Критерий на Фишерви позволява да сравните дисперсиите на извадката на две независими извадки. За да изчислите F emp, трябва да намерите съотношението на дисперсиите на две проби, така че по-голямата дисперсия да е в числителя, а по-малката - в знаменателя. Формулата за изчисляване на критерия на Фишер е:
където са дисперсиите съответно на първата и втората извадка.
Тъй като според условията на критерия стойността на числителя трябва да бъде по-голяма или равна на стойността на знаменателя, стойността на F emp винаги ще бъде по-голяма или равна на единица.
Броят на степените на свобода също се определя просто:
к 1 =n л - 1 за първата проба (т.е. за пробата, чиято дисперсия е по-голяма) и к 2 = н 2 - 1 за втората проба.
В Приложение 1 критичните стойности на критерия на Фишер се намират чрез стойностите на k 1 (горния ред на таблицата) и k 2 (лявата колона на таблицата).
Ако t em >t crit, тогава нулевата хипотеза се приема, в противен случай се приема алтернативата.
Пример 3.Тестването е проведено в два трети класа умствено развитиедесет ученици на теста TURMSH. Получените средни стойности не се различават значително, но психологът се интересува от въпроса дали има разлики в степента на хомогенност на показателите за умствено развитие между класовете.
Решение. За теста на Фишер е необходимо да се сравнят дисперсиите на резултатите от тестовете в двата класа. Резултатите от теста са представени в таблицата:
Таблица 3.
|
Брой студенти |
Първи клас |
Втори клас |
След като изчислим дисперсиите за променливите X и Y, получаваме:
с х 2 =572.83; с г 2 =174,04
След това, използвайки формула (8) за изчисление, използвайки F критерия на Фишер, намираме:
![]()
Според таблицата от Приложение 1 за критерия F със степени на свобода и в двата случая k = 10 - 1 = 9 намираме F crit = 3,18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Непараметрични тестове
Сравнявайки на око (в проценти) резултатите преди и след всяко въздействие, изследователят стига до извода, че ако се наблюдават разлики, значи има разлика в сравняваните проби. Този подход е категорично неприемлив, тъй като за проценти е невъзможно да се определи нивото на надеждност в разликите. Процентите, взети сами по себе си, не позволяват да се направят статистически надеждни заключения. За да се докаже ефективността на всяка интервенция, е необходимо да се идентифицира статистически значима тенденция в отклонението (изместването) на индикаторите. За да разреши такива проблеми, изследователят може да използва редица критерии за дискриминация. По-долу ще разгледаме непараметрични тестове: знаков тест и хи-квадрат тест.
Значимостта на уравнението на множествената регресия като цяло, както и в сдвоената регресия, се оценява с помощта на критерия на Фишер:
 ,
(2.22)
,
(2.22)
Където  – фактор сбор от квадрати за степен на свобода;
– фактор сбор от квадрати за степен на свобода;  – остатъчна сума от квадрати за степен на свобода;
– остатъчна сума от квадрати за степен на свобода;  – коефициент (индекс) на множествена детерминация;
– коефициент (индекс) на множествена детерминация;  – брой параметри за променливи
– брой параметри за променливи  (при линейна регресия съвпада с броя на факторите, включени в модела);
(при линейна регресия съвпада с броя на факторите, включени в модела);  – брой наблюдения.
– брой наблюдения.
Оценява се значимостта не само на уравнението като цяло, но и на фактора, допълнително включен в регресионния модел. Необходимостта от такава оценка се дължи на факта, че не всеки фактор, включен в модела, може значително да увеличи дела на обяснената вариация в резултантния признак. Освен това, ако има няколко фактора в модела, те могат да бъдат въведени в модела в различни последователности. Поради корелацията между факторите, значимостта на един и същи фактор може да бъде различна в зависимост от последователността на въвеждането му в модела. Мярката за оценка на включването на даден фактор в модела е частната  -критерий, т.е.
-критерий, т.е.  .
.
Частно  -критерият се основава на сравняване на увеличението на факторната дисперсия поради влиянието на допълнително включен фактор с остатъчната дисперсия за една степен на свобода за регресионния модел като цяло. Най-общо за фактора
-критерият се основава на сравняване на увеличението на факторната дисперсия поради влиянието на допълнително включен фактор с остатъчната дисперсия за една степен на свобода за регресионния модел като цяло. Най-общо за фактора  частен
частен  -критерият ще бъде определен като
-критерият ще бъде определен като
 ,
(2.23)
,
(2.23)
Където  – коефициент на множествена детерминация за модел с пълен набор от фактори,
– коефициент на множествена детерминация за модел с пълен набор от фактори,  – същия показател, но без включване на фактора в модела
– същия показател, но без включване на фактора в модела  ,
, – брой наблюдения,
– брой наблюдения,  – брой параметри в модела (без свободен член).
– брой параметри в модела (без свободен член).
Действителната стойност на коефициента  - критерият се сравнява с таблицата на ниво значимост
- критерият се сравнява с таблицата на ниво значимост  и брой степени на свобода: 1 и
и брой степени на свобода: 1 и  . Ако действителната стойност
. Ако действителната стойност  превишава
превишава  , след това допълнителното включване на фактора
, след това допълнителното включване на фактора  в модела е статистически обоснован и коефициентът на чиста регресия
в модела е статистически обоснован и коефициентът на чиста регресия  при фактор
при фактор  статистически значим. Ако действителната стойност
статистически значим. Ако действителната стойност  е по-малка от табличната стойност, тогава допълнително включване на фактора в модела
е по-малка от табличната стойност, тогава допълнително включване на фактора в модела  не увеличава значително дела на обяснената вариация в черта
не увеличава значително дела на обяснената вариация в черта  , поради което не е подходящо включването му в модела; Коефициентът на регресия за този фактор в този случай е статистически незначим.
, поради което не е подходящо включването му в модела; Коефициентът на регресия за този фактор в този случай е статистически незначим.
За двуфакторно уравнение частните  -критериите имат формата:
-критериите имат формата:
 ,
, . (2.23a)
. (2.23a)
Използване на лични  -критерий, може да се провери значимостта на всички регресионни коефициенти при допускането, че всеки съответен фактор
-критерий, може да се провери значимостта на всички регресионни коефициенти при допускането, че всеки съответен фактор  въведени в уравнението на множествената регресия последни.
въведени в уравнението на множествената регресия последни.
-Тест на студент за уравнение на множествена регресия.
