মাছ ধরার মানদণ্ডআপনাকে দুটি স্বাধীন নমুনার নমুনা বৈচিত্র তুলনা করতে দেয়। F emp গণনা করতে, আপনাকে দুটি নমুনার বৈচিত্র্যের অনুপাত খুঁজে বের করতে হবে, যাতে বৃহত্তর প্রকরণটি লবটিতে থাকে এবং ছোটটি হরটিতে থাকে। ফিশার মানদণ্ড গণনা করার সূত্র হল:
যেখানে যথাক্রমে প্রথম এবং দ্বিতীয় নমুনার ভিন্নতা আছে।
যেহেতু, মানদণ্ডের শর্ত অনুসারে, লবের মান অবশ্যই হর-এর মানের চেয়ে বেশি বা সমান হতে হবে, তাই F emp-এর মান সর্বদা একের চেয়ে বড় বা সমান হবে।
স্বাধীনতার ডিগ্রির সংখ্যাও সহজভাবে নির্ধারিত হয়:
k 1 =n l - 1 প্রথম নমুনার জন্য (অর্থাৎ যে নমুনার বৈচিত্র্য বড়) এবং k 2 = n 2 - 1 দ্বিতীয় নমুনার জন্য।
পরিশিষ্ট 1-এ, ফিশার মানদণ্ডের সমালোচনামূলক মানগুলি k 1 (টেবিলের উপরের লাইন) এবং k 2 (টেবিলের বাম কলাম) এর মান দ্বারা পাওয়া যায়।
যদি tem >t সমালোচনা হয়, তাহলে শূন্য অনুমান গৃহীত হয়, অন্যথায় বিকল্পটি গৃহীত হয়।
উদাহরণ 3.দুটি তৃতীয় গ্রেডে পরীক্ষা করা হয়েছিল মানসিক বিকাশ TURMSH পরীক্ষায় দশজন শিক্ষার্থী। প্রাপ্ত গড় মানগুলি উল্লেখযোগ্যভাবে পৃথক হয়নি, তবে মনোবিজ্ঞানী এই প্রশ্নে আগ্রহী যে শ্রেণিগুলির মধ্যে মানসিক বিকাশের সূচকগুলির একজাতীয়তার ডিগ্রির মধ্যে পার্থক্য রয়েছে কিনা।
সমাধান। ফিশারের পরীক্ষার জন্য, উভয় শ্রেণীর পরীক্ষার স্কোরের ভিন্নতা তুলনা করা প্রয়োজন। পরীক্ষার ফলাফল টেবিলে উপস্থাপন করা হয়:
টেবিল 3।
|
ছাত্র সংখ্যা |
প্রথম শ্রেণীর |
দ্বিতীয় শ্রেণী |
X এবং Y ভেরিয়েবলের বৈচিত্রগুলি গণনা করার পরে, আমরা পাই:
s এক্স 2 =572.83; s y 2 =174,04
তারপর, ফিশারের এফ মানদণ্ড ব্যবহার করে গণনার জন্য সূত্র (8) ব্যবহার করে, আমরা খুঁজে পাই:
![]()
উভয় ক্ষেত্রেই k = 10 - 1 = 9 সমান স্বাধীনতার ডিগ্রী সহ F মানদণ্ডের জন্য পরিশিষ্ট 1 থেকে সারণী অনুসারে, আমরা F crit = 3.18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 ননপ্যারামেট্রিক পরীক্ষা
চোখের দ্বারা (শতাংশ দ্বারা) ফলাফলগুলি যে কোনও প্রভাবের আগে এবং পরে তুলনা করে, গবেষক এই সিদ্ধান্তে পৌঁছেছেন যে যদি পার্থক্য পরিলক্ষিত হয়, তবে তুলনা করা নমুনাগুলিতে একটি পার্থক্য রয়েছে। এই পদ্ধতিটি স্পষ্টতই অগ্রহণযোগ্য, যেহেতু শতাংশের জন্য পার্থক্যের নির্ভরযোগ্যতার স্তর নির্ধারণ করা অসম্ভব। নিজের দ্বারা নেওয়া শতকরা পরিসংখ্যানগতভাবে নির্ভরযোগ্য উপসংহার টানা সম্ভব করে না। যেকোনো হস্তক্ষেপের কার্যকারিতা প্রমাণ করার জন্য, সূচকগুলির পক্ষপাত (বদলে) একটি পরিসংখ্যানগতভাবে উল্লেখযোগ্য প্রবণতা চিহ্নিত করা প্রয়োজন। এই ধরনের সমস্যা সমাধানের জন্য, একজন গবেষক বিভিন্ন বৈষম্যের মানদণ্ড ব্যবহার করতে পারেন। নীচে আমরা নন-প্যারামেট্রিক পরীক্ষাগুলি বিবেচনা করব: সাইন পরীক্ষা এবং চি-স্কয়ার পরীক্ষা।
সামগ্রিকভাবে একাধিক রিগ্রেশন সমীকরণের তাত্পর্য, সেইসাথে জোড়া রিগ্রেশনে, ফিশার মানদণ্ড ব্যবহার করে মূল্যায়ন করা হয়:
 ,
(2.22)
,
(2.22)
কোথায়  - স্বাধীনতার ডিগ্রী প্রতি বর্গক্ষেত্রের ফ্যাক্টর যোগফল;
- স্বাধীনতার ডিগ্রী প্রতি বর্গক্ষেত্রের ফ্যাক্টর যোগফল;  - স্বাধীনতার ডিগ্রী প্রতি বর্গক্ষেত্রের অবশিষ্ট যোগফল;
- স্বাধীনতার ডিগ্রী প্রতি বর্গক্ষেত্রের অবশিষ্ট যোগফল;  - একাধিক সংকল্পের সহগ (সূচক);
- একাধিক সংকল্পের সহগ (সূচক);  - ভেরিয়েবলের জন্য প্যারামিটারের সংখ্যা
- ভেরিয়েবলের জন্য প্যারামিটারের সংখ্যা  (লিনিয়ার রিগ্রেশনে এটি মডেলের অন্তর্ভুক্ত কারণগুলির সংখ্যার সাথে মিলে যায়);
(লিনিয়ার রিগ্রেশনে এটি মডেলের অন্তর্ভুক্ত কারণগুলির সংখ্যার সাথে মিলে যায়);  - পর্যবেক্ষণের সংখ্যা।
- পর্যবেক্ষণের সংখ্যা।
সামগ্রিকভাবে শুধুমাত্র সমীকরণের তাত্পর্যই মূল্যায়ন করা হয় না, তবে রিগ্রেশন মডেলের অন্তর্ভুক্ত ফ্যাক্টরটিও। এই ধরনের মূল্যায়নের প্রয়োজনীয়তা এই কারণে যে মডেলটিতে অন্তর্ভুক্ত প্রতিটি ফ্যাক্টর ফলাফলের বৈশিষ্ট্যে ব্যাখ্যাকৃত বৈচিত্র্যের অনুপাতকে উল্লেখযোগ্যভাবে বৃদ্ধি করতে পারে না। উপরন্তু, যদি মডেলটিতে বেশ কয়েকটি কারণ থাকে তবে সেগুলি বিভিন্ন ক্রম অনুসারে মডেলটিতে প্রবেশ করা যেতে পারে। কারণগুলির মধ্যে পারস্পরিক সম্পর্কের কারণে, একই ফ্যাক্টরের তাত্পর্য মডেলে এর প্রবর্তনের ক্রম অনুসারে ভিন্ন হতে পারে। মডেলে একটি ফ্যাক্টর অন্তর্ভুক্তি মূল্যায়ন করার জন্য পরিমাপ ব্যক্তিগত  - মানদণ্ড, যেমন
- মানদণ্ড, যেমন  .
.
ব্যক্তিগত  -মানদন্ডটি সামগ্রিকভাবে রিগ্রেশন মডেলের জন্য স্বাধীনতার এক ডিগ্রী প্রতি অবশিষ্ট প্রকরণের সাথে অতিরিক্ত অন্তর্ভুক্ত ফ্যাক্টরের প্রভাবের কারণে ফ্যাক্টর বৈচিত্র্যের বৃদ্ধির তুলনা করার উপর ভিত্তি করে। ফ্যাক্টর জন্য সাধারণ শর্তাবলী
-মানদন্ডটি সামগ্রিকভাবে রিগ্রেশন মডেলের জন্য স্বাধীনতার এক ডিগ্রী প্রতি অবশিষ্ট প্রকরণের সাথে অতিরিক্ত অন্তর্ভুক্ত ফ্যাক্টরের প্রভাবের কারণে ফ্যাক্টর বৈচিত্র্যের বৃদ্ধির তুলনা করার উপর ভিত্তি করে। ফ্যাক্টর জন্য সাধারণ শর্তাবলী  ব্যক্তিগত
ব্যক্তিগত  - মাপদণ্ড হিসাবে নির্ধারণ করা হবে
- মাপদণ্ড হিসাবে নির্ধারণ করা হবে
 ,
(2.23)
,
(2.23)
কোথায়  - কারণগুলির সম্পূর্ণ সেট সহ একটি মডেলের জন্য একাধিক সংকল্পের সহগ,
- কারণগুলির সম্পূর্ণ সেট সহ একটি মডেলের জন্য একাধিক সংকল্পের সহগ,  – একই সূচক, কিন্তু মডেলে ফ্যাক্টর অন্তর্ভুক্ত না করে
– একই সূচক, কিন্তু মডেলে ফ্যাক্টর অন্তর্ভুক্ত না করে  ,
, - পর্যবেক্ষণের সংখ্যা,
- পর্যবেক্ষণের সংখ্যা,  - মডেলের প্যারামিটারের সংখ্যা (মুক্ত শব্দ ছাড়া)।
- মডেলের প্যারামিটারের সংখ্যা (মুক্ত শব্দ ছাড়া)।
ভাগফলের প্রকৃত মান  - মানদণ্ডটি তাত্পর্যের স্তরে টেবিলের সাথে তুলনা করা হয়
- মানদণ্ডটি তাত্পর্যের স্তরে টেবিলের সাথে তুলনা করা হয়  এবং স্বাধীনতার ডিগ্রির সংখ্যা: 1 এবং
এবং স্বাধীনতার ডিগ্রির সংখ্যা: 1 এবং  . যদি প্রকৃত মান
. যদি প্রকৃত মান  অতিক্রম করে
অতিক্রম করে  , তারপর ফ্যাক্টরের অতিরিক্ত অন্তর্ভুক্তি
, তারপর ফ্যাক্টরের অতিরিক্ত অন্তর্ভুক্তি  মডেলের মধ্যে পরিসংখ্যানগতভাবে ন্যায়সঙ্গত এবং বিশুদ্ধ রিগ্রেশন সহগ
মডেলের মধ্যে পরিসংখ্যানগতভাবে ন্যায়সঙ্গত এবং বিশুদ্ধ রিগ্রেশন সহগ  ফ্যাক্টর এ
ফ্যাক্টর এ  পরিসংখ্যানগত ভাবে উল্লেখযোগ্য. যদি প্রকৃত মান
পরিসংখ্যানগত ভাবে উল্লেখযোগ্য. যদি প্রকৃত মান  সারণী মানের থেকে কম, তারপর মডেলে ফ্যাক্টরের অতিরিক্ত অন্তর্ভুক্তি
সারণী মানের থেকে কম, তারপর মডেলে ফ্যাক্টরের অতিরিক্ত অন্তর্ভুক্তি  একটি বৈশিষ্ট্যে ব্যাখ্যা করা বৈচিত্র্যের অনুপাত উল্লেখযোগ্যভাবে বৃদ্ধি করে না
একটি বৈশিষ্ট্যে ব্যাখ্যা করা বৈচিত্র্যের অনুপাত উল্লেখযোগ্যভাবে বৃদ্ধি করে না  , অতএব, এটি মডেলে অন্তর্ভুক্ত করা অনুপযুক্ত; এই ক্ষেত্রে এই ফ্যাক্টরের জন্য রিগ্রেশন সহগ পরিসংখ্যানগতভাবে নগণ্য।
, অতএব, এটি মডেলে অন্তর্ভুক্ত করা অনুপযুক্ত; এই ক্ষেত্রে এই ফ্যাক্টরের জন্য রিগ্রেশন সহগ পরিসংখ্যানগতভাবে নগণ্য।
একটি দ্বি-গুণিক সমীকরণের জন্য, ভাগফল  - মানদণ্ডের ফর্ম আছে:
- মানদণ্ডের ফর্ম আছে:
 ,
, . (2.23a)
. (2.23a)
ব্যক্তিগত ব্যবহার করে  -মাপদণ্ড, প্রত্যেকটি সংশ্লিষ্ট ফ্যাক্টর অনুমান করে সমস্ত রিগ্রেশন সহগগুলির তাত্পর্য পরীক্ষা করতে পারে
-মাপদণ্ড, প্রত্যেকটি সংশ্লিষ্ট ফ্যাক্টর অনুমান করে সমস্ত রিগ্রেশন সহগগুলির তাত্পর্য পরীক্ষা করতে পারে  মাল্টিপল রিগ্রেশন সমীকরণে সর্বশেষ প্রবেশ করেছে।
মাল্টিপল রিগ্রেশন সমীকরণে সর্বশেষ প্রবেশ করেছে।
- একাধিক রিগ্রেশন সমীকরণের জন্য ছাত্র পরীক্ষা।
ব্যক্তিগত  -মাপদণ্ড বিশুদ্ধ রিগ্রেশন সহগগুলির তাত্পর্য মূল্যায়ন করে। ব্যাপকতা জেনে
-মাপদণ্ড বিশুদ্ধ রিগ্রেশন সহগগুলির তাত্পর্য মূল্যায়ন করে। ব্যাপকতা জেনে  , এটা নির্ধারণ করা সম্ভব
, এটা নির্ধারণ করা সম্ভব  -এ রিগ্রেশন সহগের জন্য মানদণ্ড
-এ রিগ্রেশন সহগের জন্য মানদণ্ড  -m ফ্যাক্টর,
-m ফ্যাক্টর,  , যথা:
, যথা:
 .
