Rules for entering a function
IN steepest descent method a vector whose direction is opposite to the direction of the gradient vector of the function ▽f(x) is selected as the search direction. From mathematical analysis it is known that the vector grad f(x)=▽f(x) characterizes the direction of the fastest increase in the function (see gradient of the function). Therefore, the vector - grad f (X) = -▽f(X) is called anti-gradient and is the direction of its fastest decrease. The recurrence relation with which the steepest descent method is implemented has the form X k +1 =X k - λ k ▽f(x k), k = 0,1,...,
where λ k >0 is the step size. Depending on the choice of step size, you can get various options gradient method. If during the optimization process the step size λ is fixed, then the method is called the gradient method with a discrete step. The optimization process in the first iterations can be significantly accelerated if λ k is selected from the condition λ k =min f(X k + λS k) .
To determine λ k, any one-dimensional optimization method is used. In this case, the method is called the steepest descent method. As a rule, in general case One step is not enough to achieve the minimum of the function; the process is repeated until subsequent calculations allow the result to be improved.
If the space is very elongated in some variables, then a “ravine” is formed. The search may slow down and zigzag across the bottom of the “ravine.” Sometimes a solution cannot be obtained within an acceptable time frame.
Another disadvantage of the method may be the stopping criterion ||▽f(X k)||<ε k , так как этому условию удовлетворяет и седловая точка, а не только оптимум.
Example. Starting from the point x k =(-2, 3), determine the point x k +1 using the steepest descent method to minimize the function.
As the search direction, select the gradient vector at the current point 
Let's check the stopping criterion. We have ![]()
Let's calculate the value of the function at the initial point f(X 1) = 35. Let's do
step along the antigradient direction
Let's calculate the value of the function at a new point
f(X 2) = 3(-2 + 19λ 1) 2 + (3-8λ 1) 2 - (-2 + 19λ 1)(3-8λ 1) - 4(-2 + 19λ 1)
Let us find a step such that the objective function reaches a minimum along this direction. From the necessary condition for the existence of an extremum of the function
f’(X 2) = 6(-2 + 19λ 1) 19 + 2(3-8λ 1)(-8) – (73 - 304 λ 1) – 4*19
or f’(X 2) = 2598 λ 1 – 425 = 0.
We get the step λ 1 = 0.164
Completing this step will lead to the point ![]()
in which the gradient value ![]() , function value f(X 2) = 0.23. Accuracy is not achieved, from the point we take a step along the direction of the antigradient.
, function value f(X 2) = 0.23. Accuracy is not achieved, from the point we take a step along the direction of the antigradient.
f(X 2) = 3(1.116 – 1.008λ 1) 2 + (1.688-2.26λ 1) 2 - (1.116 – 1.008λ 1)(1.688-2.26λ 1) - 4(1.116 – 1.008λ 1)
f’(X 2) = 11.76 – 6.12λ 1 = 0
We get λ 1 = 0.52 ![]()
Statement of the problem
Let the function be given f(x) Rn
Required f(x) X = Rn

Search strategy
x k
} , k = 0.1,...,
such that ![]() , k = 0.1,...
. Sequence points ( x k
) are calculated according to the rule
, k = 0.1,...
. Sequence points ( x k
) are calculated according to the rule
where is the point x 0 user defined; step size tk determined for each value k from the condition
Problem (3) can be solved using the necessary minimum condition followed by checking the sufficient minimum condition. This path can be used either with a sufficiently simple function to be minimized, or with a sufficiently preliminary approximation complex function ![]() polynomial P(t k)
(usually of the second or third degree), and then the condition is replaced by the condition, and the condition by the condition
polynomial P(t k)
(usually of the second or third degree), and then the condition is replaced by the condition, and the condition by the condition 
Sequencing (xk)
ends at point x k
, for which , where ε
- a given small positive number, or k ≥ M
, Where M
- the limiting number of iterations, or with two simultaneous execution of two inequalities ![]() ,
, ![]() Where ε 2
- small positive number. The question is whether a point can x k
be considered as the found approximation of the desired local minimum point x*
, is resolved through additional research.
Where ε 2
- small positive number. The question is whether a point can x k
be considered as the found approximation of the desired local minimum point x*
, is resolved through additional research.
Geometric interpretation of the method for n=2 in Fig. 4.

