Kryterium Fishera umożliwia porównanie wariancji dwóch niezależnych próbek. Aby obliczyć F emp, należy znaleźć stosunek wariancji dwóch próbek, tak aby większa wariancja znajdowała się w liczniku, a mniejsza w mianowniku. Wzór na obliczenie kryterium Fishera jest następujący:
gdzie są wariancjami odpowiednio pierwszej i drugiej próbki.
Ponieważ zgodnie z warunkami kryterium wartość licznika musi być większa lub równa wartości mianownika, wartość F emp będzie zawsze większa lub równa jedności.
Liczbę stopni swobody wyznacza się również w prosty sposób:
k 1 =rzecz l - 1 dla pierwszej próbki (tj. dla próbki, której wariancja jest większa) oraz k 2 = N 2 - 1 dla drugiej próbki.
W dodatku 1 wartości krytyczne kryterium Fishera znajdują się w wartościach k 1 (górna linia tabeli) i k 2 (lewa kolumna tabeli).
Jeśli t em > t krytyczna, wówczas przyjmuje się hipotezę zerową, w przeciwnym razie przyjmuje się alternatywę.
Przykład 3. Egzamin przeprowadzono w dwóch klasach trzecich rozwój mentalny dziesięciu uczniów na teście TURMSH. Uzyskane średnie wartości nie różniły się istotnie, jednak psychologa interesuje pytanie, czy istnieją różnice w stopniu jednorodności wskaźników rozwoju umysłowego pomiędzy klasami.
Rozwiązanie. W przypadku testu Fishera konieczne jest porównanie wariancji wyników testów w obu klasach. Wyniki testu przedstawiono w tabeli:
Tabela 3.
|
Liczba studentów |
Pierwsza klasa |
Druga klasa |
Po obliczeniu wariancji dla zmiennych X i Y otrzymujemy:
S X 2 =572,83; S y 2 =174,04
Następnie korzystając ze wzoru (8) do obliczeń z wykorzystaniem kryterium F Fishera znajdujemy:
![]()
Zgodnie z tabelą z Załącznika 1 dla kryterium F przy stopniach swobody w obu przypadkach równych k = 10 - 1 = 9, znajdujemy Fcrit = 3,18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Testy nieparametryczne
Porównując naocznie (w procentach) wyniki przed i po uderzeniu, badacz dochodzi do wniosku, że jeśli zaobserwuje się różnice, oznacza to, że różnią się porównywane próbki. Takie podejście jest kategorycznie niedopuszczalne, ponieważ w przypadku procentów nie można określić poziomu wiarygodności różnic. Same wartości procentowe nie pozwalają na wyciągnięcie statystycznie wiarygodnych wniosków. Aby udowodnić skuteczność jakiejkolwiek interwencji, konieczne jest zidentyfikowanie istotnej statystycznie tendencji w odchyleniu (przesunięciu) wskaźników. Aby rozwiązać takie problemy, badacz może zastosować szereg kryteriów dyskryminacji. Poniżej rozważymy testy nieparametryczne: test znaku i test chi-kwadrat.
Znaczenie równania regresji wielokrotnej jako całości, a także w regresji w parach ocenia się za pomocą kryterium Fishera:
 ,
(2.22)
,
(2.22)
Gdzie  – współczynnik sumy kwadratów na stopień swobody;
– współczynnik sumy kwadratów na stopień swobody;  – resztowa suma kwadratów na stopień swobody;
– resztowa suma kwadratów na stopień swobody;  – współczynnik (wskaźnik) wielokrotnej determinacji;
– współczynnik (wskaźnik) wielokrotnej determinacji;  – liczba parametrów zmiennych
– liczba parametrów zmiennych  (w regresji liniowej pokrywa się z liczbą czynników uwzględnionych w modelu);
(w regresji liniowej pokrywa się z liczbą czynników uwzględnionych w modelu);  – liczba obserwacji.
– liczba obserwacji.
Ocenia się znaczenie nie tylko równania jako całości, ale także czynnika dodatkowo uwzględnionego w modelu regresji. Potrzeba takiej oceny wynika z faktu, że nie każdy czynnik uwzględniony w modelu może znacząco zwiększyć udział wyjaśnianej zmienności uzyskanej cechy. Dodatkowo, jeśli w modelu występuje kilka czynników, można je wprowadzać do modelu w różnej kolejności. Ze względu na korelację między czynnikami znaczenie tego samego czynnika może być różne w zależności od kolejności jego wprowadzania do modelu. Miarą oceny włączenia czynnika do modelu jest współczynnik prywatny  -kryterium, tj.
-kryterium, tj.  .
.
Prywatny  -kryterium opiera się na porównaniu wzrostu wariancji czynnika pod wpływem dodatkowo uwzględnionego czynnika z wariancją resztową na jeden stopień swobody dla modelu regresji jako całości. Ogólnie rzecz biorąc dla czynnika
-kryterium opiera się na porównaniu wzrostu wariancji czynnika pod wpływem dodatkowo uwzględnionego czynnika z wariancją resztową na jeden stopień swobody dla modelu regresji jako całości. Ogólnie rzecz biorąc dla czynnika  prywatny
prywatny  -kryterium zostanie określone jako
-kryterium zostanie określone jako
 ,
(2.23)
,
(2.23)
Gdzie  – współczynnik wielokrotnej determinacji dla modelu z pełnym zestawem czynników,
– współczynnik wielokrotnej determinacji dla modelu z pełnym zestawem czynników,  – ten sam wskaźnik, ale bez uwzględnienia czynnika w modelu
– ten sam wskaźnik, ale bez uwzględnienia czynnika w modelu  ,
, – liczba obserwacji,
– liczba obserwacji,  – liczba parametrów w modelu (bez terminu swobodnego).
– liczba parametrów w modelu (bez terminu swobodnego).
Rzeczywista wartość ilorazu  - kryterium porównuje się z tabelą na poziomie istotności
- kryterium porównuje się z tabelą na poziomie istotności  i liczba stopni swobody: 1 i
i liczba stopni swobody: 1 i  . Jeśli rzeczywista wartość
. Jeśli rzeczywista wartość  przekracza
przekracza  , następnie dodatkowe włączenie czynnika
, następnie dodatkowe włączenie czynnika  do modelu jest uzasadniony statystycznie i czysty współczynnik regresji
do modelu jest uzasadniony statystycznie i czysty współczynnik regresji  na czynnik
na czynnik  istotne statystycznie. Jeśli rzeczywista wartość
istotne statystycznie. Jeśli rzeczywista wartość  jest mniejsza niż wartość z tabeli, wówczas dodatkowe uwzględnienie czynnika w modelu
jest mniejsza niż wartość z tabeli, wówczas dodatkowe uwzględnienie czynnika w modelu  nie zwiększa znacząco proporcji wyjaśnionej zmienności cechy
nie zwiększa znacząco proporcji wyjaśnionej zmienności cechy  dlatego niewłaściwe jest uwzględnienie go w modelu; Współczynnik regresji dla tego czynnika jest w tym przypadku nieistotny statystycznie.
dlatego niewłaściwe jest uwzględnienie go w modelu; Współczynnik regresji dla tego czynnika jest w tym przypadku nieistotny statystycznie.
W przypadku równania dwuczynnikowego ilorazy  -kryteria mają postać:
-kryteria mają postać:
 ,
, . (2.23a)
. (2.23a)
Korzystanie z prywatnego  -kryterium, można sprawdzić istotność wszystkich współczynników regresji przy założeniu, że każdemu odpowiada współczynnik
-kryterium, można sprawdzić istotność wszystkich współczynników regresji przy założeniu, że każdemu odpowiada współczynnik  wprowadzone do równania regresji wielokrotnej jako ostatnie.
wprowadzone do równania regresji wielokrotnej jako ostatnie.