(2.24)
.
(2.24)
দ্বারা বিশুদ্ধ রিগ্রেশন সহগ এর তাত্পর্য মূল্যায়ন  -ছাত্রের টি-পরীক্ষা আংশিক হিসাব না করেই করা যেতে পারে
-ছাত্রের টি-পরীক্ষা আংশিক হিসাব না করেই করা যেতে পারে  -নির্ণায়ক. এই ক্ষেত্রে, পেয়ারওয়াইজ রিগ্রেশনের মতো, প্রতিটি ফ্যাক্টরের জন্য সূত্রটি ব্যবহার করা হয়:
-নির্ণায়ক. এই ক্ষেত্রে, পেয়ারওয়াইজ রিগ্রেশনের মতো, প্রতিটি ফ্যাক্টরের জন্য সূত্রটি ব্যবহার করা হয়:
 ,
(2.25)
,
(2.25)
কোথায়  - ফ্যাক্টর এ বিশুদ্ধ রিগ্রেশন সহগ
- ফ্যাক্টর এ বিশুদ্ধ রিগ্রেশন সহগ  ,
, - মানে রিগ্রেশন সহগ এর বর্গক্ষেত্র (মান) ত্রুটি
- মানে রিগ্রেশন সহগ এর বর্গক্ষেত্র (মান) ত্রুটি  .
.
একটি মাল্টিপল রিগ্রেশন সমীকরণের জন্য, রিগ্রেশন সহগের গড় বর্গক্ষেত্র ত্রুটি নিম্নলিখিত সূত্র দ্বারা নির্ধারণ করা যেতে পারে:
 ,
(2.26)
,
(2.26)
কোথায় 
 ,
, - বৈশিষ্ট্যের জন্য আদর্শ বিচ্যুতি
- বৈশিষ্ট্যের জন্য আদর্শ বিচ্যুতি  ,
, - একাধিক রিগ্রেশন সমীকরণের জন্য সংকল্পের সহগ,
- একাধিক রিগ্রেশন সমীকরণের জন্য সংকল্পের সহগ,  - ফ্যাক্টরের নির্ভরতার জন্য সংকল্পের সহগ
- ফ্যাক্টরের নির্ভরতার জন্য সংকল্পের সহগ  একাধিক রিগ্রেশন সমীকরণের অন্যান্য সমস্ত কারণের সাথে;
একাধিক রিগ্রেশন সমীকরণের অন্যান্য সমস্ত কারণের সাথে;  - বর্গক্ষেত্র বিচ্যুতির অবশিষ্ট যোগফলের জন্য স্বাধীনতা ডিগ্রীর সংখ্যা।
- বর্গক্ষেত্র বিচ্যুতির অবশিষ্ট যোগফলের জন্য স্বাধীনতা ডিগ্রীর সংখ্যা।
আপনি দেখতে পাচ্ছেন, এই সূত্রটি ব্যবহার করার জন্য, আপনার একটি ইন্টারফ্যাক্টর পারস্পরিক সম্পর্ক ম্যাট্রিক্স এবং এটি ব্যবহার করে সংকল্পের সংশ্লিষ্ট সহগগুলির গণনা প্রয়োজন।  . সুতরাং, সমীকরণ জন্য
. সুতরাং, সমীকরণ জন্য  রিগ্রেশন সহগ এর তাৎপর্যের মূল্যায়ন
রিগ্রেশন সহগ এর তাৎপর্যের মূল্যায়ন  ,
, ,
, তিনটি ইন্টারফ্যাক্টর নির্ধারণ সহগ গণনা জড়িত:
তিনটি ইন্টারফ্যাক্টর নির্ধারণ সহগ গণনা জড়িত:  ,
, ,
, .
.
আংশিক পারস্পরিক সম্পর্ক সহগের সূচকগুলির মধ্যে সম্পর্ক, আংশিক  - মানদণ্ড এবং
- মানদণ্ড এবং  বিশুদ্ধ রিগ্রেশন সহগগুলির জন্য ছাত্রদের টি-পরীক্ষা ফ্যাক্টর নির্বাচন পদ্ধতিতে ব্যবহার করা যেতে পারে। নির্মূল পদ্ধতি দ্বারা একটি রিগ্রেশন সমীকরণ তৈরি করার সময় ফ্যাক্টরগুলির নির্মূল কার্যত শুধুমাত্র আংশিক পারস্পরিক সম্পর্ক সহগ দ্বারা নয়, প্রতিটি ধাপে আংশিক পারস্পরিক সম্পর্ক সহগের ক্ষুদ্রতম নগণ্য মানের ফ্যাক্টর বাদ দিয়ে, কিন্তু মান দ্বারাও করা যেতে পারে।
বিশুদ্ধ রিগ্রেশন সহগগুলির জন্য ছাত্রদের টি-পরীক্ষা ফ্যাক্টর নির্বাচন পদ্ধতিতে ব্যবহার করা যেতে পারে। নির্মূল পদ্ধতি দ্বারা একটি রিগ্রেশন সমীকরণ তৈরি করার সময় ফ্যাক্টরগুলির নির্মূল কার্যত শুধুমাত্র আংশিক পারস্পরিক সম্পর্ক সহগ দ্বারা নয়, প্রতিটি ধাপে আংশিক পারস্পরিক সম্পর্ক সহগের ক্ষুদ্রতম নগণ্য মানের ফ্যাক্টর বাদ দিয়ে, কিন্তু মান দ্বারাও করা যেতে পারে।  এবং
এবং  .
ব্যক্তিগত
.
ব্যক্তিগত  ভেরিয়েবলের অন্তর্ভুক্তির পদ্ধতি এবং ধাপে ধাপে রিগ্রেশন পদ্ধতি ব্যবহার করে একটি মডেল তৈরি করার সময় মানদণ্ড ব্যাপকভাবে ব্যবহৃত হয়।
ভেরিয়েবলের অন্তর্ভুক্তির পদ্ধতি এবং ধাপে ধাপে রিগ্রেশন পদ্ধতি ব্যবহার করে একটি মডেল তৈরি করার সময় মানদণ্ড ব্যাপকভাবে ব্যবহৃত হয়।
মানদণ্ডের গণনা φ*
1. বৈশিষ্ট্যের সেই মানগুলি নির্ধারণ করুন যা বিষয়গুলিকে যাদের "একটি প্রভাব আছে" এবং যাদের "প্রভাব নেই" তাদের মধ্যে বিভক্ত করার মানদণ্ড হবে। যদি বৈশিষ্ট্যটি পরিমাণগতভাবে পরিমাপ করা হয়, তাহলে সর্বোত্তম বিচ্ছেদ বিন্দু খুঁজে পেতে λ মানদণ্ড ব্যবহার করুন।
2. দুটি কলাম এবং দুটি সারির একটি চার-কোষ (প্রতিশব্দ: চার-ক্ষেত্র) টেবিল আঁকুন। প্রথম কলাম হল "একটি প্রভাব আছে"; দ্বিতীয় কলাম - "কোন প্রভাব নেই"; শীর্ষ থেকে প্রথম লাইন - 1 গ্রুপ (নমুনা); দ্বিতীয় লাইন - গ্রুপ 2 (নমুনা)।
4. প্রথম নমুনায় "কোন প্রভাব নেই" এমন বিষয়ের সংখ্যা গণনা করুন এবং টেবিলের উপরের ডান কক্ষে এই সংখ্যাটি লিখুন। উপরের দুটি কক্ষের যোগফল গণনা করুন। এটি প্রথম গ্রুপের বিষয়ের সংখ্যার সাথে মিলিত হওয়া উচিত।
6. দ্বিতীয় নমুনায় "কোন প্রভাব নেই" এমন বিষয়ের সংখ্যা গণনা করুন এবং টেবিলের নীচের ডান কক্ষে এই সংখ্যাটি লিখুন। দুটি নিম্ন কক্ষের যোগফল গণনা করুন। এটি দ্বিতীয় গ্রুপের (নমুনা) বিষয়ের সংখ্যার সাথে মিলিত হওয়া উচিত।
7. একটি প্রদত্ত গোষ্ঠীর (নমুনা) মোট বিষয়ের সংখ্যার সাথে তাদের সংখ্যা সম্পর্কিত করে "একটি প্রভাব ফেলেছে" এমন বিষয়গুলির শতাংশ নির্ধারণ করুন। সারণীর উপরের বাম এবং নীচের বাম কক্ষে ফলিত শতাংশগুলি যথাক্রমে বন্ধনীতে লিখুন, যাতে তাদের পরম মানগুলির সাথে বিভ্রান্ত না হয়।
8. তুলনা করা শতাংশের একটি শূন্যের সমান কিনা তা পরীক্ষা করে দেখুন। যদি এটি হয় তবে গ্রুপ বিচ্ছেদ পয়েন্টটিকে এক দিক বা অন্য দিকে সরিয়ে এটি পরিবর্তন করার চেষ্টা করুন। যদি এটি অসম্ভব বা অবাঞ্ছিত হয়, তাহলে φ* মানদণ্ড ত্যাগ করুন এবং χ2 মানদণ্ড ব্যবহার করুন।
9. সারণি অনুযায়ী নির্ধারণ করুন। XII পরিশিষ্ট 1 কোণ φ প্রতিটি তুলনামূলক শতাংশের জন্য।
যেখানে: φ1 - বৃহত্তর শতাংশের সাথে সংশ্লিষ্ট কোণ;
φ2 - ছোট শতাংশের সাথে সংশ্লিষ্ট কোণ;
N1 - নমুনা 1-এ পর্যবেক্ষণের সংখ্যা;
N2 - নমুনা 2-এ পর্যবেক্ষণের সংখ্যা।
11. প্রাপ্ত মান φ* সমালোচনামূলক মানের সাথে তুলনা করুন: φ* ≤1.64 (p<0,05) и φ* ≤2,31 (р<0,01).