Coordinate descent method
Statement of the problem
Let the function be given f(x) , bounded below on the set Rn and having continuous partial derivatives at all its points.
f(x) on the set of feasible solutions X = Rn , i.e. find a point such that

Search strategy
The strategy for solving the problem is to construct a sequence of points ( x k
} , k = 0.1,...,
such that ![]() , k = 0.1,...
. Sequence points ( x k
) are calculated over cycles in accordance with the rule
, k = 0.1,...
. Sequence points ( x k
) are calculated over cycles in accordance with the rule
 (4)
(4)
Where j - calculation cycle number; j = 0,1,2,...; k - iteration number inside the loop, k = 0,1,... ,n - 1; e k +1 , k = 0,l,...,n - 1 -unit vector, (k+1) -th projection of which is equal to 1; dot x 00 user defined, step size tk is selected from the condition
 or
or  .
.
If the selected condition at the current tk
is not fulfilled, the step is halved and period  is calculated again. It is easy to see that for a fixed j, in one iteration with number k
only one projection of the point changes x jk
, having a number k+1
, and during the entire cycle with number j
, i.e. starting from k = 0
and ending k = n -1
, all n projections of the point change x j0
. After this point x j n
number is assigned x j + 1.0
, and it is taken as the starting point for calculations in j+1
cycle. The calculation ends at the point x jk
when at least one of three end-of-count criteria is met:
is calculated again. It is easy to see that for a fixed j, in one iteration with number k
only one projection of the point changes x jk
, having a number k+1
, and during the entire cycle with number j
, i.e. starting from k = 0
and ending k = n -1
, all n projections of the point change x j0
. After this point x j n
number is assigned x j + 1.0
, and it is taken as the starting point for calculations in j+1
cycle. The calculation ends at the point x jk
when at least one of three end-of-count criteria is met: ![]() , or , or double execution of inequalities.
, or , or double execution of inequalities.
The points obtained as a result of calculations can be written as elements of a sequence (xl), Where l=n*j+k - serial number of the point,
The geometric interpretation of the method for n = 2 is shown in Fig. 5.

4. Frank-Wolfe method .
Suppose we need to find the maximum value of a concave function

Under conditions

A characteristic feature of this problem is that its system of constraints contains only linear inequalities. This feature is the basis for replacing the nonlinear one in the vicinity of the point under study objective function linear, due to which the solution of the original problem is reduced to the sequential solution of linear programming problems.
The process of finding a solution to the problem begins with identifying a point belonging to the region of feasible solutions to the problem.
270
dachas Let this be the point X(k)
then at this point the gradient of function (57) is calculated
And construct a linear function