-Test studencki dotyczący równania regresji wielokrotnej.
Prywatny  -kryterium ocenia znaczenie czystych współczynników regresji. Znając wielkość
-kryterium ocenia znaczenie czystych współczynników regresji. Znając wielkość  , można to ustalić
, można to ustalić  -kryterium współczynnika regresji przy
-kryterium współczynnika regresji przy  -m współczynnik,
-m współczynnik,  , a mianowicie:
, a mianowicie:
 .
(2.24)
.
(2.24)
Ocena znaczenia czystych współczynników regresji wg  -Test t-Studenta można przeprowadzić bez obliczania częściowej
-Test t-Studenta można przeprowadzić bez obliczania częściowej  -kryteria. W tym przypadku, podobnie jak w regresji parami, dla każdego czynnika stosuje się wzór:
-kryteria. W tym przypadku, podobnie jak w regresji parami, dla każdego czynnika stosuje się wzór:
 ,
(2.25)
,
(2.25)
Gdzie  – czysty współczynnik regresji na współczynniku
– czysty współczynnik regresji na współczynniku  ,
, – błąd średniokwadratowy (standardowy) współczynnika regresji
– błąd średniokwadratowy (standardowy) współczynnika regresji  .
.
W przypadku równania regresji wielokrotnej błąd średniokwadratowy współczynnika regresji można wyznaczyć za pomocą następującego wzoru:
 ,
(2.26)
,
(2.26)
Gdzie 
 ,
, – odchylenie standardowe dla charakterystyki
– odchylenie standardowe dla charakterystyki  ,
, – współczynnik determinacji dla równania regresji wielokrotnej,
– współczynnik determinacji dla równania regresji wielokrotnej,  – współczynnik determinacji zależności czynnika
– współczynnik determinacji zależności czynnika  ze wszystkimi innymi czynnikami w równaniu regresji wielokrotnej;
ze wszystkimi innymi czynnikami w równaniu regresji wielokrotnej;  – liczba stopni swobody dla rezydualnej sumy kwadratów odchyleń.
– liczba stopni swobody dla rezydualnej sumy kwadratów odchyleń.
Jak widać, aby skorzystać z tego wzoru, potrzebna jest macierz korelacji międzyczynnikowej i obliczenie za jej pomocą odpowiednich współczynników determinacji  . A więc dla równania
. A więc dla równania  ocena znaczenia współczynników regresji
ocena znaczenia współczynników regresji  ,
, ,
, polega na obliczeniu trzech współczynników determinacji międzyczynnikowej:
polega na obliczeniu trzech współczynników determinacji międzyczynnikowej:  ,
, ,
, .
.
Zależność między wskaźnikami częściowego współczynnika korelacji, częściowa  -kryteria i
-kryteria i  -W procedurze doboru czynników można zastosować test t-Studenta dla czystych współczynników regresji. Eliminację czynników przy konstruowaniu równania regresji metodą eliminacji można w praktyce przeprowadzić nie tylko poprzez cząstkowe współczynniki korelacji, wykluczając na każdym kroku czynnik o najmniejszej nieistotnej wartości współczynnika częściowej korelacji, ale także poprzez wartości
-W procedurze doboru czynników można zastosować test t-Studenta dla czystych współczynników regresji. Eliminację czynników przy konstruowaniu równania regresji metodą eliminacji można w praktyce przeprowadzić nie tylko poprzez cząstkowe współczynniki korelacji, wykluczając na każdym kroku czynnik o najmniejszej nieistotnej wartości współczynnika częściowej korelacji, ale także poprzez wartości  I
I  .
Prywatny
.
Prywatny  -kryterium ma szerokie zastosowanie przy konstruowaniu modelu metodą włączenia zmiennych oraz metodą regresji krokowej.
-kryterium ma szerokie zastosowanie przy konstruowaniu modelu metodą włączenia zmiennych oraz metodą regresji krokowej.
Obliczenie kryterium φ*
1. Określ wartości atrybutu, które będą kryterium podziału podmiotów na tych, którzy „mają wpływ” i tych, którzy „nie mają wpływu”. Jeżeli charakterystyka jest mierzona ilościowo, należy zastosować kryterium λ w celu znalezienia optymalnego punktu separacji.
2. Narysuj czterokomórkową (synonim: czteropolową) tabelę składającą się z dwóch kolumn i dwóch wierszy. Pierwsza kolumna brzmi „istnieje efekt”; druga kolumna - „brak efektu”; pierwsza linia od góry - 1 grupa (próbka); druga linia - grupa 2 (próbka).
4. Policz liczbę pacjentów w pierwszej próbie, u których „nie zaobserwowano żadnego efektu” i wpisz tę liczbę w prawej górnej komórce tabeli. Oblicz sumę dwóch górnych komórek. Powinna pokrywać się z liczbą przedmiotów w pierwszej grupie.
6. Policz liczbę pacjentów w drugiej próbie, u których „nie zaobserwowano żadnego efektu” i wpisz tę liczbę w prawej dolnej komórce tabeli. Oblicz sumę dwóch dolnych komórek. Powinna pokrywać się z liczbą osób w drugiej grupie (próbie).
7. Określ odsetek osób, które „mają wpływ”, odnosząc ich liczbę do całkowitej liczby osób w danej grupie (próbie). Otrzymane wartości procentowe wpisz odpowiednio w lewych górnych i lewych komórkach tabeli w nawiasach, aby nie pomylić ich z wartościami bezwzględnymi.
8. Sprawdź, czy jeden z porównywanych procentów jest równy zero. W takim przypadku spróbuj to zmienić, przesuwając punkt separacji grup w tę czy inną stronę. Jeżeli jest to niemożliwe lub niepożądane, należy zrezygnować z kryterium φ* i zastosować kryterium χ2.
9. Ustalić zgodnie z tabelą. XII Załącznik 1 Kąty φ dla każdego z porównywanych procentów.
gdzie: φ1 – kąt odpowiadający większemu procentowi;
φ2 - kąt odpowiadający mniejszemu procentowi;
N1 - liczba obserwacji w próbie 1;
N2 - liczba obserwacji w próbie 2.
11. Porównaj uzyskaną wartość φ* z wartościami krytycznymi: φ* ≤1,64 (p<0,05) и φ* ≤2,31 (р<0,01).
Jeżeli φ*emp ≤φ*cr. H0 zostaje odrzucony.
W razie potrzeby określ dokładny poziom istotności otrzymanego φ*emp zgodnie z tabelą. XIII Załącznik 1.
Metodę tę opisano w wielu podręcznikach (Plokhinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992 itd.). Opis ten opiera się na wersji metody opracowanej i zaprezentowanej przez E.V. Gublera.
Cel kryterium φ*
Kryterium Fishera ma na celu porównanie dwóch próbek pod względem częstotliwości występowania efektu (wskaźnika) interesującego badacza. Im jest większy, tym bardziej wiarygodne są różnice.
Opis kryterium
Kryterium ocenia wiarygodność różnic pomiędzy procentami dwóch próbek, w których zarejestrowano interesujący nas efekt (wskaźnik). Mówiąc obrazowo, porównujemy 2 najlepsze kawałki wycięte z 2 ciast i decydujemy, który z nich jest naprawdę większy.
Istotą transformacji kątowej Fishera jest przeliczenie wartości procentowych na wartości kąta środkowego, które są mierzone w radianach. Większy procent będzie odpowiadał większemu kątowi φ, a mniejszy procent będzie odpowiadał mniejszemu kątowi, ale tutaj zależności nie są liniowe:
gdzie P jest procentem wyrażonym w ułamkach jednostki (patrz ryc. 5.1).
