از اهمیت ویژه ای برای توصیف توزیع یک متغیر تصادفی، ویژگی های عددی به نام گشتاورهای اولیه و مرکزی است.
لحظه شروع ک- مرتبه α k(X) متغیر تصادفی X ک-مین توان این کمیت، یعنی.
α k(X) = م(X k) (6.8)
فرمول (6.8) با توجه به تعریف انتظارات ریاضی برای انواع مختلف متغیرهای تصادفیشکل خاص خود را دارد، یعنی برای یک متغیر تصادفی گسسته با مجموعه ای محدود از مقادیر
برای یک متغیر تصادفی پیوسته
 , (6.10)
, (6.10)
کجا f(x) - چگالی توزیع یک متغیر تصادفی X.
انتگرال نامناسبدر فرمول (6.10) تبدیل می شود انتگرال معیندر یک بازه محدود، اگر مقادیر یک متغیر تصادفی پیوسته فقط در این بازه وجود داشته باشد.
یکی از مشخصه های عددی که قبلا معرفی شد این است انتظارات ریاضی- چیزی بیش از لحظه اولیه اولین مرتبه یا به قول آنها اولین لحظه اولیه نیست:
م(X) = α 1 (X).
در پاراگراف قبل، مفهوم متغیر تصادفی متمرکز معرفی شد HM(X). اگر این کمیت به عنوان مقدار اصلی در نظر گرفته شود، می توان لحظات اولیه را نیز برای آن یافت. برای خود بزرگی Xاین لحظات مرکزی نامیده می شوند.
لحظه مرکزی ک- مرتبه μ k(X) متغیر تصادفی Xانتظار ریاضی نامیده می شود کتوان -ام متغیر تصادفی متمرکز، یعنی.
μ k(X) = م[(HM(X))ک] (6.11)
به عبارت دیگر، نقطه مرکزی کمرتبه - انتظار ریاضی است کدرجه انحراف
لحظه مرکزی کمرتبه هفتم برای یک متغیر تصادفی گسسته با مجموعه ای محدود از مقادیر با فرمول پیدا می شود:
![]() , (6.12)
, (6.12)
برای یک متغیر تصادفی پیوسته با استفاده از فرمول:
 (6.13)
(6.13)
در آینده، وقتی مشخص شد در مورد چه نوع متغیر تصادفی صحبت می کنیم، آن را در نماد لحظه های اولیه و مرکزی نمی نویسیم، یعنی. به جای α k(X) و μ k(X) ما به سادگی می نویسیم α kو μ k .
بدیهی است که لحظه مرکزی مرتبه اول برابر با صفر است، زیرا این چیزی بیش از انتظار ریاضی انحراف نیست که مطابق آنچه قبلاً ثابت شده است برابر با صفر است. .
درک اینکه لحظه مرکزی مرتبه دوم یک متغیر تصادفی دشوار نیست Xمنطبق با واریانس همان متغیر تصادفی است، یعنی.
علاوه بر این، فرمول های زیر برای اتصال لحظه های اولیه و مرکزی وجود دارد:

بنابراین لحظه های مرتبه اول و دوم (انتظار ریاضی و پراکندگی) بیشترین ویژگی را دارد. ویژگی های مهمتوزیع: موقعیت آن و درجه پراکندگی مقادیر. برای اطلاعات بیشتر توضیحات مفصلتوزیع ها لحظاتی از مرتبه های بالاتر هستند. بیایید آن را نشان دهیم.
فرض کنید که توزیع یک متغیر تصادفی با توجه به انتظارات ریاضی آن متقارن است. سپس تمام ممان های مرکزی مرتبه فرد، اگر وجود داشته باشند، برابر با صفر هستند. این با این واقعیت توضیح داده می شود که به دلیل تقارن توزیع، برای هر مقدار مثبت کمیت X − م(X) یک مقدار منفی برابر با آن وجود دارد و احتمالات این مقادیر برابر است. در نتیجه، مجموع در فرمول (6.12) از چند جفت عبارت مساوی از نظر بزرگی اما از نظر علامت متفاوت تشکیل شده است که با جمع کردن، یکدیگر را خنثی می کنند. بنابراین، کل مقدار، یعنی. لحظه مرکزی هر متغیر تصادفی گسسته مرتبه فرد صفر است. به طور مشابه، لحظه مرکزی هر مرتبه فرد از یک متغیر تصادفی پیوسته برابر با صفر است، همانطور که انتگرال در حدود متقارن یک تابع فرد برابر است.
طبیعی است که فرض کنیم اگر لحظه مرکزی یک مرتبه فرد با صفر متفاوت باشد، خود توزیع با توجه به انتظارات ریاضی آن متقارن نخواهد بود. علاوه بر این، هرچه گشتاور مرکزی با صفر تفاوت بیشتری داشته باشد، عدم تقارن در توزیع بیشتر است. اجازه دهید لحظه مرکزی کوچکترین مرتبه فرد را به عنوان مشخصه عدم تقارن در نظر بگیریم. از آنجایی که گشتاور مرکزی مرتبه اول برای متغیرهای تصادفی دارای هر توزیع صفر است، بهتر است از گشتاور مرکزی مرتبه سوم برای این منظور استفاده شود. با این حال، این لحظه دارای ابعاد یک مکعب از یک متغیر تصادفی است. برای خلاص شدن از شر این اشکال و رفتن به یک متغیر تصادفی بدون بعد، مقدار لحظه مرکزی را بر مکعب انحراف استاندارد تقسیم کنید.
ضریب عدم تقارن یک س یا فقط عدم تقارننسبت گشتاور مرکزی مرتبه سوم به مکعب انحراف معیار نامیده می شود، یعنی.
گاهی اوقات عدم تقارن را «چولگی» می نامند و تعیین می کنند S kآنچه از آن می آید کلمه انگلیسیکج - "مورب".
