Można też wyszukiwać nie najlepszy punkt w kierunku gradientu, ale taki, który jest lepszy od aktualnego.
Najłatwiejsza do wdrożenia ze wszystkich metod optymalizacji lokalnej. Ma całkiem słabe warunki zbieżność, ale tempo zbieżności jest dość niskie (liniowe). Etap metody gradientowej jest często stosowany jako część innych metod optymalizacji, takich jak metoda Fletchera – Reevesa.
Opis [ | ]
Ulepszenia[ | ]
Metoda gradientowego opadania okazuje się bardzo powolna podczas poruszania się po wąwozie i wraz ze wzrostem liczby zmiennych funkcja celu to zachowanie metody staje się typowe. Aby zwalczyć to zjawisko, stosuje się go, którego istota jest bardzo prosta. Po wykonaniu dwóch stopni gradientowego zejścia i uzyskaniu trzech punktów należy wykonać trzeci krok w kierunku wektora łączącego pierwszy i trzeci punkt, wzdłuż dna wąwozu.
W przypadku funkcji bliskich kwadratowi skuteczna jest metoda gradientu sprzężonego.
Zastosowanie w sztucznych sieciach neuronowych[ | ]
Metoda gradientowego spadku, z pewnymi modyfikacjami, jest szeroko stosowana w treningu perceptronów i jest znana w teorii sztucznych sieci neuronowych jako metoda propagacji wstecznej. Ucząc sieć neuronową typu perceptron, należy zmienić współczynniki ważące sieci tak, aby zminimalizować średni błąd na wyjściu sieci neuronowej w momencie podania na wejście sekwencji uczących danych wejściowych. Formalnie, aby wykonać tylko jeden krok metodą gradientowego opadania (dokonać tylko jednej zmiany parametrów sieci), należy sekwencyjnie podać na wejście sieci absolutnie cały zestaw danych uczących, obliczyć błąd dla każdego obiektu dane treningowe i oblicz niezbędną korektę współczynników sieci (ale nie rób tej korekty), a po przesłaniu wszystkich danych oblicz kwotę korekty każdego współczynnika sieci (suma gradientów) i popraw współczynniki „o jeden krok” . Oczywiście przy dużym zbiorze danych uczących algorytm będzie działał niezwykle wolno, dlatego w praktyce często współczynniki sieci dopasowuje się po każdym elemencie uczącym, gdzie wartość gradientu jest aproksymowana przez gradient funkcji kosztu, obliczony tylko na jednym treningu element. Ta metoda nazywa się stochastyczne opadanie gradientowe Lub operacyjne zejście gradientowe . Stochastyczne zejście gradientowe jest formą przybliżenia stochastycznego. Teoria przybliżeń stochastycznych zapewnia warunki zbieżności metody stochastycznego gradientu.
Spinki do mankietów [ | ]
- J. Mathewsa. Moduł do metody najbardziej stromego zjazdu lub gradientu. (niedostępny link)
Literatura [ | ]
- Akulich I.L. Programowanie matematyczne na przykładach i problemach. - M.: Szkoła wyższa, 1986. - s. 298-310.
- Gill F., Murray W., Wright M. Praktyczna optymalizacja = praktyczna optymalizacja. - M.: Mir, 1985.
- Korszunow M., Korszunow M. Matematyczne podstawy cybernetyki. - M.: Energoatomizdat, 1972.
- Maksimov Yu. A., Fillipovskaya E. A. Algorytmy rozwiązywania problemów programowania nieliniowego. - M.: MEPhI, 1982.
- Maksimov Yu. Algorytmy programowania liniowego i dyskretnego. - M.: MEPhI, 1980.
- Korn G., Korn T. Podręcznik matematyki dla naukowców i inżynierów. - M.: Nauka, 1970. - s. 575-576.
- S. Yu. Gorodetsky, V. A. Grishagin. Programowanie nieliniowe i optymalizacja wieloekstremalna. - Niżny Nowogród: Wydawnictwo Uniwersytetu w Niżnym Nowogrodzie, 2007. - s. 357-363.