Wraz ze wzrostem rozbieżności pomiędzy kątami φ 1 i φ 2 i zwiększając liczbę próbek, wartość kryterium wzrasta. Im większa wartość φ*, tym większe prawdopodobieństwo, że różnice są istotne.
Hipotezy
H 0 : Proporcja osób, w których przejawia się badany efekt, w próbce 1 nie ma ich więcej niż w próbce 2.
H 1 : Odsetek osób wykazujących badany efekt jest większy w próbie 1 niż w próbie 2.
Graficzne przedstawienie kryterium φ*
Metoda transformacji kątowej jest nieco bardziej abstrakcyjna niż inne kryteria.
Wzór, którym kieruje się E.V. Gubler przy obliczaniu wartości φ zakłada, że 100% tworzy kąt φ=3,142, czyli zaokrągloną wartość π=3,14159... Pozwala to na przedstawienie porównywanych próbek w postaci dwa półkola, z których każdy symbolizuje 100% populacji danej próby. Odsetek obiektów wykazujących „efekt” będzie reprezentowany jako sektory utworzone przez kąty środkowe φ. Na ryc. Rysunek 5.2 przedstawia dwa półkola ilustrujące przykład 1. W pierwszej próbie 60% badanych rozwiązało problem. Procent ten odpowiada kątowi φ=1,772. W drugiej próbie problem rozwiązało 40% badanych. Procent ten odpowiada kątowi φ =1,369.
Kryterium φ* pozwala określić, czy dla danych liczebności próbek jeden z kątów jest rzeczywiście statystycznie istotnie lepszy od drugiego.
Ograniczenia kryterium φ*
1. Żadna z porównywanych proporcji nie powinna wynosić zero. Formalnie nie ma przeszkód, aby zastosować metodę φ w przypadkach, gdy proporcja obserwacji w jednej z próbek jest równa 0. Jednak w tych przypadkach wynik może okazać się nieuzasadniony zawyżony (Gubler E.V., 1978, s. 86).
2. Górna kryterium φ nie ma ograniczeń – próbki mogą być dowolnie duże.
Niżej limit - 2 obserwacje w jednej z próbek. Należy jednak zachować następujące proporcje w liczbie dwóch próbek:
a) jeśli jedna próbka ma tylko 2 obserwacje, to druga musi mieć co najmniej 30:
b) jeśli jedna z próbek ma tylko 3 obserwacje, to druga musi mieć co najmniej 7:
c) jeśli jedna z próbek ma tylko 4 obserwacje, to druga musi mieć co najmniej 5:
d) o godzN 1 , N 2 ≥ 5 Wszelkie porównania są możliwe.
W zasadzie możliwe jest także porównanie próbek, które nie spełniają tego warunku, np. z zależnościąN 1 =2, N 2 = 15, jednak w tych przypadkach nie będzie możliwe stwierdzenie istotnych różnic.
Kryterium φ* nie ma innych ograniczeń.
Spójrzmy na kilka przykładów, aby zilustrować możliwościkryterium φ*.
Przykład 1: porównanie próbek według jakościowo określonej cechy.
Przykład 2: porównanie próbek według ilościowo zmierzonej cechy.
Przykład 3: porównanie próbek zarówno pod względem poziomu, jak i rozkładu cechy.
Przykład 4: Stosowanie kryterium φ* w połączeniu z kryteriumX Kołmogorov-Smirnov w celu uzyskania jak najdokładniejszego wyniku.
Przykład 1 - porównanie próbek według jakościowo określonej cechy
W tym zastosowaniu kryterium porównujemy odsetek osób w jednej próbie charakteryzujących się pewną jakością z odsetkiem osób w innej próbie, charakteryzujących się tą samą jakością.
Załóżmy, że interesuje nas, czy dwie grupy uczniów różnią się pod względem powodzenia w rozwiązywaniu nowego problemu eksperymentalnego. W pierwszej 20-osobowej grupie poradziło sobie z tym 12 osób, a w drugiej 25-osobowej próbie – 10. W pierwszym przypadku odsetek osób, które rozwiązały problem wyniesie 12/20·100%=60%, a w drugim 10/25·100%= 40%. Czy te wartości procentowe różnią się znacząco, biorąc pod uwagę dane?N 1 IN 2 ?
Wydawać by się mogło, że nawet „na oko” można stwierdzić, że 60% to znacznie więcej niż 40%. Jednak w rzeczywistości te różnice, biorąc pod uwagę daneN 1 , N 2 niewiarygodne.
Sprawdźmy to. Ponieważ interesuje nas fakt rozwiązania problemu, sukces w rozwiązaniu problemu eksperymentalnego będziemy uważać za „efekt”, a niepowodzenie w rozwiązaniu za brak efektu.
Formułujmy hipotezy.
H 0 : Proporcja osóbW grupie pierwszej nie było więcej osób, które wykonały zadanie niż w grupie drugiej.
H 1 : Odsetek osób, które wykonały zadanie w grupie pierwszej jest większy niż w grupie drugiej.
Zbudujmy teraz tak zwaną tabelę czterokomórkową, czyli czteropolową, która w rzeczywistości jest tabelą częstości empirycznych dla dwóch wartości atrybutu: „jest efekt” - „nie ma efektu”.
Tabela 5.1
Czterokomórkowa tabela do obliczania kryterium przy porównywaniu dwóch grup badanych według odsetka osób, które rozwiązały problem.
Grupy | „Jest efekt”: problem rozwiązany | „Brak efektu”: problem nie został rozwiązany | Kwoty |
||||
Ilość tematy | % udział | Ilość tematy | % udział | ||||
1 grupa | (60%) | (40%) | |||||
2. grupa | (40%) | (60%) | |||||
Kwoty | |||||||
W tabeli czterokomórkowej z reguły kolumny „Występuje efekt” i „Brak efektu” są zaznaczone u góry, a wiersze „Grupa 1” i „Grupa 2” znajdują się po lewej stronie. Tak naprawdę w porównaniach biorą udział tylko pola (komórki) A i B, czyli wartości procentowe w kolumnie „Istnieje efekt”.
Według tabeli.XIIW załączniku 1 określono wartości φ odpowiadające udziałom procentowym w każdej z grup.
Obliczmy teraz wartość empiryczną φ* korzystając ze wzoru:
gdzie φ 1 - kąt odpowiadający większemu udziałowi %;
φ 2 - kąt odpowiadający mniejszemu udziałowi %;
N 1 - liczba obserwacji w próbie 1;
N 2 - liczba obserwacji w próbie 2.
W tym przypadku:
Według tabeli.XIIIW Załączniku 1 określamy, jaki poziom istotności odpowiada φ* oni=1,34:
p=0,09
Możliwe jest także ustalenie wartości krytycznych φ* odpowiadających przyjętym w psychologii poziomom istotności statystycznej:
Zbudujmy „oś znaczenia”.
Uzyskana wartość empiryczna φ* mieści się w strefie nieistotności.
Odpowiedź: H 0 przyjęty. Procent osób, które wykonały zadanieVpierwsza grupa nie jest większa niż druga grupa.
Można jedynie współczuć badaczowi, który różnice rzędu 20, a nawet 10% uważa za istotne, nie sprawdzając ich wiarygodności za pomocą kryterium φ*. W tym przypadku na przykład istotne byłyby jedynie różnice wynoszące co najmniej 24,3%.
