También puede buscar no el mejor punto en la dirección del gradiente, sino uno mejor que el actual.
El más fácil de implementar de todos los métodos de optimización local. tiene bastante condiciones débiles convergencia, pero la tasa de convergencia es bastante baja (lineal). El paso del método de gradiente se utiliza a menudo como parte de otros métodos de optimización, como el método de Fletcher-Reeves.
Descripción [ | ]
Mejoras[ | ]
El método de descenso en gradiente resulta muy lento cuando se avanza por un barranco y con un aumento en el número de variables. función objetiva este comportamiento del método se vuelve típico. Para combatir este fenómeno se utiliza, cuya esencia es muy simple. Habiendo realizado dos pasos de descenso de pendiente y obtenidos tres puntos, se debe dar el tercer paso en la dirección del vector que conecta el primer y tercer punto, a lo largo del fondo del barranco.
Para funciones cercanas a la cuadrática, el método del gradiente conjugado es eficaz.
Aplicación en redes neuronales artificiales.[ | ]
El método de descenso de gradiente, con algunas modificaciones, se utiliza ampliamente para el entrenamiento de perceptrones y se conoce en la teoría de las redes neuronales artificiales como método de retropropagación. Al entrenar una red neuronal de tipo perceptrón, es necesario cambiar los coeficientes de ponderación de la red para minimizar error promedio en la salida de la red neuronal cuando se suministra a la entrada una secuencia de datos de entrada de entrenamiento. Formalmente, para dar solo un paso usando el método de descenso de gradiente (realizar solo un cambio en los parámetros de la red), es necesario enviar secuencialmente absolutamente todo el conjunto de datos de entrenamiento a la entrada de la red, calcular el error para cada objeto de los datos de entrenamiento y calcular la corrección necesaria de los coeficientes de la red (pero no hacer esta corrección), y después de enviar todos los datos, calcular la cantidad en la corrección de cada coeficiente de la red (suma de gradientes) y corregir los coeficientes "un paso" . Obviamente, con un gran conjunto de datos de entrenamiento, el algoritmo funcionará extremadamente lento, por lo que en la práctica, los coeficientes de la red a menudo se ajustan después de cada elemento de entrenamiento, donde el valor del gradiente se aproxima al gradiente de la función de costo, calculada en un solo entrenamiento. elemento. Este método se llama descenso de gradiente estocástico o descenso de gradiente operativo . El descenso de gradiente estocástico es una forma de aproximación estocástica. La teoría de aproximaciones estocásticas proporciona condiciones para la convergencia del método de descenso de gradiente estocástico.
Enlaces [ | ]
- J. Mathews. Módulo para el Método de Descenso Más Empinado o Pendiente. (enlace no disponible)
Literatura [ | ]
- Akulich I.L. Programación matemática en ejemplos y problemas. - M.: Escuela Superior, 1986. - P. 298-310.
- Gill F., Murray W., Wright M. Optimización práctica = Optimización práctica. - M.: Mir, 1985.
- Korshunov Yu., Korshunov Yu. Fundamentos matemáticos de la cibernética. - M.: Energoatomizdat, 1972.
- Maksimov Yu., Fillipovskaya E. A. Algoritmos para la resolución de problemas de programación no lineal. - M.: MEPhI, 1982.
- Maksimov Yu. Algoritmos de programación lineal y discreta. - M.: MEPhI, 1980.
- Korn G., Korn T. Manual de matemáticas para científicos e ingenieros. - M.: Nauka, 1970. - P. 575-576.
- S. Yu. Gorodetsky, V. A. Grishagin. Programación no lineal y optimización multiextremal. - Nizhny Novgorod: Editorial de la Universidad de Nizhny Novgorod, 2007. - págs. 357-363.
El método de descenso más pronunciado es un método de gradiente con un paso variable. En cada iteración, el tamaño del paso k se selecciona a partir de la condición del mínimo de la función f(x) en la dirección de descenso, es decir
Esta condición significa que el movimiento a lo largo del antigradiente ocurre siempre que el valor de la función f (x) disminuya. Desde un punto de vista matemático, en cada iteración es necesario resolver el problema de minimización unidimensional por función.
()=f (x (k) -f (x (k)))
Usemos el método de la proporción áurea para esto.
El algoritmo del método de descenso más pronunciado es el siguiente.
Se especifican las coordenadas del punto inicial x (0).
En el punto x (k), k = 0, 1, 2, ..., se calcula el valor del gradiente f (x (k)).
El tamaño del paso k se determina mediante minimización unidimensional utilizando la función
()=f(x(k)-f(x(k))).
Las coordenadas del punto x (k) se determinan:
x i (k+1) = x i (k) - k f i (x (k)), i=1, …, n.
Se verifica la condición para detener el proceso iterativo:
||f(x(k+1))|| .
Si se cumple, entonces los cálculos se detienen. De lo contrario, procedemos al paso 1. La interpretación geométrica del método de descenso más pronunciado se presenta en la Fig. 1.

