Fisher criterion allows you to compare the sample variances of two independent samples. To calculate F emp, you need to find the ratio of the variances of two samples, so that the larger variance is in the numerator, and the smaller one is in the denominator. The formula for calculating the Fisher criterion is:
where are the variances of the first and second samples, respectively.
Since, according to the conditions of the criterion, the value of the numerator must be greater than or equal to the value of the denominator, the value of F emp will always be greater than or equal to one.
The number of degrees of freedom is also determined simply:
k 1 =n l - 1 for the first sample (i.e. for the sample whose variance is larger) and k 2 = n 2 - 1 for the second sample.
In Appendix 1, the critical values of the Fisher criterion are found by the values of k 1 (top line of the table) and k 2 (left column of the table).
If t em >t crit, then the null hypothesis is accepted, otherwise the alternative is accepted.
Example 3. Testing was carried out in two third grades mental development ten students on the TURMSH test. The obtained average values did not differ significantly, but the psychologist is interested in the question of whether there are differences in the degree of homogeneity of mental development indicators between classes.
Solution. For Fisher's test, it is necessary to compare the variances of test scores in both classes. The test results are presented in the table:
Table 3.
|
Student nos. |
First grade |
Second class |
Having calculated the variances for variables X and Y, we obtain:
s x 2 =572.83; s y 2 =174,04
Then, using formula (8) for calculation using Fisher’s F criterion, we find:
![]()
According to the table from Appendix 1 for the F criterion with degrees of freedom in both cases equal to k = 10 - 1 = 9, we find F crit = 3.18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Nonparametric tests
By comparing by eye (by percentage) the results before and after any impact, the researcher comes to the conclusion that if differences are observed, then there is a difference in the samples being compared. This approach is categorically unacceptable, since for percentages it is impossible to determine the level of reliability in the differences. Percentages taken by themselves do not make it possible to draw statistically reliable conclusions. To prove the effectiveness of any intervention, it is necessary to identify a statistically significant trend in the bias (shift) of indicators. To solve such problems, a researcher can use a number of discrimination criteria. Below we will consider non-parametric tests: the sign test and the chi-square test.
The significance of the multiple regression equation as a whole, as well as in paired regression, is assessed using the Fisher criterion:
 ,
(2.22)
,
(2.22)
Where  – factor sum of squares per degree of freedom;
– factor sum of squares per degree of freedom;  – residual sum of squares per degree of freedom;
– residual sum of squares per degree of freedom;  – coefficient (index) of multiple determination;
– coefficient (index) of multiple determination;  – number of parameters for variables
– number of parameters for variables  (in linear regression it coincides with the number of factors included in the model);
(in linear regression it coincides with the number of factors included in the model);  – number of observations.
– number of observations.
The significance of not only the equation as a whole is assessed, but also the factor additionally included in the regression model. The need for such an assessment is due to the fact that not every factor included in the model can significantly increase the proportion of explained variation in the resulting trait. In addition, if there are several factors in the model, they can be entered into the model in different sequences. Due to the correlation between factors, the significance of the same factor can be different depending on the sequence of its introduction into the model. The measure for assessing the inclusion of a factor in the model is the private  -criterion, i.e.
-criterion, i.e.  .
.
Private  -criterion is based on comparing the increase in factor variance due to the influence of an additionally included factor with the residual variance per one degree of freedom for the regression model as a whole. In general terms for the factor
-criterion is based on comparing the increase in factor variance due to the influence of an additionally included factor with the residual variance per one degree of freedom for the regression model as a whole. In general terms for the factor  private
private  -the criterion will be determined as
-the criterion will be determined as
 ,
(2.23)
,
(2.23)
Where  – coefficient of multiple determination for a model with a full set of factors,
– coefficient of multiple determination for a model with a full set of factors,  – the same indicator, but without including the factor in the model
– the same indicator, but without including the factor in the model  ,
, – number of observations,
– number of observations,  – number of parameters in the model (without free term).
– number of parameters in the model (without free term).
Actual value of the quotient  - the criterion is compared with the table at the level of significance
- the criterion is compared with the table at the level of significance  and number of degrees of freedom: 1 and
and number of degrees of freedom: 1 and  . If the actual value
. If the actual value  exceeds
exceeds  , then the additional inclusion of the factor
, then the additional inclusion of the factor  into the model is statistically justified and the pure regression coefficient
into the model is statistically justified and the pure regression coefficient  at factor
at factor  statistically significant. If the actual value
statistically significant. If the actual value  is less than the table value, then additional inclusion of the factor in the model
is less than the table value, then additional inclusion of the factor in the model  does not significantly increase the proportion of explained variation in a trait
does not significantly increase the proportion of explained variation in a trait  , therefore, it is inappropriate to include it in the model; The regression coefficient for this factor in this case is statistically insignificant.
, therefore, it is inappropriate to include it in the model; The regression coefficient for this factor in this case is statistically insignificant.
For a two-factor equation, the quotients  -criteria have the form:
-criteria have the form:
 ,
, . (2.23a)
. (2.23a)
Using private  -criterion, one can check the significance of all regression coefficients under the assumption that each corresponding factor
-criterion, one can check the significance of all regression coefficients under the assumption that each corresponding factor  entered into the multiple regression equation last.
entered into the multiple regression equation last.
-Student test for multiple regression equation.
Private  -criterion evaluates the significance of pure regression coefficients. Knowing the magnitude
-criterion evaluates the significance of pure regression coefficients. Knowing the magnitude  , it is possible to determine
, it is possible to determine  -criterion for the regression coefficient at
-criterion for the regression coefficient at  -m factor,
-m factor,  , namely:
, namely:
 .