Wydaje się, że porównując dwie próbki na dowolnej podstawie jakościowej, kryterium φ może wywołać raczej smutek niż radość. To, co wydawało się istotne, może takim nie być ze statystycznego punktu widzenia.
Kryterium Fishera ma znacznie więcej możliwości zadowolenia badacza, gdy porównujemy dwie próbki według ilościowo zmierzonych cech i może zmieniać „efekt”.
Przykład 2 - porównanie dwóch próbek według ilościowo zmierzonej charakterystyki
W tym zastosowaniu kryterium porównujemy odsetek osób w jednej próbie, które osiągnęły określony poziom wartości atrybutu, z odsetkiem osób, które osiągnęły ten poziom w innej próbie.
W badaniu G. A. Tlegenovej (1990) spośród 70 uczniów szkół zawodowych w wieku od 14 do 16 lat wybrano na podstawie wyników 10 uczniów z wysokim wynikiem w skali agresji i 11 uczniów z niskim wynikiem w skali agresji. ankiety z wykorzystaniem Kwestionariusza Osobowości Freiburga. Należy ustalić, czy grupy młodych mężczyzn agresywnych i nieagresywnych różnią się pod względem dystansu, jaki spontanicznie wybierają w rozmowie z kolegą ze studiów. Dane G. A. Tlegenovej przedstawiono w tabeli. 5.2. Można zauważyć, że agresywni młodzi mężczyźni częściej wybierają dystans 50cm lub nawet mniej, natomiast chłopcy nieagresywni częściej wybierają odległość większą niż 50 cm.
Teraz możemy uznać odległość 50 cm za krytyczną i założyć, że jeśli wybrana przez badanego odległość jest mniejsza lub równa 50 cm, to „zachodzi efekt”, a jeśli wybrana odległość jest większa niż 50 cm, to „nie ma żadnego efektu”. Widzimy, że w grupie młodych mężczyzn agresywnych efekt obserwuje się w 7 na 10, czyli w 70% przypadków, a w grupie młodych mężczyzn nieagresywnych – w 2 na 11, czyli w 18,2% przypadków . Odsetki te można porównać metodą φ* w celu ustalenia istotności różnic między nimi.
Tabela 5.2
Wskaźniki odległości (w cm) wybrane przez agresywnych i nieagresywnych młodych mężczyzn w rozmowie z kolegą ze studiów (wg G.A. Tlegenova, 1990)
Grupa 1: chłopcy z wysokimi wynikami w skali agresjiFPI- R (N 1 =10) | Grupa 2: chłopcy z niskimi wartościami na Skali AgresjiFPI- R (N 2 =11) |
|||
d (ok M ) | % udział | d (ok M ) | % udział |
|
"Jeść Efekt" D≤50cm | ||||
18,2% |
||||
"NIE efekt" d>50 cm | ||||
80 QO | 81,8% |
|||
Kwoty | 100% | 100% |
||
Przeciętny | 5b:o | 77.3 | ||
Formułujmy hipotezy.
H 0 D ≤ 50 cm, w grupie chłopców agresywnych nie jest ich więcej niż w grupie chłopców nieagresywnych.
H 1 : Odsetek osób, które wybierają odległośćD≤ 50 cm, więcej w grupie młodych mężczyzn agresywnych niż w grupie młodych mężczyzn nieagresywnych. Zbudujmy teraz tak zwaną tabelę czterokomórkową.
Tabela 53
Czterokomórkowa tabela do obliczania kryterium φ* przy porównywaniu grup agresywnych (nf=10) i nieagresywni młodzi mężczyźni (n2=11)
Grupy | „Jest efekt”: D≤50 | "Bez efektu." D>50 | Kwoty |
||||
Liczba przedmiotów | (% udział) | Liczba przedmiotów | (% udział) | ||||
Grupa 1 – agresywni młodzi mężczyźni | (70%) | (30%) | |||||
Grupa 2 – nieagresywni młodzi mężczyźni | (180%) | (81,8%) | |||||
Suma | |||||||
Według tabeli.XIIW załączniku 1 określono wartości φ odpowiadające procentowym udziałom „efektu” w każdej z grup.
Uzyskana wartość empiryczna φ* mieści się w strefie istotności.
Odpowiedź: H 0 odrzucony. PrzyjętyH 1 . Odsetek osób, które wybierają w rozmowie odległość mniejszą lub równą 50 cm, jest większy w grupie młodych mężczyzn agresywnych niż w grupie młodych mężczyzn nieagresywnych
Na podstawie uzyskanych wyników można stwierdzić, że młodzi mężczyźni bardziej agresywni częściej wybierają dystans mniejszy niż pół metra, natomiast młodzi mężczyźni nieagresywni częściej wybierają dystans większy niż pół metra. Widzimy, że agresywni młodzi mężczyźni tak naprawdę komunikują się na granicy strefy intymnej (0-46 cm) i osobistej (od 46 cm). Pamiętamy jednak, że intymny dystans pomiędzy partnerami to przywilej nie tylko bliskich, dobrych relacji, aleIwalka wręcz (Halami. T., 1959).
Przykład 3 - porównanie próbek zarówno pod względem poziomu, jak i rozkładu cechy.
W tym przypadku użycia możemy najpierw sprawdzić, czy grupy różnią się poziomem jakiejś cechy, a następnie porównać rozkład cechy w dwóch próbach. Zadanie takie może mieć znaczenie przy analizie różnic w zakresach lub kształcie rozkładu ocen uzyskiwanych przez osoby stosujące jakąkolwiek nową technikę.
W badaniach R. T. Chirkiny (1995) po raz pierwszy zastosowano kwestionariusz mający na celu identyfikację tendencji do wypierania z pamięci faktów, nazw, intencji i metod działania ze względu na kompleksy osobiste, rodzinne i zawodowe. Kwestionariusz powstał przy udziale E.V. Sidorenko na podstawie materiałów z książki 3. Freud „Psychopatologia życia codziennego”. Zbadano próbę 50 studentów Instytutu Pedagogicznego, stanu wolnego, bez dzieci, w wieku od 17 do 20 lat, stosując niniejszą ankietę oraz technikę Menestera-Corziniego w celu określenia nasilenia poczucia osobistej niewystarczalności,Lub„kompleks niższości” (ManasterG. J., CorsiniR. J., 1982).
Wyniki badania przedstawiono w tabeli. 5.4.
Czy można powiedzieć, że istnieją istotne zależności pomiędzy diagnozowanym za pomocą kwestionariusza wskaźnikiem energii wyparcia a wskaźnikami intensywności, poczuciem własnej niewystarczalności?
Tabela 5.4
Wskaźniki natężenia poczucia niedoskonałości osobistej w grupach uczniów z wysokim (nj=18) i niską (n2=24) energię wyporu
Grupa 1: energia przemieszczenia od 19 do 31 punktów (N 1 =181 | Grupa 2: energia przemieszczenia od 7 do 13 punktów (N 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
Kwoty Przeciętny | 26,11 | 15,42 |
Pomimo tego, że średnia wartość w grupie z bardziej energicznym wyparciem jest wyższa, obserwuje się w niej również 5 wartości zerowych. Jeśli porównamy histogramy rozkładu ocen w obu próbkach, ujawnimy między nimi uderzający kontrast (ryc. 5.3).
Aby porównać dwie rozkłady, moglibyśmy zastosować testχ 2 lub kryteriumλ , ale w tym celu musielibyśmy powiększyć szeregi, i to w dodatku w obu próbachN <30.
