Fisher kriteri iki bağımsız örneğin örnek varyanslarını karşılaştırmanıza olanak tanır. F emp'yi hesaplamak için, iki örneğin varyanslarının oranını bulmanız gerekir; böylece daha büyük varyans payda ve daha küçük olan paydada olur. Fisher kriterini hesaplama formülü şöyledir:
sırasıyla birinci ve ikinci örneklerin varyansları nerededir?
Kriterin koşuluna göre payın değerinin paydanın değerinden büyük veya ona eşit olması gerektiğinden F emp değeri her zaman bire eşit veya büyük olacaktır.
Serbestlik derecesinin sayısı da basitçe belirlenir:
k 1 =n ben - 1 ilk örnek için (yani varyansı daha büyük olan örnek için) ve k 2 = N 2 - 1 ikinci örnek için.
Ek 1'de Fisher kriterinin kritik değerleri k 1 (tablonun üst satırı) ve k 2 (tablonun sol sütunu) değerleriyle bulunmaktadır.
Eğer t >t kritik ise sıfır hipotezi kabul edilir, aksi halde alternatif kabul edilir.
Örnek 3. Test iki üçüncü sınıfta gerçekleştirildi zihinsel gelişim 10 öğrenci TURMSH sınavına giriyor. Elde edilen ortalama değerler önemli ölçüde farklılık göstermedi, ancak psikolog, sınıflar arasında zihinsel gelişim göstergelerinin homojenlik derecesinde farklılıklar olup olmadığı sorusuyla ilgileniyor.
Çözüm. Fisher testi için her iki sınıftaki test puanlarının varyanslarının karşılaştırılması gerekir. Test sonuçları tabloda sunulmaktadır:
Tablo 3.
|
Öğrenci no. |
Birinci sınıf |
İkinci sınıf |
X ve Y değişkenlerinin varyanslarını hesapladıktan sonra şunu elde ederiz:
S X 2 =572,83; S sen 2 =174,04
Daha sonra, Fisher'in F kriterini kullanarak hesaplama için formül (8)'i kullanarak şunları buluruz:
![]()
Her iki durumda da serbestlik dereceleri k = 10 - 1 = 9'a eşit olan F kriteri için Ek 1'deki tabloya göre, F crit = 3,18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Parametrik olmayan testler
Araştırmacı, herhangi bir etkiden önceki ve sonraki sonuçları gözle (yüzde olarak) karşılaştırarak, eğer farklılıklar gözlemlenirse karşılaştırılan örneklerde bir fark olduğu sonucuna varır. Bu yaklaşım kategorik olarak kabul edilemez, çünkü yüzdeler için farkların güvenilirlik düzeyini belirlemek imkansızdır. Tek başına alınan yüzdeler istatistiksel olarak güvenilir sonuçlar çıkarmayı mümkün kılmaz. Herhangi bir müdahalenin etkinliğini kanıtlamak için göstergelerin yanlılığında (değişiminde) istatistiksel olarak anlamlı bir eğilimin belirlenmesi gerekir. Bu tür sorunları çözmek için bir araştırmacı bir takım ayrımcılık kriterlerini kullanabilir. Aşağıda parametrik olmayan testleri ele alacağız: işaret testi ve ki-kare testi.
Çoklu regresyon denkleminin bir bütün olarak önemi ve ikili regresyonda Fisher kriteri kullanılarak değerlendirilir:
 ,
(2.22)
,
(2.22)
Nerede  – serbestlik derecesi başına karelerin faktör toplamı;
– serbestlik derecesi başına karelerin faktör toplamı;  – serbestlik derecesi başına kalan kareler toplamı;
– serbestlik derecesi başına kalan kareler toplamı;  – çoklu belirleme katsayısı (indeks);
– çoklu belirleme katsayısı (indeks);  – değişkenler için parametre sayısı
– değişkenler için parametre sayısı  (Doğrusal regresyonda modele dahil edilen faktörlerin sayısıyla örtüşür);
(Doğrusal regresyonda modele dahil edilen faktörlerin sayısıyla örtüşür);  – gözlem sayısı.
– gözlem sayısı.
Sadece denklemin bir bütün olarak önemi değil, aynı zamanda regresyon modeline ek olarak dahil edilen faktör de değerlendirilir. Böyle bir değerlendirmeye duyulan ihtiyaç, modele dahil edilen her faktörün, ortaya çıkan özellikteki açıklanan varyasyon oranını önemli ölçüde artıramamasından kaynaklanmaktadır. Ayrıca modelde birden fazla faktör varsa bunlar modele farklı sıralarla girilebilir. Faktörler arasındaki korelasyon nedeniyle, aynı faktörün önemi, modele dahil edilme sırasına bağlı olarak farklı olabilir. Bir faktörün modele dahil edilmesini değerlendirmenin ölçüsü özeldir.  -kriter, yani
-kriter, yani  .
.
Özel  -kriter, bir bütün olarak regresyon modeli için, ilave olarak dahil edilen bir faktörün etkisi nedeniyle faktör varyansındaki artışın, bir serbestlik derecesi başına artık varyansla karşılaştırılmasına dayanmaktadır. Faktör için genel anlamda
-kriter, bir bütün olarak regresyon modeli için, ilave olarak dahil edilen bir faktörün etkisi nedeniyle faktör varyansındaki artışın, bir serbestlik derecesi başına artık varyansla karşılaştırılmasına dayanmaktadır. Faktör için genel anlamda  özel
özel  -kriter şu şekilde belirlenecektir:
-kriter şu şekilde belirlenecektir:
 ,
(2.23)
,
(2.23)
Nerede  – tam bir faktör setine sahip bir model için çoklu belirleme katsayısı,
– tam bir faktör setine sahip bir model için çoklu belirleme katsayısı,  – aynı gösterge ancak faktörü modele dahil etmeden
– aynı gösterge ancak faktörü modele dahil etmeden  ,
, – gözlem sayısı,
– gözlem sayısı,  – modeldeki parametre sayısı (serbest terim olmadan).
– modeldeki parametre sayısı (serbest terim olmadan).
Bölümün gerçek değeri  - kriter anlamlılık düzeyinde tabloyla karşılaştırılır
- kriter anlamlılık düzeyinde tabloyla karşılaştırılır  ve serbestlik derecesi sayısı: 1 ve
ve serbestlik derecesi sayısı: 1 ve  . Gerçek değer ise
. Gerçek değer ise  aşar
aşar  , daha sonra faktörün ilave dahil edilmesi
, daha sonra faktörün ilave dahil edilmesi  modele istatistiksel olarak doğrulanmıştır ve saf regresyon katsayısı
modele istatistiksel olarak doğrulanmıştır ve saf regresyon katsayısı  faktörde
faktörde  istatistiksel olarak anlamlı. Gerçek değer ise
istatistiksel olarak anlamlı. Gerçek değer ise  Tablo değerinden küçükse, faktörün modele ek olarak dahil edilmesi
Tablo değerinden küçükse, faktörün modele ek olarak dahil edilmesi  bir özellikteki açıklanan varyasyonun oranını önemli ölçüde artırmaz
bir özellikteki açıklanan varyasyonun oranını önemli ölçüde artırmaz  bu nedenle modele dahil edilmesi uygun değildir; Bu durumda bu faktörün regresyon katsayısı istatistiksel olarak anlamsızdır.
bu nedenle modele dahil edilmesi uygun değildir; Bu durumda bu faktörün regresyon katsayısı istatistiksel olarak anlamsızdır.
İki faktörlü bir denklem için bölümler  -kriterler şu şekildedir:
-kriterler şu şekildedir:
 ,
, . (2.23a)
. (2.23a)
Özel kullanma  -kriter, her bir ilgili faktörün geçerli olduğu varsayımı altında tüm regresyon katsayılarının önemi kontrol edilebilir.
-kriter, her bir ilgili faktörün geçerli olduğu varsayımı altında tüm regresyon katsayılarının önemi kontrol edilebilir.  Çoklu regresyon denklemine en son girildi.
Çoklu regresyon denklemine en son girildi.
-Çoklu regresyon denklemi için öğrenci testi.