যদি φ*emp ≤φ*cr. H0 প্রত্যাখ্যাত।
প্রয়োজনে, সারণী অনুসারে ফলস্বরূপ φ*emp-এর তাৎপর্যের সঠিক স্তর নির্ধারণ করুন। XIII পরিশিষ্ট 1.
এই পদ্ধতিটি অনেক ম্যানুয়ালে বর্ণনা করা হয়েছে (Plokhinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992, ইত্যাদি) এই বর্ণনাটি পদ্ধতির সংস্করণের উপর ভিত্তি করে তৈরি করা হয়েছে যা E.V দ্বারা তৈরি এবং উপস্থাপিত হয়েছিল। গুবলার।
মানদণ্ডের উদ্দেশ্য φ*
ফিশারের পরীক্ষাটি গবেষকের আগ্রহের প্রভাব (সূচক) এর সংঘটনের ফ্রিকোয়েন্সি অনুসারে দুটি নমুনার তুলনা করার জন্য ডিজাইন করা হয়েছে। এটি যত বড়, পার্থক্য তত বেশি নির্ভরযোগ্য।
মানদণ্ডের বর্ণনা
মানদণ্ড দুটি নমুনার শতাংশের মধ্যে পার্থক্যের নির্ভরযোগ্যতা মূল্যায়ন করে যেখানে আমাদের আগ্রহের প্রভাব (সূচক) রেকর্ড করা হয়েছিল। রূপকভাবে বলতে গেলে, আমরা 2টি পাই থেকে কাটা 2টি সেরা টুকরো তুলনা করি এবং সিদ্ধান্ত নিই যে কোনটি সত্যিই বড়।
ফিশার কৌণিক রূপান্তরের সারমর্ম হল শতকরাকে কেন্দ্রীয় কোণের মানগুলিতে রূপান্তর করা, যা রেডিয়ানে পরিমাপ করা হয়। একটি বৃহত্তর শতাংশ একটি বৃহত্তর কোণ φ, এবং একটি ছোট শতাংশ একটি ছোট কোণের সাথে সঙ্গতিপূর্ণ হবে, কিন্তু এখানে সম্পর্কগুলি রৈখিক নয়:
যেখানে P হল একটি ইউনিটের ভগ্নাংশে প্রকাশ করা শতাংশ (চিত্র 5.1 দেখুন)।
কোণের মধ্যে ক্রমবর্ধমান বৈষম্য সহ φ 1 এবং φ 2 এবং নমুনার সংখ্যা বৃদ্ধি, মানদণ্ডের মান বৃদ্ধি পায়। φ* এর মান যত বড় হবে, পার্থক্যগুলি তাৎপর্যপূর্ণ হওয়ার সম্ভাবনা তত বেশি।
অনুমান
এইচ 0 : ব্যক্তির অনুপাত, যেখানে অধ্যয়ন করা প্রভাবটি নিজেকে প্রকাশ করে, নমুনা 2 এর চেয়ে নমুনা 1-এ আর কিছু নেই।
এইচ 1 : অধ্যয়নকৃত প্রভাব প্রদর্শনকারী ব্যক্তিদের অনুপাত নমুনা 2-এর তুলনায় নমুনা 1-এ বেশি।
মানদণ্ডের গ্রাফিক্যাল উপস্থাপনা φ*
কৌণিক রূপান্তর পদ্ধতি অন্যান্য মানদণ্ডের তুলনায় কিছুটা বেশি বিমূর্ত।
φ এর মান গণনা করার সময় E.V Gubler অনুসৃত সূত্রটি অনুমান করে যে 100% একটি কোণ তৈরি করে φ=3.142, অর্থাৎ একটি বৃত্তাকার মান π=3.14159... এটি আমাদের তুলনামূলক নমুনাগুলিকে আকারে উপস্থাপন করতে দেয় দুটি অর্ধবৃত্ত, যার প্রতিটি তার নমুনার জনসংখ্যার 100% প্রতীক। একটি "প্রভাব" সহ বিষয়গুলির শতাংশগুলি কেন্দ্রীয় কোণ φ দ্বারা গঠিত সেক্টর হিসাবে উপস্থাপন করা হবে। চিত্রে। চিত্র 5.2 উদাহরণ 1 চিত্রিত করে দুটি অর্ধবৃত্ত দেখায়। প্রথম নমুনায়, 60% বিষয় সমস্যার সমাধান করেছে। এই শতাংশ কোণ φ=1.772 এর সাথে মিলে যায়। দ্বিতীয় নমুনায়, 40% বিষয় সমস্যার সমাধান করেছে। এই শতাংশ কোণ φ = 1.369 এর সাথে মিলে যায়।
φ* মানদণ্ড আমাদের নির্ধারণ করতে দেয় যে একটি কোণ প্রকৃতপক্ষে প্রদত্ত নমুনা আকারের জন্য অন্যটির থেকে পরিসংখ্যানগতভাবে উল্লেখযোগ্যভাবে উচ্চতর কিনা।
মানদণ্ডের সীমাবদ্ধতা φ*
1. তুলনা করা অনুপাতের কোনোটিই শূন্য হওয়া উচিত নয়। আনুষ্ঠানিকভাবে, φ পদ্ধতি প্রয়োগ করার ক্ষেত্রে কোন বাধা নেই যেখানে একটি নমুনায় পর্যবেক্ষণের অনুপাত 0 এর সমান। তবে, এই ক্ষেত্রে, ফলাফলটি অযৌক্তিকভাবে স্ফীত হতে পারে (Gubler E.V., 1978, p) 86)।
2. উপরের φ মাপদণ্ডে কোন সীমা নেই - নমুনাগুলি ইচ্ছামত বড় হতে পারে৷
নিম্ন সীমা - একটি নমুনায় 2টি পর্যবেক্ষণ। যাইহোক, দুটি নমুনার সংখ্যায় নিম্নলিখিত অনুপাত অবশ্যই লক্ষ্য করা উচিত:
ক) যদি একটি নমুনায় মাত্র 2টি পর্যবেক্ষণ থাকে, তবে দ্বিতীয়টিতে কমপক্ষে 30টি থাকতে হবে:
খ) যদি নমুনার একটিতে মাত্র 3টি পর্যবেক্ষণ থাকে, তবে দ্বিতীয়টিতে কমপক্ষে 7টি থাকতে হবে:
গ) যদি নমুনার একটিতে মাত্র 4টি পর্যবেক্ষণ থাকে, তবে দ্বিতীয়টিতে কমপক্ষে 5টি থাকতে হবে:
d) এn 1 , n 2 ≥ 5 যেকোনো তুলনা সম্ভব।
নীতিগতভাবে, এই শর্ত পূরণ করে না এমন নমুনাগুলির তুলনা করাও সম্ভব, উদাহরণস্বরূপ, সম্পর্কের সাথেn 1 =2, n 2 = 15, কিন্তু এই ক্ষেত্রে উল্লেখযোগ্য পার্থক্য চিহ্নিত করা সম্ভব হবে না।
φ* মানদণ্ডের অন্য কোনো সীমাবদ্ধতা নেই।
এর সম্ভাবনাগুলি ব্যাখ্যা করার জন্য কয়েকটি উদাহরণ দেখা যাকমানদণ্ড φ*.
উদাহরণ 1: গুণগতভাবে সংজ্ঞায়িত বৈশিষ্ট্য অনুযায়ী নমুনার তুলনা।
উদাহরণ 2: পরিমাণগতভাবে পরিমাপ করা বৈশিষ্ট্য অনুসারে নমুনার তুলনা।
উদাহরণ 3: একটি বৈশিষ্ট্যের স্তর এবং বিতরণ উভয় দ্বারা নমুনার তুলনা।
উদাহরণ 4: মানদণ্ডের সাথে একত্রে φ* মানদণ্ড ব্যবহার করাএক্স সবচেয়ে সঠিক ফলাফল অর্জন করার জন্য Kolmogorov-Smirnov.
উদাহরণ 1 - গুণগতভাবে সংজ্ঞায়িত বৈশিষ্ট্য অনুযায়ী নমুনার তুলনা
মানদণ্ডের এই ব্যবহারে, আমরা কিছু গুণমান দ্বারা চিহ্নিত একটি নমুনায় বিষয়ের শতাংশের সাথে একই মানের দ্বারা চিহ্নিত অন্য নমুনায় বিষয়ের শতাংশের সাথে তুলনা করি।
আসুন আমরা বলি যে একটি নতুন পরীক্ষামূলক সমস্যা সমাধানে শিক্ষার্থীদের দুটি গ্রুপ তাদের সাফল্যে ভিন্ন কিনা তা নিয়ে আমরা আগ্রহী। 20 জনের প্রথম দলে, 12 জন লোক এটির সাথে মোকাবিলা করেছে, এবং 25 জনের দ্বিতীয় নমুনায় - 10। প্রথম ক্ষেত্রে, যারা সমস্যাটি সমাধান করেছেন তাদের শতাংশ হবে 12/20·100% = 60%, এবং দ্বিতীয়টিতে 10/25·100% = 40%। তথ্য দেওয়া এই শতাংশ উল্লেখযোগ্যভাবে পৃথক?n 1 এবংn 2 ?