Najbardziej stromą metodą zniżania jest metoda gradientowa ze zmiennym krokiem. W każdej iteracji wielkość kroku k wybierana jest z warunku minimum funkcji f(x) w kierunku opadania, tj.
Warunek ten oznacza, że ruch wzdłuż antygradientu zachodzi tak długo, jak wartość funkcji f(x) maleje. Z matematycznego punktu widzenia przy każdej iteracji konieczne jest rozwiązanie problemu jednowymiarowej minimalizacji przez funkcję
()=f (x (k) -f (x (k)))
Skorzystajmy w tym celu z metody złotego podziału.
Algorytm metody najbardziej stromego zniżania jest następujący.
Podawane są współrzędne punktu początkowego x (0).
W punkcie x (k), k = 0, 1, 2, ... obliczana jest wartość gradientu f (x (k)).
Wielkość kroku k wyznacza się poprzez jednowymiarową minimalizację za pomocą funkcji
()=f (x (k) -f (x (k))).
Wyznacza się współrzędne punktu x (k):
x ja (k+1) = x i (k) - k fa ja (x (k)), i=1, …, n.
Sprawdzany jest warunek zatrzymania procesu iteracyjnego:
||f (x (k +1))|| .
Jeśli zostanie spełniony, obliczenia zostaną zatrzymane. W przeciwnym razie przechodzimy do kroku 1. Interpretację geometryczną metody najbardziej stromego zniżania przedstawiono na rys. 1.

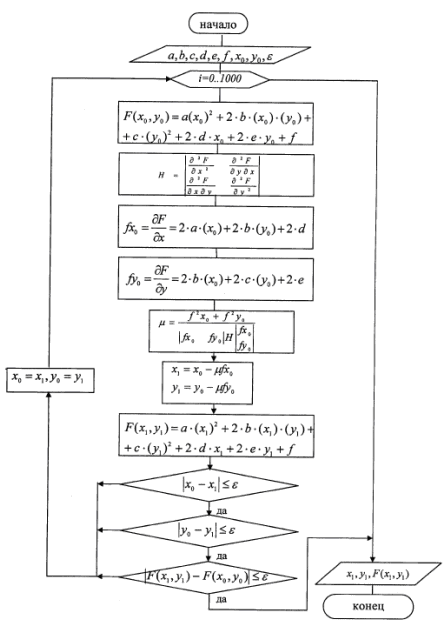
Ryż. 2.1. Schemat blokowy metody najbardziej stromego zjazdu.
Implementacja metody w programie:
Metoda najbardziej stromego zejścia.

Ryż. 2.2. Implementacja metody najbardziej stromego zjazdu.
Wniosek: W naszym przypadku metoda osiągnęła zbieżność w 7 iteracjach. Punkt A7 (0,6641; -1,3313) jest punktem ekstremalnym. Metoda kierunków sprzężonych. Dla funkcji kwadratowych można stworzyć metodę gradientową, w której czas zbieżności będzie skończony i równy liczbie zmiennych n.
Nazwijmy pewien kierunek i skoniugujmy względem jakiejś dodatnio określonej macierzy Hessa H, jeżeli:
Zatem dla jednostki H kierunek sprzężenia oznacza ich prostopadłość. W ogólnym przypadku H jest nietrywialne. W przypadek ogólny koniugacja to zastosowanie macierzy Hessa do wektora - oznacza to obrócenie tego wektora o jakiś kąt, rozciągnięcie go lub ściśnięcie.

A teraz wektor jest ortogonalny, tj. koniugacja nie jest ortogonalnością wektora, ale ortogonalnością obróconego wektora.tj.


Ryż. 2.3. Schemat blokowy metody kierunków sprzężonych.
Implementacja metody w programie: Metoda kierunków sprzężonych.

Ryż. 2.4. Implementacja metody kierunków sprzężonych.

Ryż. 2.5. Wykres metody kierunków sprzężonych.
Wniosek: Punkt A3 (0,6666; -1,3333) został znaleziony w 3 iteracjach i jest punktem ekstremalnym.