Özel  -kriter saf regresyon katsayılarının anlamlılığını değerlendirir. Büyüklüğünü bilmek
-kriter saf regresyon katsayılarının anlamlılığını değerlendirir. Büyüklüğünü bilmek  belirlemek mümkündür
belirlemek mümkündür  - regresyon katsayısı için kriter
- regresyon katsayısı için kriter  -m faktörü,
-m faktörü,  , yani:
, yani:
 .
(2.24)
.
(2.24)
Saf regresyon katsayılarının öneminin değerlendirilmesi  -Student's t-testi kısmi hesaplama yapılmadan yapılabilir
-Student's t-testi kısmi hesaplama yapılmadan yapılabilir  -kriterler. Bu durumda ikili regresyonda olduğu gibi her faktör için formül kullanılır:
-kriterler. Bu durumda ikili regresyonda olduğu gibi her faktör için formül kullanılır:
 ,
(2.25)
,
(2.25)
Nerede  – faktördeki saf regresyon katsayısı
– faktördeki saf regresyon katsayısı  ,
, – regresyon katsayısının ortalama kare (standart) hatası
– regresyon katsayısının ortalama kare (standart) hatası  .
.
Çoklu regresyon denklemi için regresyon katsayısının ortalama kare hatası aşağıdaki formülle belirlenebilir:
 ,
(2.26)
,
(2.26)
Nerede 
 ,
, – karakteristik için standart sapma
– karakteristik için standart sapma  ,
, – çoklu regresyon denkleminin belirleme katsayısı,
– çoklu regresyon denkleminin belirleme katsayısı,  – faktörün bağımlılığı için belirleme katsayısı
– faktörün bağımlılığı için belirleme katsayısı  çoklu regresyon denklemindeki diğer tüm faktörlerle;
çoklu regresyon denklemindeki diğer tüm faktörlerle;  – sapmaların karelerinin kalan toplamı için serbestlik derecesi sayısı.
– sapmaların karelerinin kalan toplamı için serbestlik derecesi sayısı.
Gördüğünüz gibi, bu formülü kullanmak için faktörler arası korelasyon matrisine ve bunu kullanarak karşılık gelen belirleme katsayılarının hesaplanmasına ihtiyacınız var.  . Yani denklem için
. Yani denklem için  Regresyon katsayılarının öneminin değerlendirilmesi
Regresyon katsayılarının öneminin değerlendirilmesi  ,
, ,
, üç faktör arası belirleme katsayısının hesaplanmasını içerir:
üç faktör arası belirleme katsayısının hesaplanmasını içerir:  ,
, ,
, .
.
Kısmi korelasyon katsayısı göstergeleri arasındaki ilişki, kısmi  -kriterler ve
-kriterler ve  - Faktör seçimi prosedüründe saf regresyon katsayıları için Öğrenci t testi kullanılabilir. Eleme yöntemiyle bir regresyon denklemi oluştururken faktörlerin ortadan kaldırılması, pratik olarak yalnızca kısmi korelasyon katsayılarıyla değil, her adımda kısmi korelasyon katsayısının en küçük önemsiz değerine sahip faktörü hariç tutarak, aynı zamanda değerlerle de gerçekleştirilebilir.
- Faktör seçimi prosedüründe saf regresyon katsayıları için Öğrenci t testi kullanılabilir. Eleme yöntemiyle bir regresyon denklemi oluştururken faktörlerin ortadan kaldırılması, pratik olarak yalnızca kısmi korelasyon katsayılarıyla değil, her adımda kısmi korelasyon katsayısının en küçük önemsiz değerine sahip faktörü hariç tutarak, aynı zamanda değerlerle de gerçekleştirilebilir.  Ve
Ve  .
Özel
.
Özel  -kriter, değişkenleri dahil etme yöntemini ve aşamalı regresyon yöntemini kullanarak bir model oluştururken yaygın olarak kullanılır.
-kriter, değişkenleri dahil etme yöntemini ve aşamalı regresyon yöntemini kullanarak bir model oluştururken yaygın olarak kullanılır.
φ* kriterinin hesaplanması
1. Konuları "etkisi olan" ve "etkisi olmayan" olarak ayırmanın kriteri olacak özelliğin değerlerini belirleyin. Karakteristik niceliksel olarak ölçülüyorsa, en uygun ayırma noktasını bulmak için λ kriterini kullanın.
2. İki sütun ve iki satırdan oluşan dört hücreli (eşanlamlı: dört alanlı) bir tablo çizin. İlk sütun “bir etkisi var”; ikinci sütun - “etkisi yok”; üstten ilk satır - 1 grup (örnek); ikinci satır - grup 2 (örnek).
4. İlk örnekte "etkisi olmayan" deneklerin sayısını sayın ve bu sayıyı tablonun sağ üst hücresine girin. İlk iki hücrenin toplamını hesaplayın. İlk gruptaki denek sayısıyla örtüşmelidir.
6. İkinci örnekte "etkisi olmayan" deneklerin sayısını sayın ve bu sayıyı tablonun sağ alt hücresine girin. Alttaki iki hücrenin toplamını hesaplayın. İkinci gruptaki (örneklem) denek sayısıyla örtüşmelidir.
7. Sayılarını belirli bir gruptaki (örneklem) toplam konu sayısıyla ilişkilendirerek "etkisi olan" konuların yüzdesini belirleyin. Elde edilen yüzdeleri mutlak değerlerle karıştırmamak için sırasıyla tablonun sol üst ve sol alt hücrelerine parantez içinde yazın.
8. Karşılaştırılan yüzdelerden birinin sıfıra eşit olup olmadığını kontrol edin. Durum buysa, grup ayırma noktasını bir yönde veya başka bir yönde hareket ettirerek bunu değiştirmeye çalışın. Eğer bu mümkün değilse veya istenmiyorsa, φ* kriterini terk edin ve χ2 kriterini kullanın.
9. Tabloya göre belirleyin. XII Ek 1, karşılaştırılan yüzdelerin her biri için φ açıları.
burada: φ1 - daha büyük yüzdeye karşılık gelen açı;
φ2 - daha küçük yüzdeye karşılık gelen açı;
N1 - örnek 1'deki gözlem sayısı;
N2 - örnek 2'deki gözlem sayısı.
11. Elde edilen φ* değerini kritik değerlerle karşılaştırın: φ* ≤1,64 (p<0,05) и φ* ≤2,31 (р<0,01).
Eğer φ*emp ≤φ*cr ise. H0 reddedilir.
Gerekirse, ortaya çıkan φ*emp'nin kesin önem düzeyini Tabloya göre belirleyin. XIII Ek 1.
Bu yöntem birçok kılavuzda açıklanmaktadır (Plokhinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992, vb.). Bu açıklama, yöntemin E.V. tarafından geliştirilen ve sunulan versiyonuna dayanmaktadır. Gubler.
Kriterin amacı φ*
Fisher kriteri, araştırmacının ilgisini çeken etkinin (göstergenin) ortaya çıkma sıklığına göre iki örneği karşılaştırmayı amaçlamaktadır. Ne kadar büyük olursa, farklar o kadar güvenilir olur.
Kriterin açıklaması
Kriter, bizi ilgilendiren etkinin (göstergenin) kaydedildiği iki numunenin yüzdeleri arasındaki farkların güvenilirliğini değerlendirir. Mecazi anlamda konuşursak, 2 pastadan kesilen en iyi 2 parçayı karşılaştırırız ve hangisinin gerçekten daha büyük olduğuna karar veririz.
Fisher açısal dönüşümünün özü, yüzdeleri radyan cinsinden ölçülen merkezi açı değerlerine dönüştürmektir. Daha büyük bir yüzde, daha büyük bir φ açısına karşılık gelir ve daha küçük bir yüzde, daha küçük bir açıya karşılık gelir, ancak buradaki ilişkiler doğrusal değildir:
burada P, bir birimin kesirleri cinsinden ifade edilen yüzdedir (bkz. Şekil 5.1).