(2.24)
.
(2.24)
Assessing the significance of pure regression coefficients by  -Student's t-test can be carried out without calculating the partial
-Student's t-test can be carried out without calculating the partial  -criteria. In this case, as in pairwise regression, the formula is used for each factor:
-criteria. In this case, as in pairwise regression, the formula is used for each factor:
 ,
(2.25)
,
(2.25)
Where  – pure regression coefficient at the factor
– pure regression coefficient at the factor  ,
, – mean square (standard) error of the regression coefficient
– mean square (standard) error of the regression coefficient  .
.
For a multiple regression equation, the mean square error of the regression coefficient can be determined by the following formula:
 ,
(2.26)
,
(2.26)
Where 
 ,
, – standard deviation for the characteristic
– standard deviation for the characteristic  ,
, – coefficient of determination for the multiple regression equation,
– coefficient of determination for the multiple regression equation,  – coefficient of determination for the dependence of the factor
– coefficient of determination for the dependence of the factor  with all other factors in the multiple regression equation;
with all other factors in the multiple regression equation;  – number of degrees of freedom for the residual sum of squared deviations.
– number of degrees of freedom for the residual sum of squared deviations.
As you can see, in order to use this formula, you need an interfactor correlation matrix and the calculation of the corresponding coefficients of determination using it  . So, for the equation
. So, for the equation  assessment of the significance of regression coefficients
assessment of the significance of regression coefficients  ,
, ,
, involves the calculation of three interfactor determination coefficients:
involves the calculation of three interfactor determination coefficients:  ,
, ,
, .
.
The relationship between the indicators of the partial correlation coefficient, partial  -criteria and
-criteria and  -Student's t-test for pure regression coefficients can be used in the factor selection procedure. The elimination of factors when constructing a regression equation by the elimination method can practically be carried out not only by partial correlation coefficients, excluding at each step the factor with the smallest insignificant value of the partial correlation coefficient, but also by values
-Student's t-test for pure regression coefficients can be used in the factor selection procedure. The elimination of factors when constructing a regression equation by the elimination method can practically be carried out not only by partial correlation coefficients, excluding at each step the factor with the smallest insignificant value of the partial correlation coefficient, but also by values  And
And  .
Private
.
Private  -criterion is widely used when constructing a model using the method of inclusion of variables and the stepwise regression method.
-criterion is widely used when constructing a model using the method of inclusion of variables and the stepwise regression method.
Calculation of criterion φ*
1. Determine those values of the attribute that will be the criterion for dividing subjects into those who “have an effect” and those who “do not have an effect.” If the characteristic is measured quantitatively, use the λ criterion to find the optimal separation point.
2. Draw a four-cell (synonym: four-field) table of two columns and two rows. The first column is “there is an effect”; second column - “no effect”; first line from the top - 1 group (sample); second line - group 2 (sample).
4. Count the number of subjects in the first sample who have “no effect” and enter this number in the upper right cell of the table. Calculate the sum of the top two cells. It should coincide with the number of subjects in the first group.
6. Count the number of subjects in the second sample who have “no effect” and enter this number in the lower right cell of the table. Calculate the sum of the two lower cells. It should coincide with the number of subjects in the second group (sample).
7. Determine the percentage of subjects who “have an effect” by relating their number to the total number of subjects in a given group (sample). Write the resulting percentages in the upper left and lower left cells of the table in parentheses, respectively, so as not to confuse them with absolute values.
8. Check to see if one of the percentages being compared is equal to zero. If this is the case, try to change this by moving the group separation point in one direction or another. If this is impossible or undesirable, abandon the φ* criterion and use the χ2 criterion.
9. Determine according to Table. XII Appendix 1 angles φ for each of the compared percentages.
where: φ1 - angle corresponding to the larger percentage;
φ2 - angle corresponding to the smaller percentage;
N1 - number of observations in sample 1;
N2 - number of observations in sample 2.
11. Compare the obtained value φ* with the critical values: φ* ≤1.64 (p<0,05) и φ* ≤2,31 (р<0,01).
If φ*emp ≤φ*cr. H0 is rejected.
If necessary, determine the exact level of significance of the resulting φ*emp according to Table. XIII Appendix 1.
This method is described in many manuals (Plokhinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992, etc.) This description is based on the version of the method that was developed and presented by E.V. Gubler.
Purpose of the criterion φ*
Fisher's criterion is designed to compare two samples according to the frequency of occurrence of the effect (indicator) of interest to the researcher. The larger it is, the more reliable the differences.
Description of criterion
The criterion evaluates the reliability of differences between those percentages of two samples in which the effect (indicator) of interest to us was recorded. Figuratively speaking, we compare the 2 best pieces cut from 2 pies and decide which one is truly larger.
The essence of the Fisher angular transformation is to convert percentages into central angle values, which are measured in radians. A larger percentage will correspond to a larger angle φ, and a smaller percentage will correspond to a smaller angle, but the relationships here are not linear:
where P is the percentage expressed in fractions of a unit (see Fig. 5.1).
With increasing discrepancy between angles φ 1 and φ 2 and increasing the number of samples, the value of the criterion increases. The larger the value of φ*, the more likely it is that the differences are significant.
Hypotheses
H 0 : Proportion of persons, in which the studied effect manifests itself, there are no more in sample 1 than in sample 2.
H 1 : The proportion of individuals who exhibit the studied effect is greater in sample 1 than in sample 2.