3. Analiza metod wyznaczania wartości minimalnej i maksymalnej funkcji w warunkach ograniczeń
Przypomnijmy to wspólne zadanie Optymalizacja warunkowa wygląda tak
f(x) ® min, x О W,
gdzie W jest właściwym podzbiorem R m. Podklasę problemów z ograniczeniami typu równościowego wyróżnia fakt, że zbiór jest określony przez ograniczenia postaci
fa ja (x) = 0, gdzie f i: R m ®R (i = 1, …, k).
ZatemW = (x О R m: f i (x) = 0, i = 1, …, k).
Wygodnie będzie nam zapisać indeks „0” dla funkcji f. Zatem problem optymalizacji z ograniczeniami typu równości jest zapisany jako
f 0 (x) ® min, (3.1)
fa ja (x) = 0, ja = 1, …, k. (3.2)
Jeśli teraz oznaczymy przez f funkcję na R m o wartościach w R k, której zapis współrzędnych ma postać f(x) = (f 1 (x), ..., f k (x)), to ( 3.1)–(3.2) możemy to zapisać także w formie
f 0 (x) ® min, f(x) = Q.
Geometrycznie problemem z ograniczeniami typu równości jest problem znalezienia najniższego punktu wykresu funkcji f 0 nad rozmaitością (patrz rys. 3.1).

Punkty spełniające wszystkie ograniczenia (tj. punkty ze zbioru ) nazywane są zwykle punktami dopuszczalnymi. Dopuszczalny punkt x* nazywany jest minimum warunkowym funkcji f 0 przy ograniczeniach f i (x) = 0, i = 1, ..., k (lub rozwiązaniem problemu (3.1)–(3.2)), jeżeli dla wszystkich dopuszczalnych punktów x f 0 (x *) f 0 (x). (3.3)
Jeżeli (3.3) jest spełniony tylko dla dopuszczalnego x leżącego w pewnym sąsiedztwie V x * punktu x*, to mówimy o lokalnym minimum warunkowym. Pojęcia warunkowych ścisłych minimów lokalnych i globalnych są definiowane w sposób naturalny.
W tej wersji metody gradientowej ciąg minimalizujący (X k) również konstruowany jest zgodnie z zasadą (2.22). Jednakże wielkość kroku a k wyznacza się w wyniku rozwiązania pomocniczego problemu minimalizacji jednowymiarowej
min(j k (a) | a>0 ), (2,27)
gdzie j k (a)=f(X k - a· (X k)). Zatem przy każdej iteracji w kierunku antygradientu ![]() następuje wyczerpujące zejście. Aby rozwiązać problem (2.27), można zastosować jedną z jednowymiarowych metod wyszukiwania opisanych w rozdziale 1, na przykład metodę wyszukiwania bitowego lub metodę złotego podziału.
następuje wyczerpujące zejście. Aby rozwiązać problem (2.27), można zastosować jedną z jednowymiarowych metod wyszukiwania opisanych w rozdziale 1, na przykład metodę wyszukiwania bitowego lub metodę złotego podziału.
Opiszmy algorytm metody najbardziej stromego zniżania.
Krok 0. Ustaw parametr dokładności e>0, wybierz X 0 ОE n , ustaw k=0.
Krok 1. Znajdź (X k) i sprawdź warunek osiągnięcia określonej dokładności || (x k) ||£ e. Jeśli jest spełniony, przejdź do kroku 3, w przeciwnym razie - do kroku 2.
Krok 2. Rozwiąż zadanie (2.27), tj. znajdź k. Znajdź następny punkt, wstaw k=k+1 i przejdź do kroku 1.
Krok 3 Uzupełnij obliczenia wstawiając X * = X k, f * = f(X k).
Minimalizuj funkcję
f(x)=x 1 2 +4x 2 2 -6x 1 -8x 2 +13; (2.28)
Najpierw rozwiążmy problem klasyczny metoda. Zapiszmy układ równań reprezentujący niezbędne warunki bezwarunkowe ekstremum

Po rozwiązaniu otrzymujemy punkt stacjonarny X*=(3;1). Następnie sprawdźmy wykonanie warunek wystarczający, dla którego znajdujemy macierz drugich pochodnych
Ponieważ zgodnie z kryterium Sylwestra macierz ta jest dodatnio określona dla ", to znaleziony punkt X* jest punktem minimalnym funkcji f(X). Wartość minimalna f *=f(X*)=0. To jest dokładne rozwiązanie problemu (11).