এটা মনে হবে যে এমনকি "চোখ দ্বারা" কেউ নির্ধারণ করতে পারে যে 60% উল্লেখযোগ্যভাবে 40% এর চেয়ে বেশি। যাইহোক, আসলে, এই পার্থক্য, তথ্য দেওয়াn 1 , n 2 অবিশ্বস্ত
আসুন এটি পরীক্ষা করে দেখি। যেহেতু আমরা একটি সমস্যা সমাধানের বিষয়টিতে আগ্রহী, তাই আমরা একটি পরীক্ষামূলক সমস্যা সমাধানে সাফল্যকে একটি "প্রভাব" হিসাবে বিবেচনা করব এবং এটির সমাধানে ব্যর্থতাকে প্রভাবের অনুপস্থিতি হিসাবে বিবেচনা করব।
আসুন অনুমান প্রণয়ন করি।
এইচ 0 : ব্যক্তির অনুপাতদ্বিতীয় গ্রুপের তুলনায় প্রথম গ্রুপে কাজটি সম্পন্ন করেছে এমন আর বেশি লোক ছিল না।
এইচ 1 : প্রথম গ্রুপে যারা কাজটি সম্পন্ন করেছে তাদের অনুপাত দ্বিতীয় গ্রুপের তুলনায় বেশি।
এখন আসুন একটি তথাকথিত চার-কোষ বা চার-ক্ষেত্রের টেবিল তৈরি করি, যা আসলে বৈশিষ্ট্যের দুটি মানের জন্য অভিজ্ঞতামূলক ফ্রিকোয়েন্সির একটি টেবিল: "একটি প্রভাব আছে" - "কোন প্রভাব নেই।"
সারণি 5.1
যারা সমস্যাটি সমাধান করেছেন তাদের শতাংশ অনুসারে বিষয়ের দুটি গ্রুপের তুলনা করার সময় মাপদণ্ড গণনার জন্য চার-কোষ টেবিল।
গোষ্ঠী | "একটি প্রভাব আছে": সমস্যাটি সমাধান করা হয়েছে | "কোন প্রভাব নেই": সমস্যার সমাধান হয় না | পরিমাণ |
||||
পরিমাণ বিষয় | % ভাগ | পরিমাণ বিষয় | % শেয়ার | ||||
1 দল | (60%) | (40%) | |||||
২য় দল | (40%) | (60%) | |||||
পরিমাণ | |||||||
একটি চার-কোষ টেবিলে, একটি নিয়ম হিসাবে, কলামগুলি "একটি প্রভাব আছে" এবং "কোন প্রভাব নেই" শীর্ষে চিহ্নিত করা হয়েছে এবং "গ্রুপ 1" এবং "গ্রুপ 2" সারিগুলি বাম দিকে রয়েছে। প্রকৃতপক্ষে, শুধুমাত্র ক্ষেত্র (কোষ) A এবং B তুলনার সাথে জড়িত, অর্থাৎ, "একটি প্রভাব আছে" কলামে শতাংশ।
টেবিল অনুযায়ী।XIIপরিশিষ্ট 1 প্রতিটি গ্রুপে শতাংশ শেয়ারের সাথে সঙ্গতিপূর্ণ φ এর মান নির্ধারণ করে।
এখন সূত্রটি ব্যবহার করে φ* এর অভিজ্ঞতামূলক মান গণনা করা যাক:
যেখানে φ 1 - বৃহত্তর % ভাগের সাথে সংশ্লিষ্ট কোণ;
φ 2 - ছোট % ভাগের সাথে সংশ্লিষ্ট কোণ;
n 1 - নমুনা 1 পর্যবেক্ষণের সংখ্যা;
n 2 - নমুনা 2-এ পর্যবেক্ষণের সংখ্যা।
এক্ষেত্রে:
টেবিল অনুযায়ী।XIIIপরিশিষ্ট 1 এ আমরা নির্ধারণ করি কোন স্তরের তাৎপর্য φ* এর সাথে মিলে যায় em=1,34:
p=0.09
মনোবিজ্ঞানে গৃহীত পরিসংখ্যানগত তাত্পর্যের স্তরের সাথে φ*-এর সমালোচনামূলক মান স্থাপন করাও সম্ভব:
আসুন একটি "তাৎপর্য অক্ষ" তৈরি করি।
প্রাপ্ত অভিজ্ঞতামূলক মান φ* তুচ্ছ অঞ্চলে রয়েছে।
উত্তর: এইচ 0 গৃহীত টাস্ক সম্পন্ন করা লোকেদের শতাংশভিপ্রথম দলটি দ্বিতীয় গ্রুপের চেয়ে বেশি নয়।
φ* মানদণ্ড ব্যবহার করে তাদের নির্ভরযোগ্যতা পরীক্ষা না করেই একজন গবেষকের প্রতি সহানুভূতি প্রকাশ করতে পারেন যিনি 20% এমনকি 10% এর পার্থক্যকেও তাৎপর্যপূর্ণ বিবেচনা করেন। এই ক্ষেত্রে, উদাহরণস্বরূপ, শুধুমাত্র অন্তত 24.3% এর পার্থক্য তাৎপর্যপূর্ণ হবে।
মনে হচ্ছে যে কোনো গুণগত ভিত্তিতে দুটি নমুনার তুলনা করার সময়, φ মানদণ্ড আমাদের খুশির পরিবর্তে দুঃখিত করতে পারে। যা তাৎপর্যপূর্ণ বলে মনে হচ্ছে তা পরিসংখ্যানগত দৃষ্টিকোণ থেকে তা নাও হতে পারে।
ফিশারের মানদণ্ডে গবেষককে খুশি করার আরও অনেক সুযোগ রয়েছে যখন আমরা পরিমাণগতভাবে পরিমাপ করা বৈশিষ্ট্য অনুসারে দুটি নমুনার তুলনা করি এবং "প্রভাব" পরিবর্তিত হতে পারে।
উদাহরণ 2 - একটি পরিমাণগতভাবে পরিমাপ করা বৈশিষ্ট্য অনুযায়ী দুটি নমুনার তুলনা
মানদণ্ডের এই ব্যবহারে, আমরা একটি নমুনায় এমন বিষয়ের শতাংশের তুলনা করি যারা একটি নির্দিষ্ট স্তরের বৈশিষ্ট্যের মান অর্জন করে অন্য নমুনায় এই স্তরটি অর্জনকারী বিষয়গুলির শতাংশের সাথে।
G. A. Tlegenova (1990) এর একটি সমীক্ষায়, 14 থেকে 16 বছর বয়সী 70 জন তরুণ ভোকেশনাল স্কুল ছাত্রদের মধ্যে, আগ্রাসন স্কেলে উচ্চ স্কোর সহ 10টি বিষয় এবং আগ্রাসন স্কেলে কম স্কোর সহ 11টি বিষয় ফলাফলের ভিত্তিতে নির্বাচিত হয়েছিল ফ্রেইবার্গ ব্যক্তিত্ব প্রশ্নাবলী ব্যবহার করে একটি সমীক্ষা। আক্রমনাত্মক এবং অ-আক্রমনাত্মক যুবকদের দলগুলি সহকর্মী ছাত্রের সাথে কথোপকথনে স্বতঃস্ফূর্তভাবে বেছে নেওয়া দূরত্বের পরিপ্রেক্ষিতে আলাদা কিনা তা নির্ধারণ করা প্রয়োজন। G. A. Tlegenova-এর তথ্য সারণীতে উপস্থাপন করা হয়েছে। 5.2। আপনি লক্ষ্য করতে পারেন যে আক্রমণাত্মক যুবকরা প্রায়শই 50 এর দূরত্ব বেছে নেয়সেমি বা তারও কম, যখন অ-আক্রমনাত্মক ছেলেরা প্রায়শই 50 সেন্টিমিটারের বেশি দূরত্ব বেছে নেয়।
এখন আমরা 50 সেমি দূরত্বকে সমালোচনামূলক হিসাবে বিবেচনা করতে পারি এবং ধরে নিতে পারি যে যদি বিষয় দ্বারা নির্বাচিত দূরত্বটি 50 সেন্টিমিটারের কম বা সমান হয়, তবে "একটি প্রভাব আছে" এবং যদি নির্বাচিত দূরত্ব 50 সেন্টিমিটারের বেশি হয়, তাহলে "কোন প্রভাব নেই।" আমরা দেখতে পাই যে আক্রমণাত্মক যুবকদের দলে 10 টির মধ্যে 7 টিতে প্রভাব পরিলক্ষিত হয়, অর্থাৎ 70% ক্ষেত্রে এবং অ-আক্রমনাত্মক যুবকদের দলে - 11 টির মধ্যে 2 টিতে, অর্থাৎ 18.2% ক্ষেত্রে। . তাদের মধ্যে পার্থক্যের তাৎপর্য প্রতিষ্ঠা করতে φ* পদ্ধতি ব্যবহার করে এই শতাংশগুলি তুলনা করা যেতে পারে।
সারণি 5.2
সহকর্মী ছাত্রের সাথে কথোপকথনে আক্রমণাত্মক এবং অ-আক্রমনাত্মক যুবকদের দ্বারা নির্বাচিত দূরত্বের সূচক (সেমিতে) (G.A. Tlegenova, 1990 অনুযায়ী)
গ্রুপ 1: আগ্রাসন স্কেলে উচ্চ স্কোর সহ ছেলেরাএফপিআই- আর (n 1 =10) | গ্রুপ 2: আগ্রাসন স্কেলে কম মানসম্পন্ন ছেলেরাএফপিআই- আর (n 2 =11) |
|||
d(c মি ) | % শেয়ার | d(c এম ) | % শেয়ার |
|
"খাওয়া প্রভাব" d≤50 সেমি | ||||
18,2% |
||||
"না প্রভাব" d>50সেমি | ||||
80 QO | 81,8% |
|||
পরিমাণ | 100% | 100% |
||
গড় | 5b:o | 77.3 | ||
আসুন অনুমান প্রণয়ন করি।
এইচ 0 d ≤ 50 সেমি, আক্রমনাত্মক ছেলেদের দলে অ-আক্রমনাত্মক ছেলেদের গ্রুপের চেয়ে বেশি কিছু নেই।
এইচ 1 : দূরত্ব বেছে নেওয়া লোকেদের অনুপাতd≤ 50 সেমি, অ-আক্রমনাত্মক যুবকদের গ্রুপের তুলনায় আক্রমণাত্মক যুবকদের দলে বেশি। এখন একটি তথাকথিত চার-কোষ টেবিল তৈরি করা যাক।
সারণি 53
আক্রমণাত্মক (nf=10) এবং অ-আক্রমনাত্মক যুবক (n2=11)
গোষ্ঠী | "একটি প্রভাব আছে": d≤50 | "কোন প্রভাব নেই." d>50 | পরিমাণ |
||||
বিষয়ের সংখ্যা | (% ভাগ) | বিষয়ের সংখ্যা | (% ভাগ) | ||||
গ্রুপ 1 - আক্রমণাত্মক যুবক | (70%) | (30%) | |||||
গ্রুপ 2 - অ-আক্রমনাত্মক যুবক | (180%) | (81,8%) | |||||
সমষ্টি | |||||||
টেবিল অনুযায়ী।XIIপরিশিষ্ট 1 প্রতিটি গ্রুপে "প্রভাব" এর শতাংশ শেয়ারের সাথে সম্পর্কিত φ এর মান নির্ধারণ করে।
প্রাপ্ত অভিজ্ঞতামূলক মান φ* তাৎপর্যের অঞ্চলে রয়েছে।
উত্তর: এইচ 0 প্রত্যাখ্যাত. গৃহীতএইচ 1 . যারা কথোপকথনে 50 সেন্টিমিটারের কম বা সমান দূরত্ব বেছে নেয় তাদের অনুপাত আক্রমণাত্মক যুবকদের দলে অ-আক্রমনাত্মক যুবকদের তুলনায় বেশি।
প্রাপ্ত ফলাফলের উপর ভিত্তি করে, আমরা এই উপসংহারে পৌঁছাতে পারি যে আরও আক্রমণাত্মক যুবকরা প্রায়শই আধা মিটারের কম দূরত্ব বেছে নেয়, যখন অ-আক্রমনাত্মক যুবকরা প্রায়শই আধা মিটারের বেশি দূরত্ব বেছে নেয়। আমরা দেখতে পাই যে আক্রমনাত্মক যুবকরা আসলে অন্তরঙ্গ (0-46 সেমি) এবং ব্যক্তিগত অঞ্চল (46 সেমি থেকে) এর মধ্যে সীমান্তে যোগাযোগ করে। যাইহোক, আমরা মনে রাখি যে, অংশীদারদের মধ্যে ঘনিষ্ঠ দূরত্ব শুধুমাত্র ঘনিষ্ঠ, ভাল সম্পর্কের বিশেষাধিকার নয়, কিন্তুএবংমল্লযুদ্ধ (হলই. টি., 1959).
উদাহরণ 3 - বৈশিষ্ট্যের স্তর এবং বিতরণ উভয় দ্বারা নমুনার তুলনা।
এই ব্যবহারের ক্ষেত্রে, আমরা প্রথমে পরীক্ষা করতে পারি যে গোষ্ঠীগুলি কিছু বৈশিষ্ট্যের স্তরে আলাদা কিনা এবং তারপরে দুটি নমুনায় বৈশিষ্ট্যের বিতরণের তুলনা করতে পারি। কোনো নতুন কৌশল ব্যবহার করে বিষয়ের দ্বারা প্রাপ্ত মূল্যায়নের বন্টনের রেঞ্জ বা আকারের পার্থক্য বিশ্লেষণ করার সময় এই ধরনের একটি কাজ প্রাসঙ্গিক হতে পারে।
R. T. Chirkina (1995) এর একটি গবেষণায়, প্রথমবারের মতো, ব্যক্তিগত, পারিবারিক এবং পেশাগত জটিলতার কারণে স্মৃতি থেকে তথ্য, নাম, উদ্দেশ্য এবং কর্মের পদ্ধতিগুলিকে দমন করার প্রবণতা চিহ্নিত করার লক্ষ্যে একটি প্রশ্নাবলী ব্যবহার করা হয়েছিল। প্রশ্নপত্রটি E.V Sidorenko-এর অংশগ্রহণে তৈরি করা হয়েছিল বই 3. ফ্রয়েড "সাইকোপ্যাথলজি অফ প্রাত্যহিক জীবনের"। পেডাগোজিকাল ইনস্টিটিউটের 50 জন শিক্ষার্থীর একটি নমুনা, অবিবাহিত, সন্তানহীন, 17 থেকে 20 বছর বয়সী, এই প্রশ্নাবলী ব্যবহার করে পরীক্ষা করা হয়েছিল, সেইসাথে ব্যক্তিগত অপ্রতুলতার অনুভূতির তীব্রতা সনাক্ত করতে মেনেস্টার-কর্জিনি কৌশল ব্যবহার করে,বা"হীনমন্যতা" (মানাস্টারজি. জে., করসিনিআর. জে., 1982).