Graphical representation of the criterion φ*
The angular transformation method is somewhat more abstract than the other criteria.
The formula followed by E.V. Gubler when calculating the values of φ assumes that 100% makes up an angle φ=3.142, that is, a rounded value π=3.14159... This allows us to present the compared samples in the form of two semicircles, each which symbolizes 100% of the population of its sample. The percentages of subjects with an “effect” will be represented as sectors formed by the central angles φ. In Fig. Figure 5.2 shows two semicircles illustrating Example 1. In the first sample, 60% of subjects solved the problem. This percentage corresponds to the angle φ=1.772. In the second sample, 40% of subjects solved the problem. This percentage corresponds to the angle φ =1.369.
The φ* criterion allows you to determine whether one of the angles is indeed statistically significantly superior to the other for given sample sizes.
Limitations of the criterion φ*
1. None of the proportions being compared should be zero. Formally, there are no obstacles to using the φ method in cases where the proportion of observations in one of the samples is equal to 0. However, in these cases, the result may turn out to be unjustifiably inflated (Gubler E.V., 1978, p. 86).
2. Upper there is no limit in the φ criterion - samples can be as large as desired.
Lower limit - 2 observations in one of the samples. However, the following ratios in the number of two samples must be observed:
a) if one sample has only 2 observations, then the second must have at least 30:
b) if one of the samples has only 3 observations, then the second must have at least 7:
c) if one of the samples has only 4 observations, then the second must have at least 5:
d) atn 1 , n 2 ≥ 5 Any comparisons are possible.
In principle, it is also possible to compare samples that do not meet this condition, for example, with the relationn 1 =2, n 2 = 15, but in these cases it will not be possible to identify significant differences.
The φ* criterion has no other restrictions.
Let's look at a few examples to illustrate the possibilitiescriterion φ*.
Example 1: comparison of samples according to a qualitatively defined characteristic.
Example 2: comparison of samples according to a quantitatively measured characteristic.
Example 3: comparison of samples both by level and distribution of a characteristic.
Example 4: Using the φ* criterion in combination with the criterionX Kolmogorov-Smirnov in order to achieve the most accurate result.
Example 1 - comparison of samples according to a qualitatively defined characteristic
In this use of the criterion, we compare the percentage of subjects in one sample characterized by some quality with the percentage of subjects in another sample characterized by the same quality.
Let's say we are interested in whether two groups of students differ in their success in solving a new experimental problem. In the first group of 20 people, 12 people coped with it, and in the second sample of 25 people - 10. In the first case, the percentage of those who solved the problem will be 12/20·100%=60%, and in the second 10/25·100%= 40%. Do these percentages differ significantly given the data?n 1 Andn 2 ?
It would seem that even “by eye” one can determine that 60% is significantly higher than 40%. However, in fact, these differences, given the datan 1 , n 2 unreliable.
Let's check it out. Since we are interested in the fact of solving the problem, we will consider success in solving the experimental problem as an “effect”, and failure in solving it as the absence of an effect.
Let's formulate hypotheses.
H 0 : Proportion of personsThere were no more people who completed the task in the first group than in the second group.
H 1 : The proportion of people who completed the task in the first group is greater than in the second group.
Now let’s build the so-called four-cell, or four-field table, which is actually a table of empirical frequencies for two values of the attribute: “there is an effect” - “there is no effect.”
Table 5.1
Four-cell table for calculating the criterion when comparing two groups of subjects according to the percentage of those who solved the problem.
Groups | “There is an effect”: problem solved | "No effect": the problem is not solved | Amounts |
||||
Quantity subjects | % share | Quantity subjects | % share | ||||
1 group | (60%) | (40%) | |||||
2nd group | (40%) | (60%) | |||||
Amounts | |||||||
In a four-cell table, as a rule, the columns “There is an effect” and “No effect” are marked at the top, and the rows “Group 1” and “Group 2” are on the left. In fact, only fields (cells) A and B are involved in comparisons, that is, percentage shares in the “There is an effect” column.
According to Table.XIIAppendix 1 determines the values of φ corresponding to the percentage shares in each of the groups.
Now let’s calculate the empirical value of φ* using the formula:
where φ 1 - angle corresponding to the larger % share;
φ 2 - angle corresponding to the smaller % share;
n 1 - number of observations in sample 1;
n 2 - number of observations in sample 2.
In this case:
According to Table.XIIIIn Appendix 1 we determine what level of significance corresponds to φ* em=1,34:
p=0.09
It is also possible to establish critical values of φ* corresponding to the levels of statistical significance accepted in psychology:
Let's build a "significance axis".
The obtained empirical value φ* is in the zone of insignificance.
Answer: H 0 accepted. The percentage of people who completed the taskVin the first group no more than in the second group.
One can only sympathize with a researcher who considers differences of 20% and even 10% significant without checking their reliability using the φ* criterion. In this case, for example, only differences of at least 24.3% would be significant.
It seems that when comparing two samples on any qualitative basis, the φ criterion can make us sad rather than happy. What seemed significant may not be so from a statistical point of view.
The Fisher criterion has much more opportunities to please the researcher when we compare two samples according to quantitatively measured characteristics and can vary the “effect.”
Example 2 - comparison of two samples according to a quantitatively measured characteristic
In this use of the criterion, we compare the percentage of subjects in one sample who achieve a certain level of attribute value with the percentage of subjects who achieve this level in another sample.