Wykonajmy jedną iterację metody zejście gradientowe dla (2.28). Wybierzmy punkt początkowy X 0 =(1;0), ustawmy krok początkowy a=1 i parametr l=0,5. Obliczmy f(X 0)=8.
Znajdźmy gradient funkcji f(X) w punkcie X 0
(X 0) = = (2,29)
Zdefiniujmy nowy punkt X=X 0 -a· (X 0) obliczając jego współrzędne
x 1 = 
x 2 =  (2.30)
(2.30)
Obliczmy f(X)= f(X 0 -a· (X 0))=200. Ponieważ f(X)>f(X 0), dzielimy krok, zakładając a=a·l=1·0,5=0,5. Obliczamy ponownie, korzystając ze wzorów (2.30) x 1 =1+4a=3; x 2 =8a=4 i znajdź wartość f(X)=39. Ponieważ f(X)>f(X 0) ponownie zmniejszamy wielkość kroku, ustawiając a=a·l=0,5·0,5=0,25. Obliczamy nowy punkt o współrzędnych x 1 =1+4·0,25=2; x 2 =8·0,25=2 i wartość funkcji w tym punkcie f(X)=5. Ponieważ warunek zmniejszania f(X) Wykonajmy jedną iterację stosując metodę najbardziej stromy zjazd dla (2.28) z tym samym punktem początkowym X 0 =(1;0). Korzystając z już znalezionego gradientu (2.29), znajdujemy X= X 0 -a · (X 0) i skonstruuj funkcję j 0 (a)=f(X 0 -a· (X 0))=(4a-2) 2 +4(8a-1) 2. Minimalizując go za pomocą warunku koniecznego j 0 ¢(a)=8·(4a - 2)+64·(8a - 1)=0 znajdujemy optymalną wartość wielkości kroku a 0 =5/34. Wyznaczanie punktu ciągu minimalizującego X 1 = X 0 -a 0 · (X 0) Gradient funkcji różniczkowalnej f(x) w punkcie X zwany N-wektor wymiarowy f(x)
, których składowe są pochodnymi cząstkowymi funkcji f(x), obliczone w punkcie X, tj. f” (x ) = (df(x)/dh 1 , …, df(x)/dx n) T . Wektor ten jest prostopadły do płaszczyzny przechodzącej przez ten punkt X i styczną do płaskiej powierzchni funkcji f(x), przechodząc przez punkt X.W każdym punkcie takiej powierzchni funkcja k(x) przyjmuje tę samą wartość. Przyrównując funkcję do różnych stałych wartości C 0 , C 1 , ..., otrzymujemy szereg powierzchni charakteryzujących jej topologię (ryc. 2.8). Wektor gradientu jest skierowany w stronę najszybszego wzrostu funkcji w danym punkcie. Wektor przeciwny do gradientu (-f’(x))
, zwany antygradientowy i jest ukierunkowany na najszybszy spadek funkcji. W punkcie minimalnym gradient funkcji wynosi zero. Metody pierwszego rzędu, zwane także metodami gradientowymi i minimalizacyjnymi, opierają się na właściwościach gradientów. Stosowanie tych metod w ogólnym przypadku pozwala na wyznaczenie lokalnego punktu minimalnego funkcji. Oczywiście, jeśli nie ma dodatkowych informacji, to od punktu wyjścia X rozsądne jest przejście do rzeczy X, leżący w kierunku antygradientu - najszybszy spadek funkcji. Wybór kierunku opadania R[k] antygradientowy - f'(x[k] )
w tym punkcie X[k], otrzymujemy proces iteracyjny postaci X[ k+ 1] = X[k]-a k f” (x[k] )
,
i k > 0; k=0, 1, 2, ... W formie współrzędnych proces ten zapisuje się w następujący sposób: x ja [ k+1]=x ja[k] - kf(x[k] )
