metoda najbardziej stromy zjazd(w literaturze angielskiej „method of stromeest descent”) to iteracyjna metoda numeryczna (pierwszego rzędu) rozwiązywania problemów optymalizacyjnych, która pozwala wyznaczyć ekstremum (minimum lub maksimum) funkcji celu:
![]() są wartościami argumentu funkcji (parametrów kontrolowanych) w domenie rzeczywistej.
są wartościami argumentu funkcji (parametrów kontrolowanych) w domenie rzeczywistej.
Zgodnie z rozważaną metodą ekstremum (maksimum lub minimum) funkcji celu wyznacza się w kierunku najszybszego wzrostu (spadku) funkcji, tj. w kierunku gradientu (antygradientu) funkcji. Funkcja gradientu w punkcie ![]() jest wektorem, którego rzuty na osie współrzędnych są pochodnymi cząstkowymi funkcji po współrzędnych:
jest wektorem, którego rzuty na osie współrzędnych są pochodnymi cząstkowymi funkcji po współrzędnych:
gdzie i, j,…, n są wektorami jednostkowymi równoległymi do osi współrzędnych.
Gradient w punkcie bazowym ![]() jest ściśle prostopadły do powierzchni, a jego kierunek wskazuje kierunek najszybszego wzrostu funkcji, a kierunek przeciwny (antygradient) odpowiednio wskazuje kierunek najszybszego spadku funkcji.
jest ściśle prostopadły do powierzchni, a jego kierunek wskazuje kierunek najszybszego wzrostu funkcji, a kierunek przeciwny (antygradient) odpowiednio wskazuje kierunek najszybszego spadku funkcji.
Najbardziej stroma metoda zjazdu to dalszy rozwój Metoda gradientowego opadania. W przypadek ogólny Proces znajdowania ekstremum funkcji jest procedurą iteracyjną, którą można zapisać w następujący sposób:

gdzie znak „+” służy do znalezienia maksimum funkcji, a znak „-” służy do znalezienia minimum funkcji;
Jednostkowy wektor kierunku, który jest określony wzorem:

![]() - moduł gradientu określa szybkość wzrostu lub spadku funkcji w kierunku gradientu lub antygradientu:
- moduł gradientu określa szybkość wzrostu lub spadku funkcji w kierunku gradientu lub antygradientu:

Stała określająca wielkość kroku, taka sama dla wszystkich i-tych kierunków.
Wielkość kroku dobierana jest z warunku minimum funkcji celu f(x) w kierunku ruchu, czyli w wyniku rozwiązania jednowymiarowego problemu optymalizacji w kierunku gradientu lub antygradientu:
Innymi słowy, wielkość kroku określa się rozwiązując równanie:
![]()
Zatem etap obliczeń wybiera się tak, aby ruch był wykonywany do momentu poprawy funkcji, osiągając w ten sposób w pewnym momencie ekstremum. W tym miejscu ponownie wyznacza się kierunek poszukiwań (za pomocą gradientu) i poszukuje się nowego optymalnego punktu funkcji celu itp. Zatem w tej metodzie poszukiwanie odbywa się w większych krokach, a gradient funkcji obliczany jest w mniejszej liczbie punktów.
W przypadku funkcji dwóch zmiennych Ta metoda ma następującą interpretację geometryczną: kierunek ruchu od punktu dotyka linii poziomu w punkcie . Trajektoria opadania jest zygzakowata, a sąsiednie zygzaki są prostopadłe do siebie. Warunek ortogonalności wektorów kierunków zniżania w sąsiadujących punktach zapisuje się wzorem:
![]()

Trajektoria ruchu do punktu ekstremum metodą najbardziej stromego zniżania przedstawiona na wykresie linii równego poziomu funkcji f(x)
Poszukiwanie optymalnego rozwiązania kończy się na etapie obliczeń iteracyjnych (kilka kryteriów):
Trajektoria wyszukiwania pozostaje w niewielkim sąsiedztwie bieżącego punktu wyszukiwania:
Przyrost funkcji celu nie zmienia się:
![]()
Gradient funkcji celu w lokalnym punkcie minimalnym staje się zerowy:
Należy zauważyć, że metoda gradientowego opadania okazuje się bardzo powolna podczas poruszania się po wąwozie, a wraz ze wzrostem liczby zmiennych w funkcji celu takie zachowanie metody staje się typowe. Wąwóz jest zagłębieniem, którego linie poziomów mają w przybliżeniu kształt elips o wielokrotnie różniących się półosiach. W obecności wąwozu trajektoria zniżania przybiera formę zygzakowatej linii z małym krokiem, w wyniku czego uzyskana prędkość zniżania do minimum jest znacznie spowolniona. Wyjaśnia to fakt, że kierunek antygradientu tych funkcji znacznie odbiega od kierunku do punktu minimalnego, co prowadzi do dodatkowego opóźnienia w obliczeniach. W rezultacie algorytm traci wydajność obliczeniową.