জরিপ ফলাফল টেবিলে উপস্থাপন করা হয়. 5.4।
এটা কি বলা সম্ভব যে দমন শক্তির সূচক, একটি প্রশ্নাবলী ব্যবহার করে নির্ণয় করা এবং নিজের অপ্রতুলতার অনুভূতির তীব্রতার সূচকগুলির মধ্যে কোনও উল্লেখযোগ্য সম্পর্ক রয়েছে?
টেবিল 5.4
উচ্চ সহ শিক্ষার্থীদের গ্রুপে ব্যক্তিগত অপ্রতুলতার অনুভূতির তীব্রতার সূচক (এনজে=18) এবং নিম্ন (n2=24) স্থানচ্যুতি শক্তি
গ্রুপ 1: স্থানচ্যুতি শক্তি 19 থেকে 31 পয়েন্ট পর্যন্ত (n 1 =181 | গ্রুপ 2: স্থানচ্যুতি শক্তি 7 থেকে 13 পয়েন্ট পর্যন্ত (n 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
পরিমাণ গড় | 26,11 | 15,42 |
আরও শক্তিশালী দমনের সাথে গ্রুপে গড় মান বেশি হওয়া সত্ত্বেও, এতে 5 শূন্য মানও পরিলক্ষিত হয়। যদি আমরা দুটি নমুনায় রেটিং বিতরণের হিস্টোগ্রামের তুলনা করি, তবে তাদের মধ্যে একটি আকর্ষণীয় বৈপরীত্য প্রকাশিত হয় (চিত্র 5.3)।
দুটি বিতরণের তুলনা করতে আমরা পরীক্ষাটি প্রয়োগ করতে পারিχ 2 বা মানদণ্ডλ , কিন্তু এর জন্য আমাদের র্যাঙ্ক বড় করতে হবে, এবং উপরন্তু, উভয় নমুনায়n <30.
φ* মানদণ্ড আমাদের গ্রাফে পরিলক্ষিত দুটি বিতরণের মধ্যে পার্থক্যের প্রভাব পরীক্ষা করার অনুমতি দেবে যদি আমরা অনুমান করতে সম্মত হই যে "একটি প্রভাব আছে" যদি অপর্যাপ্ততার অনুভূতির সূচকটি হয় খুব কম (0) বা বিপরীতভাবে নেয় , খুব উচ্চ মান (এস30), এবং "কোন প্রভাব নেই" যদি অপর্যাপ্ততার অনুভূতির সূচকটি 5 থেকে 25 পর্যন্ত গড় মান নেয়।
আসুন অনুমান প্রণয়ন করি।
এইচ 0 : ঘাটতি সূচকের চরম মান (হয় 0 বা 30 বা তারও বেশি) বেশি উদ্যমী দমনের গ্রুপে কম উদ্যমী দমনের গ্রুপের তুলনায় বেশি সাধারণ নয়।
এইচ 1 : ঘাটতি সূচকের চরম মানগুলি (হয় 0 বা 30 বা তার বেশি) বেশি উদ্যমী দমনের গ্রুপে কম উদ্যমী দমনের গ্রুপের তুলনায় বেশি সাধারণ।
φ* মানদণ্ডের আরও গণনার জন্য সুবিধাজনক একটি চার-কোষ টেবিল তৈরি করা যাক।
টেবিল 5.5
অপর্যাপ্ততা সূচকের অনুপাতের উপর ভিত্তি করে উচ্চ এবং নিম্ন দমন শক্তির সাথে গ্রুপগুলির তুলনা করার সময় φ* মানদণ্ড গণনার জন্য চার-কোষ টেবিল
গোষ্ঠী | "একটি প্রভাব আছে": ঘাটতি নির্দেশক হল 0 বা>30৷ | "কোন প্রভাব নেই": ব্যর্থতার সূচক 5 থেকে 25 পর্যন্ত | পরিমাণ |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
পরিমাণ | |||||
টেবিল অনুযায়ী।XIIপরিশিষ্ট 1-এ আমরা φ-এর মান নির্ধারণ করি তুলনামূলক শতাংশের সাথে:
আসুন φ* এর অভিজ্ঞতামূলক মান গণনা করি:
যে কোনোটির জন্য φ* এর সমালোচনামূলক মানn 1 , n 2 , যেমন আমরা আগের উদাহরণ থেকে মনে করি, হল:
টেবিলXIIIপরিশিষ্ট 1 আমাদের প্রাপ্ত ফলাফলের তাত্পর্যের মাত্রা আরও সঠিকভাবে নির্ধারণ করতে দেয়: পি<0,001.
উত্তর: এইচ 0 প্রত্যাখ্যাত. গৃহীতএইচ 1 . ঘাটতি সূচকের চরম মানগুলি (হয় 0 বা 30 বা তার বেশি) বৃহত্তর দমন শক্তি সহ গ্রুপে কম দমন শক্তি সহ গোষ্ঠীর তুলনায় প্রায়শই ঘটে।
সুতরাং, বৃহত্তর দমন শক্তি সহ বিষয়গুলি তাদের নিজস্ব অপ্রতুলতার অনুভূতির খুব উচ্চ (30 বা তার বেশি) এবং খুব কম (শূন্য) উভয় সূচক থাকতে পারে। এটা অনুমান করা যেতে পারে যে তারা তাদের অসন্তুষ্টি এবং জীবনে সাফল্যের প্রয়োজনীয়তা উভয়ই দমন করছে। এই অনুমানগুলি আরও পরীক্ষার প্রয়োজন।
প্রাপ্ত ফলাফল, এর ব্যাখ্যা নির্বিশেষে, দুটি নমুনায় একটি বৈশিষ্ট্যের বন্টনের আকারে পার্থক্য মূল্যায়ন করার ক্ষেত্রে φ* মানদণ্ডের ক্ষমতা নিশ্চিত করে।
আসল নমুনাটিতে 50 জন লোক অন্তর্ভুক্ত ছিল, তবে তাদের মধ্যে 8 জনকে দমন শক্তি সূচকে গড় স্কোর (14-15) হিসাবে বিবেচনা থেকে বাদ দেওয়া হয়েছিল। অপ্রতুলতার অনুভূতির তীব্রতার তাদের সূচকগুলিও গড়: প্রতিটি 20 পয়েন্টের 6 টি মান এবং 25 পয়েন্টের 2 টি মান।
এই উদাহরণের উপাদানগুলি বিশ্লেষণ করার সময় সম্পূর্ণ ভিন্ন অনুমান নিশ্চিত করে φ* মানদণ্ডের শক্তিশালী ক্ষমতা যাচাই করা যেতে পারে। উদাহরণস্বরূপ, আমরা প্রমাণ করতে পারি যে বৃহত্তর দমন শক্তি সহ একটি গোষ্ঠীতে এই গোষ্ঠীতে এর বিতরণের বৈপরীত্য প্রকৃতি সত্ত্বেও অপর্যাপ্ততার হার এখনও বেশি।
আসুন নতুন অনুমান প্রণয়ন করি।
এইচ 0 ঘাটতি সূচকের সর্বোচ্চ মান (30 বা তার বেশি) বৃহত্তর দমন শক্তি সহ গ্রুপে কম দমন শক্তি সহ গ্রুপের চেয়ে বেশি সাধারণ নয়।
এইচ 1 : ঘাটতি সূচকের সর্বোচ্চ মান (30 বা তার বেশি) বৃহত্তর দমন শক্তি সহ গ্রুপে কম দমন শক্তি সহ গোষ্ঠীর তুলনায় প্রায়শই ঘটে। টেবিলের ডেটা ব্যবহার করে একটি চার-ক্ষেত্রের টেবিল তৈরি করা যাক। 5.4।
টেবিল 5.6
অপর্যাপ্ততা সূচকের স্তর অনুসারে বৃহত্তর এবং কম দমন শক্তির সাথে গোষ্ঠীর তুলনা করার সময় φ* মানদণ্ড গণনার জন্য চার-কোষ টেবিল
গোষ্ঠী | "একটি প্রভাব আছে"* ব্যর্থতার সূচক 30 এর চেয়ে বেশি বা সমান | "কোন প্রভাব নেই": ব্যর্থতার হার কম 30 | পরিমাণ |
||
গ্রুপ 1 - বৃহত্তর স্থানচ্যুতি শক্তি সহ | (61,1%) | (38.9%) | |||
গ্রুপ 2 - নিম্ন স্থানচ্যুতি শক্তি সহ | (25.0%) | (75.0%) | |||
পরিমাণ | |||||
টেবিল অনুযায়ী।XIIIপরিশিষ্ট 1 এ আমরা নির্ধারণ করি যে এই ফলাফলটি p = 0.008 এর তাৎপর্য স্তরের সাথে মিলে যায়।
উত্তর: কিন্তু তা প্রত্যাখ্যান করা হয়। গৃহীতHj: গ্রুপে ঘাটতির সর্বোচ্চ সূচক (30 বা তার বেশি পয়েন্ট)সঙ্গেবৃহত্তর স্থানচ্যুতি শক্তির সাথে কম স্থানচ্যুতি শক্তি (p = 0.008) গ্রুপের তুলনায় বেশি ঘটে।
সুতরাং, আমরা এটি প্রমাণ করতে সক্ষম হয়েছিভিদলসঙ্গেআরও উদ্যমী দমনের সাথে, অপর্যাপ্ততা সূচকের চরম মানগুলি প্রাধান্য পায় এবং এই সূচকটি তার মানকে ছাড়িয়ে যায়পৌঁছায়ঠিক এই গ্রুপে।
এখন আমরা প্রমাণ করার চেষ্টা করতে পারি যে উচ্চ দমন শক্তি সহ গ্রুপে, গড় মান থাকা সত্ত্বেও অপর্যাপ্ততা সূচকের নিম্ন মানগুলি বেশি সাধারণ।ভি এই গ্রুপে আরও আছে (26.11 বনাম 15.42 গ্রুপেসঙ্গে কম স্থানচ্যুতি)।
আসুন অনুমান প্রণয়ন করি।
এইচ 0 : গ্রুপে সর্বনিম্ন ঘাটতির হার (শূন্য)সঙ্গে বৃহত্তর শক্তি সহ নিপীড়ন গ্রুপের চেয়ে বেশি সাধারণ নয়সঙ্গে কম স্থানচ্যুতি শক্তি।
এইচ 1 : ঘাটতির সর্বনিম্ন হার (শূন্য) ঘটেভি বৃহত্তর দমন শক্তি সঙ্গে গ্রুপ আরো প্রায়ই গ্রুপসঙ্গে কম অনলস দমন। একটি নতুন চার-কোষ টেবিলে ডেটা গোষ্ঠীবদ্ধ করা যাক।
সারণি 5.7
ঘাটতি সূচকের শূন্য মানের ফ্রিকোয়েন্সির উপর ভিত্তি করে বিভিন্ন দমন শক্তির সাথে গ্রুপগুলির তুলনা করার জন্য চার-কোষ টেবিল
গোষ্ঠী | "একটি প্রভাব আছে": ব্যর্থতার সূচক হল 0 | অপর্যাপ্ততার "কোন প্রভাব নেই" | সূচক 0 এর সমান নয় | পরিমাণ |
|
গ্রুপ 1 - বৃহত্তর স্থানচ্যুতি শক্তি সহ | (27,8%) | (72,2%) | |||
1 গ্রুপ - কম স্থানচ্যুতি শক্তি সহ | (8,3%) | (91,7%) | |||
পরিমাণ | |||||
আমরা φ এর মান নির্ধারণ করি এবং φ* এর মান গণনা করি:
উত্তর: এইচ 0 প্রত্যাখ্যাত. বৃহত্তর দমন শক্তি সহ গোষ্ঠীতে অপ্রতুলতার সর্বনিম্ন সূচকগুলি (শূন্য) কম দমন শক্তি সহ গোষ্ঠীর তুলনায় বেশি সাধারণ (p<0,05).