/x ja ja = 1, ..., N; k= 0, 1, 2,... Jako kryterium zatrzymania procesu iteracyjnego przyjmuje się albo spełnienie warunku małego przyrostu argumentu || X[k+l] -X[k] || <= e
,
либо выполнение условия малости градиента || f'(x[k+l] )
|| <= g
, Tutaj e i g podano małe ilości. Możliwe jest także kryterium łączone, polegające na jednoczesnym spełnieniu określonych warunków. Metody gradientowe różnią się od siebie sposobem doboru wielkości kroku i k. W metodzie ze stałym krokiem dla wszystkich iteracji wybierana jest pewna stała wartość kroku. Całkiem mały krok i k zapewni, że funkcja maleje, tj. nierówność f(x[ k+1])
= f(x[k] – a k f’(x[k] ))
< f(x[k] )
. Może to jednak skutkować koniecznością przeprowadzenia niedopuszczalnie dużej liczby iteracji, aby osiągnąć punkt minimalny. Z drugiej strony zbyt duży krok może spowodować nieoczekiwany wzrost funkcji lub doprowadzić do oscylacji wokół punktu minimalnego (cykling). Ze względu na trudność uzyskania informacji niezbędnych do doboru wielkości kroku, w praktyce rzadko stosuje się metody ze stałymi krokami. Gradientowe są bardziej ekonomiczne pod względem liczby iteracji i niezawodności metody zmiennego kroku, gdy w zależności od wyników obliczeń wielkość kroku zmienia się w jakiś sposób. Rozważmy warianty takich metod stosowanych w praktyce. W przypadku stosowania metody najbardziej stromego opadania w każdej iteracji, wielkość kroku i k jest wybierany z minimalnego warunku funkcji k(x) w kierunku opadania, tj. Warunek ten oznacza, że ruch wzdłuż antygradientu następuje tak długo, jak długo trwa wartość funkcji k(x) maleje. Z matematycznego punktu widzenia przy każdej iteracji konieczne jest rozwiązanie problemu jednowymiarowej minimalizacji wg A Funkcje Algorytm metody najbardziej stromego zniżania jest następujący. 1. Ustaw współrzędne punktu początkowego X.
2. W punkcie X[k],
k = 0, 1, 2, ... oblicza wartość gradientu f'(x[k])
. 3. Określa się wielkość kroku A k, poprzez jednowymiarową minimalizację A funkcje j (A) = f(x[k]-af” (x[k])).
4. Wyznacza się współrzędne punktu X[k+ 1]: x ja [ k+ 1]= xi[k]– a k f’ i (x[k]), i = 1,..., p. 5. Sprawdzane są warunki zatrzymania procesu sterylizacji. Jeśli zostaną spełnione, obliczenia zostaną zatrzymane. W przeciwnym razie przejdź do kroku 1. W rozważanej metodzie kierunek ruchu od punktu X[k] dotyka w tym punkcie linii poziomu X[k+ 1] (ryc. 2.9). Trajektoria opadania jest zygzakowata, a sąsiednie zygzaki są prostopadłe do siebie. Rzeczywiście, krok A k jest wybierane poprzez minimalizację przez A Funkcje? (A) = f(x[k] -af” (x[k]))
. Warunek konieczny minimum funkcji D J (a)/da = 0. Po obliczeniu pochodnej funkcji zespolonej otrzymujemy warunek ortogonalności wektorów kierunków opadania w sąsiadujących punktach: DJ (a)/da = -f’(x[k+ 1]f'(x[k])
= 0.
