Як приклад безперервної випадкової величинирозглянемо випадкову величину X, рівномірно розподілену на інтервалі (a; b). Говорять, що випадкова величина X рівномірно розподілено на проміжку (a; b), якщо її щільність розподілу непостійна на цьому проміжку:
З умови нормування визначимо значення константи c. Площа під кривою щільності розподілу повинна дорівнювати одиниці, але в нашому випадку - це площа прямокутника з основою (b - α) і висотою c (рис. 1). 
Мал. 1 Щільність рівномірного розподілу
Звідси знаходимо значення постійної з: ![]()
Отже, щільність рівномірно розподіленої випадкової величини дорівнює 
Знайдемо тепер функцію розподілу за такою формулою:
1) для ![]()
2) для
3) для 0+1+0=1.
Таким чином, 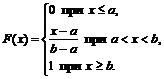
Функція розподілу безперервна і зменшується (рис. 2). 
Мал. 2 Функція розподілу рівномірно розподіленої випадкової величини
Знайдемо математичне очікуваннярівномірно розподіленої випадкової величиниза формулою:
Дисперсія рівномірного розподілурозраховується за формулою і дорівнює
Приклад №1. Ціна поділу шкали вимірювального приладу дорівнює 0.2. Показання приладу округляють до найближчого поділу. Знайти ймовірність того, що при відліку буде зроблено помилку: а) менша 0.04; б) велика 0.02
Рішення. Помилка округлення є випадковою величиною, рівномірно розподіленою на проміжку між сусідніми цілими поділами. Розглянемо як такий поділ інтервал (0; 0,2) (рис. а). Округлення може проводитися як у бік лівої межі - 0, так і в бік правої - 0,2, отже, помилка, менша або рівна 0,04, може бути зроблена двічі, що необхідно врахувати при підрахунку ймовірності: 