Частно  -критерий оценява значимостта на чистите регресионни коефициенти. Познавайки величината
-критерий оценява значимостта на чистите регресионни коефициенти. Познавайки величината  , възможно е да се определи
, възможно е да се определи  -критерий за коефициента на регресия при
-критерий за коефициента на регресия при  -m фактор,
-m фактор,  , а именно:
, а именно:
 .
(2.24)
.
(2.24)
Оценяване на значимостта на чистите коефициенти на регресия чрез  -Тестът на Стюдънт може да се извърши без изчисляване на частичното
-Тестът на Стюдънт може да се извърши без изчисляване на частичното  - критерии. В този случай, както при регресия по двойки, формулата се използва за всеки фактор:
- критерии. В този случай, както при регресия по двойки, формулата се използва за всеки фактор:
 ,
(2.25)
,
(2.25)
Където  – чист коефициент на регресия при фактора
– чист коефициент на регресия при фактора  ,
, – средна квадратична (стандартна) грешка на регресионния коефициент
– средна квадратична (стандартна) грешка на регресионния коефициент  .
.
За уравнение на множествена регресия средната квадратична грешка на регресионния коефициент може да се определи по следната формула:
 ,
(2.26)
,
(2.26)
Където 
 ,
, – стандартно отклонение за характеристиката
– стандартно отклонение за характеристиката  ,
, – коефициент на определяне за уравнението на множествената регресия,
– коефициент на определяне за уравнението на множествената регресия,  – коефициент на детерминация за зависимостта на фактора
– коефициент на детерминация за зависимостта на фактора  с всички други фактори в уравнението на множествената регресия;
с всички други фактори в уравнението на множествената регресия;  – брой степени на свобода за остатъчната сума на квадратите на отклоненията.
– брой степени на свобода за остатъчната сума на квадратите на отклоненията.
Както можете да видите, за да използвате тази формула, имате нужда от междуфакторна корелационна матрица и изчисляването на съответните коефициенти на детерминация, използвайки я  . И така, за уравнението
. И така, за уравнението  оценка на значимостта на регресионните коефициенти
оценка на значимостта на регресионните коефициенти  ,
, ,
, включва изчисляването на три междуфакторни коефициента на определяне:
включва изчисляването на три междуфакторни коефициента на определяне:  ,
, ,
, .
.
Връзката между показателите на частичния коефициент на корелация, частична  - критерии и
- критерии и  -Тестът на Стюдънт за коефициенти на чиста регресия може да се използва в процедурата за избор на фактор. Елиминирането на факторите при конструиране на регресионно уравнение по метода на елиминиране може практически да се извърши не само чрез частични корелационни коефициенти, изключвайки на всяка стъпка фактора с най-малката незначителна стойност на частичния корелационен коефициент, но и чрез стойности
-Тестът на Стюдънт за коефициенти на чиста регресия може да се използва в процедурата за избор на фактор. Елиминирането на факторите при конструиране на регресионно уравнение по метода на елиминиране може практически да се извърши не само чрез частични корелационни коефициенти, изключвайки на всяка стъпка фактора с най-малката незначителна стойност на частичния корелационен коефициент, но и чрез стойности  И
И  .
Частно
.
Частно  -критерият се използва широко при конструирането на модел с помощта на метода на включване на променливи и метода на поетапната регресия.
-критерият се използва широко при конструирането на модел с помощта на метода на включване на променливи и метода на поетапната регресия.
Изчисляване на критерия φ*
1. Определете онези стойности на атрибута, които ще бъдат критерий за разделяне на субектите на тези, които „имат ефект“ и тези, които „нямат ефект“. Ако характеристиката се измерва количествено, използвайте критерия λ, за да намерите оптималната точка на разделяне.
2. Начертайте таблица с четири клетки (синоним: четири полета) с две колони и два реда. Първата колона е „има ефект“; втора колона - „без ефект“; първи ред отгоре - 1 група (проба); втори ред - група 2 (проба).
4. Пребройте броя на субектите в първата проба, които нямат ефект, и въведете това число в горната дясна клетка на таблицата. Изчислете сумата от горните две клетки. Той трябва да съвпада с броя на предметите от първа група.
6. Пребройте броя на субектите във втората проба, които нямат ефект, и въведете това число в долната дясна клетка на таблицата. Изчислете сумата от двете долни клетки. Той трябва да съвпада с броя на субектите във втората група (проба).
7. Определете процента на субектите, които „имат ефект“, като съотнесете техния брой към общия брой субекти в дадена група (извадка). Запишете получените проценти съответно в горната лява и долната лява клетка на таблицата в скоби, за да не ги объркате с абсолютни стойности.
8. Проверете дали един от сравняваните проценти е равен на нула. Ако случаят е такъв, опитайте да промените това, като преместите точката за разделяне на групата в една или друга посока. Ако това е невъзможно или нежелателно, изоставете критерия φ* и използвайте критерия χ2.
9. Определете по табл. XII Приложение 1 ъгли φ за всеки от сравняваните проценти.
където: φ1 - ъгъл, съответстващ на по-големия процент;
φ2 - ъгъл, съответстващ на по-малкия процент;
N1 - брой наблюдения в проба 1;
N2 - брой наблюдения в проба 2.
11. Сравнете получената стойност φ* с критичните стойности: φ* ≤1,64 (p<0,05) и φ* ≤2,31 (р<0,01).
Ако φ*emp ≤φ*cr. H0 се отхвърля.
Ако е необходимо, определете точното ниво на значимост на полученото φ*emp съгласно табл. XIII Приложение 1.
Този метод е описан в много ръководства (Plokhinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992 и др.) Това описание се основава на версията на метода, която е разработена и представена от E.V. Гублер.
Предназначение на критерия φ*
Критерият на Фишер е предназначен за сравняване на две проби според честотата на поява на ефекта (индикатора), който представлява интерес за изследователя. Колкото по-голямо е, толкова по-надеждни са разликите.
Описание на критерия
Критерият оценява надеждността на разликите между онези проценти от две проби, в които е записан ефектът (показателят), който ни интересува. Образно казано, сравняваме 2-те най-добри парчета, изрязани от 2 пая, и решаваме кое е наистина по-голямо.
Същността на ъгловата трансформация на Фишер е да преобразува процентите в стойности на централен ъгъл, които се измерват в радиани. По-голям процент ще съответства на по-голям ъгъл φ, а по-малък процент ще съответства на по-малък ъгъл, но връзките тук не са линейни:
където P е процентът, изразен в части от единица (виж Фиг. 5.1).
С увеличаване на несъответствието между ъглите φ 1 и φ 2 и увеличаване на броя на пробите, стойността на критерия се увеличава. Колкото по-голяма е стойността на φ*, толкова по-вероятно е разликите да са значителни.
