Maaari ka ring maghanap hindi para sa pinakamahusay na punto sa direksyon ng gradient, ngunit para sa ilang mas mahusay kaysa sa kasalukuyang isa.
Ang pinakamadaling ipatupad sa lahat ng lokal na paraan ng pag-optimize. May medyo mahinang kondisyon convergence, ngunit ang rate ng convergence ay medyo mababa (linear). Ang hakbang ng gradient na paraan ay kadalasang ginagamit bilang bahagi ng iba pang mga paraan ng pag-optimize, gaya ng paraan ng Fletcher–Reeves.
Paglalarawan [ | ]
Mga pagpapabuti[ | ]
Ang gradient descent method ay lumalabas na napakabagal kapag gumagalaw sa isang bangin, at may pagtaas sa bilang ng mga variable. layunin function nagiging tipikal ang pag-uugaling ito ng pamamaraan. Upang labanan ang hindi pangkaraniwang bagay na ito, ginagamit ito, ang kakanyahan nito ay napaka-simple. Ang pagkakaroon ng dalawang hakbang ng gradient descent at nakakuha ng tatlong puntos, ang ikatlong hakbang ay dapat gawin sa direksyon ng vector na nagkokonekta sa una at ikatlong mga punto, kasama ang ilalim ng bangin.
Para sa mga function na malapit sa quadratic, ang conjugate gradient method ay epektibo.
Application sa mga artipisyal na neural network[ | ]
Ang gradient descent method, na may ilang pagbabago, ay malawakang ginagamit para sa perceptron na pagsasanay at kilala sa teorya ng mga artipisyal na neural network bilang paraan ng backpropagation. Kapag nagsasanay ng perceptron-type neural network, kailangang baguhin ang weighting coefficients ng network upang mabawasan average na error sa output ng neural network kapag ang isang sequence ng training input data ay ibinibigay sa input. Sa pormal na paraan, upang makagawa lamang ng isang hakbang gamit ang gradient descent method (gumawa lamang ng isang pagbabago sa mga parameter ng network), kinakailangang sunud-sunod na isumite ang buong hanay ng data ng pagsasanay sa input ng network, kalkulahin ang error para sa bawat object ng ang data ng pagsasanay at kalkulahin ang kinakailangang pagwawasto ng mga koepisyent ng network (ngunit huwag gawin ang pagwawasto na ito), at pagkatapos isumite ang lahat ng data, kalkulahin ang halaga sa pagsasaayos ng bawat koepisyent ng network (kabuuan ng mga gradient) at itama ang mga koepisyent "isang hakbang" . Malinaw, na may malaking hanay ng data ng pagsasanay, ang algorithm ay gagana nang napakabagal, kaya sa pagsasagawa, ang mga coefficient ng network ay madalas na nababagay pagkatapos ng bawat elemento ng pagsasanay, kung saan ang halaga ng gradient ay tinatantya ng gradient ng function ng gastos, na kinakalkula sa isang pagsasanay lamang. elemento. Ang pamamaraang ito ay tinatawag na stochastic gradient descent o operational gradient descent . Ang stochastic gradient descent ay isang anyo ng stochastic approximation. Ang teorya ng stochastic approximations ay nagbibigay ng mga kondisyon para sa convergence ng stochastic gradient descent method.
Mga link [ | ]
- J. Mathews. Module para sa Steepest Descent o Gradient Method. (hindi available na link)
Panitikan [ | ]
- Akulich I. L. Ang programming sa matematika sa mga halimbawa at problema. - M.: Higher School, 1986. - P. 298-310.
- Gill F., Murray W., Wright M. Praktikal na pag-optimize = Praktikal na Pag-optimize. - M.: Mir, 1985.
- Korshunov Yu M., Korshunov Yu. Mga pundasyon ng matematika ng cybernetics. - M.: Energoatomizdat, 1972.
- Maksimov Yu A., Fillipovskaya E. A. Algorithm para sa paglutas ng mga problema sa nonlinear programming. - M.: MEPhI, 1982.
- Maximov Yu. Algorithm para sa linear at discrete programming. - M.: MEPhI, 1980.
- Korn G., Korn T. Handbook ng matematika para sa mga siyentipiko at inhinyero. - M.: Nauka, 1970. - P. 575-576.
- S. Yu. Gorodetsky, V. A. Grishagin. Nonlinear programming at multiextremal optimization. - Nizhny Novgorod: Nizhny Novgorod University Publishing House, 2007. - pp. 357-363.
Ang pinakamatarik na paraan ng pagbaba ay isang gradient na paraan na may variable na hakbang. Sa bawat pag-ulit, ang laki ng hakbang k ay pinili mula sa kondisyon ng minimum ng function na f(x) sa direksyon ng pagbaba, i.e.