In a study by G. A. Tlegenova (1990), out of 70 young vocational school students aged 14 to 16 years, 10 subjects with a high score on the Aggression scale and 11 subjects with a low score on the Aggression scale were selected based on the results of a survey using the Freiburg Personality Questionnaire. It is necessary to determine whether groups of aggressive and non-aggressive young men differ in terms of the distance they spontaneously choose in a conversation with a fellow student. The data of G. A. Tlegenova are presented in Table. 5.2. You can notice that aggressive young men more often choose a distance of 50cm or even less, while non-aggressive boys more often choose a distance greater than 50 cm.
Now we can consider a distance of 50 cm as critical and assume that if the distance chosen by the subject is less than or equal to 50 cm, then “there is an effect,” and if the selected distance is greater than 50 cm, then “there is no effect.” We see that in the group of aggressive young men the effect is observed in 7 out of 10, i.e. in 70% of cases, and in the group of non-aggressive young men - in 2 out of 11, i.e. in 18.2% of cases. These percentages can be compared using the φ* method to establish the significance of the differences between them.
Table 5.2
Indicators of the distance (in cm) chosen by aggressive and non-aggressive young men in a conversation with a fellow student (according to G.A. Tlegenova, 1990)
Group 1: boys with high scores on the Aggression scaleFPI- R (n 1 =10) | Group 2: boys with low values on the Aggression scaleFPI- R (n 2 =11) |
|||
d(c m ) | % share | d(c M ) | % share |
|
"Eat Effect" d≤50 cm | ||||
18,2% |
||||
"No effect" d>50 cm | ||||
80 QO | 81,8% |
|||
Amounts | 100% | 100% |
||
Average | 5b:o | 77.3 | ||
Let's formulate hypotheses.
H 0 d ≤ 50 cm, in the group of aggressive boys there is no more than in the group of non-aggressive boys.
H 1 : Proportion of people who choose distanced≤ 50 cm, more in the group of aggressive young men than in the group of non-aggressive young men. Now let's build a so-called four-cell table.
Table 53
Four-cell table for calculating the φ* criterion when comparing groups of aggressive (nf=10) and non-aggressive young men (n2=11)
Groups | "There is an effect": d≤50 | "No effect." d>50 | Amounts |
||||
Number of subjects | (% share) | Number of subjects | (% share) | ||||
Group 1 - aggressive young men | (70%) | (30%) | |||||
Group 2 - non-aggressive young men | (180%) | (81,8%) | |||||
Sum | |||||||
According to Table.XIIAppendix 1 determines the values of φ corresponding to the percentage shares of the “effect” in each of the groups.
The obtained empirical value φ* is in the zone of significance.
Answer: H 0 rejected. AcceptedH 1 . The proportion of people who choose a distance in conversation less than or equal to 50 cm is greater in the group of aggressive young men than in the group of non-aggressive young men
Based on the results obtained, we can conclude that more aggressive young men more often choose a distance of less than half a meter, while non-aggressive young men more often choose a distance greater than half a meter. We see that aggressive young men actually communicate on the border between the intimate (0-46 cm) and personal zones (from 46 cm). We remember, however, that intimate distance between partners is the prerogative of not only close, good relationships, butAndhand-to-hand combat (HallE. T., 1959).
Example 3 - comparison of samples both by level and distribution of the characteristic.
In this use case, we can first test whether the groups differ in levels of some trait and then compare the distributions of the trait in the two samples. Such a task may be relevant when analyzing differences in the ranges or shape of the distribution of assessments obtained by subjects using any new technique.
In a study by R. T. Chirkina (1995), for the first time, a questionnaire was used aimed at identifying the tendency to repress facts, names, intentions and methods of action from memory due to personal, family and professional complexes. The questionnaire was created with the participation of E.V. Sidorenko based on materials from the book 3. Freud “Psychopathology of Everyday Life”. A sample of 50 students of the Pedagogical Institute, unmarried, without children, aged 17 to 20 years, was examined using this questionnaire, as well as the Menester-Corzini technique to identify the intensity of the feeling of personal insufficiency,or"inferiority complex" (ManasterG. J., CorsiniR. J., 1982).
The survey results are presented in Table. 5.4.
Is it possible to say that there are any significant relationships between the indicator of repression energy, diagnosed using a questionnaire, and indicators of intensity, the feeling of one’s own insufficiency?
Table 5.4
Indicators of the intensity of feelings of personal insufficiency in groups of students with high (nj=18) and low (n2=24) displacement energy
Group 1: displacement energy from 19 to 31 points (n 1 =181 | Group 2: displacement energy from 7 to 13 points (n 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
Amounts Average | 26,11 | 15,42 |
Despite the fact that the average value in the group with more energetic repression is higher, 5 zero values are also observed in it. If we compare the histograms of the distribution of ratings in the two samples, a striking contrast is revealed between them (Fig. 5.3).
To compare two distributions we could apply the testχ 2 or criterionλ , but for this we would have to enlarge the ranks, and in addition, in both samplesn <30.
The φ* criterion will allow us to check the effect of the discrepancy between two distributions observed in the graph if we agree to assume that “there is an effect” if the indicator of feelings of insufficiency takes either very low (0) or, conversely, very high values (S30), and that “there is no effect” if the indicator of feelings of insufficiency takes average values, from 5 to 25.
Let's formulate hypotheses.
H 0 : Extreme values of the deficiency index (either 0 or 30 or more) in the group with more energetic repression are no more common than in the group with less energetic repression.
H 1 : Extreme values of the deficiency index (either 0 or 30 or more) in the group with more energetic repression are more common than in the group with less energetic repression.
Let's create a four-cell table convenient for further calculation of the φ* criterion.