Metody gradientowe zbiegają się do minimum przy dużej prędkości (prędkość postępu geometrycznego) w celu uzyskania gładkich funkcji wypukłych. Takie funkcje mają najwięcej M i najmniej M wartości własne macierzy drugich pochodnych (macierz Hesja) niewiele się od siebie różnią, czyli macierz N(x) dobrze uwarunkowane. Przypomnijmy, że wartości własne l i, I
=1, …, N, macierze są pierwiastkami równania charakterystycznego Jednak w praktyce minimalizowane funkcje mają z reguły źle uwarunkowane macierze drugich pochodnych (t/m<<
1). Wartości takich funkcji w niektórych kierunkach zmieniają się znacznie szybciej (czasami o kilka rzędów wielkości) niż w innych kierunkach. Ich płaskie powierzchnie w najprostszym przypadku są silnie wydłużone (ryc. 2.10), w bardziej skomplikowanych przypadkach wyginają się i wyglądają jak wąwozy. Nazywa się funkcje o takich właściwościach wąwóz. Kierunek antygradientu tych funkcji (patrz rys. 2.10) odbiega znacznie od kierunku do punktu minimalnego, co prowadzi do spowolnienia szybkości zbieżności. Stopień zbieżności metod gradientowych zależy także w istotny sposób od dokładności obliczeń gradientowych. Utrata dokładności, która zwykle występuje w pobliżu punktów minimalnych lub w sytuacji wąwozu, może ogólnie zakłócić zbieżność procesu opadania gradientu. Z powyższych powodów metody gradientowe często stosuje się w połączeniu z innymi, bardziej efektywnymi metodami już na początkowym etapie rozwiązywania problemu. W tym przypadku rzecz X jest daleki od punktu minimalnego, a kroki w kierunku antygradientu pozwalają osiągnąć znaczny spadek funkcji. Omówione powyżej metody gradientowe znajdują minimalny punkt funkcji w przypadku ogólnym tylko w nieskończonej liczbie iteracji. Metoda gradientu sprzężonego generuje kierunki poszukiwań bardziej spójne z geometrią minimalizowanej funkcji. Zwiększa to znacząco szybkość ich zbieżności i pozwala np. minimalizować funkcję kwadratową f(x) = (x, Hx) + (b, x) + a z symetryczną dodatnio określoną macierzą N w skończonej liczbie kroków P, równa liczbie zmiennych funkcji. Każdą gładką funkcję w pobliżu punktu minimalnego można dobrze przybliżyć funkcją kwadratową, dlatego metody gradientu sprzężonego z powodzeniem stosuje się do minimalizacji funkcji niekwadratowych. W tym przypadku przestają być skończone i stają się iteracyjne. Z definicji dwa N-wektor wymiarowy X I Na zwany sprzężony względem matrycy H(Lub H-koniugat), jeśli iloczyn skalarny (X, Cóż) = 0. Tutaj N - symetryczna dodatnio określona macierz wielkości P X P. Jednym z najistotniejszych problemów metod gradientu sprzężonego jest problem efektywnego konstruowania kierunków. Metoda Fletchera-Reevesa rozwiązuje ten problem poprzez transformację antygradientu na każdym etapie -f(x[k])
w kierunku P[k],
H-koniuguj z wcześniej znalezionymi kierunkami R, R, ..., R[k-1]. Rozważmy najpierw tę metodę w odniesieniu do problemu minimalizacji. funkcja kwadratowa R[k Wskazówki ] oblicza się za pomocą wzorów: k] = -f'(x[k])
P[ P[k+b k-1 k>= 1; -l], p = -’(X)
. F k wartości b P[k], R[k-1 są wybierane tak, aby kierunki H-1] były :
(P[k], -sprzężony[HP 1])= 0.
k- W rezultacie dla funkcji kwadratowej iteracyjny proces minimalizacji ma postać k+l] X[[k]=x[k], +a k str R[k] -
Gdzie HP kierunek zejścia do m krok; i k- Rozmiar kroku. Ten ostatni jest wybierany z minimalnego warunku funkcji A k(x) f(x[ k] + Przez[k])
= f(x[k] + w kierunku ruchu, czyli w wyniku rozwiązania jednowymiarowego problemu minimalizacji: [k])
. a k r ar Dla funkcji kwadratowej X Algorytm metody gradientu sprzężonego Fletchera-Reevesa jest następujący. P = -f'(x)
. 1. W punkcie HP obliczony A 2. Włączone .