মোট, প্রাপ্ত ফলাফলগুলি এস ফ্রয়েড এবং এ অ্যাডলারের জটিল ধারণাগুলির আংশিক কাকতালীয়তার প্রমাণ হিসাবে বিবেচিত হতে পারে।
এটি উল্লেখযোগ্য যে দমন শক্তির সূচক এবং সামগ্রিকভাবে নমুনায় নিজের অপ্রতুলতার অনুভূতির তীব্রতার সূচকের মধ্যে একটি ইতিবাচক রৈখিক সম্পর্ক প্রাপ্ত হয়েছিল (p = +0.491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
উদাহরণ 4 - মানদণ্ডের সাথে φ* মানদণ্ড ব্যবহার করে λ Kolmogorov-Smirnov সর্বোচ্চ অর্জন করার জন্য সঠিকফলাফল
যদি কোনো পরিমাণগতভাবে পরিমাপ করা সূচক অনুসারে নমুনাগুলি তুলনা করা হয়, তাহলে সমস্যাটি বণ্টনের বিন্দু চিহ্নিত করার ক্ষেত্রে দেখা দেয় যা সমস্ত বিষয়কে যাদের "একটি প্রভাব আছে" এবং যাদের "প্রভাব নেই" তাদের মধ্যে বিভক্ত করার জন্য একটি গুরুত্বপূর্ণ পয়েন্ট হিসাবে ব্যবহার করা যেতে পারে।
নীতিগতভাবে, যে বিন্দুতে আমরা গ্রুপটিকে উপগোষ্ঠীতে বিভক্ত করব যেখানে একটি প্রভাব আছে এবং যেখানে কোন প্রভাব নেই তা বেশ নির্বিচারে বেছে নেওয়া যেতে পারে। আমরা যে কোনও প্রভাবে আগ্রহী হতে পারি এবং তাই, আমরা উভয় নমুনাকে যে কোনও সময়ে দুটি অংশে বিভক্ত করতে পারি, যতক্ষণ না এটি কিছু অর্থবোধ করে।
φ* পরীক্ষার শক্তি সর্বাধিক করার জন্য, যাইহোক, দুটি তুলনামূলক গোষ্ঠীর মধ্যে পার্থক্য সবচেয়ে বেশি সেই বিন্দুটি নির্বাচন করা প্রয়োজন। সবচেয়ে সঠিকভাবে, আমরা মানদণ্ড গণনার জন্য একটি অ্যালগরিদম ব্যবহার করে এটি করতে পারিλ , আপনাকে দুটি নমুনার মধ্যে সর্বাধিক বৈষম্যের বিন্দু সনাক্ত করার অনুমতি দেয়।
মানদণ্ড φ* এবং একত্রিত করার সম্ভাবনাλ E.V দ্বারা বর্ণিত গুবলার (1978, পৃ. 85-88)। আসুন নিম্নলিখিত সমস্যা সমাধানে এই পদ্ধতিটি ব্যবহার করার চেষ্টা করি।
M.A দ্বারা একটি যৌথ গবেষণায় কুরোচকিনা, ই.ভি. সিডোরেঙ্কো এবং ইউ.এ. ইউকেতে চুরাকভ (1992) দুটি বিভাগের ইংরেজি সাধারণ অনুশীলনকারীদের একটি সমীক্ষা পরিচালনা করেছেন: ক) ডাক্তার যারা চিকিৎসা সংস্কারকে সমর্থন করেছিলেন এবং ইতিমধ্যে তাদের অভ্যর্থনা অফিসগুলিকে তাদের নিজস্ব বাজেটে তহবিল-ধারণকারী সংস্থায় পরিণত করেছেন; b) ডাক্তার যাদের অফিসে এখনও তাদের নিজস্ব তহবিল নেই এবং সম্পূর্ণরূপে রাজ্য বাজেট দ্বারা প্রদান করা হয়। বড় শহর বা প্রদেশে - বিভিন্ন লিঙ্গ, বয়স, পরিষেবার দৈর্ঘ্য এবং কাজের জায়গার লোকেদের প্রতিনিধিত্বের পরিপ্রেক্ষিতে 200 জন ডাক্তারের নমুনা, ইংরেজি ডাক্তারদের সাধারণ জনসংখ্যার প্রতিনিধির কাছে প্রশ্নাবলী পাঠানো হয়েছিল।
78 জন ডাক্তার প্রশ্নাবলীর উত্তর দিয়েছেন, যার মধ্যে 50 জন তহবিল সহ ওয়েটিং রুমে কাজ করেছেন এবং 28 জন ফান্ড ছাড়াই ওয়েটিং রুমে কাজ করেছেন। পরবর্তী বছর, 1993-এ তহবিলের সাথে ভর্তির ভাগ কী হবে তা প্রতিটি ডাক্তারকে ভবিষ্যদ্বাণী করতে হয়েছিল। উত্তর পাঠানো 78 জনের মধ্যে মাত্র 70 জন ডাক্তার এই প্রশ্নের উত্তর দিয়েছেন। তাদের পূর্বাভাসের বিতরণ সারণীতে উপস্থাপন করা হয়েছে। 5.8 ফান্ড সহ ডাক্তারদের গ্রুপ এবং ফান্ড ছাড়া ডাক্তারদের গ্রুপের জন্য আলাদাভাবে।
তহবিল সহ ডাক্তার এবং তহবিল ছাড়া ডাক্তারদের পূর্বাভাস কি কোন উপায়ে আলাদা?
টেবিল 5.8
1993 সালে তহবিল সহ জরুরী কক্ষের ভাগ কী হবে সে সম্পর্কে সাধারণ অনুশীলনকারীদের কাছ থেকে পূর্বাভাসের বিতরণ
প্রজেক্টেড শেয়ার | |||
তহবিল সহ অভ্যর্থনা কক্ষ | তহবিলের সাথে ডাক্তাররা (n 1 =45) | তহবিল ছাড়া ডাক্তার (n 2 =25) | পরিমাণ |
1. 0 থেকে 20% | 4 | 5 | 9 |
2. 21 থেকে 40% | 15 | এবং | 26 |
3. 41 থেকে 60% | 18 | 5 | 23 |
4. 61 থেকে 80% | 7 | 4 | এবং |
5. 81 থেকে 100% | 1 | 0 | 1 |
পরিমাণ | 45 | 25 | 70 |
আসুন ক্লজ 4.3 (টেবিল 5.9 দেখুন) থেকে অ্যালগরিদম 15 ব্যবহার করে উত্তরের দুটি বিতরণের মধ্যে সর্বাধিক বৈষম্যের বিন্দু নির্ধারণ করি।
টেবিল 5.9
দুটি গ্রুপের ডাক্তারদের পূর্বাভাসের বিতরণে জমে থাকা ফ্রিকোয়েন্সিগুলির সর্বাধিক পার্থক্যের গণনা
তহবিল সহ ভর্তির অনুমিত ভাগ (%) | প্রদত্ত প্রতিক্রিয়া বিভাগের জন্য পছন্দের অভিজ্ঞতামূলক ফ্রিকোয়েন্সি | অভিজ্ঞতামূলক ফ্রিকোয়েন্সি | ক্রমবর্ধমান অভিজ্ঞতামূলক ফ্রিকোয়েন্সি | পার্থক্য (ঘ) |
|||
তহবিল সঙ্গে ডাক্তার(n 1 =45) | তহবিল ছাড়া ডাক্তার (n 2 =25) | চ* উহ 1 | চ* a2 | ∑চ* e1 | ∑চ* a1 |
||
1. 0 থেকে 20% 2. 21 থেকে 40% 3. 41 থেকে 60% 4. 61 থেকে 80% 5. 81 থেকে 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
দুটি পুঞ্জীভূত অভিজ্ঞতামূলক ফ্রিকোয়েন্সির মধ্যে সর্বাধিক পার্থক্য সনাক্ত করা হয়0,218.
এই পার্থক্যটি পূর্বাভাসের দ্বিতীয় বিভাগে জমা হতে দেখা যাচ্ছে। আসুন উভয় নমুনাকে একটি উপগোষ্ঠীতে বিভক্ত করার জন্য এই বিভাগের উপরের সীমাটিকে একটি মানদণ্ড হিসাবে ব্যবহার করার চেষ্টা করি যেখানে "একটি প্রভাব আছে" এবং একটি উপগোষ্ঠী যেখানে "কোন প্রভাব নেই।" আমরা অনুমান করব যে একটি "প্রভাব" আছে যদি একজন প্রদত্ত ডাক্তার 41 থেকে 100% ভর্তির পূর্বাভাস দেন1993 বছর, এবং যে "কোন প্রভাব নেই" যদি একজন প্রদত্ত ডাক্তার 0 থেকে 40% ভর্তির ভবিষ্যদ্বাণী করে1993 বছর আমরা একদিকে পূর্বাভাস বিভাগ 1 এবং 2 এবং অন্য দিকে পূর্বাভাস বিভাগ 3, 4 এবং 5 একত্রিত করি। পূর্বাভাসের ফলাফল বন্টন সারণিতে উপস্থাপন করা হয়েছে। 5.10।
সারণি 5.10
তহবিল সহ ডাক্তার এবং তহবিল ছাড়া ডাক্তারদের জন্য পূর্বাভাস বিতরণ
তহবিলের সাথে ভর্তির অনুমিত ভাগ (%1 | একটি প্রদত্ত পূর্বাভাস বিভাগ নির্বাচন করার জন্য অভিজ্ঞতামূলক ফ্রিকোয়েন্সি | পরিমাণ |
|
তহবিল সঙ্গে ডাক্তার(n 1 =45) | তহবিল ছাড়াই ডাক্তার(n 2 =25) |
||
1. 0 থেকে 40% পর্যন্ত | 19 | 16 | 35 |
2. 41 থেকে 100% | 26 | 9 | 35 |
পরিমাণ | 45 | 25 | 70 |
আমরা ফলাফল টেবিল (সারণী 5.10) ব্যবহার করে এর যেকোনো দুটি কোষের তুলনা করে বিভিন্ন অনুমান পরীক্ষা করতে পারি। আমরা মনে করি যে এটি তথাকথিত চার-কোষ, বা চার-ক্ষেত্র, টেবিল।
এখানে, আমরা আগ্রহী যে চিকিত্সকদের কাছে ইতিমধ্যে তহবিল রয়েছে তারা এই আন্দোলনের বৃহত্তর ভবিষ্যত বৃদ্ধির ভবিষ্যদ্বাণী করে যে চিকিৎসকদের কাছে তহবিল নেই। অতএব, আমরা শর্তসাপেক্ষে বিবেচনা করি যে "একটি প্রভাব আছে" যখন পূর্বাভাসটি 41 থেকে 100% বিভাগে পড়ে। গণনা সহজ করার জন্য, আমাদের এখন টেবিলটিকে ঘড়ির কাঁটার দিকে ঘুরিয়ে 90° ঘোরাতে হবে। এমনকি আপনি টেবিলের সাথে বইটি ঘুরিয়ে আক্ষরিক অর্থে এটি করতে পারেন। এখন আমরা φ* মানদণ্ড - ফিশারের কৌণিক রূপান্তর গণনার জন্য ওয়ার্কশীটে যেতে পারি।
টেবিল 5.11
সাধারণ অনুশীলনকারীদের দুটি গ্রুপের পূর্বাভাসের পার্থক্য সনাক্ত করতে ফিশারের φ* মানদণ্ড গণনা করার জন্য চার-কোষ টেবিল
গ্রুপ | একটি প্রভাব আছে - 41 থেকে 100% পর্যন্ত পূর্বাভাস | কোন প্রভাব নেই - 0 থেকে 40% পর্যন্ত পূর্বাভাস | মোট |
আমিগ্রুপ - ডাক্তার যারা তহবিল নিয়েছে | 26 (57.8%) | 19 (42.2%) | 45 |
২গ্রুপ - ডাক্তার যারা তহবিল নেননি | 9 (36.0%) | 16 (64.0%) | 25 |