Table 5.5
Four-cell table for calculating the φ* criterion when comparing groups with higher and lower repression energies based on the ratio of insufficiency indicators
Groups | “There is an effect”: the deficiency indicator is 0 or >30 | “No effect”: failure index from 5 to 25 | Amounts |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
Amounts | |||||
According to Table.XIIIn Appendix 1 we determine the values of φ corresponding to the compared percentages:
Let's calculate the empirical value of φ*:
Critical values of φ* for anyn 1 , n 2 , as we remember from the previous example, are:
TableXIIIAppendix 1 allows us to more accurately determine the level of significance of the result obtained: p<0,001.
Answer: H 0 rejected. AcceptedH 1 . Extreme values of the deficiency index (either 0 or 30 or more) in the group with greater repression energy occur more often than in the group with less repression energy.
So, subjects with greater repression energy can have both very high (30 or more) and very low (zero) indicators of the feeling of their own insufficiency. It can be assumed that they are repressing both their dissatisfaction and the need for success in life. These assumptions need further testing.
The obtained result, regardless of its interpretation, confirms the capabilities of the φ* criterion in assessing differences in the shape of the distribution of a trait in two samples.
There were 50 people in the original sample, but 8 of them were excluded from consideration as having an average score on the repression anergy index (14-15). Their indicators of the intensity of feelings of insufficiency are also average: 6 values of 20 points each and 2 values of 25 points each.
The powerful capabilities of the φ* criterion can be verified by confirming a completely different hypothesis when analyzing the materials of this example. We can prove, for example, that in a group with greater repression energy the rate of insufficiency is still higher, despite the paradoxical nature of its distribution in this group.
Let's formulate new hypotheses.
H 0 The highest values of the deficiency index (30 or more) in the group with greater repression energy are no more common than in the group with less repression energy.
H 1 : The highest values of the deficiency index (30 or more) in the group with greater repression energy occur more often than in the group with less repression energy. Let's build a four-field table using the data in Table. 5.4.
Table 5.6
Four-cell table for calculating the φ* criterion when comparing groups with greater and lesser repression energy according to the level of insufficiency indicator
Groups | “There is an effect”* failure indicator is greater than or equal to 30 | “No effect”: the failure rate is lower 30 | Amounts |
||
Group 1 - with greater displacement energy | (61,1%) | (38.9%) | |||
Group 2 - with lower displacement energy | (25.0%) | (75.0%) | |||
Amounts | |||||
According to Table.XIIIIn Appendix 1 we determine that this result corresponds to the significance level of p = 0.008.
Answer: But it is rejected. AcceptedHj: The highest indicators of deficiency (30 or more points) in the groupWithwith greater displacement energy occur more often than in the group with less displacement energy (p = 0.008).
So, we were able to prove thatVgroupWithwith more energetic repression, extreme values of the insufficiency indicator predominate, and the fact that this indicator exceeds its valuesreachesexactly in this group.
Now we could try to prove that in the group with higher repression energy, lower values of the insufficiency index are more common, despite the fact that the average valueV this group has more (26.11 versus 15.42 in the groupWith less displacement).
Let's formulate hypotheses.
H 0 : Lowest deficiency rates (zero) in the groupWith repressions with greater energy are no more common than in the groupWith less displacement energy.
H 1 : The lowest rates of deficiency (zero) occurV group with greater repression energy more often than in the groupWith less energetic repression. Let's group the data into a new four-cell table.
Table 5.7
Four-cell table for comparing groups with different repression energies based on the frequency of zero values of the deficiency indicator
Groups | "There is an effect": the failure indicator is 0 | "No effect" of insufficiency | indicator is not equal to 0 | Amounts |
|
Group 1 - with greater displacement energy | (27,8%) | (72,2%) | |||
1 group - with less displacement energy | (8,3%) | (91,7%) | |||
Amounts | |||||
We determine the values of φ and calculate the value of φ*:
Answer: H 0 rejected. The lowest indices of insufficiency (zero) in the group with greater repression energy are more common than in the group with less repression energy (p<0,05).
In total, the results obtained can be considered as evidence of a partial coincidence of the concepts of complex in S. Freud and A. Adler.
It is significant that a positive linear correlation was obtained between the indicator of repression energy and the indicator of the intensity of the feeling of one’s own insufficiency in the sample as a whole (p = +0.491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Example 4 - using the φ* criterion in combination with the criterion λ Kolmogorov-Smirnov in order to achieve the maximum accurateresult
If samples are compared according to any quantitatively measured indicators, the problem arises of identifying the distribution point that can be used as a critical point in dividing all subjects into those who “have an effect” and those who “do not have an effect.”
In principle, the point at which we would divide the group into subgroups where there is an effect and where there is no effect can be chosen quite arbitrarily. We can be interested in any effect and, therefore, we can divide both samples into two parts at any point, as long as it makes some sense.
In order to maximize the power of the φ* test, however, it is necessary to select the point at which the differences between the two compared groups are greatest. Most accurately, we can do this using an algorithm for calculating the criterionλ , allowing you to detect the point of maximum discrepancy between two samples.
Possibility of combining criteria φ* andλ described by E.V. Gubler (1978, pp. 85-88). Let's try to use this method in solving the following problem.
In a joint study by M.A. Kurochkina, E.V. Sidorenko and Yu.A. Churakov (1992) in the UK conducted a survey of English general practitioners of two categories: a) doctors who supported medical reform and had already turned their reception offices into fund-holding organizations with their own budget; b) doctors whose offices still do not have their own funds and are entirely provided by the state budget. Questionnaires were sent to a sample of 200 doctors, representative of the general population of English doctors in terms of representation of people of different gender, age, length of service and place of work - in large cities or in the provinces.