Funkcja wpustu
Metoda gradientowa wraz z wieloma jej modyfikacjami jest szeroko rozpowszechniona i skuteczna metoda poszukiwanie optymalnego dla badanych obiektów. Wadą poszukiwania gradientowego (jak również metod omówionych powyżej) jest to, że podczas jego stosowania można wykryć jedynie lokalne ekstremum funkcji. Aby znaleźć innych lokalne ekstrema konieczne jest wyszukiwanie od innych punktów wyjścia. Szybkość zbieżności metod gradientowych również w istotny sposób zależy od dokładności obliczeń gradientowych. Utrata dokładności, która zwykle występuje w pobliżu punktów minimalnych lub w sytuacji wąwozu, może ogólnie zakłócić zbieżność procesu opadania gradientu.
Metoda obliczeniowa
Krok 1: Definicja wyrażeń analitycznych (w formie symbolicznej) do obliczania gradientu funkcji

Krok 2: Ustaw przybliżenie początkowe
Krok 3: Stwierdzono konieczność ponownego uruchomienia procedury algorytmicznej w celu zresetowania ostatniego kierunku wyszukiwania. W wyniku ponownego uruchomienia wyszukiwanie jest przeprowadzane ponownie w kierunku najszybszego zjazdu.
Można też wyszukiwać nie najlepszy punkt w kierunku gradientu, ale taki, który jest lepszy od aktualnego.
Najłatwiejsza do wdrożenia ze wszystkich metod optymalizacji lokalnej. Ma całkiem słabe warunki zbieżność, ale tempo zbieżności jest dość niskie (liniowe). Krok metoda gradientowa często używany jako część innych metod optymalizacji, takich jak metoda Fletchera – Reevesa.
Opis [ | ]
Ulepszenia[ | ]
Metoda gradientowego opadania okazuje się bardzo powolna podczas poruszania się po wąwozie, a wraz ze wzrostem liczby zmiennych w funkcji celu takie zachowanie metody staje się typowe. Aby zwalczyć to zjawisko, stosuje się, którego istota jest bardzo prosta. Po wykonaniu dwóch stopni gradientowego zejścia i uzyskaniu trzech punktów należy wykonać trzeci krok w kierunku wektora łączącego pierwszy i trzeci punkt, wzdłuż dna wąwozu.
W przypadku funkcji bliskich kwadratowi skuteczna jest metoda gradientu sprzężonego.
Zastosowanie w sztucznych sieciach neuronowych[ | ]
Metoda gradientowego spadku, z pewnymi modyfikacjami, jest szeroko stosowana w treningu perceptronów i jest znana w teorii sztucznych sieci neuronowych jako metoda propagacji wstecznej. Ucząc sieć neuronową typu perceptron, należy zmienić współczynniki ważące sieci tak, aby zminimalizować średni błąd na wyjściu sieci neuronowej w momencie podania na wejście sekwencji uczących danych wejściowych. Formalnie, aby wykonać tylko jeden krok metodą gradientowego opadania (dokonać tylko jednej zmiany parametrów sieci), należy sekwencyjnie podać na wejście sieci absolutnie cały zestaw danych uczących, obliczyć błąd dla każdego obiektu dane treningowe i oblicz niezbędną korektę współczynników sieci (ale nie rób tej korekty), a po przesłaniu wszystkich danych oblicz kwotę korekty każdego współczynnika sieci (suma gradientów) i popraw współczynniki „o jeden krok” . Oczywiście przy dużym zbiorze danych uczących algorytm będzie działał wyjątkowo wolno, dlatego w praktyce często współczynniki sieci dopasowuje się po każdym elemencie uczącym, gdzie wartość gradientu jest aproksymowana przez gradient funkcji kosztu, obliczony tylko na jednym treningu element. Ta metoda nazywa się stochastyczne zejście gradientowe Lub operacyjne zejście gradientowe . Stochastyczne zejście gradientowe jest formą przybliżenia stochastycznego. Teoria przybliżeń stochastycznych zapewnia warunki zbieżności metody stochastycznego gradientu.