اگر ضریب عدم تقارن منفی باشد، مقدار آن به شدت تحت تأثیر شرایط منفی (انحرافات) قرار می گیرد و توزیع خواهد داشت. عدم تقارن چپ، و نمودار توزیع (منحنی) در سمت چپ انتظار ریاضی صاف تر است. اگر ضریب مثبت باشد، پس عدم تقارن درست، و منحنی در سمت راست انتظار ریاضی صاف تر است (شکل 6.1).
 |
همانطور که نشان داده شد، برای مشخص کردن گسترش مقادیر یک متغیر تصادفی در اطراف انتظارات ریاضی آن، از لحظه مرکزی دوم استفاده میشود، یعنی. پراکندگی اگر این لحظه از اهمیت بالایی برخوردار است مقدار عددیسپس این متغیر تصادفی دارای گستردگی زیادی از مقادیر است و منحنی توزیع مربوطه نسبت به منحنی که لحظه مرکزی دوم مقدار کمتری دارد، شکل صافتری دارد. بنابراین، دومین لحظه مرکزی، تا حدی، منحنی توزیع "روی تخت" یا "باله تیز" را مشخص می کند. با این حال، این ویژگی خیلی راحت نیست. لحظه مرکزی مرتبه دوم دارای بعد است برابر مربعابعاد یک متغیر تصادفی اگر بخواهیم با تقسیم مقدار گشتاور بر مجذور انحراف معیار یک کمیت بی بعد به دست آوریم، برای هر متغیر تصادفی به دست می آوریم: ![]() . بنابراین، این ضریب نمی تواند هیچ مشخصه ای از توزیع یک متغیر تصادفی باشد. برای همه توزیع ها یکسان است. در این حالت می توان از ممان مرکزی مرتبه چهارم استفاده کرد.
. بنابراین، این ضریب نمی تواند هیچ مشخصه ای از توزیع یک متغیر تصادفی باشد. برای همه توزیع ها یکسان است. در این حالت می توان از ممان مرکزی مرتبه چهارم استفاده کرد.
مازاد اک مقدار تعیین شده توسط فرمول است
![]() (6.15)
(6.15)
Kurtosis عمدتاً برای متغیرهای تصادفی پیوسته استفاده می شود و برای مشخص کردن به اصطلاح "تند بودن" منحنی توزیع، یا در غیر این صورت، همانطور که قبلاً ذکر شد، برای مشخص کردن منحنی توزیع "در بالای صفحه" یا "تیز بالای" استفاده می شود. منحنی توزیع مرجع به عنوان منحنی در نظر گرفته می شود توزیع نرمال(در فصل بعدی به تفصیل به این موضوع پرداخته خواهد شد). برای یک متغیر تصادفی که طبق یک قانون عادی توزیع شده است، برابری برقرار است. بنابراین، کشیدگی داده شده با فرمول (6.15) برای مقایسه این توزیع با توزیع نرمال، که برای آن کشیدگی برابر با صفر است، استفاده می شود.
اگر یک کشش مثبت برای برخی از متغیرهای تصادفی به دست آید، منحنی توزیع این مقدار بیشتر از منحنی توزیع نرمال است. اگر کشیدگی منفی باشد، آنگاه منحنی در مقایسه با منحنی توزیع نرمال دارای سطح صاف تر است (شکل 6.2).
 |
اجازه دهید اکنون به سراغ انواع خاصی از قوانین توزیع برای متغیرهای تصادفی گسسته و پیوسته برویم.
علاوه بر ویژگی های موقعیت - میانگین، مقادیر معمولی یک متغیر تصادفی - تعدادی ویژگی استفاده می شود که هر کدام یک یا ویژگی دیگری از توزیع را توصیف می کند. به اصطلاح لحظه ها اغلب به عنوان چنین ویژگی هایی استفاده می شوند.
مفهوم گشتاور به طور گسترده ای در مکانیک برای توصیف توزیع جرم ها (لمان های ایستا، ممان اینرسی و غیره) استفاده می شود. دقیقاً از همین تکنیک ها در نظریه احتمال برای توصیف ویژگی های اساسی توزیع یک متغیر تصادفی استفاده می شود. اغلب در عمل از دو نوع لحظه استفاده می شود: اولیه و مرکزی.
لحظه اولیه مرتبه هفتم یک متغیر تصادفی ناپیوسته مجموع شکل زیر است:
 . (5.7.1)
. (5.7.1)
بدیهی است که این تعریف با تعریف گشتاور اولیه مرتبه s در مکانیک منطبق است، اگر جرم ها در محور آبسیسا در نقاط متمرکز شوند.
برای متغیر تصادفی پیوسته X، لحظه اولیه مرتبه انتگرال نامیده می شود
 . (5.7.2)
. (5.7.2)
به راحتی می توان فهمید که مشخصه اصلی موقعیت معرفی شده در شماره قبلی - انتظار ریاضی - چیزی بیش از اولین لحظه اولیه متغیر تصادفی نیست.
با استفاده از علامت انتظار ریاضی، می توانید دو فرمول (5.7.1) و (5.7.2) را در یک فرمول ترکیب کنید. در واقع فرمول های (5.7.1) و (5.7.2) از نظر ساختار کاملاً شبیه فرمول های (5.6.1) و (5.6.2) هستند، با این تفاوت که به ترتیب به جای و وجود دارند و . بنابراین، میتوانیم یک تعریف کلی از لحظه اولیه مرتبه هفتم بنویسیم که برای هر دو حالت ناپیوسته و ناپیوسته معتبر است. مقادیر پیوسته:
![]() , (5.7.3)
, (5.7.3)
آن ها لحظه اولیه مرتبه هفتم یک متغیر تصادفی، انتظار ریاضی درجه دهم این متغیر تصادفی است.
قبل از تعریف لحظه مرکزی، مفهوم جدیدی از "متغیر تصادفی متمرکز" را معرفی می کنیم.
اجازه دهید یک متغیر تصادفی با انتظارات ریاضی وجود داشته باشد. یک متغیر تصادفی متمرکز مربوط به مقدار، انحراف متغیر تصادفی از انتظارات ریاضی آن است:
در آینده، ما موافقت خواهیم کرد که در همه جا متغیر تصادفی متمرکز مربوط به یک متغیر تصادفی معین را با همان حرف با یک نماد در بالا مشخص کنیم.
به راحتی می توان تأیید کرد که انتظارات ریاضی از یک متغیر تصادفی متمرکز برابر با صفر است. در واقع، برای یک مقدار ناپیوسته
به طور مشابه برای یک کمیت پیوسته.
وسط قرار دادن یک متغیر تصادفی بدیهی است که معادل انتقال مبدأ مختصات به نقطه میانی و "مرکزی" است که آبسیسا برابر با انتظار ریاضی است.
گشتاورهای یک متغیر تصادفی متمرکز را ممان مرکزی می گویند. آنها مشابه لحظات مربوط به مرکز ثقل در مکانیک هستند.
