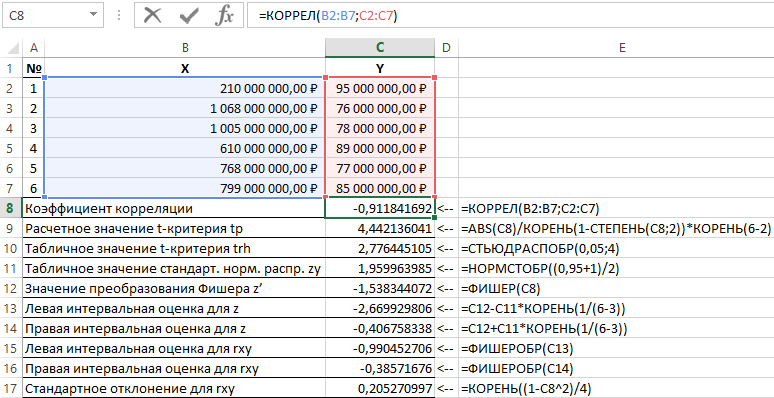
Rajah 1 – Contoh pengiraan.
| Tidak. | Nama penunjuk | Formula pengiraan |
| 1 | Pekali korelasi | =CORREL(B2:B7,C2:C7) |
| 2 | Nilai ujian-t dikira tp | =ABS(C8)/SQRT(1-KUASA(C8,2))*SQRT(6-2) |
| 3 | Nilai jadual trh ujian-t | =KAJIAN(0.05,4) |
| 4 | Nilai jadual standard taburan normal zy | =NORMSINV((0.95+1)/2) |
| 5 | Nilai transformasi Fisher z’ | =FISHER(C8) |
| 6 | Anggaran selang kiri untuk z | =C12-C11*ROOT(1/(6-3)) |
| 7 | Anggaran selang kanan untuk z | =C12+C11*ROOT(1/(6-3)) |
| 8 | Anggaran selang kiri untuk rxy | =FISHEROBR(C13) |
| 9 | Anggaran selang kanan untuk rxy | =FISHEROBR(C14) |
| 10 | Sisihan piawai untuk rxy | =ROOT((1-C8^2)/4) |
Oleh itu, dengan kebarangkalian 0.95, pekali korelasi linear terletak dalam julat dari (–0.386) hingga (–0.990) dengan ralat piawai 0.205.
Menyemak kepentingan statistik regresi menggunakan fungsi FASTER
Contoh 2: Uji kepentingan statistik persamaan regresi berganda Menggunakan ujian F Fisher, buat kesimpulan.
Untuk menyemak kepentingan persamaan secara keseluruhan, kami mengemukakan hipotesis H 0 tentang ketidaksignifikan statistik bagi pekali penentuan dan hipotesis bertentangan H 1 tentang kepentingan statistik pekali penentuan:
H 1: R 2 ≠ 0.
Mari kita uji hipotesis menggunakan ujian F Fisher. Penunjuk ditunjukkan dalam Jadual 2.
Jadual 2 - Data awal
Untuk melakukan ini, kami menggunakan fungsi dalam Excel:
LEBIH CEPAT (α;p;n-p-1)
- α ialah kebarangkalian yang dikaitkan dengan taburan tertentu;
- p dan n ialah pengangka dan penyebut darjah kebebasan, masing-masing.
Mengetahui bahawa α = 0.05, p = 2 dan n = 53, kami memperoleh nilai berikut untuk kritikan F (lihat Rajah 2).
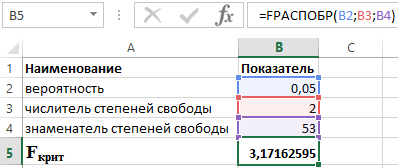
Rajah 2 – Contoh pengiraan.
Oleh itu kita boleh mengatakan bahawa F dikira > F kritikal. Hasilnya, hipotesis H 1 tentang kepentingan statistik bagi pekali penentuan diterima.
Mengira nilai penunjuk korelasi dalam Excel
Contoh 3. Menggunakan data daripada 23 perusahaan tentang: X ialah harga produk A, ribu rubel; Y ialah keuntungan perusahaan perdagangan, pergantungan mereka sedang dikaji. Gred model regresi memberikan yang berikut: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. Apakah penunjuk korelasi yang boleh ditentukan daripada data ini? Kira nilai penunjuk korelasi dan, menggunakan kriteria Fisher, buat kesimpulan tentang kualiti model regresi.
Mari kita tentukan kritikan F daripada ungkapan:
F dikira = R 2 /23*(1-R 2)
di mana R ialah pekali penentuan bersamaan dengan 0.67.