Spinki do mankietów [ | ]
- J. Mathewsa. Moduł do metody najbardziej stromego zjazdu lub gradientu. (niedostępny link)
Literatura [ | ]
- Akulich I.L. Programowanie matematyczne na przykładach i problemach. - M.: Szkoła wyższa, 1986. - s. 298-310.
- Gill F., Murray W., Wright M. Praktyczna optymalizacja = praktyczna optymalizacja. - M.: Mir, 1985.
- Korszunow M., Korszunow M. Matematyczne podstawy cybernetyki. - M.: Energoatomizdat, 1972.
- Maksimov Yu. A., Fillipovskaya E. A. Algorytmy rozwiązywania problemów programowania nieliniowego. - M.: MEPhI, 1982.
- Maksimov Yu. Algorytmy programowania liniowego i dyskretnego. - M.: MEPhI, 1980.
- Korn G., Korn T. Podręcznik matematyki dla naukowców i inżynierów. - M.: Nauka, 1970. - s. 575-576.
- S. Yu. Gorodetsky, V. A. Grishagin. Programowanie nieliniowe i optymalizacja wieloekstremalna. - Niżny Nowogród: Wydawnictwo Uniwersytetu w Niżnym Nowogrodzie, 2007. - s. 357-363.
Zasady wprowadzania funkcji
W najbardziej stroma metoda zjazdu jako kierunek poszukiwań wybierany jest wektor, którego kierunek jest przeciwny do kierunku wektora gradientu funkcji ▽f(x). Z Analiza matematyczna wiadomo, że wektor grad f(x)=▽f(x) charakteryzuje kierunek najszybszego wzrostu funkcji (patrz gradient funkcji). Dlatego nazywa się wektor - grad f (X) = -▽f(X). antygradientowy i jest kierunkiem jego najszybszego spadku. Relacja rekurencyjna, z jaką realizowana jest metoda najbardziej stromego opadania, ma postać X k +1 =X k - λ k ▽f(x k), k = 0,1,...,
gdzie λ k > 0 jest wielkością kroku. W zależności od wyboru wielkości kroku, możesz uzyskać różne opcje metoda gradientowa. Jeżeli w procesie optymalizacji wielkość kroku λ jest stała, to metodę nazywa się metodą gradientową ze krokiem dyskretnym. Proces optymalizacji w pierwszych iteracjach można znacznie przyspieszyć, jeśli z warunku λ k =min f(X k + λS k) wybierze się λ k.
Do wyznaczenia λ k wykorzystuje się dowolną metodę optymalizacji jednowymiarowej. W tym przypadku metodę nazywa się metodą najbardziej stromego zjazdu. Z reguły w ogólnym przypadku jeden krok nie wystarczy do osiągnięcia minimum funkcji, proces powtarza się do czasu, aż kolejne obliczenia pozwolą na poprawę wyniku.
Jeśli przestrzeń jest w niektórych zmiennych bardzo wydłużona, powstaje „wąwóz”. Poszukiwania mogą zwolnić i prowadzić zygzakiem po dnie „wąwozu”. Czasami rozwiązania nie można uzyskać w akceptowalnym terminie.
Kolejną wadą tej metody może być kryterium zatrzymania ||▽f(X k)||<ε k , так как этому условию удовлетворяет и седловая точка, а не только оптимум.
Przykład. Zaczynając od punktu x k =(-2, 3), wyznacz punkt x k +1 metodą najbardziej stromego opadania, aby zminimalizować funkcję.
Jako kierunek wyszukiwania wybierz wektor gradientu w bieżącym punkcie 
Sprawdźmy kryterium zatrzymania. Mamy ![]()
Obliczmy wartość funkcji w punkcie początkowym f(X 1) = 35. Zróbmy to
krok w kierunku antygradientowym
Obliczmy wartość funkcji w nowym punkcie
f(X 2) = 3(-2 + 19λ 1) 2 + (3-8λ 1) 2 - (-2 + 19λ 1)(3-8λ 1) - 4(-2 + 19λ 1)
Znajdźmy krok taki, że funkcja celu osiągnie minimum w tym kierunku. Z warunku koniecznego istnienia ekstremum funkcji
f’(X 2) = 6(-2 + 19λ 1) 19 + 2(3-8λ 1)(-8) – (73 - 304 λ 1) – 4*19
lub f’(X 2) = 2598 λ 1 – 425 = 0.