Хипотези
з 0 : Съотношение на лицата, в които се проявява изследваният ефект, в проба 1 няма повече, отколкото в проба 2.
з 1 : Делът на индивидите, които проявяват изследвания ефект, е по-голям в проба 1, отколкото в проба 2.
Графично представяне на критерия φ*
Методът на ъглова трансформация е малко по-абстрактен от другите критерии.
Формулата, следвана от E.V. Gubler при изчисляване на стойностите на φ, предполага, че 100% съставлява ъгъл φ=3,142, тоест закръглена стойност π=3,14159... Това ни позволява да представим сравнените проби под формата на два полукръга, всеки от които символизира 100% от съвкупността от своята извадка. Процентите на субектите с „ефект“ ще бъдат представени като сектори, образувани от централните ъгли φ. На фиг. Фигура 5.2 показва два полукръга, илюстриращи Пример 1. В първата извадка 60% от участниците са решили проблема. Този процент съответства на ъгъла φ=1,772. Във втората извадка 40% от субектите са решили проблема. Този процент съответства на ъгъл φ =1,369.
Критерият φ* ни позволява да определим дали един от ъглите наистина е статистически значимо по-добър от другия за дадени размери на извадката.
Ограничения на критерия φ*
1. Нито една от сравняваните пропорции не трябва да е нула. Формално няма пречки за прилагането на метода φ в случаите, когато делът на наблюденията в една от извадките е равен на 0. Въпреки това, в тези случаи резултатът може да се окаже неоправдано завишен (Gubler E.V., 1978, p. 86).
2. Горна няма ограничение в критерия φ - пробите могат да бъдат толкова големи, колкото желаете.
Нисък граница - 2 наблюдения в една от пробите. Трябва обаче да се спазват следните съотношения в броя на две проби:
а) ако една проба има само 2 наблюдения, тогава втората трябва да има поне 30:
б) ако една от пробите има само 3 наблюдения, тогава втората трябва да има поне 7:
в) ако една от пробите има само 4 наблюдения, тогава втората трябва да има поне 5:
г) прин 1 , н 2 ≥ 5 Възможни са всякакви сравнения.
По принцип също е възможно да се сравняват проби, които не отговарят на това условие, например с връзкатан 1 =2, н 2 = 15, но в тези случаи няма да е възможно да се установят съществени разлики.
Критерият φ* няма други ограничения.
Нека да разгледаме няколко примера, за да илюстрираме възможноститекритерий φ*.
Пример 1: сравнение на проби по качествено определена характеристика.
Пример 2: сравнение на проби по количествено измерена характеристика.
Пример 3: сравнение на проби както по ниво, така и по разпределение на характеристика.
Пример 4: Използване на критерия φ* в комбинация с критериях Колмогоров-Смирнов, за да се постигне най-точен резултат.
Пример 1 - сравнение на проби по качествено определен признак
При това използване на критерия, ние сравняваме процента на субекти в една проба, характеризираща се с някакво качество, с процента на субекти в друга проба, характеризираща се със същото качество.
Да кажем, че се интересуваме дали две групи ученици се различават по успеха си при решаването на нов експериментален проблем. В първата група от 20 души с нея са се справили 12 души, а във втората извадка от 25 души - 10. В първия случай процентът на решилите задачата ще бъде 12/20·100%=60%, а във втория 10/25·100%= 40%. Различават ли се значително тези проценти предвид данните?н 1 Ин 2 ?
Изглежда, че дори „на око“ може да се определи, че 60% е значително по-високо от 40%. Въпреки това, в действителност, тези разлики, предвид даннитен 1 , н 2 ненадежден.
Нека го проверим. Тъй като се интересуваме от факта на решаването на даден проблем, ще считаме успеха при решаването на експериментален проблем като „ефект“, а неуспеха при решаването му като липса на ефект.
Да формулираме хипотези.
з 0 : Съотношение на лицатаВ първата група няма повече хора, които са изпълнили задачата, отколкото във втората група.
з 1 : Делът на хората, изпълнили задачата в първата група, е по-голям, отколкото във втората група.
Сега нека изградим така наречената таблица с четири клетки или четири полета, която всъщност е таблица с емпирични честоти за две стойности на атрибута: „има ефект“ - „няма ефект“.
Таблица 5.1
Таблица с четири клетки за изчисляване на критерия при сравняване на две групи субекти според процента на решилите задачата.
Групи | „Има ефект“: проблемът е решен | „Няма ефект“: проблемът не е решен | суми |
||||
Количество предмети | % дял | Количество предмети | % дял | ||||
1 група | (60%) | (40%) | |||||
2-ра група | (40%) | (60%) | |||||
суми | |||||||
В таблица с четири клетки, като правило, колоните „Има ефект“ и „Няма ефект“ са маркирани в горната част, а редовете „Група 1“ и „Група 2“ са отляво. Всъщност в сравненията участват само полета (клетки) A и B, тоест проценти в колоната „Има ефект“.
Според табл.XIIПриложение 1 определя стойностите на φ, съответстващи на процентните дялове във всяка от групите.
Сега нека изчислим емпиричната стойност на φ*, използвайки формулата:
където φ 1 - ъгъл, съответстващ на по-големия % дял;
φ 2 - ъгъл, съответстващ на по-малкия % дял;
н 1 - брой наблюдения в проба 1;
н 2 - брой наблюдения в проба 2.
В такъв случай:
Според табл.XIIIВ Приложение 1 определяме какво ниво на значимост съответства на φ* ем=1,34:
р=0,09
Също така е възможно да се установят критични стойности на φ *, съответстващи на нивата на статистическа значимост, приети в психологията:
Нека изградим "ос на значимост".
Получената емпирична стойност φ* е в зоната на незначимост.
Отговор: з 0 приет. Процентът на хората, изпълнили задачатаVв първата група не повече, отколкото във втората група.
Човек може само да симпатизира на изследовател, който смята разликите от 20% и дори 10% за значими, без да провери надеждността им с помощта на критерия φ*. В този случай, например, само разлики от най-малко 24,3% биха били значими.
Изглежда, че когато сравняваме две проби на каквато и да е качествена основа, критерият φ може да ни направи по-скоро тъжни, отколкото щастливи. Това, което изглежда значително, може да не е така от статистическа гледна точка.
Критерият на Фишер има много повече възможности да угоди на изследователя, когато сравняваме две проби според количествено измерените характеристики и може да променя „ефекта“.
Пример 2 - сравнение на две проби по количествено измерена характеристика
При това използване на критерия, ние сравняваме процента субекти в една извадка, които постигат определено ниво на стойност на атрибута, с процента субекти, които постигат това ниво в друга извадка.