Ang kundisyong ito ay nangangahulugan na ang paggalaw sa kahabaan ng antigradient ay nangyayari hangga't ang halaga ng function na f (x) ay bumababa. Mula sa isang matematikal na punto ng view, sa bawat pag-ulit ito ay kinakailangan upang malutas ang problema ng one-dimensional minimization sa pamamagitan ng function.
()=f (x (k) -f (x (k)))
Gamitin natin ang golden ratio method para dito.
Ang algorithm ng pinakamatarik na paraan ng pagbaba ay ang mga sumusunod.
Ang mga coordinate ng panimulang punto x (0) ay tinukoy.
Sa puntong x (k) , k = 0, 1, 2, ..., ang gradient value na f (x (k)) ay kinakalkula.
Ang laki ng hakbang k ay tinutukoy ng one-dimensional minimization gamit ang function
()=f (x (k) -f (x (k))).
Ang mga coordinate ng point x (k) ay tinutukoy:
x i (k+1) = x i (k) - k f i (x (k)), i=1, …, n.
Ang kondisyon para sa paghinto ng umuulit na proseso ay nasuri:
||f (x (k +1))|| .
Kung ito ay natupad, pagkatapos ay ang mga kalkulasyon ay hihinto. Kung hindi, magpapatuloy kami sa hakbang 1. Ang geometric na interpretasyon ng pinakamatarik na paraan ng pagbaba ay ipinakita sa Fig. 1.

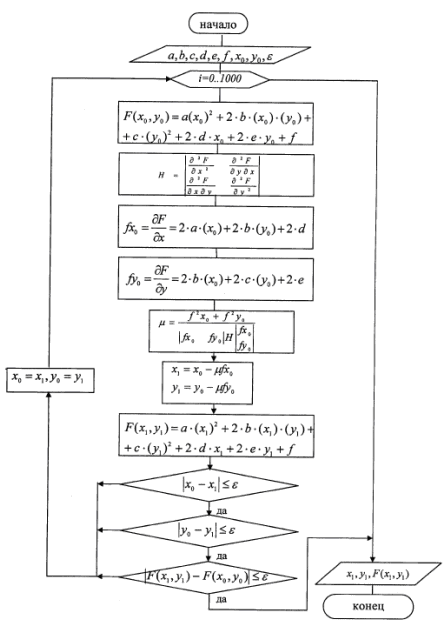
kanin. 2.1. Block diagram ng pinakamatarik na paraan ng pagbaba.
Pagpapatupad ng pamamaraan sa programa:
Paraan ng pinakamatarik na pagbaba.

kanin. 2.2. Pagpapatupad ng pinakamatarik na paraan ng pagbaba.
Konklusyon: Sa aming kaso, ang pamamaraan ay nagtagpo sa 7 pag-ulit. Ang Point A7 (0.6641; -1.3313) ay isang extremum point. Paraan ng conjugate na mga direksyon. Para sa mga quadratic function, maaari kang lumikha ng gradient method kung saan ang convergence time ay magiging may hangganan at katumbas ng bilang ng mga variable n.
Tawagan natin ang isang tiyak na direksyon at conjugate tungkol sa ilang positibong tiyak na Hess matrix H kung:
Pagkatapos i.e. Kaya para sa yunit H, ang direksyon ng conjugate ay nangangahulugang ang kanilang patayo. Sa pangkalahatang kaso, ang H ay hindi mahalaga. SA pangkalahatang kaso Ang conjugacy ay ang paglalapat ng Hess matrix sa isang vector - nangangahulugan ito ng pag-ikot ng vector na ito sa ilang anggulo, pag-uunat o pag-compress nito.

At ngayon ang vector ay orthogonal, ibig sabihin, ang conjugacy ay hindi ang orthogonality ng vector, ngunit ang orthogonality ng rotated vector.e.i.


kanin. 2.3. Block diagram ng conjugate directions method.
Pagpapatupad ng pamamaraan sa programa: Paraan ng mga direksyon ng conjugate.

kanin. 2.4. Pagpapatupad ng paraan ng mga direksyon ng conjugate.

kanin. 2.5. Graph ng conjugate directions method.
Konklusyon: Ang Point A3 (0.6666; -1.3333) ay natagpuan sa 3 pag-ulit at ito ay isang extremum point.
3. Pagsusuri ng mga pamamaraan para sa pagtukoy ng minimum at maximum na halaga ng isang function sa pagkakaroon ng mga paghihigpit
Alalahanin natin iyon karaniwang gawain ganito ang conditional optimization
f(x) ® min, x О W,
kung saan ang W ay isang wastong subset ng R m. Ang subclass ng mga problema sa equality-type constraints ay nakikilala sa pamamagitan ng katotohanan na ang set ay tinukoy ng constraints ng form
f i (x) = 0, kung saan f i: R m ®R (i = 1, …, k).
Kaya,W = (x О R m: f i (x) = 0, i = 1, …, k).