φ açıları arasındaki farkın artmasıyla 1 ve φ 2 ve örneklem sayısı arttıkça kriterin değeri artar. φ* değeri ne kadar büyükse, farkların anlamlı olma olasılığı da o kadar yüksektir.
hipotezler
H 0 : Kişilerin oranı, Çalışılan etkinin kendini gösterdiği durumda, numune 1'de numune 2'den daha fazlası yoktur.
H 1 : Çalışılan etkiyi sergileyen bireylerin oranı örnek 1'de örnek 2'ye göre daha fazladır.
Kriterin grafiksel gösterimi φ*
Açısal dönüşüm yöntemi diğer kriterlere göre biraz daha soyuttur.
E.V. Gubler'in φ değerlerini hesaplarken izlediği formül,% 100'ün φ=3.142 açısını, yani yuvarlanmış bir π=3.14159 değerini oluşturduğunu varsayar... Bu, karşılaştırılan örnekleri şu şekilde sunmamızı sağlar: her biri örnekleminin popülasyonunun %100'ünü simgeleyen iki yarım daire. “Etki”ye sahip konuların yüzdeleri, φ merkez açılarının oluşturduğu sektörler olarak temsil edilecektir. İncirde. Şekil 5.2, Örnek 1'i gösteren iki yarım daireyi göstermektedir. İlk örnekte deneklerin %60'ı sorunu çözmüştür. Bu yüzde φ=1.772 açısına karşılık gelir. İkinci örnekte deneklerin %40'ı sorunu çözdü. Bu yüzde φ =1,369 açısına karşılık gelir.
φ* kriteri, belirli örnek boyutları için açılardan birinin diğerine göre gerçekten istatistiksel olarak önemli ölçüde üstün olup olmadığını belirlemenize olanak tanır.
Kriterin sınırlamaları φ*
1. Karşılaştırılan oranların hiçbiri sıfır olmamalıdır. Resmi olarak, örneklerden birindeki gözlem oranının 0'a eşit olduğu durumlarda φ yönteminin uygulanmasında herhangi bir engel yoktur. Ancak bu durumlarda, sonuç haksız yere şişirilmiş olabilir (Gubler E.V., 1978, s. .86).
2. Üst φ kriterinde herhangi bir sınır yoktur; örnekler istenildiği kadar büyük olabilir.
Daha düşük limit - numunelerden birinde 2 gözlem. Ancak iki numune sayısında aşağıdaki oranlara dikkat edilmelidir:
a) bir numunenin yalnızca 2 gözlemi varsa, ikincisinin en az 30 gözlemi olmalıdır:
b) eğer numunelerden birinde yalnızca 3 gözlem varsa, ikincisi en az 7 gözleme sahip olmalıdır:
c) eğer numunelerden birinde yalnızca 4 gözlem varsa, ikincisi en az 5 gözleme sahip olmalıdır:
d) enN 1 , N 2 ≥ 5 Her türlü karşılaştırma mümkündür.
Prensip olarak bu koşulu karşılamayan örnekleri örneğin şu ilişkiyle karşılaştırmak da mümkündür:N 1 =2, N 2 = 15, ancak bu durumlarda önemli farklılıkları tespit etmek mümkün olmayacaktır.
φ* kriterinin başka bir kısıtlaması yoktur.
Olasılıkları göstermek için birkaç örneğe bakalımkriter φ*.
Örnek 1: numunelerin niteliksel olarak tanımlanmış bir özelliğe göre karşılaştırılması.
Örnek 2: numunelerin niceliksel olarak ölçülen bir özelliğe göre karşılaştırılması.
Örnek 3: Örneklerin bir özelliğin hem düzeyine hem de dağılımına göre karşılaştırılması.
Örnek 4: φ* kriterinin kriterle birlikte kullanılmasıX En doğru sonuca ulaşmak için Kolmogorov-Smirnov.
Örnek 1 - numunelerin niteliksel olarak belirlenmiş bir özelliğe göre karşılaştırılması
Kriterin bu kullanımında, bir örnekteki belirli bir kaliteyle karakterize edilen deneklerin yüzdesini, başka bir örnekteki aynı kaliteyle karakterize edilen deneklerin yüzdesiyle karşılaştırırız.
Diyelim ki iki öğrenci grubunun yeni bir deneysel problemi çözmedeki başarıları açısından farklılık gösterip göstermediğiyle ilgileniyoruz. 20 kişilik ilk grupta 12 kişi sorunla başa çıktı, 25 kişilik ikinci örneklemde ise - 10. İlk durumda sorunu çözenlerin yüzdesi 12/20·100%=%60 olacaktır, ve ikincide %10/25·100= %40. Verilere göre bu yüzdeler önemli ölçüde farklılık gösteriyor mu?N 1 VeN 2 ?
Görünüşe göre "gözle" bile% 60'ın% 40'tan önemli ölçüde yüksek olduğu belirlenebilir. Ancak aslında veriler göz önüne alındığında bu farklılıklarN 1 , N 2 güvenilmez.
Hadi kontrol edelim. Bir problemi çözme olgusuyla ilgilendiğimiz için, deneysel bir problemi çözmedeki başarıyı bir “etki” olarak, çözmedeki başarısızlığı ise bir etkinin yokluğu olarak değerlendireceğiz.
Hipotezleri formüle edelim.
H 0 : Kişilerin oranıBirinci grupta görevi tamamlayanların sayısı ikinci grupta olduğundan daha fazla değildi.
H 1 : Birinci grupta görevi tamamlayanların oranı ikinci gruba göre daha fazladır.
Şimdi, aslında özelliğin iki değeri için ampirik frekansların bir tablosu olan dört hücreli veya dört alanlı bir tablo oluşturalım: "bir etki var" - "etki yok."
Tablo 5.1
Sorunu çözenlerin yüzdesine göre iki denek grubunu karşılaştırırken kriteri hesaplamak için dört hücreli tablo.
Gruplar | “Bir etkisi var”: sorun çözüldü | "Etkisi yok": sorun çözülmedi | Tutarlar |
||||
Miktar konular | % paylaşmak | Miktar konular | % paylaşmak | ||||
1 grup | (60%) | (40%) | |||||
2. grup | (40%) | (60%) | |||||
Tutarlar | |||||||
Dört hücreli bir tabloda, kural olarak, "Etki var" ve "Etki yok" sütunları üstte, "Grup 1" ve "Grup 2" satırları solda işaretlenir. Aslında karşılaştırmalarda yalnızca A ve B alanları (hücreleri) yer alır, yani “Etki var” sütunundaki yüzdeler.
Tabloya göre.XIIEk 1, grupların her birindeki yüzdesel paylara karşılık gelen φ değerlerini belirler.
Şimdi aşağıdaki formülü kullanarak φ*'nin ampirik değerini hesaplayalım:
nerede φ 1 - daha büyük % paya karşılık gelen açı;
φ 2 - daha küçük % paya karşılık gelen açı;
N 1 - örnek 1'deki gözlem sayısı;
N 2 - örnek 2'deki gözlem sayısı.
Bu durumda:
Tabloya göre.XIIIEk 1'de φ*'ya hangi önem düzeyinin karşılık geldiğini belirliyoruz onları=1,34:
p=0,09
Psikolojide kabul edilen istatistiksel anlamlılık düzeylerine karşılık gelen φ*'nin kritik değerlerini belirlemek de mümkündür:
Bir "önem ekseni" oluşturalım.
Elde edilen ampirik değer φ* anlamsızlık bölgesindedir.
Cevap: H 0 kabul edilmiş. Görevi tamamlayan kişilerin yüzdesiVbirinci grupta ikinci gruptan daha fazla değil.
Yalnızca %20 ve hatta %10'luk farklılıkları φ* kriterini kullanarak güvenilirliklerini kontrol etmeden anlamlı bulan bir araştırmacıya sempati duyulabilir. Bu durumda örneğin yalnızca en az %24,3'lük farklar anlamlı olacaktır.
Görünüşe göre iki örneği herhangi bir niteliksel temelde karşılaştırırken φ kriteri bizi mutlu etmekten çok üzebilir. Önemli görünen bir şey istatistiksel açıdan öyle olmayabilir.
Fisher kriteri, iki örneği niceliksel olarak ölçülen özelliklere göre karşılaştırdığımızda araştırmacıyı memnun etmek için çok daha fazla fırsata sahiptir ve "etkiyi" çeşitlendirebilir.