Kryterium φ* pozwoli nam sprawdzić wpływ rozbieżności pomiędzy dwoma rozkładami zaobserwowanymi na wykresie, jeśli zgodzimy się przyjąć, że „istnieje efekt”, jeśli wskaźnik poczucia niedosytu przyjmuje albo bardzo niski (0), albo odwrotnie , bardzo wysokie wartości (S30), a „nie ma efektu”, jeśli wskaźnik poczucia niedosytu przyjmuje wartości średnie od 5 do 25.
Formułujmy hipotezy.
H 0 : Ekstremalne wartości wskaźnika niedoboru (0, 30 lub więcej) w grupie z bardziej energiczną represją nie są częstsze niż w grupie z mniej energetyczną represją.
H 1 : Skrajne wartości wskaźnika niedoboru (0, 30 lub więcej) w grupie z bardziej energetyczną represją są częstsze niż w grupie z mniej energetyczną represją.
Stwórzmy czterokomórkową tabelę wygodną do dalszych obliczeń kryterium φ*.
Tabela 5.5
Czterokomórkowa tabela do obliczania kryterium φ* przy porównywaniu grup o wyższych i niższych energiach represji na podstawie stosunku wskaźników niewystarczalności
Grupy | „Istnieje efekt”: wskaźnik niedoboru wynosi 0 lub >30 | „Brak efektu”: wskaźnik awarii od 5 do 25 | Kwoty |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
Kwoty | |||||
Według tabeli.XIIW Załączniku 1 wyznaczamy wartości φ odpowiadające porównywanym procentom:
Obliczmy wartość empiryczną φ*:
Krytyczne wartości φ* dla dowolnegoN 1 , N 2 , jak pamiętamy z poprzedniego przykładu, są:
TabelaXIIIZałącznik 1 pozwala dokładniej określić poziom istotności uzyskanego wyniku: s. 10-10<0,001.
Odpowiedź: H 0 odrzucony. PrzyjętyH 1 . Skrajne wartości wskaźnika niedoboru (0, 30 lub więcej) w grupie o większej energii represji występują częściej niż w grupie o mniejszej energii represji.
Zatem osoby o większej energii wyparcia mogą mieć zarówno bardzo wysokie (30 lub więcej), jak i bardzo niskie (zero) wskaźniki poczucia własnej niewydolności. Można przypuszczać, że tłumią zarówno swoje niezadowolenie, jak i potrzebę odniesienia sukcesu życiowego. Założenia te wymagają dalszych testów.
Uzyskany wynik niezależnie od interpretacji potwierdza możliwości kryterium φ* w ocenie różnic w kształcie rozkładu cechy w dwóch próbach.
W pierwotnej próbie było 50 osób, ale 8 z nich zostało wykluczonych z analizy ze względu na średni wynik w zakresie wskaźnika anergii represji (14-15). Ich wskaźniki intensywności uczucia niedosytu są również średnie: 6 wartości po 20 punktów każda i 2 wartości po 25 punktów każda.
Potężne możliwości kryterium φ* można zweryfikować, potwierdzając zupełnie inną hipotezę podczas analizy materiałów tego przykładu. Można np. wykazać, że w grupie o większej energii represji wskaźnik niewydolności jest jeszcze wyższy, pomimo paradoksalnego charakteru jej rozkładu w tej grupie.
Formułujmy nowe hipotezy.
H 0 Najwyższe wartości wskaźnika niedoboru (30 i więcej) w grupie o większej energii wyparcia nie są częstsze niż w grupie o mniejszej energii wyparcia.
H 1 : Największe wartości wskaźnika niedoboru (30 i więcej) w grupie o większej energii wyparcia występują częściej niż w grupie o mniejszej energii wyparcia. Zbudujmy tabelę z czterema polami, korzystając z danych zawartych w tabeli. 5.4.
Tabela 5.6
Czterokomarkowa tabela do obliczania kryterium φ* przy porównywaniu grup o większej i mniejszej energii represji według wskaźnika poziomu niewystarczalności
Grupy | Wskaźnik awarii „Istnieje efekt”* jest większy lub równy 30 | „Brak efektu”: wskaźnik awaryjności jest mniejszy 30 | Kwoty |
||
Grupa 1 – z większą energią wyporu | (61,1%) | (38.9%) | |||
Grupa 2 – z mniejszą energią wyporu | (25.0%) | (75.0%) | |||
Kwoty | |||||
Według tabeli.XIIIW Załączniku 1 stwierdzamy, że wynik ten odpowiada poziomowi istotności p = 0,008.
Odpowiedź: Ale zostaje odrzucony. PrzyjętyHj: Najwyższe wskaźniki niedoborów (30 i więcej punktów) w grupieZz większą energią przemieszczenia występują częściej niż w grupie z mniejszą energią przemieszczenia (p = 0,008).
Udało nam się więc to udowodnićVGrupaZprzy bardziej energicznym tłumieniu dominują skrajne wartości wskaźnika niewystarczalności, a fakt, że wskaźnik ten przekracza jego wartościsięgawłaśnie w tej grupie.
Teraz moglibyśmy spróbować wykazać, że w grupie o wyższej energii represji niższe wartości wskaźnika niewystarczalności występują częściej, mimo że wartość średniaV w tej grupie jest ich więcej (26,11 wobec 15,42 w grupie).Z mniejsze przemieszczenie).
Formułujmy hipotezy.
H 0 : Najniższy wskaźnik niedoborów (zero) w grupieZ represje o większej energii nie są częstsze niż w grupieZ mniejsza energia przemieszczenia.
H 1 : Występują najniższe wskaźniki niedoborów (zero).V częściej niż w grupie o większej energii represjiZ mniej energiczne tłumienie. Pogrupujmy dane w nową czterokomórkową tabelę.
Tabela 5.7
Czterokomórkowa tabela do porównywania grup o różnych energiach represji na podstawie częstotliwości zerowych wartości wskaźnika niedoboru
Grupy | „Jest efekt”: wskaźnik awarii wynosi 0 | „Brak efektu” niewydolności | wskaźnik nie jest równy 0 | Kwoty |
|
Grupa 1 – z większą energią wyporu | (27,8%) | (72,2%) | |||
1 grupa - z mniejszą energią przemieszczenia | (8,3%) | (91,7%) | |||
Kwoty | |||||
Wyznaczamy wartości φ i obliczamy wartość φ*:
Odpowiedź: H 0 odrzucony. Najniższe wskaźniki niewydolności (zero) w grupie o większej energii wyparcia są częstsze niż w grupie o mniejszej energii wyparcia (p<0,05).
W sumie uzyskane wyniki można uznać za dowód częściowej zbieżności pojęć kompleksu u S. Freuda i A. Adlera.
Znaczące jest, że uzyskano dodatnią korelację liniową pomiędzy wskaźnikiem energii wyparcia a wskaźnikiem natężenia poczucia własnej niewystarczalności w całej próbie (p = +0,491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Przykład 4 – zastosowanie kryterium φ* w połączeniu z kryterium λ Kołmogorowa-Smirnowa, aby osiągnąć maksimum dokładnywynik
Jeżeli próbki porównuje się według jakichkolwiek ilościowo mierzonych wskaźników, pojawia się problem określenia punktu dystrybucji, który można wykorzystać jako punkt krytyczny przy podziale wszystkich podmiotów na tych, którzy „mają wpływ” i tych, którzy „nie mają wpływu”.
W zasadzie punkt, w którym podzielilibyśmy grupę na podgrupy, w których występuje efekt i w których nie ma efektu, można wybrać dość arbitralnie. Interesować może nas dowolny efekt, dlatego w dowolnym momencie możemy podzielić obie próbki na dwie części, o ile ma to jakiś sens.