m krok, korzystając z powyższych wzorów, określa się krok X[k+ 1]. k f(x[k+1])
i okres f'(x[k+1])
. 3. Wartości są obliczane f'(x)
I X[k 4. Jeśli = 0, następnie wskaż+1] to minimalny punkt funkcji P[k f(x). W przeciwnym razie zostanie wyznaczony nowy kierunek P+l] z relacji i następuje przejście do kolejnej iteracji. Ta procedura znajdzie minimum funkcji kwadratowej w nie więcej niż kroki. X Minimalizując funkcje niekwadratowe, metoda Fletchera-Reevesa staje się iteracyjna od skończonej. W tym przypadku po X[P(p+ iteracyjny proces minimalizacji ma postać k+l] 1) iteracje procedury 1-4 powtarza się cyklicznie ze zamianą[k]=x[k],
] oblicza się za pomocą wzorów: k] NA[k])+
+1] , a obliczenia kończą się na , gdzie jest podana liczba. W tym przypadku stosuje się następującą modyfikację metody: HP 1 P[k+b k-1 k>= 1; = x X); f(x[ k] + = -f’(x[k])
= f(x[k] B[k];
p = -f’( a k s+ap a k s Tutaj I- wiele indeksów: P= (0, n, 2 p, wynagrodzenie, ...), czyli metoda jest aktualizowana co X kroki. R = Znaczenie geometryczne Metoda gradientu sprzężonego jest następująca (ryc. 2.11). Z danego punktu początkowego X zejście odbywa się w kierunku -f” (x). W punkcie X jest minimalnym punktem funkcji w kierunku R,
To f'(x)
ortogonalne do wektora R. Następnie zostaje znaleziony wektor R , H-koniugacja z R. Następnie znajdujemy minimum funkcji wzdłuż kierunku R itp. Metody kierunku sprzężonego należą do najskuteczniejszych w rozwiązywaniu problemów minimalizacji. Należy jednak zaznaczyć, że są one wrażliwe na błędy powstałe podczas procesu liczenia. Przy dużej liczbie zmiennych błąd może wzrosnąć tak bardzo, że proces będzie musiał zostać powtórzony nawet dla funkcji kwadratowej, tj. proces dla niego nie zawsze pasuje do P= (0, n, 2 Metoda najstromszego opadania (w literaturze angielskiej „method of stromeest descent”) to iteracyjna metoda numeryczna (pierwszego rzędu) służąca do rozwiązywania problemów optymalizacyjnych, która pozwala wyznaczyć ekstremum (minimum lub maksimum) funkcji celu: Zgodnie z rozważaną metodą ekstremum (maksimum lub minimum) funkcji celu wyznacza się w kierunku najszybszego wzrostu (spadku) funkcji, tj. w kierunku gradientu (antygradientu) funkcji. Funkcja gradientu w punkcie gdzie i, j,…, n są wektorami jednostkowymi równoległymi do osi współrzędnych. Gradient w punkcie bazowym Najbardziej stroma metoda zjazdu to dalszy rozwój Metoda gradientowego opadania. Ogólnie rzecz biorąc, proces znajdowania ekstremum funkcji jest procedurą iteracyjną, którą można zapisać w następujący sposób: gdzie znak „+” służy do znalezienia maksimum funkcji, a znak „-” do znalezienia minimum funkcji; Jednostkowy wektor kierunku, który jest określony wzorem: Stała określająca wielkość kroku, taka sama dla wszystkich i-tych kierunków. Wielkość kroku dobierana jest z warunku minimum funkcji celu f(x) w kierunku ruchu, czyli w wyniku rozwiązania jednowymiarowego problemu optymalizacji w kierunku gradientu lub antygradientu: Innymi słowy, wielkość kroku określa się rozwiązując równanie: Zatem etap obliczeń wybiera się tak, aby ruch był wykonywany do momentu poprawy funkcji, osiągając w ten sposób w pewnym momencie ekstremum. W tym miejscu ponownie wyznacza się kierunek poszukiwań (za pomocą gradientu) i poszukuje się nowego optymalnego punktu funkcji celu itp. Zatem w tej metodzie poszukiwanie odbywa się w większych krokach, a gradient funkcji obliczany jest w mniejszej liczbie punktów. W przypadku funkcji dwóch zmiennych Ta metoda ma następującą interpretację geometryczną: kierunek ruchu od punktu dotyka linii