Oleh itu, nilai pengiraan F calc = 46.
Untuk menentukan kritikan F kami menggunakan taburan Fisher (lihat Rajah 3).

Rajah 3 – Contoh pengiraan.
Oleh itu, anggaran yang terhasil bagi persamaan regresi adalah boleh dipercayai.
Kepentingan persamaan regresi berganda secara keseluruhan, serta dalam regresi berpasangan, dinilai menggunakan kriteria Fisher:
 ,
(2.22)
,
(2.22)
di mana  – jumlah faktor kuasa dua bagi setiap darjah kebebasan;
– jumlah faktor kuasa dua bagi setiap darjah kebebasan;  – jumlah baki kuasa dua bagi setiap darjah kebebasan;
– jumlah baki kuasa dua bagi setiap darjah kebebasan;  – pekali (indeks) penentuan berbilang;
– pekali (indeks) penentuan berbilang;  – bilangan parameter untuk pembolehubah
– bilangan parameter untuk pembolehubah  (V regresi linear bertepatan dengan bilangan faktor yang termasuk dalam model);
(V regresi linear bertepatan dengan bilangan faktor yang termasuk dalam model);  – bilangan pemerhatian.
– bilangan pemerhatian.
Kepentingan bukan sahaja persamaan secara keseluruhan dinilai, tetapi juga faktor tambahan yang dimasukkan dalam model regresi. Keperluan untuk penilaian sedemikian adalah disebabkan oleh fakta bahawa tidak setiap faktor yang termasuk dalam model boleh meningkatkan dengan ketara bahagian variasi yang dijelaskan dalam sifat yang terhasil. Di samping itu, jika terdapat beberapa faktor dalam model, ia boleh dimasukkan ke dalam model dalam urutan yang berbeza. Disebabkan oleh korelasi antara faktor, kepentingan faktor yang sama boleh berbeza bergantung pada urutan pengenalannya ke dalam model. Ukuran untuk menilai kemasukan faktor dalam model adalah peribadi  -kriteria, i.e.
-kriteria, i.e.  .
.
Persendirian  -kriteria adalah berdasarkan membandingkan peningkatan dalam varians faktor disebabkan oleh pengaruh faktor tambahan yang disertakan dengan varians baki setiap satu darjah kebebasan untuk model regresi secara keseluruhan. DALAM Pandangan umum untuk faktor
-kriteria adalah berdasarkan membandingkan peningkatan dalam varians faktor disebabkan oleh pengaruh faktor tambahan yang disertakan dengan varians baki setiap satu darjah kebebasan untuk model regresi secara keseluruhan. DALAM Pandangan umum untuk faktor  persendirian
persendirian  -kriteria akan ditentukan sebagai
-kriteria akan ditentukan sebagai
 ,
(2.23)
,
(2.23)
di mana  – pekali penentuan berbilang untuk model dengan set lengkap faktor,
– pekali penentuan berbilang untuk model dengan set lengkap faktor,  – penunjuk yang sama, tetapi tanpa memasukkan faktor dalam model
– penunjuk yang sama, tetapi tanpa memasukkan faktor dalam model  ,
, - bilangan pemerhatian,
- bilangan pemerhatian,  – bilangan parameter dalam model (tanpa jangka masa bebas).
– bilangan parameter dalam model (tanpa jangka masa bebas).
Nilai sebenar bagi hasil  - kriteria dibandingkan dengan jadual pada tahap keertian
- kriteria dibandingkan dengan jadual pada tahap keertian  dan bilangan darjah kebebasan: 1 dan
dan bilangan darjah kebebasan: 1 dan  . Jika nilai sebenar
. Jika nilai sebenar  melebihi
melebihi  , maka kemasukan tambahan faktor
, maka kemasukan tambahan faktor  ke dalam model adalah wajar secara statistik dan pekali regresi tulen
ke dalam model adalah wajar secara statistik dan pekali regresi tulen  pada faktor
pada faktor  statistik yang signifikan. Jika nilai sebenar
statistik yang signifikan. Jika nilai sebenar  adalah kurang daripada nilai jadual, maka kemasukan tambahan faktor dalam model
adalah kurang daripada nilai jadual, maka kemasukan tambahan faktor dalam model  tidak meningkatkan dengan ketara bahagian variasi yang dijelaskan dalam sesuatu sifat
tidak meningkatkan dengan ketara bahagian variasi yang dijelaskan dalam sesuatu sifat  , oleh itu, adalah tidak sesuai untuk memasukkannya ke dalam model; Pekali regresi untuk faktor ini dalam kes ini adalah tidak signifikan secara statistik.