بنابراین، لحظه مرکزی مرتبه s یک متغیر تصادفی، انتظار ریاضی از توان دهم متغیر تصادفی متمرکز مربوطه است:
![]() , (5.7.6)
, (5.7.6)
و برای پیوسته - توسط انتگرال
 . (5.7.8)
. (5.7.8)
در ادامه، در مواردی که شکی نیست که یک لحظه معین متعلق به کدام متغیر تصادفی است، برای اختصار به سادگی و به جای و می نویسیم.
بدیهی است که برای هر متغیر تصادفی لحظه مرکزی مرتبه اول برابر با صفر است:
![]() , (5.7.9)
, (5.7.9)
از آنجایی که انتظار ریاضی از یک متغیر تصادفی متمرکز همیشه برابر با صفر است.
اجازه دهید روابطی را استخراج کنیم که لحظات مرکزی و اولیه نظم های مختلف را به هم متصل می کند. ما نتیجه گیری را فقط برای مقادیر ناپیوسته انجام خواهیم داد. به راحتی می توان تأیید کرد که دقیقاً همان روابط برای کمیت های پیوسته معتبر است اگر مجموع متناهی را با انتگرال ها و احتمال ها را با عناصر احتمال جایگزین کنیم.
بیایید دومین نکته مرکزی را در نظر بگیریم:

به طور مشابه برای سومین لحظه مرکزی به دست می آوریم:
عباراتی برای غیره را می توان به روشی مشابه به دست آورد.
بنابراین، برای لحظه های مرکزی هر متغیر تصادفی، فرمول ها معتبر هستند:
 (5.7.10)
(5.7.10)
به طور کلی، لحظه ها را می توان نه تنها نسبت به مبدأ (لحظه های اولیه) یا انتظار ریاضی (لحظه های مرکزی)، بلکه نسبت به یک نقطه دلخواه نیز در نظر گرفت:
![]() . (5.7.11)
. (5.7.11)
با این حال، ممان مرکزی نسبت به سایرین برتری دارد: اولین لحظه مرکزی، همانطور که دیدیم، همیشه برابر با صفر است، و لحظه بعدی، دومین لحظه مرکزی، با این سیستم مرجع دارای حداقل مقدار است. بیایید ثابت کنیم. برای یک متغیر تصادفی ناپیوسته در، فرمول (5.7.11) به شکل زیر است:
 . (5.7.12)
. (5.7.12)
بیایید این عبارت را تبدیل کنیم:
بدیهی است که این مقدار زمانی به حداقل می رسد که، i.e. زمانی که لحظه نسبت به نقطه گرفته می شود.
از بین تمام لحظات، اولین لحظه اولیه (انتظار ریاضی) و دومین لحظه مرکزی اغلب به عنوان ویژگی های یک متغیر تصادفی استفاده می شود.
دومین لحظه مرکزی واریانس متغیر تصادفی نامیده می شود. با توجه به اهمیت فوق العاده این ویژگی، در کنار سایر نکات، یک نام گذاری ویژه برای آن معرفی می کنیم:
طبق تعریف لحظه مرکزی
آن ها واریانس یک متغیر تصادفی X انتظار ریاضی مربع متغیر مرکزی مربوطه است.
با جایگزینی کمیت در عبارت (5.7.13) با عبارت آن، همچنین داریم:
![]() . (5.7.14)
. (5.7.14)
برای محاسبه مستقیم واریانس از فرمول های زیر استفاده کنید:
 , (5.7.15)
, (5.7.15)
 (5.7.16)
(5.7.16)
بر این اساس برای کمیت های ناپیوسته و پیوسته.
پراکندگی یک متغیر تصادفی مشخصه پراکندگی است، پراکندگی مقادیر یک متغیر تصادفی در اطراف انتظارات ریاضی آن. خود کلمه پراکندگی به معنای پراکندگی است.
اگر به تفسیر مکانیکی توزیع بپردازیم، آنگاه پراکندگی چیزی بیش از لحظه اینرسی توزیع جرم معین نسبت به مرکز ثقل (انتظار ریاضی) نیست.
واریانس یک متغیر تصادفی دارای ابعاد مربع متغیر تصادفی است. برای توصیف بصری پراکندگی، استفاده از کمیتی که ابعاد آن با بعد متغیر تصادفی منطبق است راحت تر است. برای این کار، جذر واریانس را بگیرید. مقدار حاصل را انحراف استاندارد (در غیر این صورت "استاندارد") متغیر تصادفی می نامند. ما انحراف استاندارد را نشان خواهیم داد:
![]() , (5.7.17)
, (5.7.17)
برای ساده کردن نمادها، اغلب از اختصارات برای انحراف استاندارد و پراکندگی استفاده می کنیم: و. در مواردی که شکی نیست که این ویژگی ها متعلق به کدام متغیر تصادفی است، گاهی اوقات نماد x y را حذف می کنیم و به سادگی و می نویسیم. گاهی اوقات کلمات "انحراف استاندارد" به اختصار با حروف r.s.o جایگزین می شوند.
در عمل، اغلب از فرمولی استفاده می شود که پراکندگی یک متغیر تصادفی را در دومین لحظه اولیه آن بیان می کند (دوم فرمول (5.7.10)). در نماد جدید به نظر می رسد:
انتظار و واریانس (یا انحراف معیار) متداولترین مشخصههای مورد استفاده یک متغیر تصادفی هستند. آنها مهمترین ویژگی های توزیع را مشخص می کنند: موقعیت و درجه پراکندگی آن. برای توصیف دقیق تر توزیع، از لحظه های سفارشات بالاتر استفاده می شود.
سومین نقطه مرکزی برای مشخص کردن عدم تقارن (یا "چولگی") توزیع است. اگر توزیع با توجه به انتظار ریاضی متقارن باشد (یا به تعبیر مکانیکی، جرم به طور متقارن نسبت به مرکز ثقل توزیع شود)، آنگاه تمام گشتاورهای مرتبه فرد (اگر وجود داشته باشند) برابر با صفر هستند. در واقع، در مجموع

وقتی قانون توزیع نسبت به قانون متقارن و فرد باشد، هر جمله مثبت با یک جمله مساوی مطابقت دارد. ارزش مطلقجمله منفی، پس مجموع کل صفر است. واضح است که همین امر در مورد انتگرال نیز صادق است
 ,
,
که برابر با صفر به عنوان انتگرال در حدود متقارن یک تابع فرد است.