P = 0,2 + 0,2 = 0,4
Для другого випадку величина помилки може перевищувати 0,02 також з обох меж поділу, тобто вона може бути більшою за 0,02, або меншою за 0,18. 
Тоді ймовірність появи такої помилки:
Приклад №2. Передбачалося, що про стабільність економічної обстановки в країні (відсутність воєн, стихійних лих тощо) за останні 50 років можна судити за характером розподілу населення за віком: при спокійній обстановці воно має бути рівномірним. В результаті проведеного дослідження для однієї з країн були отримані такі дані.
Чи є підстави вважати, що у країні була нестабільна обстановка?Рішення проводимо за допомогою калькулятора Перевірка гіпотез. Таблиця до розрахунку показників.
| Групи | Середина інтервалу, x i | Кількість, f i | x i * f i | Накопичена частота, S | | x - x ср | * f | (x - x ср) 2 * f | Частота, f i /n |
| 0 - 10 | 5 | 0.14 | 0.7 | 0.14 | 5.32 | 202.16 | 0.14 |
| 10 - 20 | 15 | 0.09 | 1.35 | 0.23 | 2.52 | 70.56 | 0.09 |
| 20 - 30 | 25 | 0.1 | 2.5 | 0.33 | 1.8 | 32.4 | 0.1 |
| 30 - 40 | 35 | 0.08 | 2.8 | 0.41 | 0.64 | 5.12 | 0.08 |
| 40 - 50 | 45 | 0.16 | 7.2 | 0.57 | 0.32 | 0.64 | 0.16 |
| 50 - 60 | 55 | 0.13 | 7.15 | 0.7 | 1.56 | 18.72 | 0.13 |
| 60 - 70 | 65 | 0.12 | 7.8 | 0.82 | 2.64 | 58.08 | 0.12 |
| 70 - 80 | 75 | 0.18 | 13.5 | 1 | 5.76 | 184.32 | 0.18 |
| 1 | 43 | 20.56 | 572 | 1 |
Середня виважена
Показники варіації.
Абсолютні показники варіації.
Розмах варіації - різниця між максимальним та мінімальним значеннями ознаки первинного ряду.
R = X max - X min
R = 70 - 0 = 70
Дисперсія- характеризує міру розкиду біля її середнього значення (заходи розсіювання, тобто відхилення від середнього).
Середнє квадратичне відхилення.
Кожне значення ряду відрізняється від середнього значення 43 трохи більше, ніж 23.92
Перевірка гіпотез про вид розподілу.
4. Перевірка гіпотези про рівномірному розподілігенеральної сукупності.
Щоб перевірити гіпотезу про рівномірному розподілі X, тобто. згідно із законом: f(x) = 1/(b-a) в інтервалі (a,b)
треба:
1. Оцінити параметри a та b - кінці інтервалу, в якому спостерігалися можливі значення X, за формулами (через знак * позначені оцінки параметрів):
2. Знайти густину ймовірності передбачуваного розподілу f(x) = 1/(b * - a *)
3. Знайти теоретичні частоти:
n 1 = nP 1 = n = n*1/(b * - a *)*(x 1 - a *)
n 2 = n 3 = ... = n s-1 = n*1/(b * - a *)*(xi - x i-1)
n s = n*1/(b * - a *)*(b * - x s-1)
4. Порівняти емпіричні та теоретичні частоти за допомогою критерію Пірсона, прийнявши число ступенів свободи k = s-3, де s – число початкових інтервалів вибірки; якщо ж було здійснено об'єднання нечисленних частот, отже, і самих інтервалів, то s - кількість інтервалів, що залишилися після об'єднання.
Рішення:
1. Знайдемо оцінки параметрів a* та b* рівномірного розподілу за формулами:
2. Знайдемо щільність передбачуваного рівномірного розподілу:
f(x) = 1/(b * - a *) = 1/(84.42 - 1.58) = 0.0121
3. Знайдемо теоретичні частоти:
n 1 = n * f (x) (x 1 - a *) = 1 * 0.0121 (10-1.58) = 0.1
n 8 = n * f (x) (b * - x 7) = 1 * 0.0121 (84.42-70) = 0.17
Інші n s дорівнюватимуть:
n s = n * f (x) (xi - xi-1)
| i | n i | n*i | n i - n * i | (n i - n * i) 2 | (n i - n * i) 2 / n * i |
| 1 | 0.14 | 0.1 | 0.0383 | 0.00147 | 0.0144 |
| 2 | 0.09 | 0.12 | -0.0307 | 0.000943 | 0.00781 |
| 3 | 0.1 | 0.12 | -0.0207 | 0.000429 | 0.00355 |
| 4 | 0.08 | 0.12 | -0.0407 | 0.00166 | 0.0137 |
| 5 | 0.16 | 0.12 | 0.0393 | 0.00154 | 0.0128 |
| 6 | 0.13 | 0.12 | 0.0093 | 8.6E-5 | 0.000716 |
| 7 | 0.12 | 0.12 | -0.000701 | 0 | 4.0E-6 |
| 8 | 0.18 | 0.17 | 0.00589 | 3.5E-5 | 0.000199 |
| Разом | 1 | 0.0532 |
Тому критична область для цієї статистики завжди правостороння: якщо щільність її ймовірності постійна на цьому відрізку, а поза його дорівнює 0 (тобто випадкова величина Хзосереджена на відрізку [ a, b], у якому має постійну щільність). за даному визначеннющільність рівномірно розподіленої на відрізку [ a, b] випадкової величини Хмає вигляд:
де зє кілька. Втім, його легко знайти, використовуючи властивість густини ймовірності для с.в., зосереджених на відрізку [ a,
b]:
 . Звідси слідує що
. Звідси слідує що  , звідки
, звідки  . Тому щільність рівномірно розподіленої на відрізку [ a,
b] випадкової величини Хмає вигляд:
. Тому щільність рівномірно розподіленої на відрізку [ a,
b] випадкової величини Хмає вигляд:
 .
.
Судити про рівномірність розподілу н.с. Хможна з наступного міркування. Безперервна випадкова величина має рівномірний розподілна відрізку [ a, b], якщо вона набуває значення тільки з цього відрізка, і будь-яке число з цього відрізка не має переваги над іншими числами цього відрізка в сенсі можливості бути значенням цієї випадкової величини.
До випадкових величин, що мають рівномірний розподіл належать такі величини, як час очікування транспорту на зупинці (при постійному інтервалі руху тривалість очікування рівномірно розподілена на цьому інтервалі), помилка округлення числа до цілого (рівномірно розподілена на [−0.5 , 0.5 ]) та інші.
Вид функції розподілу F(x)
a,
b] випадкової величини Хшукається за відомою щільністю імовірності f(x)
за допомогою формули їх зв'язку  . В результаті відповідних обчислень отримуємо таку формулу для функції розподілу F(x)
рівномірно розподіленому відрізку [ a,
b] випадкової величини Х
:
. В результаті відповідних обчислень отримуємо таку формулу для функції розподілу F(x)
рівномірно розподіленому відрізку [ a,
b] випадкової величини Х
:
 .
.
На рисунках наведено графіки щільності ймовірності f(x) та функції розподілу f(x) рівномірно розподіленому відрізку [ a, b] випадкової величини Х :


