Method steepest descent(in English literature “method of steepest descent”) is an iterative numerical method (first order) for solving optimization problems, which allows you to determine the extremum (minimum or maximum) of the objective function:
![]() are the values of the function argument (controlled parameters) on the real domain.
are the values of the function argument (controlled parameters) on the real domain.
In accordance with the method under consideration, the extremum (maximum or minimum) of the objective function is determined in the direction of the fastest increase (decrease) of the function, i.e. in the direction of the gradient (anti-gradient) of the function. Gradient function at a point ![]() is a vector whose projections onto the coordinate axes are the partial derivatives of the function with respect to the coordinates:
is a vector whose projections onto the coordinate axes are the partial derivatives of the function with respect to the coordinates:
where i, j,…, n are unit vectors parallel to the coordinate axes.
Gradient at base point ![]() is strictly orthogonal to the surface, and its direction shows the direction of the fastest increase in the function, and the opposite direction (antigradient), respectively, shows the direction of the fastest decrease of the function.
is strictly orthogonal to the surface, and its direction shows the direction of the fastest increase in the function, and the opposite direction (antigradient), respectively, shows the direction of the fastest decrease of the function.
The steepest descent method is further development gradient descent method. IN general case The process of finding the extremum of a function is an iterative procedure, which is written as follows:

where the "+" sign is used to find the maximum of a function, and the "-" sign is used to find the minimum of a function;
Unit direction vector, which is determined by the formula:

![]() - the gradient module determines the rate of increase or decrease of the function in the direction of the gradient or anti-gradient:
- the gradient module determines the rate of increase or decrease of the function in the direction of the gradient or anti-gradient:

A constant that determines the step size and is the same for all i-th directions.
The step size is selected from the condition of the minimum of the objective function f(x) in the direction of movement, i.e., as a result of solving the one-dimensional optimization problem in the direction of the gradient or antigradient:
In other words, the step size is determined by solving this equation:
![]()
Thus, the calculation step is chosen such that the movement is carried out until the function improves, thus reaching an extremum at some point. At this point, the search direction is again determined (using the gradient) and a new optimum point of the objective function is sought, etc. Thus, in this method, the search occurs in larger steps, and the gradient of the function is calculated at a smaller number of points.
In the case of a function of two variables this method has the following geometric interpretation: the direction of movement from a point touches the level line at point . The descent trajectory is zigzag, with adjacent zigzag links orthogonal to each other. The condition for the orthogonality of the vectors of descent directions at neighboring points is written by the following expression:
![]()

The trajectory of movement to the extremum point using the steepest descent method, shown on the graph of the line of equal level of the function f(x)
The search for an optimal solution ends when at the iterative calculation step (several criteria):
The search trajectory remains in a small neighborhood of the current search point:
The increment of the objective function does not change:
![]()
The gradient of the objective function at the local minimum point becomes zero:
It should be noted that the gradient descent method turns out to be very slow when moving along a ravine, and as the number of variables in the objective function increases, this behavior of the method becomes typical. The ravine is a depression, the level lines of which approximately have the shape of ellipses with semi-axes differing many times over. In the presence of a ravine, the descent trajectory takes the form of a zigzag line with a small step, as a result of which the resulting speed of descent to a minimum is greatly slowed down. This is explained by the fact that the direction of the antigradient of these functions deviates significantly from the direction to the minimum point, which leads to an additional delay in the calculation. As a result, the algorithm loses computational efficiency.

Gully function
The gradient method, along with its many modifications, is widespread and effective method searching for the optimum of the objects under study. The disadvantage of gradient search (as well as the methods discussed above) is that when using it, only the local extremum of the function can be detected. To find others local extremes it is necessary to search from other starting points. Also, the speed of convergence of gradient methods also significantly depends on the accuracy of gradient calculations. Loss of accuracy, which usually occurs in the vicinity of minimum points or in a gully situation, can generally disrupt the convergence of the gradient descent process.
Calculation method
Step 1: Definition of analytical expressions (in symbolic form) for calculating the gradient of a function