بنابراین، طبیعی است که یکی از لحظات فرد را به عنوان مشخصه عدم تقارن توزیع انتخاب کنیم. ساده ترین آنها سومین لحظه مرکزی است. دارای ابعاد مکعب یک متغیر تصادفی است: برای به دست آوردن یک مشخصه بدون بعد، لحظه سوم بر مکعب انحراف استاندارد تقسیم می شود. مقدار حاصل را "ضریب عدم تقارن" یا به سادگی "عدم تقارن" می نامند. به آن اشاره خواهیم کرد:
در شکل 5.7.1 دو توزیع نامتقارن را نشان می دهد. یکی از آنها (منحنی I) دارای عدم تقارن مثبت است (); دیگری (منحنی II) منفی است ().

چهارمین نقطه مرکزی برای توصیف به اصطلاح "خنک بودن"، یعنی. توزیع اوج یا تخت این خواص توزیع با استفاده از به اصطلاح کرتوز توصیف می شود. کشش یک متغیر تصادفی کمیت است
عدد 3 از نسبت کم می شود زیرا برای قانون توزیع نرمال بسیار مهم و گسترده در طبیعت (که بعداً با جزئیات بیشتر آشنا خواهیم شد). بنابراین، برای توزیع نرمال، کشش صفر است. منحنی هایی که در مقایسه با منحنی نرمال اوج بیشتری دارند، کشش مثبت دارند. منحنی هایی که سطح صاف تر دارند، کشش منفی دارند.
در شکل 5.7.2 نشان می دهد: توزیع نرمال (منحنی I)، توزیع با کشیدگی مثبت (منحنی II) و توزیع با کشیدگی منفی (منحنی III).

علاوه بر ممانهای اولیه و مرکزی که در بالا مورد بحث قرار گرفت، در عمل گاهی اوقات از ممانهای به اصطلاح مطلق (اولیه و مرکزی) استفاده میشود که با فرمول تعیین میشوند.
بدیهی است که لحظه های مطلق دستورات زوج با لحظات معمولی منطبق است.
از بین ممان های مطلق، رایج ترین مورد استفاده اولین لحظه مرکزی مطلق است.
![]() , (5.7.21)
, (5.7.21)
انحراف میانگین حسابی نامیده می شود. همراه با پراکندگی و انحراف معیار، گاهی اوقات از میانگین حسابی انحراف به عنوان مشخصه پراکندگی استفاده می شود.
انتظار، حالت، گشتاورهای میانه، اولیه و مرکزی و به ویژه پراکندگی، انحراف معیار، چولگی و کشیدگی متداولترین مشخصههای عددی متغیرهای تصادفی هستند. در بسیاری از مشکلات عملی مشخصات کاملمتغیر تصادفی - قانون توزیع - یا مورد نیاز نیست یا نمی توان به دست آورد. در این موارد، ما به توصیف تقریبی متغیر تصادفی با استفاده از کمک محدود می شویم. مشخصه های عددی که هر کدام برخی از ویژگی های توزیع را بیان می کند.
اغلب از مشخصه های عددی برای جایگزینی تقریباً یک توزیع با توزیع دیگر استفاده می شود و معمولاً سعی می شود این جایگزینی به گونه ای انجام شود که چندین نکته مهم بدون تغییر باقی بماند.
مثال 1. یک آزمایش انجام می شود که در نتیجه آن ممکن است رویدادی ظاهر شود یا نباشد که احتمال آن برابر است. یک متغیر تصادفی در نظر گرفته می شود - تعداد وقوع یک رویداد (متغیر تصادفی مشخصه یک رویداد). ویژگی های آن را تعیین کنید: انتظار ریاضی، پراکندگی، انحراف معیار.
راه حل. سری توزیع ارزش به شکل زیر است:

جایی که احتمال رخ ندادن رویداد وجود دارد.
با استفاده از فرمول (5.6.1) انتظار ریاضی مقدار را پیدا می کنیم:
پراکندگی مقدار با فرمول (5.7.15) تعیین می شود:
(پیشنهاد ما این است که خواننده با بیان پراکندگی بر حسب لحظه اولیه دوم، همان نتیجه را به دست آورد).
مثال 2. سه شلیک مستقل به یک هدف شلیک می شود. احتمال زدن هر شلیک 0.4 است. متغیر تصادفی - تعداد بازدید. مشخصه های یک کمیت - انتظار ریاضی، پراکندگی، r.s.d.، عدم تقارن.
راه حل. سری توزیع ارزش به شکل زیر است:

ما ویژگی های عددی کمیت را محاسبه می کنیم.
لحظه شروع ک هفتم سفارش دهید متغیر تصادفیX X ک :
به طور خاص،
لحظه مرکزی ک هفتم سفارش دهید متغیر تصادفیXانتظار ریاضی از کمیت نامیده می شود ک :
 .
(5.11)
.
(5.11)
به طور خاص،
با استفاده از تعاریف و ویژگی های انتظار و پراکندگی ریاضی، می توانیم آن را به دست آوریم
 ,
,
 ,
,
لحظه های مرتبه بالاتر به ندرت استفاده می شوند.
فرض کنیم که توزیع متغیر تصادفی با توجه به انتظارات ریاضی متقارن است. سپس تمام سانترال های مرتبه فرد برابر با صفر هستند. این را می توان با این واقعیت توضیح داد که برای هر مقدار مثبت انحراف X–M[X] (به دلیل تقارن توزیع) یک مقدار منفی برابر با مقدار مطلق وجود دارد و احتمالات آنها یکسان خواهد بود. اگر ممان مرکزی از نظم فرد باشد و برابر با صفر نباشد، این نشان دهنده عدم تقارن توزیع است و هر چه گشتاور بیشتر باشد، عدم تقارن بیشتر است. بنابراین، معقولتر است که مقداری گشتاور مرکزی فرد را به عنوان مشخصه عدم تقارن توزیع در نظر بگیریم. از آنجایی که لحظه مرکزی مرتبه 1 همیشه برابر با صفر است، توصیه می شود از لحظه مرکزی مرتبه 3 برای این منظور استفاده کنید. با این حال، پذیرش این نکته برای ارزیابی عدم تقارن ناخوشایند است زیرا مقدار آن به واحدهایی بستگی دارد که متغیر تصادفی در آنها اندازه گیری می شود. برای رفع این ایراد، 3 بر 3 تقسیم می شود و در نتیجه یک مشخصه به دست می آید.