মোট | 35 | 35 | 70 |
আসুন অনুমান প্রণয়ন করি।
এইচ 0 : ব্যক্তির অনুপাতসমস্ত ডাক্তারের অফিসের 41%-100% তহবিল ছড়িয়ে পড়ার পূর্বাভাস, তহবিল সহ ডাক্তারদের গ্রুপে তহবিল ছাড়াই ডাক্তারদের গ্রুপের চেয়ে বেশি নেই।
এইচ 1 : সমস্ত ভর্তির 41%-100% পর্যন্ত তহবিল ছড়িয়ে পড়ার ভবিষ্যদ্বাণী করা লোকের অনুপাত তহবিলহীন ডাক্তারদের গ্রুপের তুলনায় তহবিলযুক্ত ডাক্তারদের গ্রুপে বেশি।
φ এর মান নির্ণয় কর 1 এবং φ 2 টেবিল অনুযায়ীXIIপরিশিষ্ট 1. স্মরণ করুন যে φ 1 সর্বদা বৃহত্তর শতাংশের সাথে সংশ্লিষ্ট কোণ।
এখন মানদণ্ডের অভিজ্ঞতামূলক মান নির্ধারণ করা যাক φ*:
টেবিল অনুযায়ী।XIIIপরিশিষ্ট 1 এ আমরা নির্ধারণ করি যে এই মানটি কোন স্তরের তাত্পর্যের সাথে মিলে যায়: p = 0.039৷
পরিশিষ্ট 1-এ একই টেবিল ব্যবহার করে, আপনি মানদণ্ডের সমালোচনামূলক মান নির্ধারণ করতে পারেন φ*:
উত্তর: কিন্তু এটি প্রত্যাখ্যাত (p=0.039)। ফান্ডের বিস্তারের পূর্বাভাস দেওয়া লোকেদের ভাগ41-100 % তহবিল গ্রহণকারী ডাক্তারদের গ্রুপের সমস্ত অভ্যর্থনা এই তহবিল না নেওয়া ডাক্তারদের গ্রুপে এই ভাগের বেশি।
অন্য কথায়, যে ডাক্তাররা ইতিমধ্যে একটি পৃথক বাজেটে তাদের ওয়েটিং রুমে কাজ করেন তারা এই বছর এই অনুশীলনের ব্যাপক বিস্তারের পূর্বাভাস দিয়েছেন যে ডাক্তাররা এখনও স্বাধীন বাজেটে যেতে রাজি হননি। এই ফলাফলের একাধিক ব্যাখ্যা আছে। উদাহরণস্বরূপ, এটি ধরে নেওয়া যেতে পারে যে প্রতিটি গ্রুপের ডাক্তাররা অবচেতনভাবে তাদের আচরণকে আরও সাধারণ বলে মনে করেন। এর অর্থ এমনও হতে পারে যে ডাক্তাররা যারা ইতিমধ্যে স্ব-তহবিল গ্রহণ করেছেন তারা এই আন্দোলনের সুযোগকে অতিরঞ্জিত করে, কারণ তাদের তাদের সিদ্ধান্তকে ন্যায্যতা দিতে হবে। চিহ্নিত পার্থক্যগুলি এমন কিছু বোঝাতে পারে যা অধ্যয়নে উত্থাপিত প্রশ্নের সুযোগের বাইরে। উদাহরণস্বরূপ, একটি স্বাধীন বাজেটে কাজ করা ডাক্তারদের কার্যকলাপ উভয় গ্রুপের অবস্থানের পার্থক্যকে তীক্ষ্ণ করতে অবদান রাখে। তারা যখন তহবিল নিতে রাজি হয়েছিল তখন তারা আরও সক্রিয় ছিল; তারা আরও সক্রিয় হয় যখন তারা ভবিষ্যদ্বাণী করে যে অন্যান্য চিকিত্সকরা তহবিল গ্রহণে আরও সক্রিয় হবেন।
এক উপায় বা অন্যভাবে, আমরা নিশ্চিত হতে পারি যে পরিসংখ্যানগত পার্থক্যের সনাক্ত করা স্তর এই বাস্তব ডেটার জন্য সর্বাধিক সম্ভব। আমরা মানদণ্ড ব্যবহার করে প্রতিষ্ঠিতλ দুটি বিতরণের মধ্যে সর্বাধিক বিচ্যুতির বিন্দু, এবং এই সময়ে নমুনা দুটি ভাগে বিভক্ত ছিল।
আপনার চিহ্ন.
এই উদাহরণে, আমরা বিবেচনা করব কিভাবে ফলাফল রিগ্রেশন সমীকরণের নির্ভরযোগ্যতা মূল্যায়ন করা হয়। একই পরীক্ষাটি অনুমান পরীক্ষা করতে ব্যবহৃত হয় যে রিগ্রেশন সহগ একই সাথে শূন্য, a=0, b=0 এর সমান। অন্য কথায়, গণনার সারমর্ম হল প্রশ্নের উত্তর দেওয়া: এটি কি আরও বিশ্লেষণ এবং পূর্বাভাসের জন্য ব্যবহার করা যেতে পারে?
দুটি নমুনার পার্থক্য একই বা ভিন্ন কিনা তা নির্ধারণ করতে, এই টি-পরীক্ষাটি ব্যবহার করুন।
সুতরাং, বিশ্লেষণের উদ্দেশ্য হল এমন কিছু অনুমান পাওয়া যা দিয়ে বলা যেতে পারে যে α এর একটি নির্দিষ্ট স্তরে ফলাফল রিগ্রেশন সমীকরণটি পরিসংখ্যানগতভাবে নির্ভরযোগ্য। এই জন্য নির্ণয়ের সহগ R 2 ব্যবহৃত হয়.
ফিশারের এফ পরীক্ষা ব্যবহার করে রিগ্রেশন মডেলের তাৎপর্য পরীক্ষা করা হয়, যার গণনা করা মান অধ্যয়ন করা সূচকটির পর্যবেক্ষণের মূল সিরিজের বৈচিত্র্যের অনুপাত এবং অবশিষ্ট ক্রমটির ভিন্নতার নিরপেক্ষ অনুমান হিসাবে পাওয়া যায়। এই মডেলের জন্য।
যদি k 1 =(m) এবং k 2 =(n-m-1) স্বাধীনতার ডিগ্রী সহ গণনা করা মান একটি প্রদত্ত তাৎপর্য স্তরে সারণীকৃত মানের চেয়ে বেশি হয়, তাহলে মডেলটিকে তাৎপর্যপূর্ণ হিসাবে বিবেচনা করা হবে।
যেখানে m হল মডেলের ফ্যাক্টরের সংখ্যা।
পেয়ারড লিনিয়ার রিগ্রেশনের পরিসংখ্যানগত তাত্পর্য নিম্নলিখিত অ্যালগরিদম ব্যবহার করে মূল্যায়ন করা হয়:
1. একটি শূন্য হাইপোথিসিস সামনে রাখা হয়েছে যে সামগ্রিকভাবে সমীকরণটি পরিসংখ্যানগতভাবে নগণ্য: H 0: R 2 =0 তাত্পর্য স্তরে α।
2. পরবর্তী, F-মাপদণ্ডের প্রকৃত মান নির্ধারণ করুন: ![]()
![]()
যেখানে পেয়ারওয়াইজ রিগ্রেশনের জন্য m=1।
3. একটি প্রদত্ত তাৎপর্য স্তরের জন্য ফিশার বন্টন সারণী থেকে সারণীকৃত মান নির্ধারণ করা হয়, মোট বর্গক্ষেত্রের (বৃহত্তর বৈচিত্র্য) জন্য স্বাধীনতা ডিগ্রীর সংখ্যা 1 এবং অবশিষ্টদের জন্য স্বাধীনতা ডিগ্রীর সংখ্যা। রৈখিক রিগ্রেশনে বর্গক্ষেত্রের সমষ্টি (ছোট প্রকরণ) হল n-2 (বা এক্সেল ফাংশনের মাধ্যমে FRIST(সম্ভাব্যতা,1,n-2))।
F টেবিল হল প্রদত্ত স্বাধীনতা এবং তাত্পর্য স্তর α সহ এলোমেলো কারণগুলির প্রভাবের অধীনে মানদণ্ডের সর্বাধিক সম্ভাব্য মান। তাত্পর্য স্তর α হল সঠিক অনুমানকে প্রত্যাখ্যান করার সম্ভাবনা, যদি এটি সত্য হয়। সাধারণত α কে 0.05 বা 0.01 ধরা হয়।
4. যদি F-পরীক্ষার প্রকৃত মান টেবিলের মানের থেকে কম হয়, তাহলে তারা বলে যে শূন্য অনুমান প্রত্যাখ্যান করার কোন কারণ নেই।
অন্যথায়, শূন্য হাইপোথিসিস প্রত্যাখ্যান করা হয় এবং সামগ্রিকভাবে সমীকরণের পরিসংখ্যানগত তাত্পর্য সম্পর্কে বিকল্প হাইপোথিসিস সম্ভাব্যতা (1-α) সহ গৃহীত হয়।
স্বাধীনতার ডিগ্রী সহ মানদণ্ডের সারণী মান k 1 =1 এবং k 2 =48, F টেবিল = 4
উপসংহার: যেহেতু প্রকৃত মান F > F টেবিল, নির্ণয়ের সহগ পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ ( প্রাপ্ত রিগ্রেশন সমীকরণ অনুমান পরিসংখ্যানগতভাবে নির্ভরযোগ্য) .
বৈচিত্র্যের বিশ্লেষণ
.রিগ্রেশন সমীকরণ মানের সূচক
উদাহরণ। মোট 25 টি ট্রেডিং এন্টারপ্রাইজের উপর ভিত্তি করে, নিম্নলিখিত বৈশিষ্ট্যগুলির মধ্যে সম্পর্ক অধ্যয়ন করা হয়: X - পণ্য A এর মূল্য, হাজার রুবেল; Y হল একটি ট্রেডিং এন্টারপ্রাইজের লাভ, মিলিয়ন রুবেল। রিগ্রেশন মডেলের মূল্যায়ন করার সময়, নিম্নলিখিত মধ্যবর্তী ফলাফলগুলি প্রাপ্ত হয়েছিল: ∑(y i -y x) 2 = 46000; ∑(y i -y avg) 2 = 138000। এই ডেটা থেকে কোন পারস্পরিক সম্পর্ক নির্দেশক নির্ধারণ করা যায়? এই ফলাফল এবং ব্যবহারের উপর ভিত্তি করে এই সূচকের মান গণনা করুন ফিশারের এফ পরীক্ষারিগ্রেশন মডেলের গুণমান সম্পর্কে সিদ্ধান্তে আঁকুন।
সমাধান। এই তথ্য থেকে আমরা পরীক্ষামূলক পারস্পরিক সম্পর্ক অনুপাত নির্ধারণ করতে পারি:  , যেখানে ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000।
, যেখানে ∑(y avg -y x) 2 = ∑(y i -y avg) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92,000।
η 2 = 92,000/138000 = 0.67, η = 0.816 (0.7< η < 0.9 - связь между X и Y высокая).
ফিশারের এফ পরীক্ষা: n = 25, m = 1।
R 2 = 1 - 46000/138000 = 0.67, F = 0.67/(1-0.67)x(25 - 1 - 1) = 46. F টেবিল (1; 23) = 4.27
যেহেতু প্রকৃত মান F > Ftable, রিগ্রেশন সমীকরণের পাওয়া অনুমান পরিসংখ্যানগতভাবে নির্ভরযোগ্য।
প্রশ্ন: রিগ্রেশন মডেলের তাৎপর্য পরীক্ষা করার জন্য কোন পরিসংখ্যান ব্যবহার করা হয়?