poziomu w punkcie . Trajektoria opadania jest zygzakowata, a sąsiednie zygzaki są prostopadłe do siebie. Warunek ortogonalności wektorów kierunków zniżania w sąsiadujących punktach zapisuje się wzorem: Trajektoria ruchu do punktu ekstremum metodą najbardziej stromego zniżania przedstawiona na wykresie linii równego poziomu funkcji f(x) Poszukiwanie optymalnego rozwiązania kończy się na etapie obliczeń iteracyjnych (kilka kryteriów): Trajektoria wyszukiwania pozostaje w niewielkim sąsiedztwie bieżącego punktu wyszukiwania: Przyrost funkcji celu nie zmienia się: Gradient funkcji celu w lokalnym punkcie minimalnym staje się zerowy: Należy zauważyć, że metoda gradientowego opadania okazuje się bardzo powolna podczas poruszania się po wąwozie, a wraz ze wzrostem liczby zmiennych w funkcji celu takie zachowanie metody staje się typowe. Wąwóz jest zagłębieniem, którego linie poziomów mają w przybliżeniu kształt elips o wielokrotnie różniących się półosiach. W obecności wąwozu trajektoria zniżania przybiera formę zygzakowatej linii z małym krokiem, w wyniku czego uzyskana prędkość zniżania do minimum jest znacznie spowolniona. Wyjaśnia to fakt, że kierunek antygradientu tych funkcji znacznie odbiega od kierunku do punktu minimalnego, co prowadzi do dodatkowego opóźnienia w obliczeniach. W rezultacie algorytm traci wydajność obliczeniową. Funkcja wpustu Metoda gradientowa wraz z wieloma modyfikacjami jest szeroko rozpowszechniona i skuteczna metoda poszukiwanie optymalnego badanego obiektu. Wadą poszukiwania gradientowego (jak również metod omówionych powyżej) jest to, że podczas jego stosowania można wykryć jedynie lokalne ekstremum funkcji. Aby znaleźć innych lokalne ekstrema konieczne jest wyszukiwanie od innych punktów wyjścia. Również szybkość konwergencji metody gradientowe zależy również w znacznym stopniu od dokładności obliczeń gradientu. Utrata dokładności, która zwykle występuje w pobliżu punktów minimalnych lub w sytuacji wąwozu, może ogólnie zakłócić zbieżność procesu opadania gradientu. Metoda obliczeniowa pierwszy krok: Definicja wyrażeń analitycznych (w formie symbolicznej) do obliczania gradientu funkcji Krok 2: Ustaw przybliżenie początkowe Krok 3: Stwierdzono konieczność ponownego uruchomienia procedury algorytmicznej w celu zresetowania ostatniego kierunku wyszukiwania. W wyniku ponownego uruchomienia wyszukiwanie jest przeprowadzane ponownie w kierunku najszybszego zjazdu.
 .
.
f(x[k]–a k f’(x[k]))
= f(x[k] – af”(x[k]))
.
J (A) = f(x[k]-af” (x[k]))
.




![]() ,
,![]()
 .
.
![]() są wartościami argumentu funkcji (parametry kontrolowane) w domenie rzeczywistej.
są wartościami argumentu funkcji (parametry kontrolowane) w domenie rzeczywistej.![]() jest wektorem, którego rzuty na osie współrzędnych są pochodnymi cząstkowymi funkcji po współrzędnych:
jest wektorem, którego rzuty na osie współrzędnych są pochodnymi cząstkowymi funkcji po współrzędnych:![]() jest ściśle prostopadły do powierzchni, a jego kierunek wskazuje kierunek najszybszego wzrostu funkcji, a kierunek przeciwny (antygradient) odpowiednio wskazuje kierunek najszybszego spadku funkcji.
jest ściśle prostopadły do powierzchni, a jego kierunek wskazuje kierunek najszybszego wzrostu funkcji, a kierunek przeciwny (antygradient) odpowiednio wskazuje kierunek najszybszego spadku funkcji.

![]() - moduł gradientu określa szybkość wzrostu lub spadku funkcji w kierunku gradientu lub antygradientu:
- moduł gradientu określa szybkość wzrostu lub spadku funkcji w kierunku gradientu lub antygradientu:
![]()
![]()

![]()