78 doctors responded to the questionnaire, of which 50 worked in waiting rooms with funds and 28 from waiting rooms without funds. Each of the doctors had to predict what the share of admissions with funds would be in the next year, 1993. Only 70 doctors out of 78 who sent answers answered this question. The distribution of their forecasts is presented in Table. 5.8 separately for the group of doctors with funds and the group of doctors without funds.
Are the prognoses of doctors with funds and doctors without funds different in any way?
Table 5.8
Distribution of forecasts from general practitioners about what the share of emergency rooms with funds will be in 1993
Projected share | |||
reception rooms with funds | doctors with the fund (n 1 =45) | doctors without a fund (n 2 =25) | Amounts |
1. from 0 to 20% | 4 | 5 | 9 |
2. from 21 to 40% | 15 | AND | 26 |
3. from 41 to 60% | 18 | 5 | 23 |
4. from 61 to 80% | 7 | 4 | AND |
5. from 81 to 100% | 1 | 0 | 1 |
Amounts | 45 | 25 | 70 |
Let's determine the point of maximum discrepancy between the two distributions of answers using Algorithm 15 from clause 4.3 (see Table 5.9).
Table 5.9
Calculation of the maximum difference in accumulated frequencies in the distributions of forecasts of doctors of two groups
Projected share of admissions with funds (%) | Empirical frequencies of choice for a given response category | Empirical frequencies | Cumulative empirical frequencies | Difference (d) |
|||
doctors with the fund(n 1 =45) | doctors without a fund (n 2 =25) | f* uh 1 | f* a2 | ∑f* e1 | ∑f* a1 |
||
1. from 0 to 20% 2. from 21 to 40% 3. from 41 to 60% 4. from 61 to 80% 5. from 81 to 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
The maximum difference detected between two accumulated empirical frequencies is0,218.
This difference turns out to be accumulated in the second category of the forecast. Let's try to use the upper limit of this category as a criterion for dividing both samples into a subgroup where “there is an effect” and a subgroup where “there is no effect.” We will assume that there is an “effect” if a given doctor predicts from 41 to 100% of admissions with funds in1993 year, and that there is “no effect” if a given doctor predicts from 0 to 40% of admissions with funds in1993 year. We combine forecast categories 1 and 2 on the one hand, and forecast categories 3, 4 and 5 on the other. The resulting distribution of forecasts is presented in Table. 5.10.
Table 5.10
Distribution of forecasts for doctors with funds and doctors without funds
Projected share of admissions with funds (%1 | Empirical frequencies for choosing a given forecast category | Amounts |
|
doctors with the fund(n 1 =45) | doctors without a fund(n 2 =25) |
||
1. from 0 to 40% | 19 | 16 | 35 |
2. from 41 to 100% | 26 | 9 | 35 |
Amounts | 45 | 25 | 70 |
We can use the resulting table (Table 5.10) to test different hypotheses by comparing any two of its cells. We remember that this is the so-called four-cell, or four-field, table.
Here, we are interested in whether physicians who already have funds predict greater future growth of this movement than physicians who do not have funds. Therefore, we conditionally consider that “there is an effect” when the forecast falls into the category from 41 to 100%. To simplify the calculations, we now need to rotate the table 90°, rotating it in a clockwise direction. You can even do this literally by turning the book along with the table. Now we can move on to the worksheet for calculating the φ* criterion - Fisher's Angular Transform.
Table 5.11
Four-cell table for calculating Fisher's φ* test to identify differences in the forecasts of two groups of general practitioners
Group | There is an effect - forecast from 41 to 100% | No effect - forecast from 0 to 40% | Total |
Igroup - doctors who took the fund | 26 (57.8%) | 19 (42.2%) | 45 |
IIgroup - doctors who did not take the fund | 9 (36.0%) | 16 (64.0%) | 25 |
Total | 35 | 35 | 70 |
Let's formulate hypotheses.
H 0 : Proportion of personspredicting the spread of funds to 41%-100% of all doctor's offices, in the group of doctors with funds there is no more than in the group of doctors without funds.
H 1 : The proportion of people predicting the spread of funds to 41%-100% of all admissions is greater in the group of doctors with funds than in the group of doctors without funds.
Determining the values of φ 1 and φ 2 according to TableXIIAppendix 1. Recall that φ 1 is always the angle corresponding to the larger percentage.
Now let’s determine the empirical value of the criterion φ*:
According to Table.XIIIIn Appendix 1 we determine what level of significance this value corresponds to: p = 0.039.
Using the same table in Appendix 1, you can determine the critical values of the criterion φ*:
Answer: But it is rejected (p=0.039). The share of people predicting the spread of funds to41-100 % of all receptions in the group of doctors who took the fund exceeds this share in the group of doctors who did not take the fund.
In other words, doctors who already work in their waiting rooms on a separate budget predict a wider spread of this practice this year than doctors who have not yet agreed to switch to an independent budget. There are multiple interpretations of this result. For example, it can be assumed that doctors in each group subconsciously consider their behavior to be more typical. This may also mean that doctors who have already adopted self-funding tend to exaggerate the scope of this movement, as they need to justify their decision. The identified differences may also mean something that is completely beyond the scope of the questions posed in the study. For example, that the activity of doctors working on an independent budget contributes to sharpening the differences in the positions of both groups. They were more active when they agreed to take the funds; they were more active when they took the trouble to answer the mail questionnaire; they are more active when they predict that other physicians will be more active in receiving funds.