Step 2: Set the initial approximation
Step 3: The need to restart the algorithmic procedure to reset the last search direction is determined. As a result of the restart, the search is carried out again in the direction of the fastest descent.
You can also search not for the best point in the direction of the gradient, but for some one better than the current one.
The easiest to implement of all local optimization methods. Has quite weak conditions convergence, but the rate of convergence is quite low (linear). Step gradient method often used as part of other optimization methods, such as the Fletcher–Reeves method.
Description [ | ]
Improvements[ | ]
The gradient descent method turns out to be very slow when moving along a ravine, and as the number of variables in the objective function increases, this behavior of the method becomes typical. To combat this phenomenon, it is used, the essence of which is very simple. Having made two steps of gradient descent and obtained three points, the third step should be taken in the direction of the vector connecting the first and third points, along the bottom of the ravine.
For functions close to quadratic, the conjugate gradient method is effective.
Application in artificial neural networks[ | ]
The gradient descent method, with some modification, is widely used for perceptron training and is known in the theory of artificial neural networks as the backpropagation method. When training a perceptron-type neural network, it is necessary to change the weighting coefficients of the network so as to minimize average error at the output of the neural network when a sequence of training input data is supplied to the input. Formally, in order to take just one step using the gradient descent method (make just one change in the network parameters), it is necessary to sequentially submit absolutely the entire set of training data to the network input, calculate the error for each object of the training data and calculate the necessary correction of the network coefficients (but not do this correction), and after submitting all the data, calculate the amount in the correction of each network coefficient (sum of gradients) and correct the coefficients “one step”. Obviously, with a large set of training data, the algorithm will work extremely slowly, so in practice, network coefficients are often adjusted after each training element, where the gradient value is approximated by the gradient of the cost function, calculated on only one training element. This method is called stochastic gradient descent or operational gradient descent . Stochastic gradient descent is a form of stochastic approximation. The theory of stochastic approximations provides conditions for the convergence of the stochastic gradient descent method.
Links [ | ]
- J. Mathews. Module for Steepest Descent or Gradient Method. (unavailable link)
Literature [ | ]
- Akulich I. L. Mathematical programming in examples and problems. - M.: Higher School, 1986. - P. 298-310.
- Gill F., Murray W., Wright M. Practical optimization = Practical Optimization. - M.: Mir, 1985.
- Korshunov Yu. M., Korshunov Yu. M. Mathematical foundations of cybernetics. - M.: Energoatomizdat, 1972.
- Maksimov Yu. A., Fillipovskaya E. A. Algorithms for solving nonlinear programming problems. - M.: MEPhI, 1982.
- Maksimov Yu. A. Algorithms for linear and discrete programming. - M.: MEPhI, 1980.
- Korn G., Korn T. Handbook of mathematics for scientists and engineers. - M.: Nauka, 1970. - P. 575-576.
- S. Yu. Gorodetsky, V. A. Grishagin. Nonlinear programming and multiextremal optimization. - Nizhny Novgorod: Nizhny Novgorod University Publishing House, 2007. - pp. 357-363.
Rules for entering a function
IN steepest descent method a vector whose direction is opposite to the direction of the gradient vector of the function ▽f(x) is selected as the search direction. From mathematical analysis it is known that the vector grad f(x)=▽f(x) characterizes the direction of the fastest increase in the function (see gradient of the function). Therefore, the vector - grad f (X) = -▽f(X) is called anti-gradient and is the direction of its fastest decrease. The recurrence relation with which the steepest descent method is implemented has the form X k +1 =X k - λ k ▽f(x k), k = 0,1,...,
where λ k >0 is the step size. Depending on the choice of step size, you can get various options gradient method. If during the optimization process the step size λ is fixed, then the method is called the gradient method with a discrete step. The optimization process in the first iterations can be significantly accelerated if λ k is selected from the condition λ k =min f(X k + λS k) .