Örnek 2 - iki numunenin niceliksel olarak ölçülen bir özelliğe göre karşılaştırılması
Kriterin bu kullanımında, bir örnekte belirli bir nitelik değeri düzeyine ulaşan deneklerin yüzdesini, başka bir örnekte bu düzeye ulaşan deneklerin yüzdesiyle karşılaştırırız.
G. A. Tlegenova (1990) tarafından yapılan bir çalışmada, 14-16 yaşlarındaki 70 genç meslek okulu öğrencisinden, Saldırganlık ölçeğinde yüksek puana sahip 10 konu ve Saldırganlık ölçeğinde düşük puana sahip 11 konu, sonuçlara göre seçilmiştir. Freiburg Kişilik Anketi kullanılarak yapılan bir anket. Saldırgan ve saldırgan olmayan genç erkek gruplarının, bir öğrenci arkadaşıyla yaptıkları sohbette kendiliğinden seçtikleri mesafe açısından farklılık gösterip göstermediğini belirlemek gerekir. G. A. Tlegenova'nın verileri Tablo'da sunulmaktadır. 5.2. Agresif genç erkeklerin daha çok 50 metrelik bir mesafeyi seçtiklerini fark edebilirsiniz.cm veya daha azken, saldırgan olmayan erkek çocuklar daha çok 50 cm'den daha büyük bir mesafeyi seçerler.
Artık 50 cm'lik mesafeyi kritik olarak değerlendirebilir ve eğer öznenin seçtiği mesafe 50 cm'den küçük veya ona eşitse "bir etki vardır", seçilen mesafe 50 cm'den büyükse o zaman "bir etki vardır" diye varsayabiliriz. "Hiçbir etkisi yok." Saldırgan genç erkeklerden oluşan grupta bu etkinin 10 üzerinden 7'sinde, yani vakaların %70'inde, saldırgan olmayan genç erkekler grubunda ise 11'den 2'sinde, yani vakaların %18,2'sinde gözlemlendiğini görüyoruz. . Bu yüzdeler, aralarındaki farkların önemini belirlemek için φ* yöntemi kullanılarak karşılaştırılabilir.
Tablo 5.2
Agresif ve agresif olmayan genç erkeklerin bir öğrenci arkadaşıyla yaptığı konuşmada seçilen mesafe göstergeleri (cm cinsinden) (G.A. Tlegenova'ya göre, 1990)
Grup 1: Saldırganlık ölçeğinde yüksek puan alan erkeklerFPI- R (N 1 =10) | Grup 2: Saldırganlık ölçeğinde düşük değerlere sahip erkeklerFPI- R (N 2 =11) |
|||
d(c M ) | % paylaşmak | d(c M ) | % paylaşmak |
|
"Yemek yemek Etki" D≤50cm | ||||
18,2% |
||||
"HAYIR etki" d>50 santimetre | ||||
80 QO | 81,8% |
|||
Tutarlar | 100% | 100% |
||
Ortalama | 5b:o | 77.3 | ||
Hipotezleri formüle edelim.
H 0 D ≤ 50 cm, saldırgan erkek çocuklardan oluşan grupta, saldırgan olmayan erkek çocuklardan oluşan gruptan daha fazlası yoktur.
H 1 : Mesafeyi seçenlerin oranıD≤ 50 cm, saldırgan genç erkeklerden oluşan grupta, saldırgan olmayan genç erkeklerden oluşan gruba göre daha fazla. Şimdi dört hücreli bir tablo oluşturalım.
Tablo 53
Agresif () gruplarını karşılaştırırken φ* kriterini hesaplamak için dört hücreli tablonf=10) ve saldırgan olmayan genç erkekler (n2=11)
Gruplar | "Bir etkisi var": D≤50 | "Etkisi yok." D>50 | Tutarlar |
||||
Konu sayısı | (% paylaşmak) | Konu sayısı | (% paylaşmak) | ||||
Grup 1 - agresif genç erkekler | (70%) | (30%) | |||||
Grup 2 - saldırgan olmayan genç erkekler | (180%) | (81,8%) | |||||
Toplam | |||||||
Tabloya göre.XIIEk 1, grupların her birindeki “etkinin” yüzde paylarına karşılık gelen φ değerlerini belirler.
Elde edilen ampirik değer φ* anlamlılık bölgesindedir.
Cevap: H 0 Reddedilmiş. Kabul edilmişH 1 . Konuşma mesafesini 50 cm'ye eşit veya daha az seçenlerin oranı, saldırgan genç erkeklerden oluşan grupta, saldırgan olmayan genç erkeklerden oluşan gruba göre daha fazladır.
Elde edilen sonuçlara dayanarak, daha saldırgan genç erkeklerin daha çok yarım metreden daha kısa bir mesafeyi seçtikleri, saldırgan olmayan genç erkeklerin ise daha çok yarım metreden daha büyük bir mesafeyi seçtikleri sonucuna varabiliriz. Agresif genç erkeklerin aslında mahrem bölge (0-46 cm) ile kişisel bölge (46 cm arası) arasındaki sınırda iletişim kurduğunu görüyoruz. Bununla birlikte, partnerler arasındaki yakın mesafenin yalnızca yakın ve iyi ilişkilerin değil, aynı zamandaVegöğüs göğüse çarpışma (Salone. T., 1959).
Örnek 3 - örneklerin hem seviyeye hem de özelliğin dağılımına göre karşılaştırılması.
Bu kullanım durumunda, öncelikle grupların bazı özelliklerin düzeyleri açısından farklılık gösterip göstermediğini test edebilir ve ardından özelliğin iki örnekteki dağılımlarını karşılaştırabiliriz. Böyle bir görev, herhangi bir yeni teknik kullanılarak deneklerin elde ettiği değerlendirmelerin dağılım şekli veya aralıklarındaki farklılıkları analiz ederken uygun olabilir.
R. T. Chirkina (1995) tarafından yapılan bir çalışmada ilk kez kişisel, ailevi ve mesleki kompleksler nedeniyle gerçekleri, isimleri, niyetleri ve eylem yöntemlerini hafızadan bastırma eğilimini belirlemeyi amaçlayan bir anket kullanıldı. Anket, E.V. Sidorenko'nun katılımıyla 3. Freud "Gündelik Yaşamın Psikopatolojisi" kitabındaki materyallere dayanarak oluşturuldu. Pedagoji Enstitüsü'nün 17-20 yaşları arasındaki bekar, çocuksuz 50 öğrencisinden oluşan bir örneklem, bu anketin yanı sıra kişisel yetersizlik duygusunun yoğunluğunu belirlemek için Menester-Corzini tekniği kullanılarak incelendi,veya"aşağılık kompleksi" (MüdürG. J., CorsiniR. J., 1982).
Anket sonuçları Tabloda sunulmaktadır. 5.4.
Anket kullanılarak teşhis edilen bastırma enerjisi göstergesi ile kişinin kendi yetersizlik duygusunun yoğunluğu göstergeleri arasında anlamlı bir ilişki olduğunu söylemek mümkün müdür?
Tablo 5.4
Yüksek öğrenci gruplarında kişisel yetersizlik duygularının yoğunluğunun göstergeleri (nj=18) ve düşük (n2=24) yer değiştirme enerjisi
Grup 1: 19'dan 31 noktaya kadar yer değiştirme enerjisi (N 1 =181 | Grup 2: 7'den 13 noktaya kadar yer değiştirme enerjisi (N 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
Tutarlar Ortalama | 26,11 | 15,42 |
Enerjik baskının daha fazla olduğu grupta ortalama değer daha yüksek olmasına rağmen içinde 5 sıfır değeri de gözlenmektedir. İki örnekteki derecelendirme dağılımının histogramlarını karşılaştırırsak aralarında çarpıcı bir kontrast ortaya çıkar (Şekil 5.3).
İki dağılımı karşılaştırmak için testi uygulayabilirizχ 2 veya kriterλ , ancak bunun için her iki örnekte de sıraları genişletmemiz gerekirdi.N <30.