, oleh itu, adalah tidak sesuai untuk memasukkannya ke dalam model; Pekali regresi untuk faktor ini dalam kes ini adalah tidak signifikan secara statistik.
Untuk persamaan dua faktor, hasil bagi  -kriteria mempunyai bentuk:
-kriteria mempunyai bentuk:
 ,
, . (2.23a)
. (2.23a)
Menggunakan persendirian  -kriteria, seseorang boleh menyemak kepentingan semua pekali regresi di bawah andaian bahawa setiap faktor yang sepadan
-kriteria, seseorang boleh menyemak kepentingan semua pekali regresi di bawah andaian bahawa setiap faktor yang sepadan  dimasukkan ke dalam persamaan regresi berganda yang terakhir.
dimasukkan ke dalam persamaan regresi berganda yang terakhir.
-Ujian pelajar untuk persamaan regresi berganda.
Persendirian  -kriteria menilai kepentingan pekali regresi tulen. Mengetahui magnitud
-kriteria menilai kepentingan pekali regresi tulen. Mengetahui magnitud  , adalah mungkin untuk menentukan
, adalah mungkin untuk menentukan  -kriteria untuk pekali regresi pada
-kriteria untuk pekali regresi pada  -m faktor,
-m faktor,  , iaitu:
, iaitu:
 .
(2.24)
.
(2.24)
Menilai kepentingan pekali regresi tulen dengan  -Ujian-t pelajar boleh dijalankan tanpa mengira separa
-Ujian-t pelajar boleh dijalankan tanpa mengira separa  -kriteria. Dalam kes ini, seperti dalam regresi berpasangan, formula digunakan untuk setiap faktor:
-kriteria. Dalam kes ini, seperti dalam regresi berpasangan, formula digunakan untuk setiap faktor:
 ,
(2.25)
,
(2.25)
di mana  – pekali regresi tulen pada faktor
– pekali regresi tulen pada faktor  ,
, – min ralat segi empat sama (standard) bagi pekali regresi
– min ralat segi empat sama (standard) bagi pekali regresi  .
.
Untuk persamaan regresi berbilang, ralat kuasa dua purata bagi pekali regresi boleh ditentukan dengan formula berikut:
 ,
(2.26)
,
(2.26)
di mana 
 ,
, – sisihan piawai untuk ciri
– sisihan piawai untuk ciri  ,
, – pekali penentuan untuk persamaan regresi berganda,
– pekali penentuan untuk persamaan regresi berganda,  – pekali penentuan untuk pergantungan faktor
– pekali penentuan untuk pergantungan faktor  dengan semua faktor lain dalam persamaan regresi berganda;
dengan semua faktor lain dalam persamaan regresi berganda;  – bilangan darjah kebebasan untuk jumlah baki sisihan kuasa dua.
– bilangan darjah kebebasan untuk jumlah baki sisihan kuasa dua.
Seperti yang anda lihat, untuk menggunakan formula ini, anda memerlukan matriks korelasi antara faktor dan pengiraan pekali penentuan yang sepadan menggunakannya  . Jadi, untuk persamaan
. Jadi, untuk persamaan  penilaian kepentingan pekali regresi
penilaian kepentingan pekali regresi  ,
, ,
, melibatkan pengiraan tiga pekali penentuan antara faktor:
melibatkan pengiraan tiga pekali penentuan antara faktor:  ,
, ,
, .
.
Hubungan antara penunjuk pekali korelasi separa, separa  -kriteria dan
-kriteria dan  -Ujian-t pelajar untuk pekali regresi tulen boleh digunakan dalam prosedur pemilihan faktor. Penghapusan faktor semasa membina persamaan regresi dengan kaedah penyingkiran boleh praktikal dilakukan bukan sahaja oleh pekali korelasi separa, tidak termasuk pada setiap langkah faktor dengan nilai pekali korelasi separa yang paling kecil tidak penting, tetapi juga dengan nilai.
-Ujian-t pelajar untuk pekali regresi tulen boleh digunakan dalam prosedur pemilihan faktor. Penghapusan faktor semasa membina persamaan regresi dengan kaedah penyingkiran boleh praktikal dilakukan bukan sahaja oleh pekali korelasi separa, tidak termasuk pada setiap langkah faktor dengan nilai pekali korelasi separa yang paling kecil tidak penting, tetapi juga dengan nilai.  Dan
Dan  .
Persendirian
.
Persendirian  -kriteria digunakan secara meluas semasa membina model menggunakan kaedah kemasukan pembolehubah dan kaedah regresi berperingkat.
-kriteria digunakan secara meluas semasa membina model menggunakan kaedah kemasukan pembolehubah dan kaedah regresi berperingkat.