Magiging maginhawa para sa amin na isulat ang index na "0" para sa function na f. Kaya, ang problema sa pag-optimize na may mga hadlang sa uri ng pagkakapantay-pantay ay isinulat bilang
f 0 (x) ® min, (3.1)
f i (x) = 0, i = 1, …, k. (3.2)
Kung tinutukoy natin ngayon sa pamamagitan ng f isang function sa R m na may mga halaga sa R k, ang coordinate notation na kung saan ay may form na f(x) = (f 1 (x), ..., f k (x)), pagkatapos ay ( 3.1)–(3.2) maaari din natin itong isulat sa anyo
f 0 (x) ® min, f(x) = Q.
Geometrically, ang problema sa equality type constraints ay problema sa paghahanap ng pinakamababang punto ng graph ng isang function f 0 sa manifold (tingnan ang Fig. 3.1).

Ang mga puntos na nakakatugon sa lahat ng mga hadlang (i.e., mga puntos sa set ) ay karaniwang tinatawag na tinatanggap. Ang tinatanggap na puntong x* ay tinatawag na conditional minimum ng function f 0 sa ilalim ng mga hadlang f i (x) = 0, i = 1, ..., k (o isang solusyon sa problema (3.1)–(3.2)), kung para sa lahat ng tinatanggap na puntos x f 0 (x *) f 0 (x). (3.3)
Kung ang (3.3) ay nasiyahan lamang para sa tinatanggap na x na nakahiga sa ilang kapitbahayan V x * ng punto x*, kung gayon ay nagsasalita tayo ng lokal na minimum na kondisyon. Ang mga konsepto ng conditional strict local at global minima ay tinukoy sa natural na paraan.
Sa bersyong ito ng gradient method, ang minimizing sequence (X k) ay binuo din ayon sa panuntunan (2.22). Gayunpaman, ang laki ng hakbang a k ay natagpuan bilang resulta ng paglutas ng auxiliary one-dimensional minimization na problema
min(j k (a) | a>0 ), (2.27)
kung saan ang j k (a)=f(X k - a· (X k)). Kaya, sa bawat pag-ulit sa direksyon ng antigradient ![]() isinasagawa ang isang kumpletong pagbaba. Upang malutas ang problema (2.27), maaari mong gamitin ang isa sa mga one-dimensional na paraan ng paghahanap na inilarawan sa Seksyon 1, halimbawa, ang bitwise na paraan ng paghahanap o ang ginintuang paraan ng seksyon.
isinasagawa ang isang kumpletong pagbaba. Upang malutas ang problema (2.27), maaari mong gamitin ang isa sa mga one-dimensional na paraan ng paghahanap na inilarawan sa Seksyon 1, halimbawa, ang bitwise na paraan ng paghahanap o ang ginintuang paraan ng seksyon.
Ilarawan natin ang algorithm ng pinakamatarik na paraan ng pagbaba.
Hakbang 0. Itakda ang accuracy parameter e>0, piliin ang X 0 ОE n , itakda k=0.
Hakbang 1. Hanapin ang (X k) at suriin ang kundisyon para sa pagkamit ng tinukoy na katumpakan || (x k) ||£ e. Kung ito ay natupad, pagkatapos ay pumunta sa hakbang 3, kung hindi - sa hakbang 2.
Hakbang 2. Lutasin ang problema (2.27), i.e. maghanap ng k. Hanapin ang susunod na punto, ilagay ang k=k+1 at pumunta sa hakbang 1.
Hakbang 3 Kumpletuhin ang mga kalkulasyon sa pamamagitan ng paglalagay ng X * = X k, f * = f(X k).
I-minimize ang pag-andar
f(x)=x 1 2 +4x 2 2 -6x 1 -8x 2 +13; (2.28)
Solusyonan muna natin ang problema klasiko paraan. Isulat natin ang isang sistema ng mga equation na kumakatawan mga kinakailangang kondisyon walang pasubaling extremum

Nang malutas ito, nakakakuha tayo ng isang nakatigil na punto X*=(3;1). Susunod, suriin natin ang pagpapatupad sapat na kondisyon, kung saan makikita natin ang matrix ng pangalawang derivatives
Dahil, ayon sa Sylvester criterion, ang matrix na ito ay positibong tiyak para sa ", kung gayon ang nahanap na puntong X* ay ang pinakamababang punto ng function na f(X). Ang pinakamababang halaga f *=f(X*)=0. Ito ang eksaktong solusyon sa problema (11).
Magsagawa tayo ng isang pag-ulit ng pamamaraan gradient descent para sa (2.28). Piliin natin ang panimulang punto X 0 =(1;0), itakda ang paunang hakbang a=1 at ang parameter l=0.5. Kalkulahin natin ang f(X 0)=8.