Yetersizlik duygusu göstergesinin çok düşük (0) alması veya tam tersi olması durumunda “bir etkinin var” olduğunu varsaymayı kabul edersek, φ* kriteri grafikte gözlemlenen iki dağılım arasındaki tutarsızlığın etkisini kontrol etmemizi sağlayacaktır. , çok yüksek değerler (S30) ve yetersizlik duygusu göstergesinin 5'ten 25'e kadar ortalama değerler alması durumunda "hiçbir etkisi yoktur".
Hipotezleri formüle edelim.
H 0 : Enerjik baskının daha fazla olduğu grupta eksiklik indeksinin aşırı değerleri (0 veya 30 veya daha fazla), enerjik baskının daha az olduğu gruptan daha yaygın değildir.
H 1 : Enerjik baskının daha fazla olduğu grupta eksiklik indeksinin uç değerleri (0 veya 30 veya daha fazla), enerjik baskının daha az olduğu gruba göre daha yaygındır.
φ* kriterinin daha ileri düzeyde hesaplanmasına uygun dört hücreli bir tablo oluşturalım.
Tablo 5.5
Yetersizlik göstergelerinin oranına göre daha yüksek ve daha düşük bastırma enerjilerine sahip grupları karşılaştırırken φ* kriterini hesaplamak için dört hücreli tablo
Gruplar | “Etkisi var”: eksiklik göstergesi 0 veya >30 | “Etkisi yok”: başarısızlık endeksi 5'ten 25'e | Tutarlar |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
Tutarlar | |||||
Tabloya göre.XIIEk 1'de karşılaştırılan yüzdelere karşılık gelen φ değerlerini belirliyoruz:
φ*:'nin ampirik değerini hesaplayalım.
Herhangi biri için kritik φ* değerleriN 1 , N 2 Önceki örnekten hatırladığımız gibi:
MasaXIIIEk 1, elde edilen sonucun önem düzeyini daha doğru bir şekilde belirlememizi sağlar: p<0,001.
Cevap: H 0 Reddedilmiş. Kabul edilmişH 1 . Daha fazla bastırma enerjisi olan grupta eksiklik indeksinin uç değerleri (0 veya 30 veya daha fazla), daha az bastırma enerjisi olan gruba göre daha sık görülür.
Dolayısıyla, daha fazla bastırma enerjisi olan denekler, kendi yetersizlik hissine ilişkin hem çok yüksek (30 ya da daha fazla) hem de çok düşük (sıfır) göstergelere sahip olabilirler. Hem tatminsizliklerini hem de yaşamdaki başarı ihtiyacını bastırdıkları varsayılabilir. Bu varsayımların daha fazla test edilmesi gerekmektedir.
Elde edilen sonuç, yorumuna bakılmaksızın, φ* kriterinin iki örnekteki bir özelliğin dağılım şeklindeki farklılıkları değerlendirmedeki yeteneklerini doğrulamaktadır.
Orijinal örneklemde 50 kişi vardı ancak bunlardan 8'i, bastırma anerji indeksinde ortalama puana sahip olduğundan (14-15) değerlendirme dışı bırakıldı. Yetersizlik duygularının yoğunluğuna ilişkin göstergeleri de ortalamadır: her biri 20 puanlık 6 değer ve her biri 25 puanlık 2 değer.
φ* kriterinin güçlü yetenekleri, bu örneğin materyalleri analiz edilirken tamamen farklı bir hipotezin doğrulanmasıyla doğrulanabilir. Örneğin, daha fazla bastırma enerjisi olan bir grupta, bu gruptaki dağılımının paradoksal doğasına rağmen, yetersizlik oranının hala daha yüksek olduğunu kanıtlayabiliriz.
Yeni hipotezler formüle edelim.
H 0 Daha fazla bastırma enerjisi olan grupta eksiklik indeksinin en yüksek değerleri (30 veya daha fazla), daha az bastırma enerjisi olan gruba göre daha yaygın değildir.
H 1 : Daha fazla bastırma enerjisi olan grupta eksiklik indeksinin en yüksek değerleri (30 veya daha fazla), daha az bastırma enerjisi olan gruba göre daha sık ortaya çıkar. Tablodaki verileri kullanarak dört alanlı bir tablo oluşturalım. 5.4.
Tablo 5.6
Yetersizlik göstergesi düzeyine göre daha fazla ve daha az bastırma enerjisine sahip grupları karşılaştırırken φ* kriterini hesaplamak için dört hücreli tablo
Gruplar | “Bir etkisi var”* arıza göstergesi 30'dan büyük veya eşittir | “Etki yok”: başarısızlık oranı daha düşüktür 30 | Tutarlar |
||
Grup 1 - daha büyük yer değiştirme enerjisine sahip | (61,1%) | (38.9%) | |||
Grup 2 - daha düşük yer değiştirme enerjili | (25.0%) | (75.0%) | |||
Tutarlar | |||||
Tabloya göre.XIIIEk 1'de bu sonucun p = 0,008 anlamlılık düzeyine karşılık geldiğini tespit ettik.
Cevap: Ama reddediliyor. Kabul edilmişHj: Gruptaki en yüksek eksiklik göstergeleri (30 veya daha fazla puan)İledaha büyük yer değiştirme enerjisine sahip grup, daha az yer değiştirme enerjisine sahip gruba göre daha sık meydana gelir (p = 0,008).
Yani bunu kanıtlayabildikVgrupİledaha enerjik baskılamayla birlikte yetersizlik göstergesinin uç değerlerinin ağır basması ve bu göstergenin değerlerini aşmasıulaşırtam da bu grupta.
Şimdi, daha yüksek baskı enerjisi olan grupta, ortalama değerin daha yüksek olmasına rağmen, yetersizlik indeksinin daha düşük değerlerinin daha yaygın olduğunu kanıtlamaya çalışabiliriz.V bu grupta daha fazlası var (grupta 26,11'e karşı 15,42)İle daha az yer değiştirme).
Hipotezleri formüle edelim.
H 0 : Gruptaki en düşük eksiklik oranları (sıfır)İle Daha fazla enerji içeren baskılar gruptakinden daha yaygın değildirİle daha az yer değiştirme enerjisi.
H 1 : En düşük eksiklik oranları (sıfır) meydana gelirV daha fazla bastırma enerjisine sahip grup, gruba göre daha sıkİle daha az enerjik baskı. Verileri yeni bir dört hücreli tabloda gruplayalım.
Tablo 5.7
Eksiklik göstergesinin sıfır değerlerinin sıklığına göre farklı baskı enerjilerine sahip grupları karşılaştırmak için dört hücreli tablo
Gruplar | "Bir etki var": arıza göstergesi 0'dır | Yetersizliğin "etkisi yok" | gösterge 0'a eşit değil | Tutarlar |
|
Grup 1 - daha büyük yer değiştirme enerjisine sahip | (27,8%) | (72,2%) | |||
1 grup - daha az yer değiştirme enerjisine sahip | (8,3%) | (91,7%) | |||
Tutarlar | |||||
φ değerlerini belirliyoruz ve φ* değerini hesaplıyoruz:
Cevap: H 0 Reddedilmiş. Daha fazla bastırma enerjisi olan gruptaki en düşük yetersizlik indeksleri (sıfır), daha az bastırma enerjisi olan gruba göre daha yaygındır (p<0,05).
Toplamda elde edilen sonuçlar, S. Freud ve A. Adler'deki kompleks kavramlarının kısmen örtüştüğünün kanıtı olarak değerlendirilebilir.
Örneklem genelinde bastırma enerjisi göstergesi ile kişinin kendi yetersizlik duygusunun yoğunluğu göstergesi arasında pozitif doğrusal bir korelasyon elde edilmesi anlamlıdır (p = +0,491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Örnek 4 - φ* kriterinin kriterle kombinasyon halinde kullanılması λ Maksimuma ulaşmak için Kolmogorov-Smirnov kesinsonuç
Örnekler niceliksel olarak ölçülen herhangi bir göstergeye göre karşılaştırıldığında, tüm deneklerin "etkisi olanlar" ve "etkisi olmayanlar" olarak ayrılmasında kritik nokta olarak kullanılabilecek dağılım noktasının belirlenmesi sorunu ortaya çıkar.