В проучване на G. A. Tlegenova (1990) от 70 млади ученици от професионални училища на възраст от 14 до 16 години, въз основа на резултатите бяха избрани 10 субекта с висок резултат по скалата на агресивността и 11 субекта с нисък резултат по скалата на агресивността. на проучване, използващо Фрайбургския въпросник за личността. Необходимо е да се установи дали групите от агресивни и неагресивни младежи се различават по дистанцията, която спонтанно избират в разговор със съученик. Данните на Г. А. Тлегенова са представени в табл. 5.2. Можете да забележите, че агресивните млади мъже по-често избират разстояние от 50cm или дори по-малко, докато неагресивните момчета по-често избират разстояние, по-голямо от 50 cm.
Сега можем да считаме разстояние от 50 см за критично и да приемем, че ако разстоянието, избрано от субекта, е по-малко или равно на 50 см, тогава „има ефект“, а ако избраното разстояние е по-голямо от 50 см, тогава "няма ефект." Виждаме, че в групата на агресивните младежи ефектът се наблюдава в 7 от 10, т.е. в 70% от случаите, а в групата на неагресивните младежи - в 2 от 11, т.е. в 18,2% от случаите. . Тези проценти могат да бъдат сравнени с помощта на метода φ*, за да се установи значимостта на разликите между тях.
Таблица 5.2
Показатели за разстоянието (в см), избрано от агресивни и неагресивни млади мъже в разговор със съученик (според G.A. Tlegenova, 1990)
Група 1: момчета с висок резултат по скалата за агресивностFPI- Р (н 1 =10) | Група 2: момчета с ниски стойности по скалата на агресивносттаFPI- Р (н 2 =11) |
|||
d(c м ) | % дял | d(c М ) | % дял |
|
"Яжте ефект" д≤50 см | ||||
18,2% |
||||
"Не ефект" d>50см | ||||
80 QO | 81,8% |
|||
суми | 100% | 100% |
||
Средно аритметично | 5b:o | 77.3 | ||
Да формулираме хипотези.
з 0 д ≤ 50 cm, в групата на агресивните младежи няма повече, отколкото в групата на неагресивните младежи.
з 1 : Пропорция на хората, които избират разстояниед≤ 50 см, повече в групата на агресивните младежи, отколкото в групата на неагресивните младежи. Сега нека изградим така наречената таблица с четири клетки.
Таблица 53
Таблица с четири клетки за изчисляване на критерия φ* при сравняване на групи от агресивни (nf=10) и неагресивни млади мъже (n2=11)
Групи | "Има ефект": д≤50 | "Без ефект." д>50 | суми |
||||
Брой предмети | (% дял) | Брой предмети | (% дял) | ||||
1 група - агресивни млади мъже | (70%) | (30%) | |||||
2 група - неагресивни младежи | (180%) | (81,8%) | |||||
Сума | |||||||
Според табл.XIIПриложение 1 определя стойностите на φ, съответстващи на процентните дялове на „ефекта“ във всяка от групите.
Получената емпирична стойност φ* е в зоната на значимост.
Отговор: з 0 отхвърлени. Приетоз 1 . Делът на хората, които избират дистанция в разговор по-малка или равна на 50 см, е по-голям в групата на агресивните младежи, отколкото в групата на неагресивните младежи
Въз основа на получените резултати можем да заключим, че по-агресивните млади мъже по-често избират разстояние под половин метър, докато неагресивните младежи по-често избират разстояние, по-голямо от половин метър. Виждаме, че агресивните млади мъже всъщност общуват на границата между интимната (0-46 см) и личната зона (от 46 см). Помним обаче, че интимното разстояние между партньорите е прерогатив не само на близки, добри отношения, ноИръкопашен бой (Холд. T., 1959).
Пример 3 - сравнение на проби както по ниво, така и по разпределение на характеристиката.
В този случай на употреба можем първо да тестваме дали групите се различават по нива на дадена черта и след това да сравним разпределенията на чертата в двете проби. Такава задача може да бъде уместна, когато се анализират разликите в обхватите или формата на разпределението на оценките, получени от субекти, използващи всяка нова техника.
В изследване на Р. Т. Чиркина (1995) за първи път е използван въпросник, насочен към идентифициране на тенденцията да се изтласкват от паметта факти, имена, намерения и методи на действие поради лични, семейни и професионални комплекси. Въпросникът е създаден с участието на Е.В. Сидоренко по материали от книгата 3. Фройд „Психопатология на ежедневието“. Извадка от 50 студенти от Педагогическия институт, неженени, без деца, на възраст от 17 до 20 години, беше изследвана с помощта на този въпросник, както и с техниката Menester-Corzini за идентифициране на интензивността на чувството за лична недостатъчност,или"комплекс за малоценност" (МанастирЖ. Дж., КорсиниР. Дж., 1982).
Резултатите от проучването са представени в табл. 5.4.
Може ли да се каже, че има значими връзки между показателя енергия на потискане, диагностициран с помощта на въпросник, и показателите за интензивността на чувството за собствена недостатъчност?
Таблица 5.4
Индикатори за интензивността на чувството за лична недостатъчност в групи от студенти с висока (nj=18) и ниска (n2=24) енергия на изместване
Група 1: енергия на изместване от 19 до 31 точки (н 1 =181 | Група 2: енергия на изместване от 7 до 13 точки (н 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
суми Средно аритметично | 26,11 | 15,42 |
Въпреки факта, че средната стойност в групата с по-енергична репресия е по-висока, в нея се наблюдават и 5 нулеви стойности. Ако сравним хистограмите на разпределението на оценките в двете извадки, се разкрива ярък контраст между тях (фиг. 5.3).
За да сравним две разпределения, можем да приложим тестаχ 2 или критерийλ , но за това ще трябва да увеличим ранговете и в допълнение, в двете извадкин <30.
Критерият φ* ще ни позволи да проверим ефекта от несъответствието между две разпределения, наблюдавани в графиката, ако се съгласим да приемем, че „има ефект“, ако индикаторът за чувство на недостатъчност е много нисък (0) или обратно , много високи стойности (С30), и че „няма ефект“, ако индикаторът за чувство на недостатъчност приема средни стойности от 5 до 25.
Да формулираме хипотези.
з 0 : Екстремните стойности на индекса на дефицит (0 или 30 или повече) в групата с по-енергична репресия не са по-чести, отколкото в групата с по-малко енергична репресия.
з 1 : Екстремните стойности на индекса на дефицит (0 или 30 или повече) в групата с по-енергична репресия са по-чести, отколкото в групата с по-малко енергична репресия.