Hanapin natin ang gradient ng function na f(X) sa punto X 0
(X 0)= = (2.29)
Tukuyin natin ang isang bagong punto X=X 0 -a· (X 0) sa pamamagitan ng pagkalkula ng mga coordinate nito
x 1 = 
x 2 =  (2.30)
(2.30)
Kalkulahin natin ang f(X)= f(X 0 -a· (X 0))=200. Dahil f(X)>f(X 0), hinati namin ang hakbang, sa pag-aakalang a=a·l=1·0.5=0.5. Kinakalkula namin muli gamit ang mga formula (2.30) x 1 =1+4a=3; x 2 =8a=4 at hanapin ang halaga f(X)=39. Dahil muli ang f(X)>f(X 0), lalo naming binabawasan ang laki ng hakbang, na nagtatakda ng a=a·l=0.5·0.5=0.25. Kinakalkula namin ang isang bagong punto na may mga coordinate x 1 =1+4·0.25=2; x 2 =8·0.25=2 at ang halaga ng function sa puntong ito f(X)=5. Dahil ang kundisyon para sa pagpapababa ng f(X) Magsagawa tayo ng isang pag-ulit gamit ang pamamaraan pinakamatarik na pagbaba para sa (2.28) na may parehong inisyal na punto X 0 =(1;0). Gamit ang nahanap na gradient (2.29), nakita namin X= X 0 -a· (X 0) at buuin ang function na j 0 (a)=f(X 0 -a· (X 0))=(4a-2) 2 +4(8a-1) 2. Sa pamamagitan ng pagliit nito gamit ang kinakailangang kondisyon j 0 ¢(a)=8·(4a - 2)+64·(8a - 1)=0 nakita namin ang pinakamainam na halaga ng laki ng hakbang a 0 =5/34. Pagtukoy sa punto ng minimizing sequence X 1 = X 0 -a 0 · (X 0) Ang gradient ng differentiable function na f(x) sa punto X tinawag n-dimensional na vector f(x)
, na ang mga bahagi ay mga partial derivatives ng function f(x), kinakalkula sa punto X, ibig sabihin. f"(x ) = (df(x)/dh 1 , …, df(x)/dx n) T . Ang vector na ito ay patayo sa eroplano sa pamamagitan ng punto X, at padaplis sa antas ng ibabaw ng function f(x), dumadaan sa isang punto X.Sa bawat punto ng naturang surface ang function f(x) tumatagal ng parehong halaga. Ang equating ang function sa iba't ibang mga pare-pareho ang halaga C 0 , C 1 , ..., nakakakuha kami ng isang serye ng mga ibabaw na nagpapakilala sa topology nito (Larawan 2.8). Ang gradient vector ay nakadirekta sa direksyon ng pinakamabilis na pagtaas ng function sa isang naibigay na punto. Vector na kabaligtaran ng gradient (-f’(x))
, tinawag anti-gradient at nakadirekta sa pinakamabilis na pagbaba ng function. Sa pinakamababang punto, ang gradient ng function ay zero. Ang mga first-order na pamamaraan, na tinatawag ding gradient at minimization na pamamaraan, ay batay sa mga katangian ng mga gradient. Ang paggamit ng mga pamamaraang ito sa pangkalahatang kaso ay nagbibigay-daan sa iyo upang matukoy ang lokal na minimum na punto ng isang function. Malinaw, kung walang karagdagang impormasyon, pagkatapos ay mula sa panimulang punto X makatwirang pumunta sa punto X, nakahiga sa direksyon ng antigradient - ang pinakamabilis na pagbaba ng function. Pagpili bilang direksyon ng pagbaba R[k] anti-gradient - f'(x[k] )
sa punto X[k], nakakakuha kami ng umuulit na proseso ng form X[ k+ 1] = x[k]-isang k f"(x[k] )
,
at k > 0; k=0, 1, 2, ... Sa coordinate form, ang prosesong ito ay nakasulat bilang mga sumusunod: x i [ k+1]=x i[k] - isang kf(x[k] )
/x i i = 1, ..., n; k= 0, 1, 2,... Bilang isang criterion para sa pagpapahinto sa umuulit na proseso, alinman sa katuparan ng kondisyon ng maliit na pagtaas ng argument || x[k+l] - x[k] || <= e
,
либо выполнение условия малости градиента || f'(x[k+l] )