Prensip olarak, grubu etkinin olduğu ve etkinin olmadığı alt gruplara ayıracağımız nokta oldukça keyfi bir şekilde seçilebilir. Herhangi bir etkiyle ilgilenebiliriz ve bu nedenle, bir anlam ifade ettiği sürece her iki örneği de herhangi bir noktada iki parçaya bölebiliriz.
Ancak φ* testinin gücünü maksimuma çıkarmak için, karşılaştırılan iki grup arasındaki farkların en büyük olduğu noktanın seçilmesi gerekir. En doğrusu, bunu kriteri hesaplamak için bir algoritma kullanarak yapabiliriz.λ , iki örnek arasındaki maksimum tutarsızlık noktasını tespit etmenize olanak tanır.
φ* ve kriterlerini birleştirme imkanıλ E.V. Gubler (1978, s. 85-88). Aşağıdaki sorunu çözmek için bu yöntemi kullanmaya çalışalım.
M.A.'nın ortak çalışmasında. Kurochkina, E.V. Sidorenko ve Yu.A. Birleşik Krallık'ta Churakov (1992) İngiliz pratisyen hekimler arasında iki kategoride bir anket gerçekleştirdi: a) tıbbi reformu destekleyen ve kabul ofislerini halihazırda kendi bütçeleriyle fon tutan kuruluşlara dönüştürmüş doktorlar; b) muayenehanelerinin henüz kendi fonları bulunmayan ve tamamı devlet bütçesinden karşılanan doktorlar. Büyük şehirlerde veya taşrada farklı cinsiyet, yaş, hizmet süresi ve iş yeri olan kişilerin temsili açısından İngiliz doktorların genel popülasyonunu temsil eden 200 doktordan oluşan bir örneklem grubuna anketler gönderildi.
Ankete 50'si fonlu bekleme salonlarında, 28'i ise fonsuz bekleme salonlarında çalışan 78 doktor yanıt verdi. Doktorların her birinin, gelecek yıl, yani 1993'te fonlarla birlikte kabullerin payının ne olacağını tahmin etmesi gerekiyordu. Yanıt gönderen 78 doktordan yalnızca 70'i bu soruyu yanıtladı. Tahminlerinin dağılımı Tablo'da sunulmaktadır. 5,8 fonlu doktorlar grubu ve fonsuz doktorlar grubu için ayrı ayrı.
Parası olan doktorların ve parası olmayan doktorların öngörüleri herhangi bir şekilde farklı mı?
Tablo 5.8
1993 yılında acil servislerin fon payının ne olacağına ilişkin pratisyen hekimlerin tahminlerinin dağılımı
Tahmini pay | |||
fonlu resepsiyon odaları | fonlu doktorlar (N 1 =45) | fonu olmayan doktorlar (N 2 =25) | Tutarlar |
1. %0'dan %20'ye | 4 | 5 | 9 |
2. %21'den %40'a | 15 | VE | 26 |
3. %41'den %60'a | 18 | 5 | 23 |
4. %61'den %80'e | 7 | 4 | VE |
5. %81'den %100'e | 1 | 0 | 1 |
Tutarlar | 45 | 25 | 70 |
Madde 4.3'teki Algoritma 15'i kullanarak iki yanıt dağılımı arasındaki maksimum tutarsızlık noktasını belirleyelim (bkz. Tablo 5.9).
Tablo 5.9
İki gruptaki doktorların tahmin dağılımlarında birikmiş frekanslardaki maksimum farkın hesaplanması
Fonlu kabullerin tahmini payı (%) | Belirli bir yanıt kategorisi için ampirik tercih frekansları | Ampirik frekanslar | Kümülatif ampirik frekanslar | Fark (D) |
|||
fonlu doktorlar(N 1 =45) | fonu olmayan doktorlar (N 2 =25) | F* ah 1 | F* a2 | ∑F* e1 | ∑F* a1 |
||
1. %0'dan %20'ye 2. %21'den %40'a 3. %41'den %60'a 4. %61'den %80'e 5. %81'den %100'e | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
Birikmiş iki ampirik frekans arasında tespit edilen maksimum fark0,218.
Bu farkın tahminin ikinci kategorisinde toplandığı ortaya çıkıyor. Bu kategorinin üst sınırını, her iki örneği de "etkinin olduğu" bir alt gruba ve "etkinin olmadığı" bir alt gruba bölmek için bir kriter olarak kullanmaya çalışalım. Belirli bir doktorun fonlarla kabullerin %41 ila %100'ünü öngörmesi durumunda bir "etki" olduğunu varsayacağız.1993 yıl ve belirli bir doktorun fonlarla kabullerin %0 ila 40'ını öngörmesi durumunda "hiçbir etki" olmayacağı.1993 yıl. Bir tarafta tahmin kategorileri 1 ve 2'yi, diğer tarafta tahmin kategorileri 3, 4 ve 5'i birleştiriyoruz. Tahminlerin sonuçta ortaya çıkan dağılımı Tablo'da sunulmaktadır. 5.10.
Tablo 5.10
Fonlu doktorlar ve fonsuz doktorlara ilişkin tahminlerin dağılımı
Fonlu kabullerin tahmini payı (%1) | Belirli bir tahmin kategorisini seçmek için ampirik frekanslar | Tutarlar |
|
fonlu doktorlar(N 1 =45) | fonu olmayan doktorlar(N 2 =25) |
||
1. %0'dan %40'a | 19 | 16 | 35 |
2. %41'den %100'e | 26 | 9 | 35 |
Tutarlar | 45 | 25 | 70 |
Ortaya çıkan tabloyu (Tablo 5.10) herhangi iki hücreyi karşılaştırarak farklı hipotezleri test etmek için kullanabiliriz. Bunun sözde dört hücreli veya dört alanlı tablo olduğunu hatırlıyoruz.
Burada, hâlihazırda fonu olan doktorların, fonu olmayan doktorlara göre bu hareketin gelecekte daha fazla büyüyüp büyümeyeceğini tahmin edip edemeyeceğiyle ilgileniyoruz. Bu nedenle, tahminin %41'den %100'e düştüğü kategoriye girdiğinde "bir etkinin var" olduğunu şartlı olarak değerlendiriyoruz. Hesaplamaları basitleştirmek için şimdi masayı saat yönünde döndürerek 90° döndürmemiz gerekiyor. Hatta kitabı masayla birlikte çevirerek bunu tam anlamıyla yapabilirsiniz. Artık φ* kriterini (Fisher'ın Açısal Dönüşümü) hesaplamak için çalışma sayfasına geçebiliriz.
Masa 5.11
İki grup pratisyen hekimin tahminlerindeki farklılıkları belirlemek amacıyla Fisher'in φ* testini hesaplamak için dört hücreli tablo
Grup | Bir etki var - tahmin %41'den %100'e | Etki yok - tahmin %0'dan %40'a | Toplam |
BENgrup - fonu alan doktorlar | 26 (57.8%) | 19 (42.2%) | 45 |
IIgrup - fonu almayan doktorlar | 9 (36.0%) | 16 (64.0%) | 25 |
Toplam | 35 | 35 | 70 |
Hipotezleri formüle edelim.
H 0 : Kişi oranıFonların tüm doktor muayenehanelerinin %41 ila %100'üne yayılacağını tahmin ederek, fonu olan doktorlar grubunda, fonu olmayan doktorlar grubundan daha fazlası yoktur.
H 1 : Tüm başvuruların %41-%100'üne fonların yayılmasını öngörenlerin oranı, fonu olan doktorlar grubunda, fonu olmayan doktorlar grubuna göre daha fazladır.
φ değerlerinin belirlenmesi 1 ve φ 2 Tabloya göreXIIEk 1. φ'yi hatırlayın 1 her zaman daha büyük yüzdeye karşılık gelen açıdır.
Şimdi φ*: kriterinin ampirik değerini belirleyelim:
Tabloya göre.XIIIEk 1'de bu değerin hangi anlamlılık düzeyine karşılık geldiğini belirliyoruz: p = 0,039.