ضریب عدم تقارن الف کمیت نامیده می شود
 .
(5.12)
.
(5.12)

برنج. 5.1
اگر ضریب عدم تقارن منفی باشد، این نشان دهنده تأثیر زیادی بر مقدار 3 انحراف منفی است. در این حالت، منحنیهای توزیع در سمت چپ M[X] صافتر هستند. اگر ضریب A مثبت باشد، منحنی در سمت راست صاف تر است.همانطور که مشخص است، پراکندگی (لمان مرکزی دوم) برای مشخص کردن پراکندگی مقادیر یک متغیر تصادفی در اطراف انتظارات ریاضی است. هرچه پراکندگی بیشتر باشد، منحنی توزیع مربوطه صاف تر است. با این حال، ممان نرمال شده از مرتبه دوم 2 / 2 نمی تواند به عنوان مشخصه توزیع "مصطح" یا "باله تیز" عمل کند زیرا برای هر توزیع D[ x]/ 2 =1. در این حالت از لحظه مرکزی مرتبه 4 استفاده می شود.
مازاد E کمیت نامیده می شود
 .
(5.13)
.
(5.13)
اچ
برنج. 5.2
مثال 5.6. DSV X توسط قانون توزیع زیر ارائه می شود:
ضریب چولگی و کشیدگی را پیدا کنید.
 برنج. 5.4
برنج. 5.4




حال بیایید لحظات مرکزی را محاسبه کنیم:

بیایید انتظارات ریاضی را پیدا کنیم X 2 :
م(X 2) = 1* 0, 6 + 4* 0, 2 + 25* 0, 19+ 10000* 0, 01 = 106, 15.
ما آن را می بینیم م(X 2) خیلی بیشتر م(X). این به این دلیل است که پس از مربع معنی ممکنمقادیر X 2 مربوط به مقدار x= 100 قدر X،برابر 10000 شد، یعنی به طور قابل توجهی افزایش یافت. احتمال این مقدار کم است (0.01).
بنابراین، انتقال از م(X) به م(X 2) این امکان را فراهم می کند که تأثیر آن بر انتظارات ریاضی آن مقدار ممکن را که بزرگ است و احتمال کمی دارد، بهتر در نظر بگیریم. البته اگر ارزش Xچندین مقدار بزرگ و بعید داشت، سپس انتقال به مقدار X 2، و حتی بیشتر از آن به مقادیر X 3 , X 4 و غیره به ما این امکان را می دهد که "نقش" این مقادیر بزرگ، اما بعید ممکن را بیشتر تقویت کنیم. به همین دلیل است که توصیه می شود انتظار ریاضی یک توان مثبت عدد صحیح از یک متغیر تصادفی (نه تنها گسسته، بلکه پیوسته) را نیز در نظر بگیریم.
لحظه اولیه سفارش kمتغیر تصادفی Xانتظار ریاضی از کمیت نامیده می شود Xk:
v k = M(X).
به طور خاص،
v 1 = م(X)، v 2 = م(X 2).
با استفاده از این نقاط، فرمول محاسبه واریانس دی(X)= م(X 2)- [م(X)] 2 را می توان اینگونه نوشت:
دی(X)= v 2 – . (*)
علاوه بر ممان های متغیر تصادفی Xتوصیه می شود لحظات انحراف را در نظر بگیرید X-M(X).
لحظه مرکزی مرتبه k متغیر تصادفی X انتظار ریاضی کمیت است(HM(X))ک:
به طور خاص،
روابطی که لحظه های اولیه و مرکزی را به هم متصل می کنند به راحتی بدست می آیند. به عنوان مثال، با مقایسه (*) و (***)، به دست می آوریم
m 2 = v 2 – .
بر اساس تعریف لحظه مرکزی و با استفاده از ویژگی های انتظار ریاضی، به دست آوردن فرمول ها دشوار نیست:
m 3 = v 3 – 3v 2 v 1 + 2 ,
m 4 = v 4 – 4v 3 v 1 + 6v 2 + 3 .
لحظه های مرتبه بالاتر به ندرت استفاده می شوند.
نظر دهید. نکاتی که در اینجا مورد بحث قرار می گیرد نامیده می شوند نظریبر خلاف ممان های نظری، گشتاورهایی که از داده های مشاهده ای محاسبه می شوند نامیده می شوند تجربیتعاریف لحظات تجربی در زیر آورده شده است (به فصل XVII، § 2 مراجعه کنید).
وظایف
1. واریانس دو متغیر تصادفی مستقل شناخته شده است: دی(X) = 4، دی(Y)=3. واریانس مجموع این مقادیر را پیدا کنید.
نماینده 7.
2. واریانس یک متغیر تصادفی Xبرابر 5 است. واریانس کمیت های زیر را بیابید: الف) X-1؛ ب) -2 X; V) ZH + 6.
نمایندهالف) 5؛ ب) 20; ج) 45.
3. متغیر تصادفی Xتنها دو مقدار را می گیرد: +C و -C، هر کدام با احتمال 0.5. واریانس این کمیت را پیدا کنید.
نماینده با 2 .
4. ، دانستن قانون توزیع آن
| X | 0, 1 | |||
| پ | 0, 4 | 0, 2 | 0, 15 | 0, 25 |
نماینده 67,6404.
5. متغیر تصادفی Xمی تواند دو مقدار ممکن را بگیرد: X 1 با احتمال 0.3 و x 2 با احتمال 0.7 و X 2 > x 1 . پیدا کنید x 1 و x 2، دانستن آن م(X) = 2, 7i دی(X) =0,21.
نماینده x 1 = 2، x 2 = 3.
6. واریانس یک متغیر تصادفی را پیدا کنید X-تعداد وقوع رویدادها الفدر دو تست های مستقل، اگر م(X) = 0, 8.
توجه داشته باشید. یک قانون دو جمله ای برای توزیع احتمال تعداد وقوع یک رویداد بنویسید الفدر دو آزمایش مستقل
نماینده 0, 48.
7. دستگاهی متشکل از چهار دستگاه مستقل در حال آزمایش است. احتمال خرابی دستگاه به شرح زیر است: r 1 = 0,3; r 2 = 0,4; ص 3 = 0,5; r 4 = 0.6. انتظارات ریاضی و واریانس تعداد دستگاه های خراب را پیدا کنید.
نماینده 1,8; 0,94.
8. واریانس یک متغیر تصادفی را پیدا کنید X- تعداد وقوع رویداد در 100 آزمایش مستقل که در هر یک از آنها احتمال وقوع رویداد 0.7 است.