One way or another, we can be sure that the detected level of statistical differences is the maximum possible for these real data. We established using the criterionλ the point of maximum divergence between the two distributions, and it was at this point that the samples were divided into two parts.
Your mark.
In this example, we will consider how the reliability of the resulting regression equation is assessed. The same test is used to test the hypothesis that the regression coefficients are simultaneously equal to zero, a=0, b=0. In other words, the essence of the calculations is to answer the question: can it be used for further analysis and forecasts?
To determine whether the variances in two samples are similar or different, use this t-test.
So, the purpose of the analysis is to obtain some estimate, with the help of which it could be stated that at a certain level of α, the resulting regression equation is statistically reliable. For this coefficient of determination R 2 is used.
Testing the significance of a regression model is carried out using Fisher's F test, the calculated value of which is found as the ratio of the variance of the original series of observations of the indicator being studied and the unbiased estimate of the variance of the residual sequence for this model.
If the calculated value with k 1 =(m) and k 2 =(n-m-1) degrees of freedom is greater than the tabulated value at a given significance level, then the model is considered significant.
where m is the number of factors in the model.
The statistical significance of paired linear regression is assessed using the following algorithm:
1. A null hypothesis is put forward that the equation as a whole is statistically insignificant: H 0: R 2 =0 at the significance level α.
2. Next, determine the actual value of the F-criterion: ![]()
![]()
where m=1 for pairwise regression.
3. The tabulated value is determined from the Fisher distribution tables for a given significance level, taking into account that the number of degrees of freedom for the total sum of squares (larger variance) is 1 and the number of degrees of freedom for the residual sum of squares (smaller variance) in linear regression is n-2 (or through the Excel function FRIST(probability,1,n-2)).
F table is the maximum possible value of the criterion under the influence of random factors with given degrees of freedom and significance level α. The significance level α is the probability of rejecting the correct hypothesis, provided that it is true. Typically α is taken to be 0.05 or 0.01.
4. If the actual value of the F-test is less than the table value, then they say that there is no reason to reject the null hypothesis.
Otherwise, the null hypothesis is rejected and with probability (1-α) the alternative hypothesis about the statistical significance of the equation as a whole is accepted.
Table value of the criterion with degrees of freedom k 1 =1 and k 2 =48, F table = 4
conclusions: Since the actual value F > F table, the coefficient of determination is statistically significant ( the found regression equation estimate is statistically reliable) .
Analysis of variance
.Regression equation quality indicators
Example. Based on a total of 25 trading enterprises, the relationship between the following characteristics is studied: X - price of product A, thousand rubles; Y is the profit of a trading enterprise, million rubles. When assessing the regression model, the following intermediate results were obtained: ∑(y i -y x) 2 = 46000; ∑(y i -y avg) 2 = 138000. What correlation indicator can be determined from these data? Calculate the value of this indicator based on this result and using Fisher's F test draw conclusions about the quality of the regression model.
Solution. From these data we can determine the empirical correlation ratio:  , where ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
, where ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000.
η 2 = 92,000/138000 = 0.67, η = 0.816 (0.7< η < 0.9 - связь между X и Y высокая).
Fisher's F test: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 - 1 - 1) = 46. F table (1; 23) = 4.27
Since the actual value F > Ftable, the found estimate of the regression equation is statistically reliable.
Question: What statistics are used to test the significance of a regression model?
Answer: For the significance of the entire model as a whole, F-statistics (Fisher's test) are used.
To compare two normally distributed populations that have no differences in sample means, but there is a difference in variances, use Fisher test. The actual criterion is calculated using the formula:
where the numerator is the larger value of the sample variance, and the denominator is the smaller one. To conclude the reliability of differences between samples, use THE BASIC PRINCIPLE
testing statistical hypotheses. Critical points for  are contained in the table. The null hypothesis is rejected if the actual value
are contained in the table. The null hypothesis is rejected if the actual value 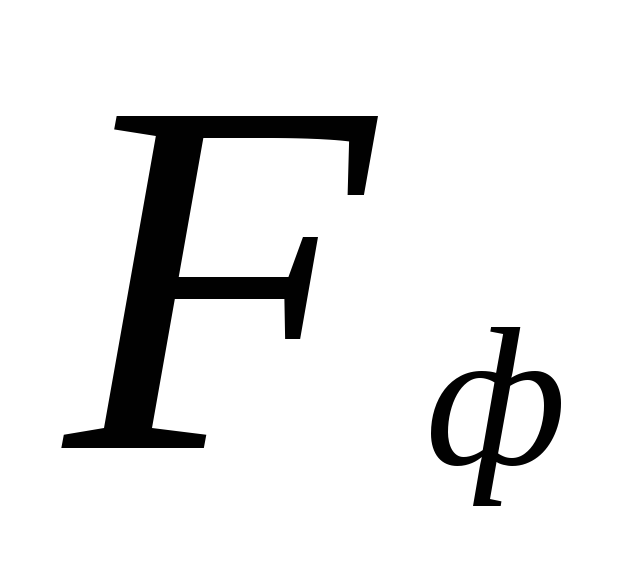 will exceed or be equal to the critical (standard) value
will exceed or be equal to the critical (standard) value  this value for the accepted significance level
and number of degrees of freedom k
1
=
n
big
-1
;
k
2
=
n
smaller
-1
.
this value for the accepted significance level
and number of degrees of freedom k
1
=
n
big
-1
;
k
2
=
n
smaller
-1
.