Ek 1'deki aynı tabloyu kullanarak φ*: kriterinin kritik değerlerini belirleyebilirsiniz.
Cevap: Ancak reddedildi (p=0,039). Fonların yayılmasını öngören kişilerin payı41-100 % Fonu alan doktorlar grubundaki tüm resepsiyonların oranı, fonu almayan doktorlar grubundaki bu oranı aşıyor.
Başka bir deyişle, hâlihazırda ayrı bir bütçeyle bekleme salonlarında çalışan doktorlar, bu uygulamanın bu yıl, henüz bağımsız bir bütçeye geçmeyi kabul etmeyen doktorlara göre daha yaygın olacağını öngörüyor. Bu sonucun birden fazla yorumu var. Örneğin, her gruptaki doktorların bilinçaltında kendi davranışlarını daha tipik olarak değerlendirdikleri varsayılabilir. Bu aynı zamanda kendi kendini finanse etmeyi benimsemiş olan doktorların, kararlarını gerekçelendirmeleri gerektiğinden bu hareketin kapsamını abartma eğiliminde oldukları anlamına da gelebilir. Belirlenen farklılıklar aynı zamanda çalışmada sorulan soruların kapsamının tamamen ötesinde bir anlama da gelebilir. Örneğin, bağımsız bir bütçe üzerinde çalışan doktorların faaliyeti, her iki grubun pozisyonlarındaki farklılıkların keskinleşmesine katkıda bulunuyor. Parayı almayı kabul ettiklerinde daha aktiftiler, posta yoluyla anketi yanıtlama zahmetine girdiklerinde daha aktiftiler; diğer doktorların fon alma konusunda daha aktif olacaklarını tahmin ettiklerinde daha aktif oluyorlar.
Öyle ya da böyle, tespit edilen istatistiksel fark düzeyinin bu gerçek veriler için mümkün olan maksimum düzeyde olduğundan emin olabiliriz. Kriteri kullanarak belirledikλ iki dağılım arasındaki maksimum farklılık noktasıdır ve bu noktada numuneler iki parçaya bölünmüştür.
İşaretin.
Bu örneği kullanarak, ortaya çıkan regresyon denkleminin güvenilirliğinin nasıl değerlendirildiğini ele alacağız. Aynı test, regresyon katsayılarının eş zamanlı olarak sıfıra (a=0, b=0) eşit olduğu hipotezini test etmek için kullanılır. Başka bir deyişle, hesaplamaların özü şu soruyu yanıtlamaktır: Daha ileri analiz ve tahminler için kullanılabilir mi?
İki örnekteki varyansların benzer mi yoksa farklı mı olduğunu belirlemek için bu t testini kullanın.
Dolayısıyla analizin amacı, belirli bir α seviyesinde ortaya çıkan regresyon denkleminin istatistiksel olarak güvenilir olduğunu ifade edebilecek bir tahmin elde etmektir. Bunun için belirleme katsayısı R 2 kullanılır.
Bir regresyon modelinin öneminin test edilmesi, hesaplanan değeri, incelenen göstergenin orijinal gözlem serisinin varyansının oranı ve artık dizinin varyansının tarafsız tahmini olarak bulunan Fisher'in F testi kullanılarak gerçekleştirilir. bu model için.
k 1 =(m) ve k 2 =(n-m-1) serbestlik derecesi ile hesaplanan değer, belirli bir anlamlılık seviyesinde tablodaki değerden büyükse, model anlamlı kabul edilir.
burada m modeldeki faktörlerin sayısıdır.
Eşleştirilmiş doğrusal regresyonun istatistiksel önemi aşağıdaki algoritma kullanılarak değerlendirilir:
1. Denklemin bir bütün olarak istatistiksel olarak anlamsız olduğuna dair boş bir hipotez öne sürülüyor: α anlamlılık düzeyinde H 0: R 2 =0.
2. Daha sonra F kriterinin gerçek değerini belirleyin: ![]()
![]()
burada m=1 ikili regresyon için.
3. Tablolanan değer, toplam kareler toplamı için serbestlik derecesi sayısının (daha büyük varyans) 1 olduğu ve kalan için serbestlik derecesi sayısı dikkate alınarak, belirli bir anlamlılık düzeyi için Fisher dağılım tablolarından belirlenir. Doğrusal regresyonda karelerin toplamı (daha küçük varyans) n-2'dir (veya FRIST(olasılık,1,n-2) Excel işlevi aracılığıyla).
F tablosu, belirli bir serbestlik derecesine ve anlamlılık düzeyi α'ya sahip, rastgele faktörlerin etkisi altında kriterin mümkün olan maksimum değeridir. Anlamlılık düzeyi α, doğru olması koşuluyla doğru hipotezin reddedilme olasılığıdır. Tipik olarak α, 0,05 veya 0,01 olarak alınır.
4. F testinin gerçek değeri tablo değerinden küçükse sıfır hipotezini reddetmek için hiçbir neden olmadığını söylüyorlar.
Aksi takdirde sıfır hipotezi reddedilir ve denklemin bir bütün olarak istatistiksel anlamlılığına ilişkin alternatif hipotez (1-α) olasılığıyla kabul edilir.
Kriterin serbestlik dereceli tablo değeri k 1 =1 ve k 2 =48, F tablosu = 4
sonuçlar: Gerçek değer F > F tablosu olduğundan belirleme katsayısı istatistiksel olarak anlamlıdır ( bulunan regresyon denklemi tahmini istatistiksel olarak güvenilirdir) .
Varyans analizi
.Regresyon denklemi kalite göstergeleri
Örnek. Toplam 25 ticari işletmeye dayanarak aşağıdaki özellikler arasındaki ilişki incelenmiştir: X - A ürününün fiyatı, bin ruble; Y, bir ticari işletmenin karıdır, milyon ruble. Regresyon modelini değerlendirirken aşağıdaki ara sonuçlar elde edildi: ∑(y i -y x) 2 = 46000; ∑(y i -y ort) 2 = 138000. Bu verilerden hangi korelasyon göstergesi belirlenebilir? Bu sonuca dayanarak ve kullanarak bu göstergenin değerini hesaplayın. Fisher'in F testi Regresyon modelinin kalitesi hakkında sonuçlar çıkarmak.
Çözüm. Bu verilerden ampirik korelasyon oranını belirleyebiliriz:  , burada ∑(y ort -y x) 2 = ∑(y ben -y ort) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92.000.
, burada ∑(y ort -y x) 2 = ∑(y ben -y ort) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92.000.
η 2 = 92.000/138000 = 0,67, η = 0,816 (0,7< η < 0.9 - связь между X и Y высокая).
Fisher'in F testi: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0,67, F = 0,67/(1-0,67)x(25 - 1 - 1) = 46. F tablosu (1; 23) = 4,27
Gerçek değer F > Ftablo olduğundan, regresyon denkleminin bulunan tahmini istatistiksel olarak güvenilirdir.
Soru: Bir regresyon modelinin anlamlılığını test etmek için hangi istatistikler kullanılır?
Cevap: Modelin tamamının bir bütün olarak anlamlılığı için F istatistikleri (Fisher testi) kullanılmaktadır.