Математичне очікування, дисперсія, середнє квадратичне відхилення, мода та медіана рівномірно розподіленому відрізку [ a, b] випадкової величини Хобчислюються за щільністю ймовірності f(x) звичайним чином (і досить просто через простого вигляду f(x) ). В результаті виходять такі формули:
а модою d(X) є будь-яке число відрізка [ a, b].
Знайдемо ймовірність попадання рівномірно розподіленого відрізка [ a,
b] випадкової величини Хв інтервал  , що повністю лежить всередині [ a,
b]. Враховуючи відомий вид функції розподілу, отримуємо:
, що повністю лежить всередині [ a,
b]. Враховуючи відомий вид функції розподілу, отримуємо:
Таким чином, ймовірність попадання рівномірно розподіленого відрізка [ a,
b] випадкової величини Хв інтервал  , що повністю лежить всередині [ a,
b], не залежить від положення цього інтервалу, а залежить тільки від його довжини і прямо пропорційна цій довжині.
, що повністю лежить всередині [ a,
b], не залежить від положення цього інтервалу, а залежить тільки від його довжини і прямо пропорційна цій довжині.
приклад. Інтервал руху автобуса складає 10 хвилин. Яка ймовірність того, що пасажир, який підійшов до зупинки, чекає на автобус менше 3 хвилин? Яким є середній час очікування автобуса?
Нормальний розподіл
Цей розподіл найчастіше зустрічається практично і грає виняткову роль теорії ймовірностей і математичної статистики та його додатках, оскільки такий розподіл мають дуже багато випадкові величини в природознавстві, економіці, психології, соціології, військових науках тощо. Цей розподіл є граничним законом, до якого наближаються (за певних природних умов) багато інших законів розподілу. За допомогою нормального закону розподілу описуються також явища, схильні до дії багатьох незалежних випадкових факторів будь-якої природи та будь-якого закону їх розподілу. Перейдемо до визначень.
Безперервна випадкова величина називається розподіленою за нормальному закону (або закону Гауса), якщо її щільність ймовірності має вигляд:
 ,
,
де числа аі σ (σ>0 ) є параметрами цього розподілу.
Як було зазначено, закон Гаусса розподілу випадкових величин має численні докладання. За цим законом розподілені помилки вимірювань приладами, відхилення від центру мішені при стрільбі, розміри виготовлених деталей, вага та зростання людей, річна кількість опадів, кількість новонароджених та багато іншого.
Наведена формула щільності ймовірності нормально розподіленої випадкової величини містить, як було сказано, два параметри аі σ , тому задає сімейство функцій, змінюються залежно від значень цих параметрів. Якщо застосувати звичайні методи математичного аналізу дослідження функцій та побудови графіків до щільності ймовірності нормального розподілу, можна зробити такі выводы.