Aby jednak zmaksymalizować moc testu φ*, należy wybrać punkt, w którym różnice pomiędzy porównywanymi grupami są największe. Najdokładniej możemy to zrobić za pomocą algorytmu obliczania kryteriumλ , co pozwala wykryć punkt maksymalnej rozbieżności pomiędzy dwiema próbkami.
Możliwość łączenia kryteriów φ* iλ opisany przez E.V. Gublera (1978, s. 85-88). Spróbujmy zastosować tę metodę do rozwiązania następującego problemu.
We wspólnym badaniu M.A. Kurochkina, E.V. Sidorenko i Yu.A. Churakov (1992) w Wielkiej Brytanii przeprowadził badanie wśród angielskich lekarzy pierwszego kontaktu dwóch kategorii: a) lekarzy, którzy wspierali reformę medycyny i przekształcili już swoje biura recepcyjne w organizacje posiadające fundusze z własnym budżetem; b) lekarzy, których gabinety nadal nie posiadają własnych środków i są w całości finansowane z budżetu państwa. Ankiety wysłano do próby 200 lekarzy, reprezentatywnej dla ogólnej populacji lekarzy angielskich pod względem reprezentacji osób różnej płci, wieku, stażu pracy i miejscu pracy – w dużych miastach lub na województwach.
Na ankietę odpowiedziało 78 lekarzy, z czego 50 pracowało w poczekalniach za środki, a 28 w poczekalniach bez środków. Każdy z lekarzy musiał przewidzieć, jaki będzie udział przyjęć w funduszach w następnym roku, 1993. Na to pytanie odpowiedziało jedynie 70 lekarzy z 78, którzy przesłali odpowiedzi. Rozkład ich prognoz przedstawiono w tabeli. 5.8 oddzielnie dla grupy lekarzy posiadających fundusze i grupy lekarzy nieposiadających środków.
Czy prognozy lekarzy z funduszami i lekarzy bez funduszy różnią się w jakiś sposób?
Tabela 5.8
Rozpowszechnienie prognoz lekarzy pierwszego kontaktu na temat tego, jaki będzie udział izb przyjęć w funduszach w 1993 roku
Prognozowany udział | |||
sale recepcyjne z funduszami | lekarze z funduszem (N 1 =45) | lekarze bez funduszu (N 2 =25) | Kwoty |
1. od 0 do 20% | 4 | 5 | 9 |
2. od 21 do 40% | 15 | I | 26 |
3. od 41 do 60% | 18 | 5 | 23 |
4. od 61 do 80% | 7 | 4 | I |
5. od 81 do 100% | 1 | 0 | 1 |
Kwoty | 45 | 25 | 70 |
Wyznaczmy punkt maksymalnej rozbieżności pomiędzy dwoma rozkładami odpowiedzi, korzystając z Algorytmu 15 z punktu 4.3 (patrz tabela 5.9).
Tabela 5.9
Obliczenie maksymalnej różnicy skumulowanych częstotliwości w rozkładach prognoz lekarzy dwóch grup
Prognozowany udział przyjęć wraz ze środkami (%) | Częstotliwości empiryczne wybrane dla danej kategorii odpowiedzi | Częstotliwości empiryczne | Skumulowane częstotliwości empiryczne | Różnica (D) |
|||
lekarze z funduszu(N 1 =45) | lekarze bez funduszu (N 2 =25) | F* uh 1 | F* a2 | ∑F* e1 | ∑F* a1 |
||
1. od 0 do 20% 2. od 21 do 40% 3. od 41 do 60% 4. od 61 do 80% 5. od 81 do 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
Maksymalna wykryta różnica między dwiema skumulowanymi częstotliwościami empirycznymi wynosi0,218.
Różnica ta okazuje się kumulować w drugiej kategorii prognozy. Spróbujmy wykorzystać górną granicę tej kategorii jako kryterium podziału obu próbek na podgrupę, w której „jest efekt” i podgrupę, w której „nie ma efektu”. Założymy, że jest „efekt”, jeśli dany lekarz przepowie od 41 do 100% przyjęć ze środkami w1993 roku i że „nie ma efektu”, jeśli dany lekarz przewidzi od 0 do 40% przyjęć ze środkami w1993 rok. Łączymy z jednej strony kategorie prognoz 1 i 2, a z drugiej kategorie prognoz 3, 4 i 5. Otrzymany rozkład prognoz przedstawiono w tabeli. 5.10.
Tabela 5.10
Dystrybucja prognoz dla lekarzy posiadających środki i lekarzy bez środków
Prognozowany udział przyjęć ze środkami (%1 | Empiryczne częstotliwości wyboru danej kategorii prognozy | Kwoty |
|
lekarze z funduszu(N 1 =45) | lekarze bez funduszy(N 2 =25) |
||
1. od 0 do 40% | 19 | 16 | 35 |
2. od 41 do 100% | 26 | 9 | 35 |
Kwoty | 45 | 25 | 70 |
Możemy wykorzystać wynikową tabelę (Tabela 5.10) do przetestowania różnych hipotez, porównując dowolne dwie jej komórki. Pamiętamy, że jest to tzw. tabela czterokomórkowa, czyli czteropolowa.
W tym miejscu interesuje nas, czy lekarze, którzy już mają fundusze, przewidują większy przyszły rozwój tego ruchu niż lekarze, którzy nie mają funduszy. Dlatego warunkowo uważamy, że „istnieje efekt”, gdy prognoza mieści się w kategorii od 41 do 100%. Aby uprościć obliczenia, musimy teraz obrócić stół o 90°, obracając go w kierunku zgodnym z ruchem wskazówek zegara. Można to zrobić nawet dosłownie, obracając książkę wraz ze stołem. Teraz możemy przejść do arkusza kalkulacyjnego obliczania kryterium φ* – Transformaty Kątowej Fishera.
Tabela 5.11
Czterokomórkowa tabela do obliczania kryterium φ* Fishera w celu identyfikacji różnic w prognozach dwóch grup lekarzy pierwszego kontaktu
Grupa | Jest efekt - prognoza od 41 do 100% | Brak efektu - prognoza od 0 do 40% | Całkowity |
Igrupa - lekarze, którzy wzięli fundusz | 26 (57.8%) | 19 (42.2%) | 45 |
IIgrupa - lekarze, którzy nie przyjęli funduszu | 9 (36.0%) | 16 (64.0%) | 25 |
Całkowity | 35 | 35 | 70 |
Formułujmy hipotezy.
H 0 : Proporcja osóbprognozując rozproszenie środków na 41%-100% wszystkich gabinetów lekarskich, w grupie lekarzy posiadających środki nie ma ich więcej niż w grupie lekarzy bez środków.
H 1 : Odsetek osób przewidujących rozdysponowanie środków do 41%-100% wszystkich przyjęć jest większy w grupie lekarzy posiadających środki niż w grupie lekarzy bez środków.
Określanie wartości φ 1 i φ 2 zgodnie z tabeląXIIDodatek 1. Przypomnijmy, że φ 1 jest zawsze kątem odpowiadającym większemu procentowi.
Wyznaczmy teraz wartość empiryczną kryterium φ*:
Według tabeli.XIIIW Załączniku 1 określamy, jakiemu poziomowi istotności odpowiada ta wartość: p = 0,039.
Korzystając z tej samej tabeli w dodatku 1, możesz określić wartości krytyczne kryterium φ*:
Odpowiedź: Został on jednak odrzucony (p=0,039). Odsetek osób przewidujących rozproszenie środków do41-100 % wszystkich przyjęć w grupie lekarzy, którzy skorzystali z funduszu, przekracza ten udział w grupie lekarzy, którzy nie skorzystali z funduszu.