نماینده 21.
9. واریانس یک متغیر تصادفی دی(X) = 6.25. پیدا کردن انحراف استاندارد s( X).
نماینده 2, 5.
10. متغیر تصادفی توسط قانون توزیع مشخص می شود
| X | |||
| پ | 0, 1 | 0, 5 | 0, 4 |
انحراف معیار این مقدار را پیدا کنید.
نماینده 2, 2.
11. واریانس هر یک از 9 متغیر تصادفی مستقل متقابل با توزیع یکسان برابر با 36 است. واریانس میانگین حسابی این متغیرها را بیابید.
نماینده 4.
12. انحراف معیار هر یک از 16 متغیر تصادفی مستقل دو طرفه توزیع شده یکسان 10 است. انحراف معیار میانگین حسابی این متغیرها را بیابید.
نماینده 2,5.
فصل نهم
قانون اعداد بزرگ
اظهارات مقدماتی
همانطور که قبلاً شناخته شده است ، نمی توان از قبل با اطمینان پیش بینی کرد که یک متغیر تصادفی در نتیجه آزمایش کدام یک از مقادیر ممکن را خواهد گرفت. به خیلی ها بستگی دارد دلایل تصادفی، که نمی توان به آن توجه کرد. به نظر می رسد که از آنجایی که ما اطلاعات بسیار کمی در مورد هر متغیر تصادفی در این معنا داریم، به سختی امکان ایجاد الگوهای رفتاری و مجموع تعداد کافی از متغیرهای تصادفی وجود دارد. در واقع این درست نیست. به نظر می رسد که برای برخی نسبتا شرایط گستردهرفتار کلی تعداد زیادی از متغیرهای تصادفی تقریباً ویژگی تصادفی خود را از دست می دهد و طبیعی می شود.
برای تمرین، دانستن شرایطی که تحت آن عمل ترکیبی بسیاری از علل تصادفی منجر به نتیجه ای می شود که تقریباً مستقل از شانس است، بسیار مهم است، زیرا به فرد اجازه می دهد تا روند پدیده ها را پیش بینی کند. این شرایط در حامل قضایا نشان داده شده است نام مشترکقانون اعداد بزرگ. اینها شامل قضایای چبیشف و برنولی است (قضیه های دیگری نیز وجود دارند که در اینجا مورد بحث قرار نمی گیرند). قضیه چبیشف کلی ترین قانون اعداد بزرگ است، قضیه برنولی ساده ترین است. برای اثبات این قضایا از نابرابری چبیشف استفاده می کنیم.
نابرابری چبیشف
نابرابری چبیشف برای متغیرهای تصادفی گسسته و پیوسته معتبر است. برای سادگی، ما خود را به اثبات این نابرابری برای مقادیر گسسته محدود می کنیم.
یک متغیر تصادفی گسسته را در نظر بگیرید X،مشخص شده توسط جدول توزیع:
| X | x 1 | X 2 | … | x n |
| ص | ص 1 | پ 2 | … | p n |
بیایید وظیفه خود را تخمین بزنیم که انحراف یک متغیر تصادفی از انتظار ریاضی آن از مقدار مطلق عدد مثبت e تجاوز نکند. اگر e به اندازه کافی کوچک باشد، احتمال آن را تخمین می زنیم Xمقادیر نسبتاً نزدیک به انتظارات ریاضی خود را خواهد گرفت. پی. ال. چبیشف نابرابری را ثابت کرد که به ما امکان می دهد برآوردی را که به آن علاقه مندیم ارائه دهیم.
نابرابری چبیشف احتمال اینکه انحراف متغیر تصادفی X از انتظار ریاضی آن در مقدار مطلق کمتر از عدد مثبت باشد کمتر از 1-دی(X)/e 2 :
آر(|X -M(X)|< e ) 1-دی(X)/e 2 .
اثبات از آنجایی که رویدادهای متشکل از اجرای نابرابری ها |X-M(X)|
آر(|X -M(X)|< e )+ آر(|X -M(X)| ه)= 1.
از این رو احتمال مورد علاقه ما است
آر(|X -M(X)|< e )= 1- آر(|X -M(X)| ه). (*)
بنابراین، مشکل به محاسبه احتمال ختم می شود آر(| HM(X)| ه).
بیایید عبارت واریانس متغیر تصادفی را بنویسیم X:
دی(X)= [x 1 -م(X)] 2 ص 1 + [x 2 -م(X)] 2 ص 2 +…+ [x n -M(X)]2pn.
بدیهی است که تمامی شرایط این مبلغ غیرمنفی است.
اجازه دهید آن شرایطی را که برای آنها | x i-م(X)|<ه(برای شرایط باقیمانده | x j-م(X)| ه), در نتیجه، مقدار فقط می تواند کاهش یابد. اجازه دهید برای قطعیت فرض کنیم که کاصطلاحات اول (بدون از دست دادن کلیت، می توانیم فرض کنیم که در جدول توزیع مقادیر ممکن دقیقاً به این ترتیب شماره گذاری شده اند). بنابراین،
دی(X) [x k + 1 -م(X)] 2 p k + 1 + [x k + 2 -م(X)] 2 p k + z + ... +[x n -M(X)] 2 pn.
توجه داشته باشید که هر دو طرف نابرابری | x j - م(X)| ه (j = ک+1, ک+ 2, ..., n) مثبت هستند، بنابراین، با مجذور کردن آنها، نابرابری معادل | x j - م(X)| 2 e 2اجازه دهید از این نکته استفاده کنیم و هر یک از عوامل را در مجموع باقی مانده جایگزین کنیم | x j - م(X)| 2 در تعداد e 2(در این مورد نابرابری فقط می تواند افزایش یابد)، دریافت می کنیم
دی(X) e 2 (r k+ 1 + p k + 2 + … + р n). (**)
با توجه به قضیه جمع، مجموع احتمالات r k+ 1 + p k + 2 + … + р nاین احتمال وجود دارد که Xبدون توجه به کدام ارزش، یکی را خواهد گرفت x k + 1 ، x k+ 2 ,....x pو برای هر یک از آنها انحراف نابرابری را برآورده می کند | x j - م(X)| هنتیجه می شود که مقدار r k+ 1 + p k + 2 + … + р nاحتمال را بیان می کند
پ(|X - م(X)| ه)
این ملاحظات به ما امکان می دهد نابرابری (**) را به صورت زیر بازنویسی کنیم:
دی(X) e 2 P(|X - م(X)| ه),
پ(|X - م(X)| ه)دی(X) /ه 2 (***)
با جایگزینی (***) به (*)، در نهایت دریافت می کنیم
پ(|X - م(X)| <ه) 1-دی(X) /ه 2 ,
Q.E.D.