Нека създадем таблица с четири клетки, удобна за по-нататъшно изчисляване на критерия φ*.
Таблица 5.5
Таблица с четири клетки за изчисляване на критерия φ* при сравняване на групи с по-високи и по-ниски енергии на репресия въз основа на съотношението на показателите за недостатъчност
Групи | „Има ефект“: индикаторът за дефицит е 0 или >30 | „Без ефект“: индекс на повреда от 5 до 25 | суми |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
суми | |||||
Според табл.XIIВ Приложение 1 определяме стойностите на φ, съответстващи на сравнените проценти:
Нека изчислим емпиричната стойност на φ*:
Критични стойности на φ * за всякаквин 1 , н 2 , както помним от предишния пример, са:
ТаблицаXIIIПриложение 1 ни позволява по-точно да определим нивото на значимост на получения резултат: стр<0,001.
Отговор: з 0 отхвърлени. Приетоз 1 . Екстремни стойности на индекса на дефицит (0 или 30 или повече) в групата с по-голяма репресивна енергия се срещат по-често, отколкото в групата с по-малко репресивна енергия.
И така, субекти с по-голяма репресивна енергия могат да имат както много високи (30 или повече), така и много ниски (нула) показатели за чувството за собствена недостатъчност. Може да се предположи, че те потискат както своето недоволство, така и нуждата от успех в живота. Тези предположения се нуждаят от допълнителни тестове.
Полученият резултат, независимо от неговата интерпретация, потвърждава възможностите на критерия φ* при оценка на разликите във формата на разпределение на признак в две извадки.
Първоначалната извадка включваше 50 души, но 8 от тях бяха изключени от разглеждането като имащи среден резултат по индекса на репресивна енергия (14-15). Техните показатели за интензивността на чувството за недостатъчност също са средни: 6 стойности по 20 точки и 2 стойности по 25 точки.
Мощните възможности на критерия φ* могат да бъдат проверени чрез потвърждаване на напълно различна хипотеза при анализиране на материалите от този пример. Можем да докажем например, че в група с по-голяма репресивна енергия степента на недостатъчност е все още по-висока, въпреки парадоксалния характер на нейното разпределение в тази група.
Да формулираме нови хипотези.
з 0 Най-високите стойности на индекса на дефицит (30 или повече) в групата с по-голяма репресивна енергия не са по-чести, отколкото в групата с по-малко репресивна енергия.
з 1 : Най-високите стойности на индекса на дефицит (30 или повече) в групата с по-голяма репресивна енергия се срещат по-често, отколкото в групата с по-малко репресивна енергия. Нека изградим таблица с четири полета, използвайки данните в Таблица. 5.4.
Таблица 5.6
Таблица с четири клетки за изчисляване на критерия φ* при сравняване на групи с по-голяма и по-малка енергия на репресия според нивото на индикатора за недостатъчност
Групи | Индикаторът за повреда „Има ефект“* е по-голям или равен на 30 | „Няма ефект“: степента на неуспех е по-малка 30 | суми |
||
Група 1 - с по-голяма енергия на преместване | (61,1%) | (38.9%) | |||
Група 2 - с по-ниска енергия на изместване | (25.0%) | (75.0%) | |||
суми | |||||
Според табл.XIIIВ Приложение 1 определяме, че този резултат съответства на нивото на значимост p = 0,008.
Отговор: Но се отхвърля. ПриетоHj: Най-високите показатели за недостатъчност (30 или повече точки) в групатасс по-голяма енергия на изместване се срещат по-често, отколкото в групата с по-малка енергия на изместване (p = 0,008).
И така, успяхме да докажем товаVгрупаспри по-енергична репресия преобладават екстремни стойности на показателя за недостатъчност и фактът, че този показател надвишава стойностите сидостигаточно в тази група.
Сега можем да се опитаме да докажем, че в групата с по-висока репресивна енергия по-често се срещат по-ниски стойности на индекса на недостатъчност, въпреки факта, че средната стойностV тази група има повече (26,11 срещу 15,42 в групатас по-малко изместване).
Да формулираме хипотези.
з 0 : Най-ниски нива на дефицит (нула) в групатас репресиите с по-голяма енергия не са по-чести, отколкото в групатас по-малко енергия на изместване.
з 1 : Има най-ниски нива на дефицит (нула).V група с по-голяма репресивна енергия по-често, отколкото в групатас по-малко енергична репресия. Нека групираме данните в нова таблица с четири клетки.
Таблица 5.7
Таблица с четири клетки за сравняване на групи с различни енергии на потискане въз основа на честотата на нулевите стойности на индикатора за дефицит
Групи | „Има ефект“: индикаторът за повреда е 0 | „Без ефект“ на недостатъчност | индикаторът не е равен на 0 | суми |
|
Група 1 - с по-голяма енергия на преместване | (27,8%) | (72,2%) | |||
1 група - с по-малка енергия на изместване | (8,3%) | (91,7%) | |||
суми | |||||
Определяме стойностите на φ и изчисляваме стойността на φ*:
Отговор: з 0 отхвърлени. Най-ниските индекси на недостатъчност (нула) в групата с по-голяма репресивна енергия са по-чести, отколкото в групата с по-малко репресивна енергия (p<0,05).
Като цяло получените резултати могат да се считат за доказателство за частично съвпадение на понятията за комплекс при З. Фройд и А. Адлер.
Показателно е, че се получава положителна линейна корелация между показателя енергия на потискане и показателя интензитет на чувството за собствена недостатъчност в извадката като цяло (p = +0,491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Пример 4 - използване на критерия φ* в комбинация с критерия λ Колмогоров-Смирнов, за да се постигне максимума точенрезултат
Ако пробите се сравняват според каквито и да било количествено измерени показатели, възниква проблемът с идентифицирането на точката на разпределение, която може да се използва като критична точка при разделянето на всички субекти на тези, които „имат ефект“ и тези, които „нямат ефект“.
По принцип точката, в която бихме разделили групата на подгрупи, където има ефект и където няма ефект, може да бъде избрана съвсем произволно. Можем да се интересуваме от какъвто и да е ефект и следователно можем да разделим и двете проби на две части по всяко време, стига да има някакъв смисъл.
За да се увеличи максимално мощността на φ* теста обаче, е необходимо да се избере точката, в която разликите между двете сравнявани групи са най-големи. Най-точно можем да направим това с помощта на алгоритъм за изчисляване на критерияλ , което ви позволява да откриете точката на максимално несъответствие между две проби.