Then find the maximum value of this function under restrictions (58) and (59). Let the solution to this problem be determined by the point Z(k)
. Then the coordinates of the point are taken as a new feasible solution to the original problem X(k+1)
:
Where λk - a certain number called the calculation step and enclosed between zero and one (0<λ k < 1). Это число λk taken arbitrarily or determined
so that the value of the function at the point X (k +1) f(X (k +1)) , depending on λk , was the maximum. To do this, you need to find a solution to the equation and choose its smallest root. If its value is greater than one, then we should put λk=1 . After determining the number λk find the coordinates of a point X(k+1) calculate the value of the objective function in it and determine the need to move to a new point X(k+2) . If there is such a need, then calculate at the point X(k+1) gradient of the objective function, go to the corresponding linear programming problem and find its solution. Determine the coordinates of the point and X(k+2) and investigate the need for further calculations. After a finite number of steps, a solution to the original problem is obtained with the required accuracy.
So, the process of finding a solution to problem (57) - (59) using the Frank-Wolfe method includes the following stages:
1. Determine the initial feasible solution to the problem.
2. Find the gradient of function (57) at the point of an admissible solution.
3. Construct function (60) and find its maximum value under conditions (58) and (59).
4. Determine the calculation step.
5. Using formulas (61), the components of a new feasible solution are found.
6. Check the need to move on to the next feasible solution. If necessary, proceed to stage 2, otherwise an acceptable solution to the original problem is found.
Method of penalty functions.
Consider the problem of determining the maximum value of the concave function
f (x 1, x 2, .... x n) under conditions g i (x 1, x 2, .... x n) ≤ b i (i=l, m) , x j ≥ 0 (j=1, n) , Where g i (x 1, x 2, .... x n) - convex functions.
Instead of solving this problem directly, find the maximum value of the function F(x 1, x 2, ...., x n)= f(x 1, x 2, ...., x n) +H(x 1, x 2, ...., x n) which is the sum of the objective function of the problem, and some function
H(x 1, x 2, ...., x n), defined by a system of restrictions and called penalty function. The penalty function can be constructed in various ways. However, most often it looks like
A a i > 0
- some constant numbers representing weighting coefficients.
Using the penalty function, they sequentially move from one point to another until they obtain an acceptable solution. In this case, the coordinates of the next point are found using the formula
From the last relation it follows that if the previous point is in the region of feasible solutions to the original problem, then the second term in square brackets is equal to zero and the transition to the next point is determined only by the gradient of the objective function. If the specified point does not belong to the region of admissible solutions, then due to this term in subsequent iterations a return to the region of admissible solutions is achieved
decisions. At the same time, the less a i
, the faster an acceptable solution is found, but the accuracy of its determination decreases. Therefore, the iterative process usually starts at relatively small values a i
and, continuing it, these values gradually increase.
So, the process of finding a solution to a convex programming problem using the penalty function method includes the following steps:
1. Determine the initial feasible solution.
2. Select the calculation step.
3. Find, for all variables, the partial derivatives of the objective function and functions that determine the range of feasible solutions to the problem.
4. Using formula (72), the coordinates of the point that determines a possible new solution to the problem are found.
5. Check whether the coordinates of the found point satisfy the system of problem constraints. If not, then move on to the next stage. If the coordinates of the found point determine an admissible solution to the problem, then the need to move to the next admissible solution is investigated. If necessary, proceed to stage 2, otherwise an acceptable solution to the original problem has been found.
6. Set the values of the weighting coefficients and proceed to step 4.
Arrow-Hurwitz method.
When finding solutions to nonlinear programming problems using the penalty function method, we chose the values a i , arbitrarily, which led to significant fluctuations in the distance of the determined points from the region of feasible solutions. This drawback is eliminated when solving the problem by the Arrow-Hurwitz method, according to which at the next step the numbers a i (k) calculated by the formula
As initial values a i (0) take arbitrary non-negative numbers.
EXAMPLE SOLUTION
Example 1.
Find the local minimum of a function
Defining a point x k
1. Let's set .
2. Let's put k = 0 .
3 0 . Let's calculate
4 0 . Let's calculate ![]() . Let's move on to step 5.
. Let's move on to step 5.
5 0 . Let's check the condition ![]() . Let's move on to step 6.
. Let's move on to step 6.
6 0 . Let's set t0 = 0.5 .
7 0 . Let's calculate
8 0 . Let's compare ![]() . We have
. We have ![]() . Conclusion: condition for k = 0
is not executed. Let's set t0 = 0.25
, proceed to repeating steps 7, 8.
. Conclusion: condition for k = 0
is not executed. Let's set t0 = 0.25
, proceed to repeating steps 7, 8.
7 01. Let's calculate.
8 01. Let's compare f (x 1) and f (x 0) . Conclusion: f (x 1)< f (x 0) . Let's move on to step 9.
9 0 . Let's calculate
Conclusion: we believe k =1 and go to step 3.
3 1. Let's calculate
4 1. Let's calculate ![]() . Let's move on to step 5.
. Let's move on to step 5.
5 1. Let's check the condition k ≥ M: k = 1< 10 = M . Let's move on to step 6.
6 1. Let's set t 1 = 0.25.
7 1. Let's calculate
![]()
8 1. Let's compare f (x 2) with f (x 1) . Conclusion: f (x 2)< f (х 1). Let's move on to step 9.
9 1. Let's calculate
Conclusion: we believe k = 2 and go to step 3.
3 2. Let's calculate
4 2. Let's calculate. Let's move on to step 5.
5 2. Let's check the condition k ≥ M : k = 2< 10 = М , go to step 6.
6 2. Let's set t 2 =0,25 .
7 2. Let's calculate
![]()
8 2. Let's compare f (x 3) And f (x 2) . Conclusion: f (x 3)< f (х 2) .Go to step 9.
9 2. Let's calculate ![]()
Conclusion: we believe k = 3 and go to step 3.
3 3 . Let's calculate
4 3 . Let's calculate. Let's move on to step 5.
5 3. Let's check the condition k ≥ M : k = 3<10 = М , go to step 6.
6 3. Let's set t 3 = 0.25.
7 3. Let's calculate
![]()
8 3. Let's compare f (x 4) And f (x 3) : f (x 4)< f (х 3) .
9 3. Let's calculate ![]()
Conditions are met when k = 2.3 . Calculation
finished. Point found
In Fig. The 3 resulting points are connected by a dotted line.