Inaczej mówiąc, lekarze, którzy już pracują w swoich poczekalniach, korzystając z odrębnego budżetu, przewidują w tym roku szersze rozpowszechnienie tej praktyki niż lekarze, którzy nie zgodzili się jeszcze na przejście na niezależny budżet. Istnieje wiele interpretacji tego wyniku. Można na przykład założyć, że lekarze w każdej grupie podświadomie uważają swoje zachowanie za bardziej typowe. Może to również oznaczać, że lekarze, którzy już przyjęli samofinansowanie, mają tendencję do wyolbrzymiania zakresu tego ruchu, gdyż muszą uzasadnić swoją decyzję. Zidentyfikowane różnice mogą oznaczać także coś, co całkowicie wykracza poza zakres pytań postawionych w badaniu. Przykładowo, że działalność lekarzy pracujących na samodzielnym budżecie przyczynia się do zaostrzenia różnic w stanowiskach obu grup. Byli bardziej aktywni, gdy zgodzili się przyjąć środki; byli bardziej aktywni, gdy zadali sobie trud wypełnienia ankiety drogą pocztową; są bardziej aktywni, gdy przewidują, że inni lekarze będą bardziej aktywni w otrzymywaniu środków.
Tak czy inaczej, możemy być pewni, że wykryty poziom różnic statystycznych jest maksymalnym możliwym dla tych rzeczywistych danych. Ustaliliśmy za pomocą kryteriumλ punkt maksymalnej rozbieżności pomiędzy obydwoma rozkładami i to właśnie w tym miejscu próbki podzielono na dwie części.
Twój znak.
Na tym przykładzie zastanowimy się, jak ocenia się wiarygodność otrzymanego równania regresji. Ten sam test służy do sprawdzenia hipotezy, że współczynniki regresji są jednocześnie równe zero, a=0, b=0. Inaczej mówiąc, istotą obliczeń jest odpowiedź na pytanie: czy można je wykorzystać do dalszych analiz i prognoz?
Aby określić, czy wariancje w dwóch próbach są podobne, czy różne, użyj testu t.
Celem analizy jest więc uzyskanie pewnego oszacowania, na podstawie którego można by stwierdzić, że na pewnym poziomie α otrzymane równanie regresji jest statystycznie wiarygodne. Dla tego stosuje się współczynnik determinacji R2.
Badanie istotności modelu regresji odbywa się za pomocą testu F Fishera, którego obliczoną wartość wyznacza się jako stosunek wariancji pierwotnej serii obserwacji badanego wskaźnika do bezstronnego oszacowania wariancji ciągu resztowego dla tego modelu.
Jeżeli obliczona wartość przy k 1 =(m) i k 2 =(n-m-1) stopniach swobody jest większa od wartości tabelarycznej na danym poziomie istotności, wówczas model uznaje się za istotny.
gdzie m jest liczbą czynników w modelu.
Istotność statystyczną sparowanej regresji liniowej ocenia się za pomocą następującego algorytmu:
1. Postawiono hipotezę zerową, że równanie jako całość jest nieistotne statystycznie: H 0: R 2 = 0 na poziomie istotności α.
2. Następnie określ rzeczywistą wartość kryterium F: ![]()
![]()
gdzie m=1 dla regresji parami.
3. Wartość tabelaryczną wyznacza się z tablic rozkładu Fishera dla danego poziomu istotności, biorąc pod uwagę, że liczba stopni swobody dla całkowitej sumy kwadratów (większa wariancja) wynosi 1, a liczba stopni swobody dla reszty suma kwadratów (mniejsza wariancja) w regresji liniowej wynosi n-2 (lub za pomocą funkcji Excela FRIST(prawdopodobieństwo,1,n-2)).
Tabela F to maksymalna możliwa wartość kryterium pod wpływem czynników losowych przy danych stopniach swobody i poziomie istotności α. Poziom istotności α to prawdopodobieństwo odrzucenia prawidłowej hipotezy, pod warunkiem, że jest ona prawdziwa. Zazwyczaj przyjmuje się, że α wynosi 0,05 lub 0,01.
4. Jeśli rzeczywista wartość testu F jest mniejsza niż wartość z tabeli, wówczas mówią, że nie ma powodu do odrzucania hipotezy zerowej.
W przeciwnym wypadku hipoteza zerowa zostaje odrzucona i z prawdopodobieństwem (1-α) zostaje przyjęta hipoteza alternatywna dotycząca statystycznej istotności równania jako całości.
Tabela wartości kryterium o stopniach swobody k 1 =1 i k 2 =48, tabela F = 4
wnioski: Ponieważ rzeczywista wartość F > F tabeli, współczynnik determinacji jest istotny statystycznie ( znalezione oszacowanie równania regresji jest statystycznie wiarygodne) .
Analiza wariancji
.Wskaźniki jakości równań regresji
Przykład. W sumie na podstawie 25 przedsiębiorstw handlowych bada się związek między następującymi cechami: X - cena produktu A, tysiące rubli; Y to zysk przedsiębiorstwa handlowego, miliony rubli. Oceniając model regresji uzyskano następujące wyniki pośrednie: ∑(y i -y x) 2 = 46000; ∑(y i -y śr.) 2 = 138000. Jaki wskaźnik korelacji można wyznaczyć na podstawie tych danych? Na podstawie tego wyniku i korzystając z tego oblicz wartość tego wskaźnika Test F Fishera wyciągnąć wnioski na temat jakości modelu regresji.
Rozwiązanie. Na podstawie tych danych możemy wyznaczyć empiryczny współczynnik korelacji:  , gdzie ∑(y śr. -y x) 2 = ∑(y i -y śr.) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
, gdzie ∑(y śr. -y x) 2 = ∑(y i -y śr.) 2 - ∑(y i -y x) 2 = 138000 - 46000 = 92 000.
η 2 = 92 000/138 000 = 0,67, η = 0,816 (0,7< η < 0.9 - связь между X и Y высокая).
Test F Fishera: n = 25, m = 1.
R 2 = 1 - 46000/138000 = 0,67, F = 0,67/(1-0,67)x(25 - 1 - 1) = 46. F tabela (1; 23) = 4,27
Ponieważ rzeczywista wartość F > Ftable, znalezione oszacowanie równania regresji jest statystycznie wiarygodne.
Pytanie: Jakich statystyk używa się do testowania istotności modelu regresji?
Odpowiedź: Do oceny istotności całego modelu jako całości wykorzystuje się statystykę F (test Fishera).
Aby porównać dwie populacje o rozkładzie normalnym, które nie różnią się średnimi z próby, ale występują różnice w wariancjach, użyj Próba Fishera. Kryterium rzeczywiste oblicza się ze wzoru:
gdzie licznik jest większą wartością wariancji próbki, a mianownik jest mniejszą. Aby stwierdzić wiarygodność różnic między próbkami, użyj PODSTAWOWA ZASADA
testowanie hipotez statystycznych. Punkty krytyczne dla  znajdują się w tabeli. Hipotezę zerową odrzuca się, jeśli ma ona wartość rzeczywistą
znajdują się w tabeli. Hipotezę zerową odrzuca się, jeśli ma ona wartość rzeczywistą 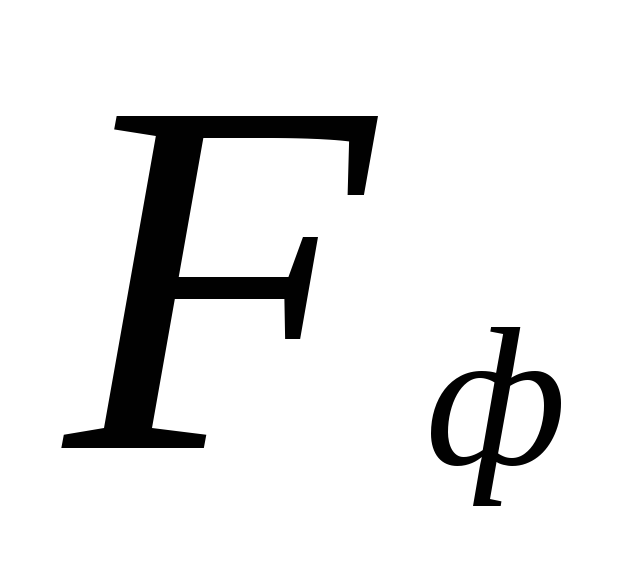 przekroczy lub będzie równa wartości krytycznej (standardowej).