To determine λ k, any one-dimensional optimization method is used. In this case, the method is called the steepest descent method. As a rule, in the general case, one step is not enough to achieve the minimum of the function; the process is repeated until subsequent calculations improve the result.
If the space is very elongated in some variables, then a “ravine” is formed. The search may slow down and zigzag across the bottom of the “ravine.” Sometimes a solution cannot be obtained within an acceptable time frame.
Another disadvantage of the method may be the stopping criterion ||▽f(X k)||<ε k , так как этому условию удовлетворяет и седловая точка, а не только оптимум.
Example. Starting from the point x k =(-2, 3), determine the point x k +1 using the steepest descent method to minimize the function.
As the search direction, select the gradient vector at the current point 
Let's check the stopping criterion. We have ![]()
Let's calculate the value of the function at the initial point f(X 1) = 35. Let's do
step along the antigradient direction
Let's calculate the value of the function at a new point
f(X 2) = 3(-2 + 19λ 1) 2 + (3-8λ 1) 2 - (-2 + 19λ 1)(3-8λ 1) - 4(-2 + 19λ 1)
Let us find a step such that the objective function reaches a minimum along this direction. From the necessary condition for the existence of an extremum of the function
f’(X 2) = 6(-2 + 19λ 1) 19 + 2(3-8λ 1)(-8) – (73 - 304 λ 1) – 4*19
or f’(X 2) = 2598 λ 1 – 425 = 0.
We get the step λ 1 = 0.164
Completing this step will lead to the point ![]()
in which the gradient value ![]() , function value f(X 2) = 0.23. Accuracy is not achieved, from the point we take a step along the direction of the antigradient.
, function value f(X 2) = 0.23. Accuracy is not achieved, from the point we take a step along the direction of the antigradient.
f(X 2) = 3(1.116 – 1.008λ 1) 2 + (1.688-2.26λ 1) 2 - (1.116 – 1.008λ 1)(1.688-2.26λ 1) - 4(1.116 – 1.008λ 1)
f’(X 2) = 11.76 – 6.12λ 1 = 0
We get λ 1 = 0.52 ![]()
Annotation: This lecture widely covers such multiparameter optimization methods as the steepest descent method and the Davidon–Fletcher–Powell method. In addition, a comparative analysis of the above methods is carried out in order to determine the most effective one, their advantages and disadvantages are identified; and also considers multidimensional optimization problems, such as the ravine method and the multiextremal method.
1. Method of steepest descent
The essence of this method is that using the previously mentioned coordinate descent method a search is carried out from a given point in a direction parallel to one of the axes to the minimum point in this direction. The search is then performed in a direction parallel to the other axis, and so on. The directions are, of course, fixed. It seems reasonable to try to modify this method so that at each stage the search for the minimum point is carried out along the "best" direction. It is not clear which direction is "best", but it is known that gradient direction is the direction of the fastest increase in the function. Therefore, the opposite direction is the direction of the fastest decrease of the function. This property can be justified as follows.
Let us assume that we are moving from point x to the next point x + hd, where d is a certain direction and h is a step of a certain length. Consequently, the movement is made from point (x 1, x 2, ..., x n) to point (x 1 + zx 1, x 2 + zx 2, ..., x n + zx n), Where
The change in function values is determined by the relations
| (1.3) |
Up to first order zx i , with partial derivatives being calculated at point x . How should the directions d i be chosen that satisfy equation (1.2) in order to obtain the greatest value of the change in the function df? This is where a maximization problem with a constraint arises. Let us apply the method of Lagrange multipliers, with the help of which we determine the function
The value df satisfying constraint (1.2) reaches its maximum when the function
Reaches the maximum. Its derivative
Hence,
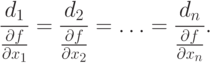 |
(1.6) |
Then di ~ df/dx i and the direction d is parallel to the direction V/(x) at point x.
Thus, largest local increase function for a given small step h occurs when d is the direction of Vf(x) or g(x) . Therefore, the direction of steepest descent is the direction
In a simpler form, equation (1.3) can be written as follows:
Where is the angle between the vectors Vf(x) and dx. For a given value of dx, we minimize df by choosing that the direction of dx coincides with the direction of -Vf(x) .
Comment. Gradient direction perpendicular to any point on a line of constant level, since along this line the function is constant. Thus, if (d 1, d 2, ..., d n) is a small step along the level line, then
And therefore
 |
(1.8) |