є точками його перегину.
Виходячи з отриманої інформації, будуємо графік густини ймовірності f(x) нормального розподілу (він називається кривою Гауса - рисунок).

З'ясуємо, як впливає зміна параметрів аі σ на форму кривої Гауса. Очевидно (це видно з формули для щільності нормального розподілу), що зміна параметра ане змінює форму кривої, а призводить лише до її зсуву вправо чи вліво вздовж осі х. Залежність від σ складніше. З проведеного вище дослідження видно, як залежить величина максимуму та координати точок перегину від параметра σ . До того ж треба врахувати, що за будь-яких параметрів аі σ площа під кривою Гауса залишається рівною 1 (це загальна властивість щільності ймовірності). Зі сказаного випливає, що зі зростанням параметра σ крива стає більш пологою і витягується вздовж осі х. На малюнку зображені криві Гауса при різних значеннях параметра σ (σ 1 < σ< σ 2 ) і тому самому значенні параметра а.

З'ясуємо імовірнісний зміст параметрів аі σ
нормального розподілу. Вже із симетричності кривої Гауса щодо вертикальної прямої, що проходить через число ана осі хзрозуміло, що середнє значення (тобто математичне очікування М(Х)) нормально розподіленої випадкової величини одно а. З цих міркувань мода і медіана теж повинні дорівнювати числу а. Точні розрахунки за відповідними формулами це підтверджують. Якщо ж ми виписане вище вираз для f(x)
підставимо у формулу для дисперсії  , то після (досить непростого) обчислення інтеграла отримаємо у відповіді число σ
2
. Таким чином, для випадкової величини Х, розподіленою за нормальним законом, вийшли такі основні її числові характеристики:
, то після (досить непростого) обчислення інтеграла отримаємо у відповіді число σ
2
. Таким чином, для випадкової величини Х, розподіленою за нормальним законом, вийшли такі основні її числові характеристики:
Тому ймовірнісний зміст параметрів нормального розподілу аі σ наступний. Якщо с.в. Хаі σ а σ.
Знайдемо тепер функцію розподілу F(x)
для випадкової величини Х, розподіленої за нормальним законом, використовуючи виписаний вище вираз для щільності ймовірності f(x)
та формулу  . При підстановці f(x)
виходить «небереться» інтеграл. Все, що вдається зробити для спрощення виразу F(x),
це подання цієї функції у вигляді:
. При підстановці f(x)
виходить «небереться» інтеграл. Все, що вдається зробити для спрощення виразу F(x),
це подання цієї функції у вигляді:
 ,
,
де Ф(х)− так звана функція Лапласа, яка має вигляд
 .
.
Інтеграл, через який виражається функція Лапласа, теж є такими, що не беруться (але при кожному хцей інтеграл може бути обчислений приблизно з будь-якою заданою точністю). Однак обчислювати його і не потрібно, тому що наприкінці будь-якого підручника з теорії ймовірностей є таблиця для визначення значень функції Ф(х)при заданому значенні х. Надалі нам знадобиться властивість непарності функції Лапласа: Ф(-х)=−Ф(х)для всіх чисел х.
Знайдемо тепер можливість, що нормально розподілена с.в. Хприйме значення із заданого числового інтервалу (α, β) . Із загальних властивостей функції розподілу Р(α< X< β)= F(β) − F(α) . Підставляючи α і β у виписане вище вираз для F(x) , отримаємо
 .
.
Як зазначено вище, якщо с.в. Хрозподілено нормально з параметрами аі σ , то її середнє значення дорівнює а, а середнє квадратичне відхилення одно σ. Тому середнявідхилення значень цієї с.в. при випробуванні від числа аодно σ. Але це середнє відхилення. Тому можливі і великі відхилення. Дізнаємось, наскільки можливі ті чи інші відхилення від середнього значення. Знайдемо ймовірність того, що значення розподіленої за нормальним законом випадкової величини Хвідхилитися від її середнього значення М(Х)=аменше, ніж деяке число δ, тобто. Р(| X− a|<δ ): . Таким чином,
 .
.