Example: when studying the effect of a certain drug on the rate of seed germination, it was found that in the experimental batch of seeds and the control, the average germination rate is the same, but there is a difference in the variances.  =1250,
=1250, =417. The sample sizes are the same and equal to 20.
=417. The sample sizes are the same and equal to 20. 
 =2.12. Therefore, the null hypothesis is rejected.
=2.12. Therefore, the null hypothesis is rejected.
Correlation dependence. Correlation coefficient and its properties. Regression equations.
TASK correlation analysis comes down to:
Establishing the direction and form of connection between characteristics;
Measuring its tightness.
Functional An unambiguous relationship between variable quantities is called when a certain value of one (independent) variable X , called an argument, corresponds to a certain value of another (dependent) variable at , called a function. ( Example: dependence of the rate of a chemical reaction on temperature; dependence of the force of attraction on the masses of attracting bodies and the distance between them).
Correlation is a relationship between variables that are statistical in nature, when a certain value of one characteristic (considered as an independent variable) corresponds to a whole series of numerical values of another characteristic. ( Example: relationship between harvest and rainfall; between height and weight, etc.).
Correlation field represents a set of points whose coordinates are equal to experimentally obtained pairs of variable values X And at .
By the type of correlation field one can judge the presence or absence of a connection and its type.




The connection is called positive , if when one variable increases, another variable increases.
The connection is called negative , if when one variable increases, another variable decreases.
The connection is called linear
, if it can be represented analytically as 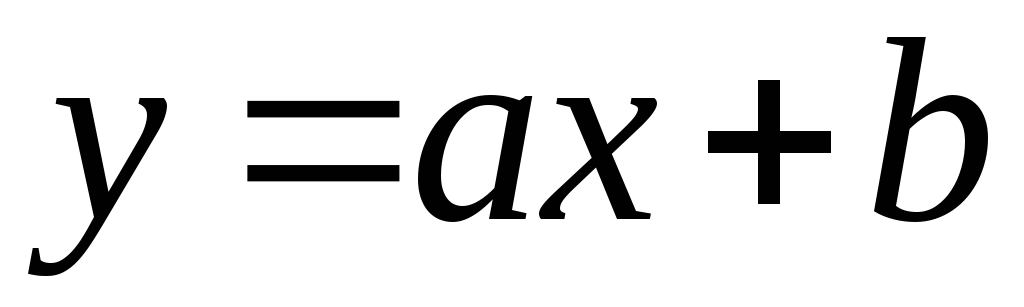 .
.
An indicator of the closeness of the connection is correlation coefficient . The empirical correlation coefficient is given by:

The correlation coefficient ranges from -1 before 1 and characterizes the degree of closeness between quantities x And y . If:

The correlation between characteristics can be described in different ways. In particular, any form of connection can be expressed by an equation of the general form 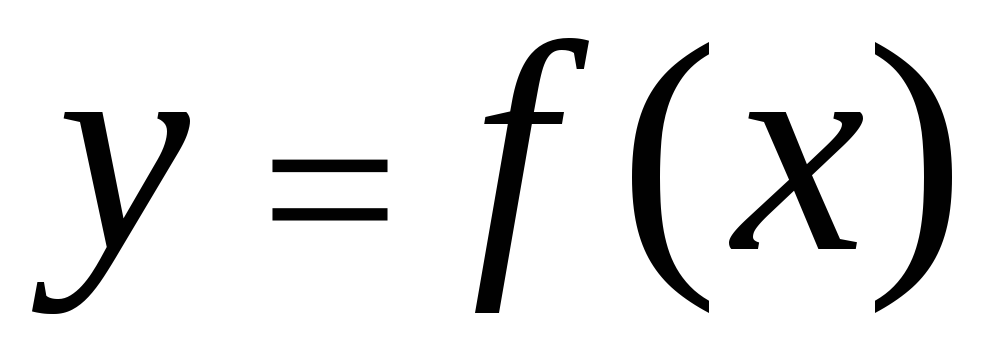 . Equation of the form
. Equation of the form  And
And 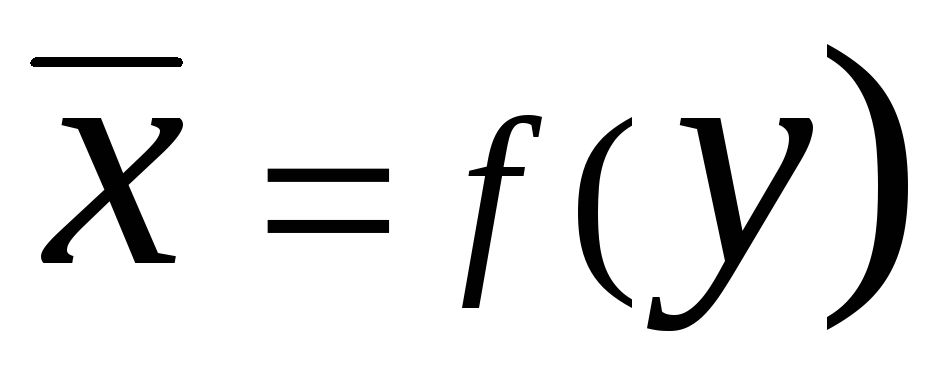 are called regression
. Forward Regression Equation at
on X
in the general case can be written in the form
are called regression
. Forward Regression Equation at
on X
in the general case can be written in the form

Forward Regression Equation X on at in general it looks like

The most probable values of the coefficients A And V, With And d can be calculated, for example, using the least squares method.