উত্তর: সামগ্রিকভাবে সম্পূর্ণ মডেলের তাৎপর্যের জন্য, F- পরিসংখ্যান (ফিশারের পরীক্ষা) ব্যবহার করা হয়।
দুটি সাধারণভাবে বিতরণ করা জনসংখ্যার তুলনা করার জন্য যেগুলির নমুনায় কোনও পার্থক্য নেই, তবে পার্থক্যগুলির মধ্যে পার্থক্য রয়েছে, ব্যবহার করুন ফিশার পরীক্ষা. প্রকৃত মানদণ্ড সূত্র ব্যবহার করে গণনা করা হয়:
যেখানে লব হল নমুনা প্রকরণের বড় মান, এবং হর হল ছোট। নমুনার মধ্যে পার্থক্য নির্ভরযোগ্যতা উপসংহারে, ব্যবহার করুন মৌলিক নীতি
পরিসংখ্যানগত অনুমান পরীক্ষা করা। জন্য সমালোচনামূলক পয়েন্ট  টেবিলের মধ্যে রয়েছে। প্রকৃত মান হলে নাল অনুমান প্রত্যাখ্যান করা হয়
টেবিলের মধ্যে রয়েছে। প্রকৃত মান হলে নাল অনুমান প্রত্যাখ্যান করা হয় 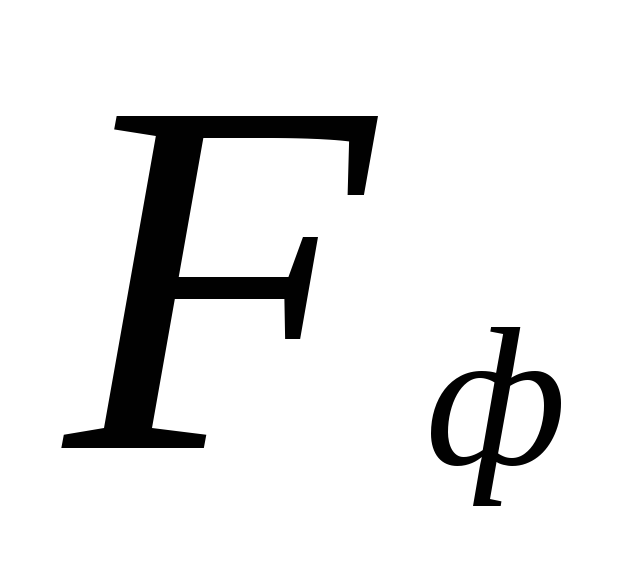 সমালোচনামূলক (মান) মান অতিক্রম করবে বা সমান হবে
সমালোচনামূলক (মান) মান অতিক্রম করবে বা সমান হবে  গৃহীত তাত্পর্য স্তরের জন্য এই মান
এবং স্বাধীনতা ডিগ্রী সংখ্যা k
1
=
n
বড়
-1
;
k
2
=
n
ছোট
-1
.
গৃহীত তাত্পর্য স্তরের জন্য এই মান
এবং স্বাধীনতা ডিগ্রী সংখ্যা k
1
=
n
বড়
-1
;
k
2
=
n
ছোট
-1
.
উদাহরণ: বীজের অঙ্কুরোদগমের হারের উপর একটি নির্দিষ্ট ওষুধের প্রভাব অধ্যয়ন করার সময়, এটি পাওয়া গেছে যে বীজের পরীক্ষামূলক ব্যাচ এবং নিয়ন্ত্রণে, গড় অঙ্কুরোদগমের হার একই, তবে পার্থক্যগুলির মধ্যে পার্থক্য রয়েছে।  =1250,
=1250, =417। নমুনার আকার একই এবং 20 এর সমান।
=417। নমুনার আকার একই এবং 20 এর সমান। 
 =2.12। অতএব, শূন্য অনুমান প্রত্যাখ্যান করা হয়.
=2.12। অতএব, শূন্য অনুমান প্রত্যাখ্যান করা হয়.
পারস্পরিক নির্ভরতা। পারস্পরিক সম্পর্ক সহগ এবং এর বৈশিষ্ট্য। রিগ্রেশন সমীকরণ।
টাস্কপারস্পরিক সম্পর্ক বিশ্লেষণ নিচে আসে:
বৈশিষ্ট্যগুলির মধ্যে সংযোগের দিক এবং ফর্ম স্থাপন করা;
তার নিবিড়তা পরিমাপ.
কার্যকরী পরিবর্তনশীল পরিমাণের মধ্যে একটি দ্ব্যর্থহীন সম্পর্ক বলা হয় যখন একটি (স্বতন্ত্র) পরিবর্তনশীলের একটি নির্দিষ্ট মান এক্স , একটি আর্গুমেন্ট বলা হয়, অন্য (নির্ভরশীল) ভেরিয়েবলের একটি নির্দিষ্ট মানের সাথে মিলে যায় এ , একটি ফাংশন বলা হয়। ( উদাহরণ: তাপমাত্রার উপর রাসায়নিক বিক্রিয়ার হারের নির্ভরতা; আকর্ষণকারী দেহের জনসাধারণের উপর আকর্ষণ শক্তির নির্ভরতা এবং তাদের মধ্যে দূরত্ব)।
পারস্পরিক সম্পর্ক ভেরিয়েবলের মধ্যে একটি সম্পর্ক যা প্রকৃতিতে পরিসংখ্যানগত, যখন একটি বৈশিষ্ট্যের একটি নির্দিষ্ট মান (একটি স্বাধীন পরিবর্তনশীল হিসাবে বিবেচিত) অন্য বৈশিষ্ট্যের সংখ্যাসূচক মানের সম্পূর্ণ সিরিজের সাথে মিলে যায়। ( উদাহরণ: ফসল কাটা এবং বৃষ্টিপাতের মধ্যে সম্পর্ক; উচ্চতা এবং ওজন, ইত্যাদির মধ্যে)।
পারস্পরিক সম্পর্ক ক্ষেত্র বিন্দুর একটি সেট প্রতিনিধিত্ব করে যার স্থানাঙ্ক পরীক্ষামূলকভাবে প্রাপ্ত পরিবর্তনশীল মানের জোড়ার সমান এক্স এবং এ .
পারস্পরিক সম্পর্ক ক্ষেত্রের ধরন দ্বারা একজন সংযোগের উপস্থিতি বা অনুপস্থিতি এবং এর ধরন বিচার করতে পারে।




সংযোগ বলা হয় ইতিবাচক , যদি একটি ভেরিয়েবল বাড়ে, অন্য একটি ভেরিয়েবল বাড়ে।
সংযোগ বলা হয় নেতিবাচক , যদি একটি ভেরিয়েবল বাড়ে, অন্য একটি পরিবর্তনশীল হ্রাস পায়।
সংযোগ বলা হয় রৈখিক
, যদি এটি বিশ্লেষণাত্মকভাবে উপস্থাপন করা যায় 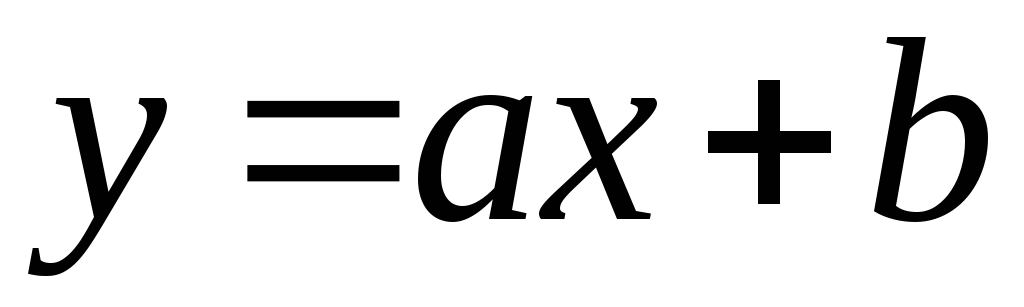 .
.
সংযোগ ঘনিষ্ঠতা একটি সূচক হয় পারস্পরিক সম্পর্ক সহগ . অভিজ্ঞতামূলক পারস্পরিক সম্পর্ক সহগ দ্বারা দেওয়া হয়:

পারস্পরিক সম্পর্ক সহগ থেকে রেঞ্জ -1 আগে 1 এবং পরিমাণের মধ্যে ঘনিষ্ঠতার মাত্রা চিহ্নিত করে এক্স এবং y . যদি:

বৈশিষ্ট্যের মধ্যে পারস্পরিক সম্পর্ক বিভিন্ন উপায়ে বর্ণনা করা যেতে পারে। বিশেষ করে, সংযোগের যেকোনো রূপকে সাধারণ ফর্মের সমীকরণ দ্বারা প্রকাশ করা যেতে পারে 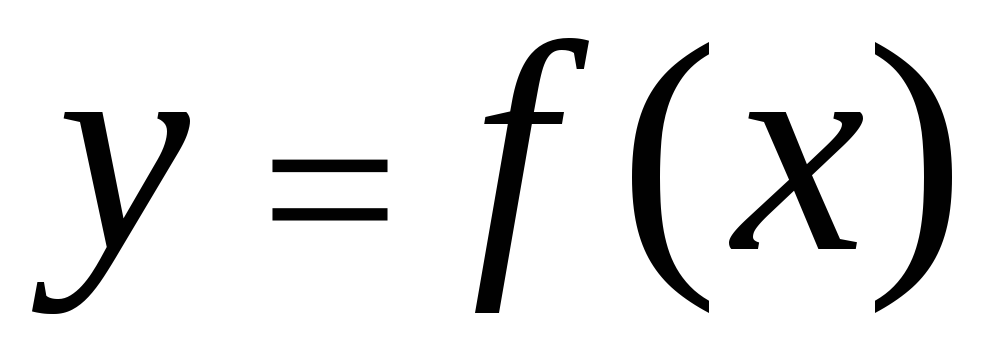 . ফর্মের সমীকরণ
. ফর্মের সমীকরণ  এবং
এবং 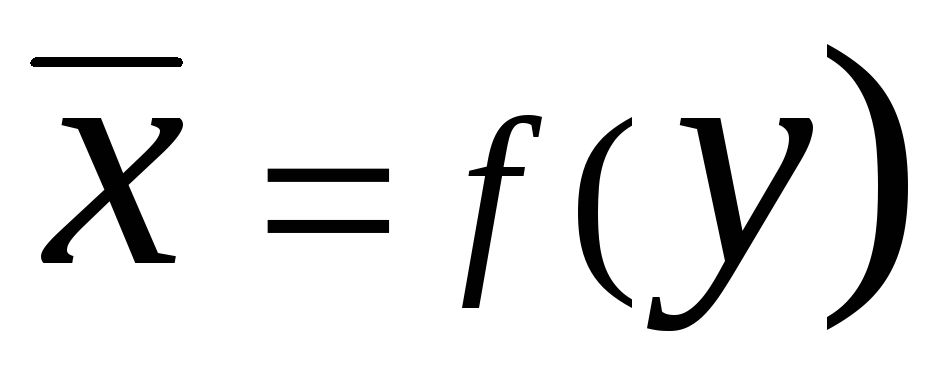 ডাকল রিগ্রেশন
. ফরোয়ার্ড রিগ্রেশন সমীকরণ এ
চালু এক্স
সাধারণ ক্ষেত্রে ফর্মে লেখা যেতে পারে
ডাকল রিগ্রেশন
. ফরোয়ার্ড রিগ্রেশন সমীকরণ এ
চালু এক্স
সাধারণ ক্ষেত্রে ফর্মে লেখা যেতে পারে

ফরোয়ার্ড রিগ্রেশন সমীকরণ এক্স চালু এ সাধারণভাবে এটা মনে হচ্ছে

সহগগুলির সবচেয়ে সম্ভাব্য মান কএবং ভি, সঙ্গেএবং dগণনা করা যেতে পারে, উদাহরণস্বরূপ, সর্বনিম্ন বর্গ পদ্ধতি ব্যবহার করে।