Възможност за комбиниране на критерии φ* иλ описан от E.V. Gubler (1978, стр. 85-88). Нека се опитаме да използваме този метод при решаването на следния проблем.
В съвместно проучване на M.A. Курочкина, Е.В. Сидоренко и Ю.А. Чураков (1992) в Обединеното кралство провежда проучване на английски общопрактикуващи лекари от две категории: а) лекари, които подкрепят медицинската реформа и вече са превърнали приемните си кабинети в организации, държащи средства със собствен бюджет; б) лекари, чиито кабинети все още не разполагат със собствени средства и се осигуряват изцяло от държавния бюджет. Бяха изпратени въпросници на извадка от 200 лекари, представителни за общата съвкупност от английски лекари по отношение на представителството на хора от различен пол, възраст, стаж и месторабота - в големите градове или в провинцията.
На въпросника са отговорили 78 лекари, от които 50 са работили в чакални със средства и 28 от чакални без средства. Всеки от лекарите трябваше да прогнозира какъв ще бъде делът на приетите със средства през следващата 1993 година. Само 70 лекари от 78 изпратили отговори отговориха на този въпрос. Разпределението на техните прогнози е представено в табл. 5.8 поотделно за групата лекари със средства и групата лекари без средства.
Различават ли се по нещо прогнозите на лекарите със средства и тези без средства?
Таблица 5.8
Разпределение на прогнозите на общопрактикуващите лекари за това какъв ще бъде делът на спешните кабинети със средства през 1993 г.
Прогнозиран дял | |||
приемни стаи със средства | лекари с фонда (н 1 =45) | лекари без фонд (н 2 =25) | суми |
1. от 0 до 20% | 4 | 5 | 9 |
2. от 21 до 40% | 15 | И | 26 |
3. от 41 до 60% | 18 | 5 | 23 |
4. от 61 до 80% | 7 | 4 | И |
5. от 81 до 100% | 1 | 0 | 1 |
суми | 45 | 25 | 70 |
Нека определим точката на максимално несъответствие между двете разпределения на отговора, като използваме алгоритъм 15 от точка 4.3 (виж таблица 5.9).
Таблица 5.9
Изчисляване на максималната разлика в натрупаните честоти в разпределенията на прогнозите на лекарите от две групи
Прогнозиран дял на приема със средства (%) | Емпирични честоти на избор за дадена категория отговор | Емпирични честоти | Кумулативни емпирични честоти | Разлика (д) |
|||
лекари с фонда(н 1 =45) | лекари без фонд (н 2 =25) | е* ъъъ 1 | е* a2 | ∑е* e1 | ∑е* a1 |
||
1. от 0 до 20% 2. от 21 до 40% 3. от 41 до 60% 4. от 61 до 80% 5. от 81 до 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
Максималната разлика, открита между две натрупани емпирични честоти, е0,218.
Тази разлика се оказва натрупана във втората категория на прогнозата. Нека се опитаме да използваме горната граница на тази категория като критерий за разделяне на двете проби на подгрупа, където „има ефект“ и подгрупа, където „няма ефект“. Ще приемем, че има „ефект“, ако даден лекар прогнозира от 41 до 100% от приема със средства в1993 година и че няма „никакъв ефект“, ако даден лекар прогнозира от 0 до 40% от приема със средства в1993 година. Комбинираме прогнозни категории 1 и 2 от една страна и прогнозни категории 3, 4 и 5 от друга. Полученото разпределение на прогнозите е представено в табл. 5.10.
Таблица 5.10
Разпределение на прогнози за лекари с пари и лекари без пари
Прогнозиран дял от приема със средства (%1 | Емпирични честоти за избор на дадена прогнозна категория | суми |
|
лекари с фонда(н 1 =45) | лекари без фонд(н 2 =25) |
||
1. от 0 до 40% | 19 | 16 | 35 |
2. от 41 до 100% | 26 | 9 | 35 |
суми | 45 | 25 | 70 |
Можем да използваме получената таблица (Таблица 5.10), за да тестваме различни хипотези, като сравняваме произволни две нейни клетки. Спомняме си, че това е така наречената таблица с четири клетки или четири полета.
Тук се интересуваме дали лекарите, които вече имат средства, прогнозират по-голям бъдещ растеж на това движение от лекарите, които нямат средства. Затова условно считаме, че „има ефект”, когато прогнозата попада в категорията от 41 до 100%. За да опростим изчисленията, сега трябва да завъртим масата на 90°, като я завъртим по посока на часовниковата стрелка. Можете дори да направите това буквално, като завъртите книгата заедно с масата. Сега можем да преминем към работния лист за изчисляване на критерия φ* - Ъглова трансформация на Фишер.
Таблица 5.11
Таблица с четири клетки за изчисляване на φ* критерия на Фишер за идентифициране на разликите в прогнозите на две групи общопрактикуващи лекари
Група | Има ефект - прогноза от 41 до 100% | Без ефект - прогноза от 0 до 40% | Обща сума |
азгрупа - лекари, взели фонд | 26 (57.8%) | 19 (42.2%) | 45 |
IIгрупа - лекари, които не са взели касата | 9 (36.0%) | 16 (64.0%) | 25 |
Обща сума | 35 | 35 | 70 |
Да формулираме хипотези.
з 0 : Съотношение на лицатапредвиждайки разпределението на средствата към 41%-100% от всички лекарски кабинети, в групата на лекарите със средства няма повече, отколкото в групата на лекарите без средства.
з 1 : Делът на хората, които прогнозират разпределението на средствата до 41%-100% от всички приема, е по-голям в групата на лекарите със средства, отколкото в групата на лекарите без средства.
Определяне на стойностите на φ 1 и φ 2 според таблXIIПриложение 1. Припомнете си, че φ 1 винаги е ъгълът, съответстващ на по-големия процент.
Сега нека да определим емпиричната стойност на критерия φ*:
Според табл.XIIIВ Приложение 1 определяме на какво ниво на значимост отговаря тази стойност: p = 0,039.
Използвайки същата таблица в Приложение 1, можете да определите критичните стойности на критерия φ*:
Отговор: Но се отхвърля (p=0,039). Делът на хората, които прогнозират разпределението на средства към41-100 % на всички приеми в групата на лекарите, които са поели касата, надвишава този дял в групата на лекарите, които не са поели касата.