|| <= g
, Dito binibigyan ng maliit na dami ang e at g. Posible rin ang isang pinagsamang pamantayan, na binubuo sa sabay-sabay na katuparan ng mga tinukoy na kundisyon. Ang mga pamamaraan ng gradient ay naiiba sa bawat isa sa paraan ng pagpili nila ng laki ng hakbang at k. Sa paraang may pare-parehong hakbang, pinipili ang isang tiyak na halaga ng pare-parehong hakbang para sa lahat ng mga pag-ulit. Medyo maliit na hakbang at k titiyakin na ang pag-andar ay bumababa, ibig sabihin, ang hindi pagkakapantay-pantay f(x[ k+1])
= f(x[k] – isang k f’(x[k] ))
< f(x[k] )
. Gayunpaman, maaaring humantong ito sa pangangailangang magsagawa ng hindi katanggap-tanggap na malaking bilang ng mga pag-ulit upang maabot ang pinakamababang punto. Sa kabilang banda, ang isang hakbang na masyadong malaki ay maaaring magdulot ng hindi inaasahang pagtaas sa function o humantong sa mga oscillations sa paligid ng pinakamababang punto (pagbibisikleta). Dahil sa kahirapan sa pagkuha ng kinakailangang impormasyon upang piliin ang laki ng hakbang, ang mga pamamaraan na may pare-parehong mga hakbang ay bihirang ginagamit sa pagsasanay. Ang mga gradient ay mas matipid sa mga tuntunin ng bilang ng mga pag-ulit at pagiging maaasahan mga pamamaraan ng variable na hakbang, kapag, depende sa mga resulta ng mga kalkulasyon, ang laki ng hakbang ay nagbabago sa ilang paraan. Isaalang-alang natin ang mga variant ng naturang mga pamamaraan na ginagamit sa pagsasanay. Kapag ginagamit ang pinakamatarik na paraan ng pagbaba sa bawat pag-ulit, ang laki ng hakbang at k ay pinili mula sa pinakamababang kondisyon ng function f(x) sa direksyon ng pagbaba, i.e. Ang kundisyong ito ay nangangahulugan na ang paggalaw kasama ang antigradient ay nangyayari hangga't ang halaga ng function f(x) bumababa. Mula sa isang punto ng matematika, sa bawat pag-ulit ay kinakailangan upang malutas ang problema ng one-dimensional minimization ayon sa A mga function Ang algorithm ng pinakamatarik na paraan ng pagbaba ay ang mga sumusunod. 1. Itakda ang mga coordinate ng panimulang punto X.
2. Sa punto X[k],
k = 0, 1, 2, ... kinakalkula ang gradient value f'(x[k])
. 3. Natutukoy ang laki ng hakbang a k, sa pamamagitan ng one-dimensional minimization over A mga tungkulin j (a) = f(x[k]-af"(x[k])).
4. Natutukoy ang mga coordinate ng punto X[k+ 1]: x i [ k+ 1]= x i[k]– a k f’ i (x[k]), i = 1,..., p. 5. Sinusuri ang mga kundisyon para sa paghinto ng proseso ng steration. Kung natupad ang mga ito, huminto ang mga kalkulasyon. Kung hindi, pumunta sa hakbang 1. Sa paraang isinasaalang-alang, ang direksyon ng paggalaw mula sa punto X[k] hinawakan ang linya ng antas sa punto x[k+ 1] (Larawan 2.9). Paikot-ikot ang trajectory ng pagbaba, na may katabing zigzag na mga link na orthogonal sa isa't isa. Sa katunayan, isang hakbang a k ay pinili sa pamamagitan ng pagliit ng A functions? (a) = f(x[k] -af"(x[k]))
. Kinakailangang kundisyon para sa minimum ng isang function d j (a)/da = 0. Ang pagkakaroon ng pagkalkula ng derivative ng isang kumplikadong pag-andar, nakuha namin ang kondisyon para sa orthogonality ng mga vectors ng mga direksyon ng pagbaba sa mga kalapit na punto: dj (a)/da = -f’(x[k+ 1]f'(x[k])
= 0.