نظر دهید. نابرابری چبیشف اهمیت عملی محدودی دارد زیرا اغلب تخمینی خشن و گاهی پیش پا افتاده (بدون علاقه) ارائه می دهد. به عنوان مثال، اگر دی(X)> e 2 و بنابراین دی(X)/e 2 > 1 سپس 1 -دی(X)/e 2 < 0; بنابراین، در این مورد، نابرابری چبیشف فقط نشان می دهد که احتمال انحراف غیر منفی است، و این از قبل آشکار است، زیرا هر احتمالی با یک عدد غیر منفی بیان می شود.
اهمیت نظری نابرابری چبیشف بسیار زیاد است. در زیر از این نابرابری برای استخراج قضیه چبیشف استفاده خواهیم کرد.
قضیه چبیشف
قضیه چبیشف. اگر X 1 ، X 2 ,…, X n, ...-متغیرهای تصادفی مستقل دو به دو و واریانس آنها به طور یکنواخت محدود می شود(از عدد ثابت C تجاوز نکنید)، پس هر چقدر هم که عدد مثبت e کوچک باشد، احتمال نابرابری وجود دارد
به عبارت دیگر، تحت شرایط قضیه
بنابراین، قضیه چبیشف بیان میکند که اگر تعداد کافی زیادی از متغیرهای تصادفی مستقل با واریانسهای محدود در نظر گرفته شود، آنگاه میتوان رویداد را تقریباً قابل اعتماد در نظر گرفت، که شامل این واقعیت است که انحراف میانگین حسابی متغیرهای تصادفی از میانگین حسابی آنها. انتظارات ریاضی به طور دلخواه بزرگ در مقدار مطلق کوچک خواهد بود
اثبات اجازه دهید یک متغیر تصادفی جدید را در نظر بگیریم - میانگین حسابی متغیرهای تصادفی
=(X 1 +X 2 +…+X n)/n.
بیایید انتظارات ریاضی را پیدا کنیم . با استفاده از ویژگی های انتظار ریاضی (عامل ثابت را می توان از علامت انتظار ریاضی خارج کرد، انتظار ریاضی حاصل از جمع برابر با مجموع انتظارات ریاضی عبارت ها است) به دست می آوریم.
م ![]() =
=
![]() . (*)
. (*)
با اعمال نابرابری چبیشف بر کمیت، داریم
با جایگزینی سمت راست (***) به نابرابری (**) (به همین دلیل است که دومی فقط می تواند تقویت شود)، ما داریم
از اینجا، با عبور از حد در، به دست می آوریم
در نهایت، با در نظر گرفتن این که احتمال نمی تواند از یک بیشتر شود، در نهایت می توانیم بنویسیم
قضیه ثابت شده است.
در بالا، هنگام فرمول بندی قضیه چبیشف، فرض کردیم که متغیرهای تصادفی انتظارات ریاضی متفاوتی دارند. در عمل، اغلب اتفاق می افتد که متغیرهای تصادفی انتظارات ریاضی یکسانی دارند. بدیهی است که اگر مجدداً فرض کنیم که پراکندگی این مقادیر محدود است، قضیه چبیشف برای آنها قابل اجرا خواهد بود.
اجازه دهید انتظارات ریاضی هر یک از متغیرهای تصادفی را با علامت گذاری کنیم الفدر مورد مورد بررسی، میانگین حسابی انتظارات ریاضی، همانطور که به راحتی قابل مشاهده است، نیز برابر است با الفما می توانیم قضیه چبیشف را برای مورد خاص مورد بررسی فرمول بندی کنیم.
اگر X 1 ، X 2 , ..., اسب بخار ...-متغیرهای تصادفی مستقل دوتایی که انتظارات ریاضی a یکسانی دارند و اگر واریانس این متغیرها به طور یکنواخت محدود باشد، هر چقدر هم که عدد e کوچک باشد.> اوه، احتمال نابرابری
![]()
اگر تعداد متغیرهای تصادفی به اندازه کافی زیاد باشد، به اندازه دلخواه به وحدت نزدیک خواهد شد.
به عبارت دیگر، در شرایط قضیه برابری وجود خواهد داشت

جوهر قضیه چبیشف
ماهیت قضیه اثبات شده به شرح زیر است: اگرچه متغیرهای تصادفی مستقل منفرد می توانند مقادیری دور از انتظارات ریاضی خود بگیرند، میانگین حسابی تعداد بسیار زیادی از متغیرهای تصادفی با احتمال بالا مقادیری نزدیک به یک ثابت معین را می گیرد. شماره، یعنی شماره ( م(X 1)+ م(X 2)+... + م(X p))/n(یا به شماره الفدر یک مورد خاص). به عبارت دیگر، متغیرهای تصادفی منفرد ممکن است پراکندگی قابل توجهی داشته باشند و میانگین حسابی آنها به طور پراکنده کوچک باشد.
بنابراین، نمی توان با اطمینان پیش بینی کرد که هر یک از متغیرهای تصادفی چه مقدار ممکنی خواهد گرفت، اما می توان پیش بینی کرد که میانگین حسابی آنها چه مقداری خواهد داشت.
بنابراین، میانگین حسابی تعداد کافی از متغیرهای تصادفی مستقل(که واریانس ها به طور یکنواخت محدود می شوند) شخصیت یک متغیر تصادفی را از دست می دهد.این با این واقعیت توضیح داده می شود که انحرافات هر یک از کمیت ها از انتظارات ریاضی آنها می تواند مثبت و منفی باشد و در میانگین حسابی آنها یکدیگر را خنثی می کنند.
قضیه چبیشف نه تنها برای متغیرهای تصادفی گسسته، بلکه برای متغیرهای تصادفی پیوسته نیز معتبر است. او است یک نمونه درخشان، تأیید صحت آموزه ماتریالیسم دیالکتیکی در مورد ارتباط بین شانس و ضرورت.