С други думи, лекарите, които вече работят в чакалните си на отделен бюджет, прогнозират тази година по-широко разпространение на тази практика от лекарите, които все още не са се съгласили да преминат на самостоятелен бюджет. Има много интерпретации на този резултат. Например, може да се предположи, че лекарите от всяка група подсъзнателно смятат поведението си за по-типично. Това може също да означава, че лекарите, които вече са приели самофинансиране, са склонни да преувеличават обхвата на това движение, тъй като трябва да обосноват решението си. Установените различия може да означават и нещо, което е напълно извън обхвата на въпросите, поставени в изследването. Например, че дейността на лекарите, работещи на самостоятелен бюджет, допринася за изострянето на различията в позициите на двете групи. Те бяха по-активни, когато се съгласиха да вземат средствата, те бяха по-активни, когато си направиха труда да отговорят на въпросника по пощата; те са по-активни, когато прогнозират, че други лекари ще бъдат по-активни в получаването на средства.
По един или друг начин можем да сме сигурни, че установеното ниво на статистически разлики е максимално възможното за тези реални данни. Установихме с помощта на критерияλ точката на максимално разминаване между двете разпределения и именно в тази точка пробите бяха разделени на две части.
Вашата марка.
Използвайки този пример, ще разгледаме как се оценява надеждността на полученото регресионно уравнение. Същият тест се използва за проверка на хипотезата, че регресионните коефициенти са едновременно равни на нула, a=0, b=0. С други думи, същността на изчисленията е да се отговори на въпроса: може ли да се използва за по-нататъшни анализи и прогнози?
За да определите дали дисперсиите в две проби са подобни или различни, използвайте този t-тест.
И така, целта на анализа е да се получи някаква оценка, с която може да се твърди, че при определено ниво на α полученото регресионно уравнение е статистически надеждно. За това използва се коефициент на детерминация R 2.
Значимостта на регресионния модел се тества с помощта на F теста на Фишер, чиято изчислена стойност се намира като съотношението на дисперсията на първоначалната серия от наблюдения на изследвания индикатор и безпристрастната оценка на дисперсията на остатъчната последователност за тази модел.
Ако изчислената стойност с k 1 =(m) и k 2 =(n-m-1) степени на свобода е по-голяма от табличната стойност при дадено ниво на значимост, тогава моделът се счита за значим.
където m е броят на факторите в модела.
Статистическата значимост на сдвоената линейна регресия се оценява с помощта на следния алгоритъм:
1. Изложена е нулева хипотеза, че уравнението като цяло е статистически незначимо: H 0: R 2 =0 при ниво на значимост α.
2. След това определете действителната стойност на F-критерия: ![]()
![]()
където m=1 за регресия по двойки.
3. Табличната стойност се определя от таблиците за разпределение на Фишер за дадено ниво на значимост, като се има предвид, че броят на степените на свобода за общата сума на квадратите (по-голяма дисперсия) е 1, а броят на степените на свобода за остатъка е 1. сумата на квадратите (по-малка дисперсия) при линейна регресия е n-2 (или чрез функцията на Excel FRIST(вероятност,1,n-2)).
F таблица е максимално възможната стойност на критерия под въздействието на случайни фактори с дадени степени на свобода и ниво на значимост α. Нивото на значимост α е вероятността за отхвърляне на правилната хипотеза, при условие че е вярна. Обикновено α се приема за 0,05 или 0,01.
4. Ако действителната стойност на F-теста е по-малка от стойността на таблицата, тогава те казват, че няма причина да се отхвърли нулевата хипотеза.
В противен случай нулевата хипотеза се отхвърля и алтернативната хипотеза за статистическата значимост на уравнението като цяло се приема с вероятност (1-α).
Таблични стойности на критерия със степени на свобода k 1 =1 и k 2 =48, F таблица = 4
заключения: Тъй като действителната стойност F > F таблица, коефициентът на определяне е статистически значим ( получената оценка на регресионното уравнение е статистически надеждна) .
Дисперсионен анализ
.Индикатори за качество на регресионното уравнение
Пример. Въз основа на общо 25 търговски предприятия се изследва връзката между следните характеристики: X - цена на продукт А, хиляди рубли; Y е печалбата на търговско предприятие, милиони рубли. При оценката на регресионния модел са получени следните междинни резултати: ∑(y i -y x) 2 = 46000; ∑(y i -y avg) 2 = 138000. Какъв показател за корелация може да се определи от тези данни? Изчислете стойността на този индикатор въз основа на този резултат и като използвате F тест на Фишерправят заключения за качеството на регресионния модел.
Решение. От тези данни можем да определим емпиричното съотношение на корелация:  , където ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
, където ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
η 2 = 92 000/138000 = 0,67, η = 0,816 (0,7< η < 0.9 - связь между X и Y высокая).
F тест на Фишер: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0,67, F = 0,67/(1-0,67)x(25 - 1 - 1) = 46. F таблица (1; 23) = 4,27
Тъй като действителната стойност F > Ftable, намерената оценка на регресионното уравнение е статистически надеждна.
Въпрос: Какви статистики се използват за тестване на значимостта на регресионен модел?
Отговор: За значимостта на целия модел като цяло се използва F-статистика (тест на Фишер).
За да сравните две нормално разпределени популации, които нямат разлики в извадковите средни стойности, но има разлика в дисперсиите, използвайте Тест на Фишер. Действителният критерий се изчислява по формулата:
където числителят е по-голямата стойност на дисперсията на извадката, а знаменателят е по-малката. За да заключите надеждността на разликите между пробите, използвайте ОСНОВНИЯТ ПРИНЦИП
тестване на статистически хипотези. Критични точки за  се съдържат в таблицата. Нулевата хипотеза се отхвърля, ако действителната стойност
се съдържат в таблицата. Нулевата хипотеза се отхвърля, ако действителната стойност 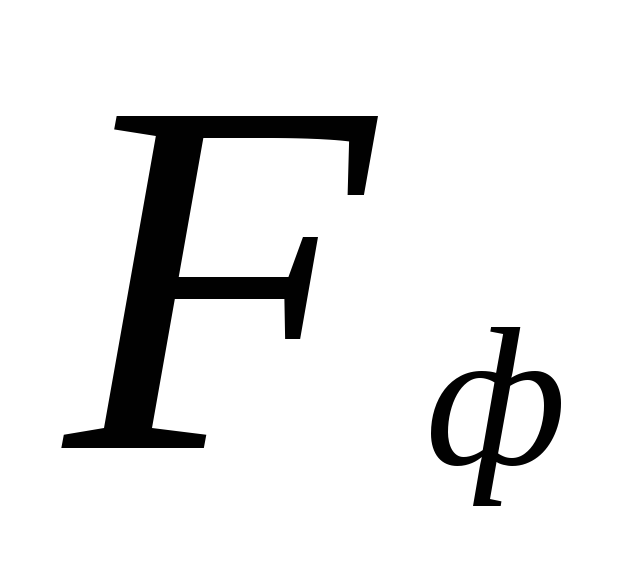 ще надвишава или е равна на критичната (стандартна) стойност
ще надвишава или е равна на критичната (стандартна) стойност  тази стойност за приетото ниво на значимост
и брой степени на свобода к
1
=
н
голям
-1
;
к
2
=
н
по-малък
-1
.