Ang mga pamamaraan ng gradient ay nagtatagpo sa pinakamababa sa mataas na bilis (geometric progression speed) para sa makinis na mga function ng convex. Ang ganitong mga pag-andar ay may pinakamalaking M at least m eigenvalues ng matrix ng pangalawang derivatives (Hessian matrix) kaunti ang pagkakaiba sa isa't isa, ibig sabihin, matrix N(x) well conditioned. Alalahanin na ang eigenvalues l i, i
=1, …, n, ang mga matrice ay ang mga ugat ng katangian na equation Gayunpaman, sa pagsasagawa, bilang panuntunan, ang mga pag-andar na pinaliit ay may mga hindi nakakondisyon na matrice ng mga pangalawang derivatives. (t/m<<
1). Ang mga halaga ng naturang mga pag-andar kasama ang ilang mga direksyon ay nagbabago nang mas mabilis (kung minsan sa pamamagitan ng ilang mga order ng magnitude) kaysa sa iba pang mga direksyon. Ang kanilang mga antas ng ibabaw sa pinakasimpleng kaso ay malakas na pinahaba (Larawan 2.10), at sa mas kumplikadong mga kaso sila ay yumuko at mukhang mga bangin. Ang mga function na may ganitong mga katangian ay tinatawag kanal. Ang direksyon ng antigradient ng mga function na ito (tingnan ang Fig. 2.10) ay makabuluhang lumihis mula sa direksyon hanggang sa pinakamababang punto, na humahantong sa isang pagbagal sa bilis ng convergence. Ang rate ng convergence ng mga pamamaraan ng gradient ay nakadepende rin nang malaki sa katumpakan ng mga kalkulasyon ng gradient. Ang pagkawala ng katumpakan, na kadalasang nangyayari sa paligid ng mga pinakamababang punto o sa isang gully na sitwasyon, ay karaniwang maaaring makagambala sa convergence ng gradient descent process. Dahil sa mga dahilan sa itaas, ang mga pamamaraan ng gradient ay kadalasang ginagamit kasama ng iba, mas epektibong mga pamamaraan sa paunang yugto ng paglutas ng isang problema. Sa kasong ito, ang punto X ay malayo sa pinakamababang punto, at ang mga hakbang sa direksyon ng antigradient ay ginagawang posible upang makamit ang isang makabuluhang pagbaba sa pag-andar. Ang mga pamamaraan ng gradient na tinalakay sa itaas ay nakakahanap ng pinakamababang punto ng isang function sa pangkalahatang kaso lamang sa isang walang katapusang bilang ng mga pag-ulit. Ang conjugate gradient method ay bumubuo ng mga direksyon sa paghahanap na mas pare-pareho sa geometry ng function na pinaliit. Ito ay makabuluhang pinatataas ang bilis ng kanilang convergence at nagbibigay-daan, halimbawa, upang mabawasan ang quadratic function f(x) = (x, Hx) + (b, x) + a na may simetriko positibong tiyak na matrix N sa isang may hangganang bilang ng mga hakbang P, katumbas ng bilang ng mga variable ng function. Anumang maayos na paggana sa paligid ng pinakamababang punto ay maaaring matantya nang husto sa pamamagitan ng isang quadratic function, samakatuwid ang conjugate gradient method ay matagumpay na ginagamit upang mabawasan ang mga non-quadratic na function. Sa kasong ito, sila ay titigil sa pagiging may hangganan at nagiging umuulit. Sa pamamagitan ng kahulugan, dalawa n-dimensional na vector X At sa tinawag conjugated may kaugnayan sa matris H(o H-conjugate), kung ang scalar product (x, Well) = 0. Dito N - simetriko positibong tiyak na matrix ng laki P X P. Ang isa sa mga pinaka makabuluhang problema sa conjugate gradient na pamamaraan ay ang problema ng mahusay na pagbuo ng mga direksyon. Ang paraan ng Fletcher-Reeves ay nilulutas ang problemang ito sa pamamagitan ng pagbabago ng antigradient sa bawat hakbang -f(x[k])
sa direksyon p[k],
H-conjugate sa mga dating nahanap na direksyon R, R, ..., R[k-1]. Isaalang-alang muna natin ang pamamaraang ito kaugnay ng problema sa minimization. quadratic function R[k Mga direksyon ] ay kinakalkula gamit ang mga formula: k] = -f'(x[k])
p[ p[k+b k-1 k>= 1; -l], p = -’(x)
. f k b mga halaga p[k], R[k-1 ay pinili upang ang mga direksyon H-1] ay :
(p[k], -conjugate[HP 1])= 0.
k- Bilang resulta, para sa quadratic function ang umuulit na proseso ng minimization ay may anyo k+l] x[[k]=x[k], +a k p R[k] -
saan HP direksyon ng pagbaba sa m hakbang; at k - laki ng hakbang. Ang huli ay pinili mula sa pinakamababang kondisyon ng function f(x) A Sa pamamagitan ng f(x[ k] + sa direksyon ng paggalaw, ibig sabihin, bilang resulta ng paglutas ng one-dimensional na problema sa minimization:[k])
= f(x[k] + isang k r [k])
. ar Para sa isang quadratic function Ang algorithm ng Fletcher-Reeves conjugate gradient method ay ang mga sumusunod. X 1. Sa punto p = -f'(x)
. kalkulado HP 2. Naka-on A m hakbang, gamit ang mga formula sa itaas, ang hakbang ay tinutukoy .