انتظارات ریاضی انتظارات ریاضیمتغیر تصادفی گسسته X، گرفتن تعداد محدودی از مقادیر Xمنبا احتمالات rمن، مبلغ نامیده می شود:
انتظارات ریاضیمتغیر تصادفی پیوسته Xانتگرال حاصل ضرب مقادیر آن نامیده می شود Xبر روی چگالی توزیع احتمال f(x):
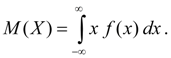 (6ب)
(6ب)
انتگرال نامناسب (6 ب) کاملاً همگرا فرض می شود (در غیر این صورت آنها می گویند که انتظار ریاضی م(X) وجود ندارد). انتظارات ریاضی مشخص می کند مقدار متوسطمتغیر تصادفی X. بعد آن با بعد متغیر تصادفی منطبق است.
ویژگی های انتظارات ریاضی:
پراکندگی. واریانسمتغیر تصادفی Xشماره نامیده می شود:
واریانس است مشخصه پراکندگیمقادیر متغیر تصادفی Xنسبت به مقدار متوسط آن م(X). بعد واریانس برابر با بعد متغیر تصادفی مربع است. بر اساس تعاریف واریانس (8) و انتظارات ریاضی (5) برای یک متغیر تصادفی گسسته و (6) برای یک متغیر تصادفی پیوسته، عبارات مشابهی را برای واریانس به دست میآوریم:
 (9)
(9)
اینجا متر = م(X).
خواص پراکندگی:
انحراف معیار:
![]() (11)
(11)
از آنجایی که بعد میانگین انحراف مربعهمانند متغیرهای تصادفی، بیشتر به عنوان معیار پراکندگی استفاده می شود تا واریانس.
لحظه های توزیع مفاهیم انتظار و پراکندگی ریاضی موارد خاص بیشتری هستند مفهوم کلیبرای ویژگی های عددی متغیرهای تصادفی - لحظات توزیع. لحظه های توزیع یک متغیر تصادفی به عنوان انتظارات ریاضی برخی از توابع ساده یک متغیر تصادفی معرفی می شوند. پس لحظه سفارش کنسبت به نقطه X 0 انتظار ریاضی نامیده می شود م(X–X 0 )ک. لحظاتی در مورد مبدا X= 0 فراخوانی می شود لحظات اولیهو مشخص شده اند:
![]() (12)
(12)
لحظه اولیه مرتبه اول مرکز توزیع متغیر تصادفی مورد بررسی است:
![]() (13)
(13)
لحظاتی در مورد مرکز توزیع X= مترنامیده می شوند نقاط مرکزیو مشخص شده اند:
![]() (14)
(14)
از (7) چنین می شود که گشتاور مرکزی مرتبه اول همیشه برابر با صفر است:
گشتاورهای مرکزی به مبدأ مقادیر متغیر تصادفی بستگی ندارند، زیرا زمانی که توسط یک مقدار ثابت جابجا می شوند. بامرکز توزیع آن با همان مقدار تغییر می کند با، و انحراف از مرکز تغییر نمی کند: X – متر = (X – با) – (متر – با).
حالا واضح است که پراکندگی- این لحظه مرکزی مرتبه دوم:
عدم تقارن. لحظه مرکزی مرتبه سوم:
![]() (17)
(17)
برای ارزیابی خدمت می کند عدم تقارن توزیع. اگر توزیع نسبت به نقطه متقارن باشد X= متر، آنگاه گشتاور مرکزی مرتبه سوم برابر با صفر خواهد بود (مانند تمام ممان مرکزی مرتبه های فرد). بنابراین، اگر ممان مرکزی مرتبه سوم با صفر متفاوت باشد، توزیع نمی تواند متقارن باشد. مقدار عدم تقارن با استفاده از یک بی بعد ارزیابی می شود ضریب عدم تقارن:
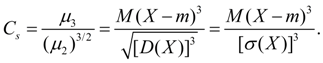 (18)
(18)
علامت ضریب عدم تقارن (18) نشان دهنده عدم تقارن سمت راست یا چپ است (شکل 2).

برنج. 2. انواع عدم تقارن توزیع.
مازاد. لحظه مرکزی مرتبه چهارم:
![]() (19)
(19)
در خدمت ارزیابی به اصطلاح بیش از حد، که درجه شیب (اوج) منحنی توزیع نزدیک به مرکز توزیع را نسبت به منحنی توزیع نرمال تعیین می کند. از آنجایی که برای توزیع نرمال، مقدار در نظر گرفته شده به عنوان کشش برابر است با:
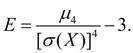 (20)
(20)
در شکل شکل 3 نمونه هایی از منحنی های توزیع را با مقادیر کشیدگی مختلف نشان می دهد. برای توزیع نرمال E= 0. منحنی هایی که بیشتر از حد معمول قله هستند دارای کشیدگی مثبت هستند، آنهایی که سطح صاف تر هستند دارای کشیدگی منفی هستند.

برنج. 3. منحنی های توزیع با درجات مختلفخنکی (زیاد).
لحظات درجه بالاتر در کاربردهای مهندسی آمار ریاضیمعمولا استفاده نمی شود
مد
گسستهیک متغیر تصادفی محتمل ترین مقدار آن است. مد مستمریک متغیر تصادفی مقدار آن است که در آن چگالی احتمال حداکثر است (شکل 2). اگر منحنی توزیع یک حداکثر داشته باشد، توزیع فراخوانی می شود تک وجهی. اگر منحنی توزیع بیش از یک حداکثر داشته باشد، توزیع فراخوانی می شود چند وجهی. گاهی اوقات توزیعهایی وجود دارند که منحنیهای آنها دارای حداقل هستند تا حداکثر. چنین توزیع هایی نامیده می شوند ضد مدال. در مورد کلیحالت و انتظارات ریاضی یک متغیر تصادفی با هم مطابقت ندارند. در مورد خاص، برای معین، یعنی داشتن یک حالت، توزیع متقارن و به شرطی که انتظار ریاضی وجود داشته باشد، دومی با حالت و مرکز تقارن توزیع منطبق است.
میانه متغیر تصادفی X- معنی آن این است مه، که برای آن برابری برقرار است: i.e. به همان اندازه احتمال دارد که متغیر تصادفی باشد Xکمتر یا بیشتر خواهد بود مه. از نظر هندسی میانهآبسیسا نقطه ای است که در آن ناحیه زیر منحنی توزیع به نصف تقسیم می شود (شکل 2). در مورد توزیع مودال متقارن، میانه، حالت و انتظار ریاضی یکسان است.