Otrzymujemy krok λ 1 = 0,164
Ukończenie tego kroku doprowadzi do celu ![]()
w którym wartość gradientu ![]() , wartość funkcji f(X 2) = 0,23. Dokładność nie jest osiągana od momentu, gdy robimy krok w kierunku antygradientu.
, wartość funkcji f(X 2) = 0,23. Dokładność nie jest osiągana od momentu, gdy robimy krok w kierunku antygradientu.
f(X 2) = 3(1,116 – 1,008λ 1) 2 + (1,688-2,26λ 1) 2 - (1,116 – 1,008λ 1)(1,688-2,26λ 1) - 4(1,116 – 1,008λ 1)
f’(X 2) = 11,76 – 6,12λ 1 = 0
Otrzymujemy λ 1 = 0,52 ![]()
Adnotacja: Wykład szeroko omawia takie wieloparametrowe metody optymalizacji, jak metoda najbardziej stromego zniżania oraz metoda Davidona–Fletchera–Powella. Dodatkowo przeprowadza się analizę porównawczą powyższych metod w celu określenia najbardziej skutecznej, identyfikuje się ich zalety i wady; a także uwzględnia wielowymiarowe problemy optymalizacji, takie jak metoda wąwozu i metoda wieloekstremalna.
1. Metoda najbardziej stromego zejścia
Istotą tej metody jest wykorzystanie wspomnianego wcześniej metoda zniżania współrzędnych przeszukiwanie odbywa się od zadanego punktu w kierunku równoległym do jednej z osi do punktu minimalnego w tym kierunku. Następnie następuje wyszukiwanie w kierunku równoległym do drugiej osi i tak dalej. Kierunki są oczywiście stałe. Zasadną wydaje się próba modyfikacji tej metody, tak aby na każdym etapie poszukiwanie punktu minimalnego odbywało się wzdłuż „najlepszego” kierunku. Nie jest jasne, który kierunek jest „najlepszy”, ale wiadomo kierunek gradientu jest kierunkiem najszybszego wzrostu funkcji. Zatem kierunek przeciwny jest kierunkiem najszybszego spadku funkcji. Właściwość tę można uzasadnić w następujący sposób.
Załóżmy, że przechodzimy od punktu x do następnego punktu x + hd, gdzie d jest pewnym kierunkiem, a h jest krokiem o określonej długości. W konsekwencji ruch odbywa się od punktu (x 1, x 2, ..., x n) do punktu (x 1 + zx 1, x 2 + zx 2, ..., x n + zx n), Gdzie
O zmianie wartości funkcji decydują relacje
| (1.3) |
Do pierwszego rzędu zx i z obliczaniem pochodnych cząstkowych w punkcie x . Jak wybrać kierunki d i spełniające równanie (1.2), aby otrzymać największą wartość zmiany funkcji df? W tym miejscu pojawia się problem maksymalizacji z ograniczeniem. Zastosujmy metodę mnożników Lagrange'a, za pomocą której wyznaczamy funkcję
Wartość df spełniająca ograniczenie (1.2) osiąga maksimum, gdy funkcja
Osiąga maksimum. Jego pochodna
Stąd,
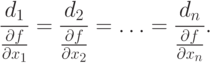 |
(1.6) |
Wtedy di ~ df/dx i i kierunek d jest równoległy do kierunku V/(x) w punkcie x.
Zatem, największy lokalny wzrost funkcja dla danego małego kroku h występuje, gdy d jest kierunkiem Vf(x) lub g(x). Dlatego kierunkiem jest kierunek najbardziej stromego zejścia
W prostszej formie równanie (1.3) można zapisać w następujący sposób:
Gdzie jest kąt pomiędzy wektorami Vf(x) i dx. Dla danej wartości dx minimalizujemy df wybierając, że kierunek dx pokrywa się z kierunkiem -Vf(x).
Komentarz. Kierunek gradientu prostopadle do dowolnego punktu linii o stałym poziomie, ponieważ wzdłuż tej linii funkcja jest stała. Zatem, jeśli (d 1, d 2, ..., d n) jest małym krokiem wzdłuż linii poziomu, to
I dlatego
 |
(1.8) |