przekroczy lub będzie równa wartości krytycznej (standardowej).  tę wartość dla przyjętego poziomu istotności
i liczbę stopni swobody k
1
=
N
duży
-1
;
k
2
=
N
mniejszy
-1
.
tę wartość dla przyjętego poziomu istotności
i liczbę stopni swobody k
1
=
N
duży
-1
;
k
2
=
N
mniejszy
-1
.
Przykład: badając wpływ określonego leku na szybkość kiełkowania nasion, stwierdzono, że w partii doświadczalnej nasion i kontrolnej średnia szybkość kiełkowania jest taka sama, ale występuje różnica w wariancjach.  =1250,
=1250, =417. Liczebność próbek jest taka sama i wynosi 20.
=417. Liczebność próbek jest taka sama i wynosi 20. 
 =2,12. Dlatego hipoteza zerowa zostaje odrzucona.
=2,12. Dlatego hipoteza zerowa zostaje odrzucona.
Zależność korelacyjna. Współczynnik korelacji i jego właściwości. Równania regresji.
ZADANIE analiza korelacji sprowadza się do:
Ustalenie kierunku i formy powiązania pomiędzy cechami;
Pomiar jego szczelności.
Funkcjonalny Jednoznaczną zależność między wielkościami zmiennymi nazywamy wtedy, gdy pewna wartość jednej (niezależnej) zmiennej X , zwany argumentem, odpowiada pewnej wartości innej (zależnej) zmiennej Na , zwaną funkcją. ( Przykład: zależność szybkości reakcji chemicznej od temperatury; zależność siły przyciągania od mas przyciągających się ciał i odległości między nimi).
Korelacja to relacja pomiędzy zmiennymi o charakterze statystycznym, gdy pewnej wartości jednej cechy (uważanej za zmienną niezależną) odpowiada cały szereg wartości liczbowych innej cechy. ( Przykład: związek między zbiorami a opadami deszczu; między wzrostem a wagą itp.).
Pole korelacji reprezentuje zbiór punktów, których współrzędne są równe otrzymanym eksperymentalnie parom wartości zmiennych X I Na .
Na podstawie rodzaju pola korelacyjnego można ocenić obecność lub brak połączenia oraz jego typ.




Połączenie nazywa się pozytywny , jeśli gdy wzrasta jedna zmienna, wzrasta inna zmienna.
Połączenie nazywa się negatywny , jeśli gdy jedna zmienna rośnie, inna zmienna maleje.
Połączenie nazywa się liniowy
, jeśli można to przedstawić analitycznie jako 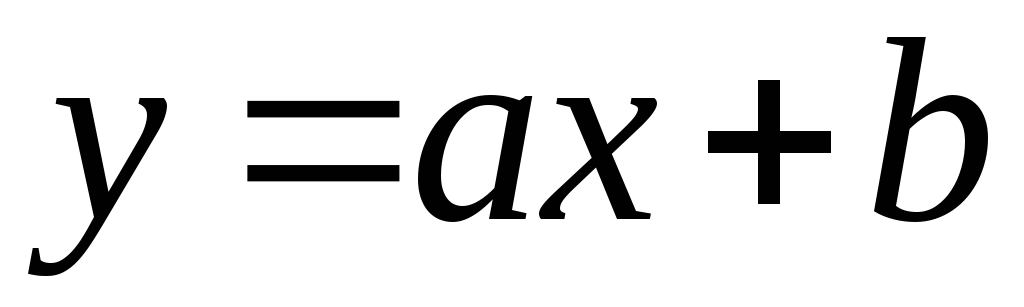 .
.
Wskaźnikiem bliskości połączenia jest Współczynnik korelacji . Empiryczny współczynnik korelacji wyraża się wzorem:

Współczynnik korelacji waha się od -1 zanim 1 i charakteryzuje stopień bliskości między wielkościami X I y . Jeśli:

Korelację między cechami można opisać na różne sposoby. W szczególności dowolną formę połączenia można wyrazić równaniem postaci ogólnej 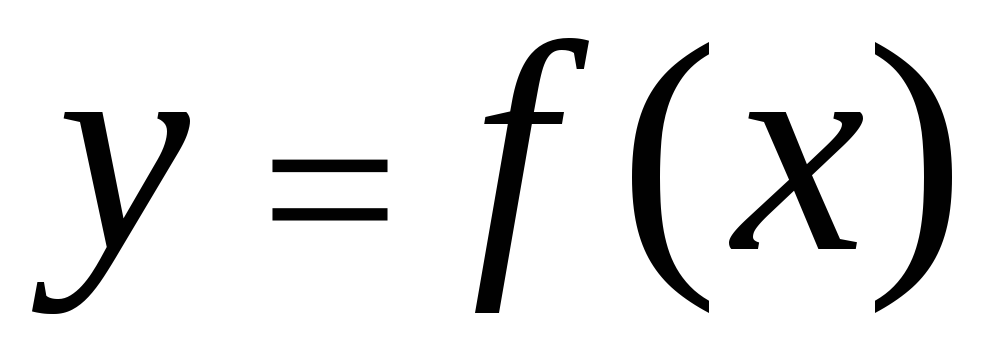 . Równanie postaci
. Równanie postaci  I
I 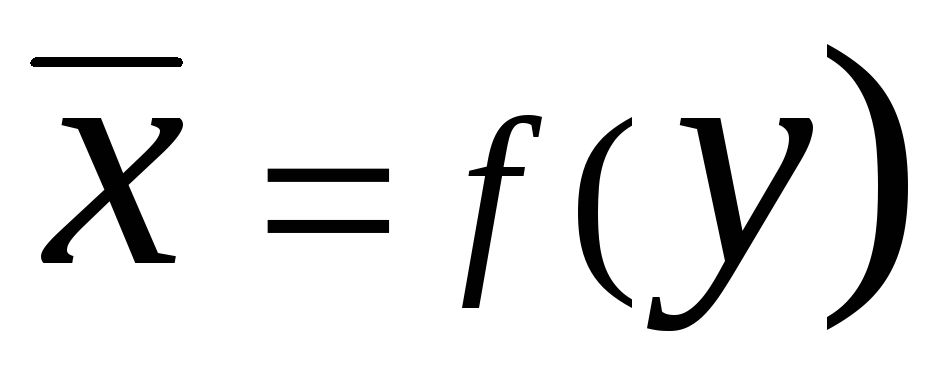 są nazywane regresja
. Równanie regresji do przodu Na
NA X
w ogólnym przypadku można zapisać w postaci
są nazywane regresja
. Równanie regresji do przodu Na
NA X
w ogólnym przypadku można zapisać w postaci

Równanie regresji do przodu X NA Na ogólnie to wygląda

Najbardziej prawdopodobne wartości współczynników A I V, Z I D można obliczyć na przykład metodą najmniejszych kwadratów.