Підставляючи в цю рівність δ=3σ, Отримаємо ймовірність того, що значення с.в. Х(при одному випробуванні) відхилиться від середнього значення менш ніж на потрійне значення σ (при середньому відхиленні, як ми пам'ятаємо, рівному σ ): (значення Ф(3)взято із таблиці значень функції Лапласа). Це майже 1 ! Тоді ймовірність протилежної події (що значення відхилиться не менше, ніж на 3σ) дорівнює 1 −0.997=0.003 , що дуже близько до 0 . Тому ця подія «майже неможливо» − трапляється вкрай рідко (у середньому 3 рази з 1000 ). Ця міркування є обґрунтуванням широко відомого «правила трьох сигм».
Правило трьох сигм. Нормально розподілена випадкова величина при одиничному випробуванніпрактично не відхиляється від свого середнього далі, ніж на 3σ.
Ще раз наголосимо, що йдеться про одне випробування. Якщо випробувань випадкової величини багато, то цілком можливо, що якесь її значення і відійде від середнього далі, ніж 3σ. Це підтверджує наступний
приклад. Яка ймовірність, що при 100 випробуваннях нормально розподіленої випадкової величини Ххоча б одне її значення відхилиться від середнього більш ніж на потрійне середнє квадратичне відхилення? А за 1000 випробувань?
Рішення. Нехай подія Аозначає, що при випробуванні випадкової величини Хїї значення відхилилося від середнього більш ніж на 3σ.Як тільки що було з'ясовано, ймовірність цієї події р = Р (А) = 0.003.Проведено 100 таких випробувань. Потрібно дізнатися ймовірність того, що подія Авідбулося хоча бразів, тобто. сталося від 1 до 100 разів. Це типова задача схеми Бернуллі з параметрами n=100 (кількість незалежних випробувань), р = 0.003(ймовірність події Ав одному випробуванні), q=1− p=0.997 . Потрібно знайти Р 100 (1≤ k≤100) . У даному випадку, звичайно, простіше знайти спочатку ймовірність протилежної події Р 100 (0) − ймовірність того, що подія Ане відбулося жодного разу (тобто відбулося 0 разів). Враховуючи зв'язок ймовірностей самої події та йому протилежної, отримаємо:
Не так уже й мало. Цілком може статися (відбувається в середньому у кожній четвертій такій серії випробувань). При 1000 випробувань за такою ж схемою можна отримати, що ймовірність хоча б одного відхилення далі, ніж на 3σ, Так само: . Тож можна з великою впевненістю дочекатися бодай одного такого відхилення.
приклад. Зростання чоловіків певної вікової групи розподілено нормально з математичним очікуванням a, та середньоквадратичним відхиленням σ . Яку частку костюмів k-го зростання слід передбачити у загальному обсязі виробництва для цієї вікової групи, якщо k-е зростання визначається такими межами:
1 зріст : 158 − 164см 2зріст : 164 − 170см 3зріст : 170 − 176см 4зріст : 176 − 182см
Рішення. Розв'яжемо задачу при наступних значеннях параметрів: а = 178,σ=6,k=3
. Нехай с.в. Х
−
зростання випадково обраного чоловіка (вона розподілена за умовою нормально із заданими параметрами). Знайдемо ймовірність того, що навмання обраному чоловікові знадобиться 3
-е зростання. Користуючись непарністю функції Лапласа Ф(х)та таблицею її значень: P(170)
Це питання вже давно докладно вивчено, і найбільшого поширення набув метод полярних координат, запропонований Джорджем Боксом, Мервіном Мюллером і Джорджем Марсальєю в 1958 році. Даний метод дозволяє отримати пару незалежних нормально розподілених випадкових величин з математичним очікуванням 0 та дисперсією 1 наступним чином:
Де Z 0 і Z 1 - значення, що шукаються, s = u 2 + v 2 , а u і v - рівномірно розподілені на відрізку (-1, 1) випадкові величини, підібрані таким чином, щоб виконувалася умова 0< s < 1.
Багато хто використовують ці формули, навіть не замислюючись, а багато хто навіть і не підозрює про їхнє існування, оскільки користується готовими реалізаціями. Але є люди, які мають запитання: «Звідки взялася ця формула? І чому виходить відразу пара величин?». Далі я намагатимусь дати наочну відповідь на ці запитання.
Спочатку нагадаю, що таке щільність ймовірності, функція розподілу випадкової величини і зворотна функція. Припустимо, є якась випадкова величина, розподіл якої заданий функцією щільності f(x), що має такий вигляд:

Це означає, що ймовірність того, що значення даної випадкової величини опиниться в інтервалі (A, B), дорівнює площі затіненої області. І як наслідок, площа всієї зафарбованої області повинна дорівнювати одиниці, так як у будь-якому випадку значення випадкової величини потрапить до області визначення функції f.
Функція розподілу випадкової величини є інтегралом функції щільності. І в даному випадку її зразковий вигляд буде таким:

Тут сенс у цьому, що значення випадкової величини буде менше ніж A з ймовірністю B. І, як наслідок, функція будь-коли зменшується, та її значення лежать у відрізку .
Зворотна функція - це функція, яка повертає аргумент вихідної функції, якщо передати значення вихідної функції. Наприклад, для функції x 2 зворотної буде функція вилучення кореня, для sin(x) arcsin(x) і т.д.
Так як більшість генераторів псевдовипадкових чисел на виході дають лише рівномірний розподіл, часто виникає необхідність його перетворення в яке-небудь інше. У даному випадку в нормальне Гаусівське:

Основу всіх методів перетворення рівномірного розподілу на будь-яке інше становить метод зворотного перетворення. Працює він в такий спосіб. Знаходиться функція, зворотна функції необхідного розподілу, і як аргумент передається до неї рівномірно розподілена на відрізку (0, 1) випадкова величина. На виході отримуємо величину з необхідним розподілом. Для наочності наводжу таку картинку.

Таким чином, рівномірний відрізок як би розмазується відповідно до нового розподілу, проецируясь на іншу вісь через зворотну функцію. Але проблема в тому, що інтеграл від щільності Гаусівського розподілу обчислюється непросто, тому переліченим вище вченим довелося схитрувати.
Існує розподіл хі-квадрат (розподіл Пірсона), який є розподілом суми квадратів k незалежних нормальних випадкових величин. І якщо k = 2, цей розподіл є експоненціальним.

Це означає, що якщо точки в прямокутній системі координат будуть випадкові координати X і Y, розподілені нормально, то після переведення цих координат в полярну систему (r, θ) квадрат радіуса (відстань від початку координат до точки) буде розподілений за експоненційним законом, так як квадрат радіуса - це сума квадратів координат (за законом Піфагора). Щільність розподілу таких точок на площині виглядатиме так:


Оскільки вона рівноцінна у всіх напрямках, кут θ матиме рівномірний розподіл у діапазоні від 0 до 2π. Справедливо і зворотне: якщо задати точку в полярній системі координат за допомогою двох незалежних випадкових величин (кута, розподіленого рівномірно, і радіуса, розподіленого експоненційно), то прямокутні координати цієї точки будуть незалежними нормальними випадковими величинами. А експоненційний розподіл з рівномірного одержати вже набагато простіше, за допомогою того ж методу зворотного перетворення. У цьому полягає суть полярного методу Бокса-Мюллера.
Тепер виведемо формули.
![]() (1)
(1)
Для отримання r і θ потрібно згенерувати дві рівномірно розподілені на відрізку (0, 1) випадкові величини (назвемо їх u і v), розподіл однієї з яких (допустимо v) необхідно перетворити на експоненційне для отримання радіусу. Функція експоненційного розподілу виглядає так:
Зворотня до неї функція:
![]()
Так як рівномірний розподіл симетрично, то аналогічно перетворення працюватиме і з функцією
![]()
З формули розподілу хі-квадрат випливає, що = 0,5. Підставимо в цю функцію λ, v і отримаємо квадрат радіусу, а потім і сам радіус:

Кут отримаємо, розтягнувши одиничний відрізок до 2π:
Тепер підставимо r і θ формули (1) і отримаємо:
 (2)
(2)
Ці формули готові до використання. X і Y будуть незалежні та розподілені нормально з дисперсією 1 та математичним очікуванням 0. Щоб отримати розподіл з іншими характеристиками достатньо помножити результат функції на середньоквадратичне відхилення та додати математичне очікування.
Але є можливість позбутися тригонометричних функцій, поставивши кут не прямо, а побічно через прямокутні координати випадкової точки в колі. Тоді через ці координати можна буде обчислити довжину радіус-вектора, а потім знайти косинус та синус, поділивши на неї x та y відповідно. Як і чому це працює?
Виберемо випадкову точку з рівномірно розподілених у колі одиничного радіусу та позначимо квадрат довжини радіус-вектора цієї точки буквою s:

Вибір здійснюється завданням випадкових прямокутних координат x і y, рівномірно розподілених в інтервалі (-1, 1), та відкиданням точок, що не належать колу, а також центральної точки, в якій кут радіус-вектора не визначений. Тобто має виконатися умова 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Отримуємо формули, як на початку статті. Недолік цього - відкидання точок, які увійшли до кола. Тобто використання лише 78,5% згенерованих випадкових величин. На старих комп'ютерах відсутність тригонометричних функцій все одно давала велику перевагу. Зараз, коли одна команда процесора за мить обчислює одночасно синус і косинус, гадаю, ці методи можуть ще позмагатися.
Особисто у мене залишається ще два питання:
- Чому значення s розподілене рівномірно?
- Чому суму квадратів двох нормальних випадкових величин розподілено експоненційно?

Якщо аналогічне перетворення зробити для нормальної випадкової величини, то функція щільності її квадрата виявиться схожою гіперболу. А додавання двох квадратів нормальних випадкових величин вже набагато складніший процес, пов'язаний із подвійним інтегруванням. І те, що в результаті вийде експоненційний розподіл, особисто мені залишається перевірити практичним методом або прийняти як аксіому. А комусь цікаво, пропоную ознайомитися з темою ближче, почерпнувши знань із цих книжок:
- Вентцель Є.С. Теорія імовірності
- Батіг Д.Е. Мистецтво Програмування, том 2
На закінчення наведу приклад реалізації генератора нормально розподілених випадкових чисел мовою JavaScript:
Function Gauss() ( var ready = false; var second = 0.0; this.next = function(mean, dev) ( mean = mean == undefined ? 0.0: mean; dev = dev == undefined ? 1.0: dev; the. mean; ) else (var u, v, s; do (u = 2.0 * Math.random() - 1.0; v = 2.0 * Math.random() - 1.0; s = u * u + v * v; ) log (s > 1.0 || s == 0.0); );this.second = r * u;this.ready = true; return r * v * dev + mean; ) ); // Створюємо об'єкт a = g.next(); // генеруємо пару значень і отримуємо перше їх b = g.next(); // Отримуємо друге c = g.next (); // Знову генеруємо пару значень і отримуємо перше з них
Параметри mean (математичне очікування) та dev (середньоквадратичне відхилення) не є обов'язковими. Звертаю вашу увагу на те, що логарифм є натуральним.