тази стойност за приетото ниво на значимост
и брой степени на свобода к
1
=
н
голям
-1
;
к
2
=
н
по-малък
-1
.
Пример: при изследване на ефекта на определено лекарство върху скоростта на покълване на семената се установи, че в опитната партида семена и контролата средната скорост на кълняемост е еднаква, но има разлика във отклоненията.  =1250,
=1250, =417. Размерите на извадката са еднакви и равни на 20.
=417. Размерите на извадката са еднакви и равни на 20. 
 =2,12. Следователно нулевата хипотеза се отхвърля.
=2,12. Следователно нулевата хипотеза се отхвърля.
Корелационна зависимост. Коефициент на корелация и неговите свойства. Регресионни уравнения.
ЗАДАЧАкорелационният анализ се свежда до:
Установяване посоката и формата на връзка между характеристиките;
Измерване на неговата плътност.
Функционален Недвусмислена връзка между променливи количества се нарича, когато определена стойност на една (независима) променлива х , наречен аргумент, съответства на определена стойност на друга (зависима) променлива при , наречена функция. ( Пример: зависимост на скоростта на химичната реакция от температурата; зависимост на силата на привличане от масите на привличащите се тела и разстоянието между тях).
Корелация е връзка между променливи, които са статистически по природа, когато определена стойност на една характеристика (разглеждана като независима променлива) съответства на цяла поредица от числени стойности на друга характеристика. ( Пример: връзка между реколтата и валежите; между ръст и тегло и др.).
Корелационно поле представлява набор от точки, чиито координати са равни на експериментално получени двойки променливи стойности х И при .
По вида на корелационното поле може да се прецени наличието или отсъствието на връзка и нейния тип.




Връзката се нарича положителен , ако когато една променлива се увеличава, друга променлива се увеличава.
Връзката се нарича отрицателен , ако когато една променлива нараства, друга променлива намалява.
Връзката се нарича линеен
, ако може да се представи аналитично като 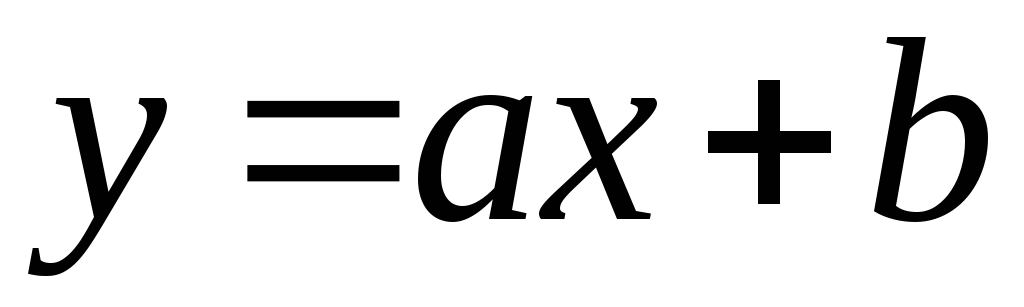 .
.
Индикатор за близостта на връзката е коефициент на корелация . Емпиричният коефициент на корелация се дава от:

Коефициентът на корелация варира от -1 преди 1 и характеризира степента на близост между количествата х И г . Ако:

Корелацията между характеристиките може да бъде описана по различни начини. По-специално, всяка форма на връзка може да бъде изразена чрез уравнение от общата форма 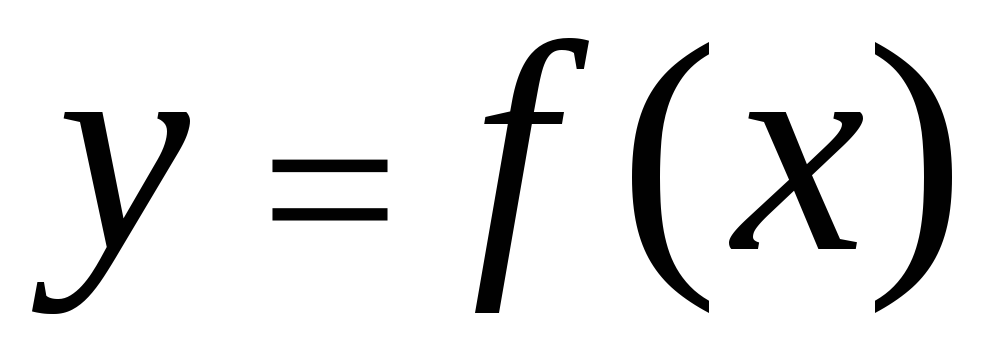 . Уравнение на формата
. Уравнение на формата  И
И 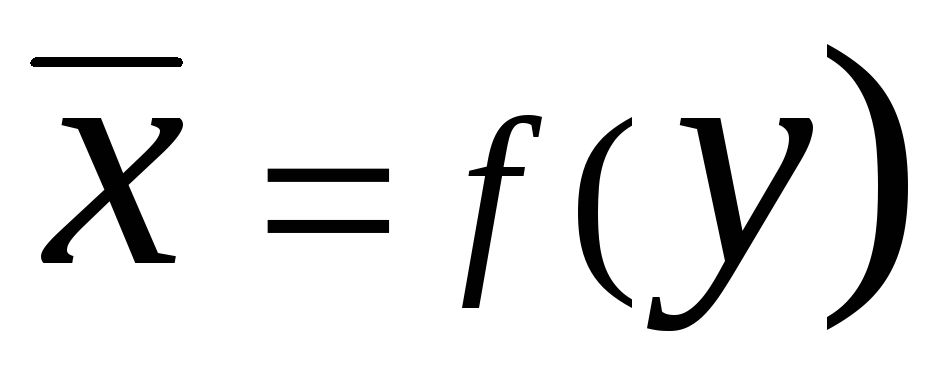 са наречени регресия
. Уравнение на предна регресия при
На х
в общия случай може да се запише във формата
са наречени регресия
. Уравнение на предна регресия при
На х
в общия случай може да се запише във формата

Уравнение на предна регресия х На при като цяло изглежда

Най-вероятните стойности на коефициента АИ V, сИ дможе да се изчисли, например, като се използва методът на най-малките квадрати.