II. Point Analysis x 4 .
Function ![]() is twice differentiable, so we will check the sufficient conditions for the minimum at the point x 4
. To do this, let's analyze the Hessian matrix.
is twice differentiable, so we will check the sufficient conditions for the minimum at the point x 4
. To do this, let's analyze the Hessian matrix.
The matrix is constant and positive definite (i.e. . H > 0
) since both of its angular minors are positive. Therefore, the point ![]() is the found approximation of the local minimum point, and the value
is the found approximation of the local minimum point, and the value ![]() is the found approximation of the value f (x *) =0
. Note that the condition H > 0
, there is at the same time a condition for strict convexity of the function
is the found approximation of the value f (x *) =0
. Note that the condition H > 0
, there is at the same time a condition for strict convexity of the function ![]() . Consequently, there are found approximations of the global minimum point f(x)
and its minimum value at R 2
. ■
. Consequently, there are found approximations of the global minimum point f(x)
and its minimum value at R 2
. ■
Example 2
Find the local minimum of a function
I. Definition of a point x k, in which at least one of the criteria for completing calculations is met.
1. Let's set .
Let's find the gradient of the function at an arbitrary point
2. Let's put k = 0 .
3 0 . Let's calculate
4 0 . Let's calculate ![]() . Let's move on to step 5.
. Let's move on to step 5.
5 0 . Let's check the condition ![]() . Let's move on to step 6.
. Let's move on to step 6.
6° The next point is found by the formula
Let us substitute the resulting expressions for coordinates into
Let's find the minimum of the function f(t 0) By t 0 using the necessary conditions for an unconditional extremum:
![]()
From here t 0 =0.24
. Because  , the found step value provides the minimum of the function f(t 0)
By t 0
.
, the found step value provides the minimum of the function f(t 0)
By t 0
.