k X[k+ 1]. at panahon f(x[k+1])
3. Kinakalkula ang mga halaga f'(x[k+1])
. At f'(x)
4. Kung X[k= 0, pagkatapos ay ituro +1] ay ang pinakamababang punto ng function f(x). p[k Kung hindi, matutukoy ang isang bagong direksyon +l] mula sa kaugnayan P at ang paglipat sa susunod na pag-ulit ay isinasagawa. Hahanapin ng pamamaraang ito ang minimum ng isang quadratic function sa hindi hihigit sa hakbang. Kapag pinaliit ang mga non-quadratic na function, ang Fletcher-Reeves na paraan ay nagiging umuulit mula sa may hangganan. Sa kasong ito, pagkatapos(p+ X 1) ang pag-ulit ng pamamaraan 1-4 ay paulit-ulit na paikot na may kapalit X[P sa ang umuulit na proseso ng minimization ay may anyo k+l] +1] , at nagtatapos ang mga kalkulasyon sa , kung saan ang isang ibinigay na numero. Sa kasong ito, ang sumusunod na pagbabago ng pamamaraan ay ginagamit:[k]=x[k],
] ay kinakalkula gamit ang mga formula: k] = x[k])+
= -f’(x HP 1 p[k+b k-1 k>= 1; b x); f(x[ k] + p = -f’([k])
= f(x[k] isang k p[k];
+ap Dito ako Dito- maraming mga index: = (0, n, 2 p, suweldo, ...) P, ibig sabihin, ang pamamaraan ay ina-update bawat hakbang. Geometric na kahulugan X Ang conjugate gradient na paraan ay ang mga sumusunod (Larawan 2.11). Mula sa isang naibigay na panimulang punto R = ang pagbaba ay isinasagawa sa direksyon-f"(x X). Sa punto ang gradient vector ay tinutukoy f"(x X ay ang pinakamababang punto ng function sa direksyon R,
yun f'(x)
orthogonal sa vector R. Pagkatapos ay natagpuan ang vector R , H-conjugate sa R. Susunod, nakita namin ang minimum ng function sa direksyon R atbp. Ang mga paraan ng direksyon ng conjugate ay kabilang sa mga pinaka-epektibo para sa paglutas ng mga problema sa minimization. Gayunpaman, dapat tandaan na sensitibo sila sa mga error na nangyayari sa proseso ng pagbibilang. Sa isang malaking bilang ng mga variable, ang error ay maaaring tumaas nang labis na ang proseso ay kailangang ulitin kahit na para sa isang quadratic function, ibig sabihin, ang proseso para dito ay hindi palaging magkasya sa P, ibig sabihin, ang pamamaraan ay ina-update bawat Ang pinakamatarik na paraan ng paglusong (sa panitikang Ingles na "paraan ng pinakamatarik na paglusong") ay isang umuulit na paraan ng numero (unang pagkakasunud-sunod) para sa paglutas ng mga problema sa pag-optimize, na nagbibigay-daan sa iyo upang matukoy ang labis (minimum o maximum) ng layunin na pag-andar: Alinsunod sa pamamaraan na isinasaalang-alang, ang extremum (maximum o minimum) ng layunin ng function ay tinutukoy sa direksyon ng pinakamabilis na pagtaas (pagbaba) ng function, i.e. sa direksyon ng gradient (anti-gradient) ng function. gradient function sa isang punto kung saan ang i, j,…, n ay mga unit vector na kahanay sa mga coordinate axes. Gradient sa base point Ang pinakamatarik na paraan ng pagbaba ay karagdagang pag-unlad paraan ng gradient descent. Sa pangkalahatan, ang proseso ng paghahanap ng extremum ng isang function ay isang umuulit na pamamaraan, na nakasulat tulad ng sumusunod: kung saan ang "+" sign ay ginagamit upang mahanap ang maximum ng isang function, at ang "-" sign ay ginagamit upang mahanap ang minimum ng isang function; Unit direction vector, na tinutukoy ng formula: Isang pare-pareho na tumutukoy sa laki ng hakbang at pareho para sa lahat ng i-th na direksyon. Ang laki ng hakbang ay pinili mula sa kundisyon ng pinakamaliit na layunin ng function na f(x) sa direksyon ng paggalaw, ibig sabihin, bilang resulta ng paglutas ng one-dimensional na problema sa pag-optimize sa direksyon ng gradient o antigradient: Sa madaling salita, ang laki ng hakbang ay tinutukoy sa pamamagitan ng paglutas ng equation na ito: Kaya, ang hakbang sa pagkalkula ay pinili upang ang paggalaw ay isinasagawa hanggang sa mapabuti ang pag-andar, kaya umabot sa isang extremum sa ilang mga punto. Sa puntong ito, muling tinutukoy ang direksyon ng paghahanap (gamit ang gradient) at hinahangad ang isang bagong pinakamabuting punto ng layunin ng function, atbp. Kaya, sa pamamaraang ito, ang paghahanap ay nangyayari sa mas malalaking hakbang, at ang gradient ng function ay kinakalkula sa mas maliit na bilang ng mga puntos. Sa kaso ng isang function ng dalawang variable ang pamamaraang ito ay may sumusunod na geometric na interpretasyon: ang direksyon ng paggalaw mula sa isang punto ay dumadampi sa antas na linya sa punto . Paikot-ikot ang trajectory ng pagbaba, na may katabing zigzag na mga link na orthogonal sa isa't isa. Ang kondisyon para sa orthogonality ng mga vector ng mga direksyon ng pagbaba sa mga kalapit na punto ay isinulat ng sumusunod na expression: Ang trajectory ng paggalaw sa extremum point gamit ang pinakamatarik na paraan ng pagbaba, na ipinapakita sa graph ng linya ng pantay na antas ng function na f(x) Ang paghahanap para sa isang pinakamainam na solusyon ay nagtatapos kapag nasa umuulit na hakbang sa pagkalkula (ilang pamantayan): Ang trajectory ng paghahanap ay nananatili sa isang maliit na lugar ng kasalukuyang punto ng paghahanap: Ang pagtaas ng layunin ng function ay hindi nagbabago: Ang gradient ng layunin ng function sa lokal na minimum na punto ay nagiging zero: Dapat pansinin na ang gradient descent method ay nagiging napakabagal kapag gumagalaw sa kahabaan ng bangin, at habang tumataas ang bilang ng mga variable sa layunin ng function, nagiging tipikal ang pag-uugaling ito ng pamamaraan. Ang bangin ay isang depresyon, ang mga linya ng antas kung saan humigit-kumulang ay may hugis ng mga ellipse na may mga semi-ax na naiiba nang maraming beses. Sa pagkakaroon ng isang bangin, ang trajectory ng pagbaba ay tumatagal ng anyo ng isang zigzag na linya na may isang maliit na hakbang, bilang isang resulta kung saan ang nagresultang bilis ng pagbaba sa isang minimum ay lubhang pinabagal. Ito ay ipinaliwanag sa pamamagitan ng katotohanan na ang direksyon ng antigradient ng mga function na ito ay lumihis nang malaki mula sa direksyon hanggang sa pinakamababang punto, na humahantong sa isang karagdagang pagkaantala sa pagkalkula. Bilang resulta, nawawalan ng kahusayan sa pagkalkula ang algorithm. Gully function Ang paraan ng gradient, kasama ang maraming pagbabago nito, ay laganap at mabisang paraan paghahanap para sa pinakamabuting kalagayan ng mga bagay na pinag-aaralan. Ang kawalan ng gradient na paghahanap (pati na rin ang mga pamamaraan na tinalakay sa itaas) ay kapag ginagamit ito, tanging ang lokal na extremum ng function ang maaaring makita. Para maghanap ng iba mga lokal na sukdulan ito ay kinakailangan upang maghanap mula sa iba pang mga panimulang punto. Ang bilis din ng convergence mga pamamaraan ng gradient malaki rin ang nakasalalay sa katumpakan ng mga kalkulasyon ng gradient. Ang pagkawala ng katumpakan, na kadalasang nangyayari sa paligid ng mga pinakamababang punto o sa isang gully na sitwasyon, ay karaniwang maaaring makagambala sa convergence ng gradient descent process. Paraan ng pagkalkula Hakbang 1: Kahulugan ng mga analytical na expression (sa simbolikong anyo) para sa pagkalkula ng gradient ng isang function Hakbang 2: Itakda ang paunang pagtatantya Hakbang 3: Natutukoy ang pangangailangang i-restart ang algorithmic procedure upang i-reset ang huling direksyon sa paghahanap. Bilang resulta ng pag-restart, ang paghahanap ay isinasagawa muli sa direksyon ng pinakamabilis na pagbaba.
 .
.
f(x[k]–a k f’(x[k]))
= f(x[k] – af"(x[k]))
.
j (a) = f(x[k]-af"(x[k]))
.




![]() ,
,![]()
 .
.
![]() ay ang mga halaga ng argumento ng function (mga kontroladong parameter) sa totoong domain.
ay ang mga halaga ng argumento ng function (mga kontroladong parameter) sa totoong domain.![]() ay isang vector na ang mga projection sa coordinate axes ay ang mga partial derivatives ng function na may paggalang sa mga coordinate:
ay isang vector na ang mga projection sa coordinate axes ay ang mga partial derivatives ng function na may paggalang sa mga coordinate:![]() ay mahigpit na orthogonal sa ibabaw, at ang direksyon nito ay nagpapakita ng direksyon ng pinakamabilis na pagtaas sa function, at ang kabaligtaran na direksyon (antigradient), ayon sa pagkakabanggit, ay nagpapakita ng direksyon ng pinakamabilis na pagbaba ng function.
ay mahigpit na orthogonal sa ibabaw, at ang direksyon nito ay nagpapakita ng direksyon ng pinakamabilis na pagtaas sa function, at ang kabaligtaran na direksyon (antigradient), ayon sa pagkakabanggit, ay nagpapakita ng direksyon ng pinakamabilis na pagbaba ng function.

![]() - tinutukoy ng gradient module ang rate ng pagtaas o pagbaba ng function sa direksyon ng gradient o anti-gradient:
- tinutukoy ng gradient module ang rate ng pagtaas o pagbaba ng function sa direksyon ng gradient o anti-gradient:
![]()
![]()

![]()