Örnek ortalamalarında hiçbir fark olmayan, ancak varyanslarda bir fark olan, normal dağılmış iki popülasyonu karşılaştırmak için şunu kullanın: Fisher testi. Gerçek kriter aşağıdaki formül kullanılarak hesaplanır:
burada pay, örneklem varyansının daha büyük değeridir ve payda daha küçüktür. Örnekler arasındaki farkların güvenilirliğini sonuçlandırmak için şunu kullanın: TEMEL PRENSİP
İstatistiksel hipotezlerin test edilmesi. için kritik noktalar  tabloda yer almaktadır. Gerçek değer ise sıfır hipotezi reddedilir
tabloda yer almaktadır. Gerçek değer ise sıfır hipotezi reddedilir 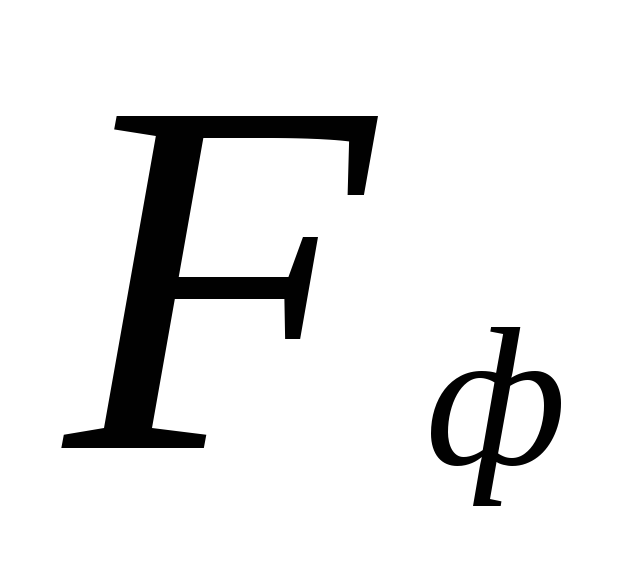 kritik (standart) değeri aşacak veya ona eşit olacaktır
kritik (standart) değeri aşacak veya ona eşit olacaktır  kabul edilen anlamlılık düzeyi için bu değer
ve serbestlik derecesi sayısı k
1
=
N
büyük
-1
;
k
2
=
N
daha küçük
-1
.
kabul edilen anlamlılık düzeyi için bu değer
ve serbestlik derecesi sayısı k
1
=
N
büyük
-1
;
k
2
=
N
daha küçük
-1
.
Örnek: Belirli bir ilacın tohum çimlenme hızı üzerindeki etkisi incelenirken, deneysel tohum grubunda ve kontrolde ortalama çimlenme oranının aynı olduğu ancak varyanslarda bir fark olduğu bulundu.  =1250,
=1250, =417. Örnek boyutları aynı ve 20'ye eşit.
=417. Örnek boyutları aynı ve 20'ye eşit. 
 =2.12. Bu nedenle sıfır hipotezi reddedilir.
=2.12. Bu nedenle sıfır hipotezi reddedilir.
Korelasyon bağımlılığı. Korelasyon katsayısı ve özellikleri. Regresyon denklemleri.
GÖREV Korelasyon analizi şu anlama gelir:
Özellikler arasındaki bağlantının yönünü ve şeklini oluşturmak;
Sıkılığını ölçmek.
Fonksiyonel Değişken miktarlar arasında kesin bir ilişki, bir (bağımsız) değişkenin belirli bir değeri olduğunda çağrılır. X argüman olarak adlandırılan, başka bir (bağımlı) değişkenin belirli bir değerine karşılık gelir en , fonksiyon olarak adlandırılır. ( Örnek: kimyasal reaksiyonun hızının sıcaklığa bağlılığı; çekim kuvvetinin çeken cisimlerin kütlelerine ve aralarındaki mesafeye bağımlılığı).
Korelasyon Bir özelliğin belirli bir değeri (bağımsız bir değişken olarak kabul edilir) başka bir özelliğin bir dizi sayısal değerine karşılık geldiğinde, doğası gereği istatistiksel olan değişkenler arasındaki bir ilişkidir. ( Örnek: hasat ve yağış arasındaki ilişki; boy ve kilo arasında vb.)
Korelasyon alanı koordinatları deneysel olarak elde edilen değişken değer çiftlerine eşit olan bir dizi noktayı temsil eder X Ve en .
Korelasyon alanının türüne göre bir bağlantının varlığı veya yokluğu ve türü değerlendirilebilir.




Bağlantı denir pozitif Bir değişken arttığında diğer değişken artıyorsa.
Bağlantı denir olumsuz Bir değişken artarken diğer değişken azalıyorsa.
Bağlantı denir doğrusal
analitik olarak temsil edilebiliyorsa 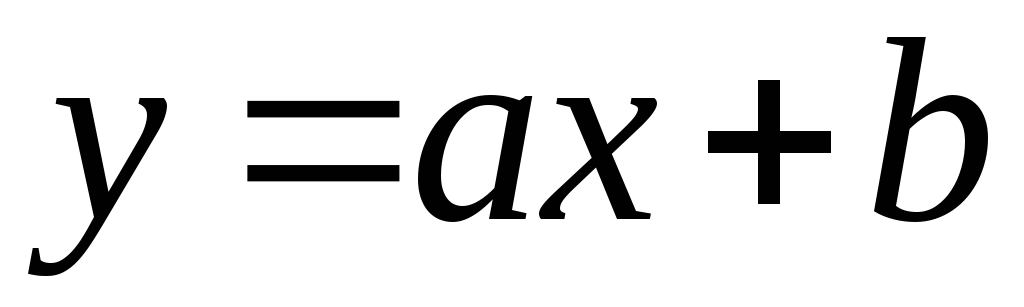 .
.
Bağlantının yakınlığının bir göstergesi korelasyon katsayısı . Ampirik korelasyon katsayısı şu şekilde verilir:

Korelasyon katsayısı şu aralıklardadır: -1 önce 1 ve miktarlar arasındaki yakınlık derecesini karakterize eder X Ve sen . Eğer:

Karakteristikler arasındaki korelasyon farklı şekillerde açıklanabilir. Özellikle herhangi bir bağlantı şekli genel formdaki bir denklemle ifade edilebilir. 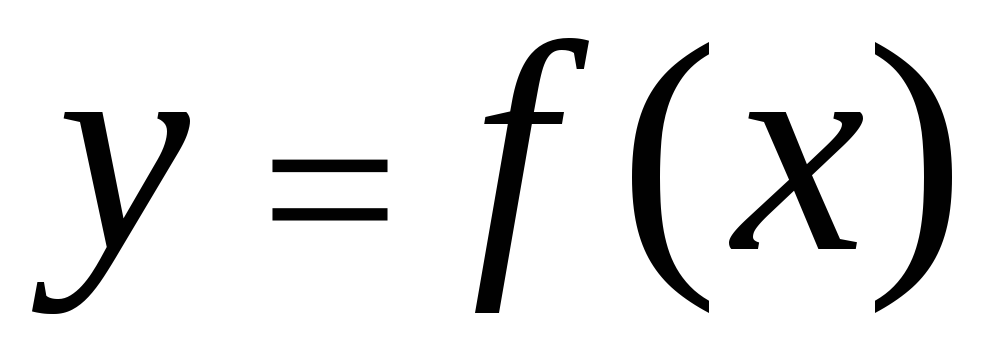 . Formun denklemi
. Formun denklemi  Ve
Ve 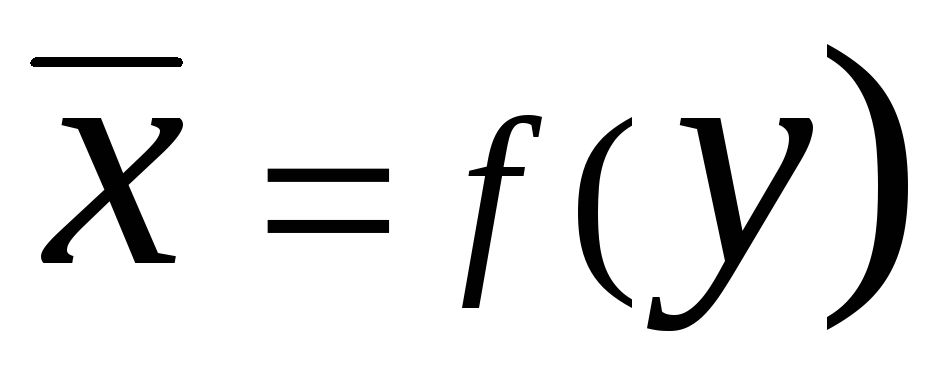 arandı gerileme
. İleri Regresyon Denklemi en
Açık X
genel durumda şu şekilde yazılabilir:
arandı gerileme
. İleri Regresyon Denklemi en
Açık X
genel durumda şu şekilde yazılabilir:

İleri Regresyon Denklemi X Açık en genel olarak öyle görünüyor

En olası katsayı değerleri A Ve V, İle Ve Dörneğin en küçük kareler yöntemi kullanılarak hesaplanabilir.