Let's define ![]()
7 0 . We'll find
8°. Let's calculate
![]()
![]()
Conclusion: we believe k = 1 and go to step 3.
3 1. Let's calculate
4 1. Let's calculate ![]()
5 1. Let's check the condition k ≥ 1: k = 1< 10 = М.
6 1. Let's define
7 1. We'll find ![]() :
:
8 1. Let's calculate
We believe k = 2 and go to step 3.
3 2. Let's calculate
4 2. Let's calculate
5 2. Let's check the condition k ≥ M: k = 2< 10 = M .
6 2. Let's define
7 2. We'll find ![]()
8 2. Let's calculate
We believe k =3 and go to step 3.
3 3 . Let's calculate
4 3 . Let's calculate.
The calculation is completed. Point found
II. Point Analysis x 3 .
In example 1.1 (Chapter 2 §1) it was shown that the function f(x) is strictly convex and, therefore, at points3 is the found approximation of the global minimum point X* .
Example 3.
Find the local minimum of a function
![]()
I. Definition of a point xjk , in which at least one of the criteria for completing calculations is met.
1. Let's set
Let's find the gradient of the function at an arbitrary point ![]()
2. Let's set j = 0.
3 0 . Let's check if the condition is met
4 0 . Let's set k = 0.
5 0 . Let's check if the condition is met
6 0 . Let's calculate
7 0 . Let's check the condition ![]()
8 0 . Let's set
9 0 . Let's calculate ![]() , Where
, Where
10 0 . Let's check the condition
Conclusion: we assume and move on to step 9.
9 01. Let's calculate x 01 in increments
10 01. Let's check the condition ![]()
11 0 . Let's check the conditions
We believe k =1 and go to step 5.
5 1. Let's check the condition
6 1. Let's calculate
7 1. Let's check the condition
8 1. Let's set
9 1. Let's calculate
10 1. Let's check the condition ![]() :
:
11 1. Let's check the conditions
We believe k = 2 , go to step 5.
5 2. Let's check the condition. Let's set , go to step 3.
3 1. Let's check the condition
4 1. Let's set k = 0.
5 2. Let's check the condition
6 2. Let's calculate
7 2. Let's check the condition
8 2. Let's set
9 2. Let's calculate
10 2. Let's check the condition ![]()
11 2. Let's check the conditions
We believe k =1 and go to step 5.
5 3. Let's check the condition
6 3. Let's calculate
7 3. Let's check the conditions
8 3. Let's set
9 3. Let's calculate
10 3. Let's check the condition ![]()
11 3. Let's check the conditions
Let's set k = 2 and go to step 5.
5 4 . Let's check the condition ![]()
We believe j = 2, x 20 = x 12 and go to step 3.
3 2. Let's check the condition
4 2. Let's set k =0 .
5 4 . Let's check the condition
6 4. Let's calculate
7 4. Let's check the condition
8 4 . Let's set
9 4. Let's calculate
10 4. Let's check the condition and move on to step 11.
11 4. Let's check the conditions
The conditions are met in two consecutive cycles with numbers j = 2 And j -1= 1 . The calculation is completed, the point has been found
In Fig. The 6 resulting points are connected by a dotted line.
In the coordinate descent method, we descend along a broken line consisting of straight segments parallel to the coordinate axes.
II. Analysis of point x21.
In Example 1.1 it was shown that the function f(x)
is strictly convex, has a unique minimum and, therefore, a point ![]() is the found approximation of the global minimum point.
is the found approximation of the global minimum point.

In all the gradient methods discussed above, the sequence of points (xk) converges to the stationary point of the function f(x) with fairly general propositions regarding the properties of this function. In particular, the theorem is true:
Theorem. If the function f(x) is bounded below, its gradient satisfies the Lipschitz condition () and the choice of value tn produced by one of the methods described above, then whatever the starting point x 0 :
![]() at .
at .
In practical implementation of the scheme
![]() k =1, 2, … n.
k =1, 2, … n.
iterations stop if for all i, i = 1, 2, ..., n , conditions like
 ,
,
where is a certain number characterizing the accuracy of finding the minimum.
Under the conditions of the theorem, the gradient method ensures convergence in the function or to the exact lower bound (if the function f(x) has no minimum; rice. 7), or to the value of the function at some stationary point, which is the limit of the sequence (x k). It is not difficult to come up with examples when a saddle is realized at this point, and not a minimum. In practice, gradient descent methods confidently bypass saddle points and find minima of the objective function (in the general case, local ones).

CONCLUSION
Examples of gradient unconstrained optimization methods were discussed above. As a result of the work done, the following conclusions can be drawn:
1. More or less complex problems of finding an extremum in the presence of restrictions require special approaches and methods.
2. Many algorithms for solving problems with constraints include unconstrained minimization as some step.
3. Various methods descents differ from each other in the way they choose the direction of descent and the length of the step along this direction.
4. There is no theory yet that would take into account any features of the functions that describe the formulation of the problem. Preference should be given to methods that are easier to manage in the process of solving a problem.
Real applied optimization problems are very complex. Modern methods optimizations do not always cope with solving real problems without human help.
REFERENCES
1. Kosorukov O.A. Operations Research: A Textbook. 2003
2. Pantleev A.V. Optimization methods in examples and problems: textbook. Benefit. 2005
3. Shishkin E.V. Operations research: textbook. 2006
4. Akulich I.L. Mathematical programming in examples and problems. 1986
5. Ventzel E.S. Operations Research. 1980
6. Ventzel E.S., Ovcharov L.A. Probability theory and its engineering applications. 1988
©2015-2019 site
All rights belong to their authors. This site does not claim authorship, but provides free use.
Page creation date: 2017-07-02
Annotation: This lecture widely covers such multiparameter optimization methods as the steepest descent method and the Davidon–Fletcher–Powell method. In addition, a comparative analysis of the above methods is carried out in order to determine the most effective one, their advantages and disadvantages are identified; and also considers multidimensional optimization problems, such as the ravine method and the multiextremal method.
1. Method of steepest descent
The essence this method is that using the previously mentioned coordinate descent method search is carried out from given point in a direction parallel to one of the axes, to a minimum point in that direction. The search is then performed in a direction parallel to the other axis, and so on. The directions are, of course, fixed. It seems reasonable to try to modify this method so that at each stage the search for the minimum point is carried out along the "best" direction. It is not clear which direction is "best", but it is known that gradient direction is the direction of the fastest increase in the function. Therefore, the opposite direction is the direction of the fastest decrease of the function. This property can be justified as follows.
Let us assume that we are moving from point x to the next point x + hd, where d is a certain direction and h is a step of a certain length. Consequently, the movement is made from point (x 1, x 2, ..., x n) to point (x 1 + zx 1, x 2 + zx 2, ..., x n + zx n), Where
The change in function values is determined by the relations
| (1.3) |
Up to first order zx i , with partial derivatives being calculated at point x . How should the directions d i be chosen that satisfy equation (1.2) in order to obtain the greatest value of the change in the function df? This is where a maximization problem with a constraint arises. Let us apply the method of Lagrange multipliers, with the help of which we determine the function
The value df satisfying constraint (1.2) reaches a maximum when the function
Reaches the maximum. Its derivative
Hence,
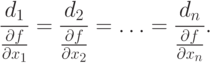 |
(1.6) |
Then di ~ df/dx i and the direction d is parallel to the direction V/(x) at point x.
Thus, largest local increase function for a given small step h occurs when d is the direction of Vf(x) or g(x) . Therefore, the direction of steepest descent is the direction
In more in simple form equation (1.3) can be written as follows:
Where is the angle between the vectors Vf(x) and dx. For given value dx we minimize df by choosing that the direction of dx coincides with the direction of -Vf(x) .
Comment. Gradient direction perpendicular to any point on a line of constant level, since along this line the function is constant. Thus, if (d 1, d 2, ..., d n) is a small step along the level line, then
And therefore
 |
(1.8) |
You can also search not for the best point in the direction of the gradient, but for some one better than the current one.
The easiest to implement of all local optimization methods. Has quite weak conditions convergence, but the rate of convergence is quite low (linear). The gradient method step is often used as part of other optimization methods, such as the Fletcher–Reeves method.
Description [ | ]
Improvements[ | ]
The gradient descent method turns out to be very slow when moving along a ravine, and as the number of variables in the objective function increases, this behavior of the method becomes typical. To combat this phenomenon it is used, the essence of which is very simple. Having made two steps of gradient descent and obtained three points, the third step should be taken in the direction of the vector connecting the first and third points, along the bottom of the ravine.
For functions close to quadratic, the conjugate gradient method is effective.
Application in artificial neural networks[ | ]
The gradient descent method, with some modification, is widely used for perceptron training and is known in the theory of artificial neural networks as the backpropagation method. When training a perceptron-type neural network, it is necessary to change the weighting coefficients of the network so as to minimize average error at the output of the neural network when a sequence of training input data is supplied to the input. Formally, in order to take just one step using the gradient descent method (make just one change in the network parameters), it is necessary to sequentially submit absolutely the entire set of training data to the network input, calculate the error for each object of the training data and calculate the necessary correction of the network coefficients (but not do this correction), and after submitting all the data, calculate the amount in the adjustment of each network coefficient (sum of gradients) and correct the coefficients “one step”. Obviously, with a large set of training data, the algorithm will work extremely slowly, so in practice, network coefficients are often adjusted after each training element, where the gradient value is approximated by the gradient of the cost function, calculated on only one training element. This method is called stochastic gradient descent or operational gradient descent . Stochastic gradient descent is one of the forms of stochastic approximation. The theory of stochastic approximations provides conditions for the convergence of the stochastic gradient descent method.
Links [ | ]
- J. Mathews. Module for Steepest Descent or Gradient Method. (unavailable link)
Literature [ | ]
- Akulich I. L. Mathematical programming in examples and problems. - M.: Higher School, 1986. - P. 298-310.
- Gill F., Murray W., Wright M. Practical optimization = Practical Optimization. - M.: Mir, 1985.
- Korshunov Yu. M., Korshunov Yu. M. Mathematical foundations of cybernetics. - M.: Energoatomizdat, 1972.
- Maksimov Yu. A., Fillipovskaya E. A. Algorithms for solving nonlinear programming problems. - M.: MEPhI, 1982.
- Maksimov Yu. A. Algorithms for linear and discrete programming. - M.: MEPhI, 1980.
- Korn G., Korn T. Handbook of mathematics for scientists and engineers. - M.: Nauka, 1970. - P. 575-576.
- S. Yu. Gorodetsky, V. A. Grishagin. Nonlinear programming and multiextremal optimization. - Nizhny Novgorod: Nizhny Novgorod University Publishing House, 2007. - pp. 357-363.
When using the steepest descent method at each iteration, the step size A k is selected from the minimum condition of the function f(x) in the direction of descent, i.e.
f(x[k] -a k f"(x[k])) = f(x[k] -af"(x[k])) .
This condition means that movement along the antigradient occurs as long as the value of the function f(x) decreases. From a mathematical point of view, at each iteration it is necessary to solve the problem of one-dimensional minimization according to A functions
j (a) = f(x[k]-af"(x[k])) .
The algorithm of the steepest descent method is as follows.
- 1. Set the coordinates of the starting point X.
- 2. At the point X[k], k = 0, 1, 2, ... calculates the gradient value f"(x[k]) .
- 3. The step size is determined a k , by one-dimensional minimization over A functions j (a) = f(x[k]-af"(x[k])).
- 4. The coordinates of the point are determined X[k+ 1]:
X i [k+ 1]= x i [k] -A k f" i (X[k]), i = 1,..., p.
5. The conditions for stopping the steration process are checked. If they are fulfilled, then the calculations stop. Otherwise, go to step 1.
In the method under consideration, the direction of movement from the point X[k] touches the level line at the point x[k+ 1] (Fig. 2.9). The descent trajectory is zigzag, with adjacent zigzag links orthogonal to each other. Indeed, a step a k is chosen by minimizing by A functions? (a) = f(x[k] -af"(x[k])) . Prerequisite minimum function d j (a)/da = 0. Having calculated the derivative of a complex function, we obtain the condition for the orthogonality of the vectors of descent directions at neighboring points:
d j (a)/da = -f"(x[k+ 1]f"(x[k]) = 0.

Rice. 2.9.
Gradient methods converge to a minimum with high speed(at speed geometric progression) for smooth convex functions. Such functions have the greatest M and least m eigenvalues of the matrix of second derivatives (Hessian matrix)

differ little from each other, i.e. matrix N(x) well conditioned. Let us remind you that eigenvalues l i, i =1, …, n, the matrices are the roots of the characteristic equation

However, in practice, as a rule, the functions being minimized have ill-conditioned matrices of second derivatives (t/m<< 1). The values of such functions along some directions change much faster (sometimes by several orders of magnitude) than in other directions. Their level surfaces in the simplest case are strongly elongated (Fig. 2.10), and in more complex cases they bend and look like ravines. Functions with such properties are called gully. The direction of the antigradient of these functions (see Fig. 2.10) deviates significantly from the direction to the minimum point, which leads to a slowdown in the speed of convergence.

Rice. 2.10.
The convergence rate of gradient methods also depends significantly on the accuracy of gradient calculations. Loss of accuracy, which usually occurs in the vicinity of minimum points or in a gully situation, can generally disrupt the convergence of the gradient descent process. Due to the above reasons, gradient methods are often used in combination with other, more effective methods at the initial stage of solving a problem. In this case, the point X is far from the minimum point, and steps in the direction of the antigradient make it possible to achieve a significant decrease in the function.