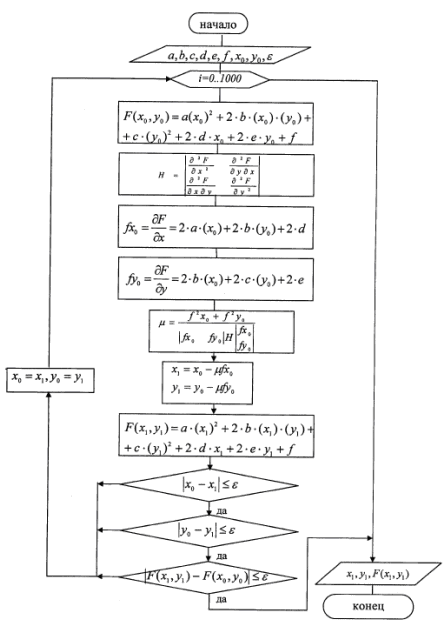
Arroz. 2.1. Diagrama de bloques del método de descenso más pronunciado.
Implementación del método en el programa:
Método de descenso más pronunciado.

Arroz. 2.2. Implementación del método de descenso más pronunciado.
Conclusión: En nuestro caso, el método convergió en 7 iteraciones. El punto A7 (0,6641; -1,3313) es un punto extremo. Método de direcciones conjugadas. Para funciones cuadráticas, puede crear un método de gradiente en el que el tiempo de convergencia será finito e igual al número de variables n.
Llamemos H a una determinada dirección y conjuguemos con respecto a alguna matriz de Hess definida positiva si:
Entonces, es decir, para la unidad H, la dirección conjugada significa su perpendicular. En el caso general, H no es trivial. EN caso general La conjugación es la aplicación de la matriz de Hess a un vector; significa rotar este vector en algún ángulo, estirarlo o comprimirlo.

Y ahora el vector es ortogonal, es decir, la conjugación no es la ortogonalidad del vector, sino la ortogonalidad del vector rotado.e.i.


Arroz. 2.3. Diagrama de bloques del método de direcciones conjugadas.
Implementación del método en el programa: Método de direcciones conjugadas.

Arroz. 2.4. Implementación del método de direcciones conjugadas.

Arroz. 2.5. Gráfica del método de direcciones conjugadas.
Conclusión: El punto A3 (0,6666; -1,3333) se encontró en 3 iteraciones y es un punto extremo.
3. Análisis de métodos para determinar el valor mínimo y máximo de una función en presencia de restricciones.
Te recordamos que Tarea común la optimización condicional se ve así
f(x) ® min, x О W,
donde W es un subconjunto propio de R m. Una subclase de problemas con restricciones de tipo igualdad se distingue por el hecho de que el conjunto está definido por restricciones de la forma
f i (x) = 0, donde f i: R m ®R (i = 1, …, k).
Así,W = (x О R m: f i (x) = 0, i = 1, …, k).
Nos resultará conveniente escribir el índice "0" para la función f. Por lo tanto, el problema de optimización con restricciones de tipo igualdad se escribe como
f 0 (x) ® mín, (3.1)
f yo (x) = 0, yo = 1,…, k. (3.2)
Si ahora denotamos por f una función en R m con valores en R k, cuya notación de coordenadas tiene la forma f(x) = (f 1 (x), ..., f k (x)), entonces ( 3.1)–(3.2) también podemos escribirlo en la forma
f 0 (x) ® mín, f(x) = Q.
Geométricamente, un problema con restricciones de tipo igualdad es un problema de encontrar el punto más bajo de la gráfica de una función f 0 sobre la variedad (ver Fig. 3.1).

Los puntos que satisfacen todas las restricciones (es decir, los puntos del conjunto ) suelen denominarse admisibles. Un punto admisible x* se llama mínimo condicional de la función f 0 bajo las restricciones f i (x) = 0, i = 1, ..., k (o una solución al problema (3.1)–(3.2)), si para todos los puntos admisibles x f 0 (x *) f 0 (x). (3.3)
Si (3.3) se satisface sólo para x admisible que se encuentra en alguna vecindad V x * del punto x*, entonces hablamos de un mínimo condicional local. Los conceptos de mínimos condicionales estrictos locales y globales se definen de forma natural.
En esta versión del método del gradiente, la secuencia minimizadora (X k) también se construye según la regla (2.22). Sin embargo, el tamaño del paso a k se encuentra como resultado de resolver el problema auxiliar de minimización unidimensional
mín(j k (a) | a>0 ), (2.27)
donde j k (a)=f(X k - a· (X k)). Por lo tanto, en cada iteración en la dirección del antigradiente ![]() Se realiza un descenso exhaustivo. Para resolver el problema (2.27), puede utilizar uno de los métodos de búsqueda unidimensional descritos en la Sección 1, por ejemplo, el método de búsqueda bit a bit o el método de la sección áurea.
Se realiza un descenso exhaustivo. Para resolver el problema (2.27), puede utilizar uno de los métodos de búsqueda unidimensional descritos en la Sección 1, por ejemplo, el método de búsqueda bit a bit o el método de la sección áurea.
Describamos el algoritmo del método de descenso más pronunciado.
Paso 0. Establezca el parámetro de precisión e>0, seleccione X 0 ОE n, establezca k=0.
Paso 1. Encuentre (X k) y verifique la condición para lograr la precisión especificada || (x k) ||£ mi. Si se cumple, vaya al paso 3; de lo contrario, al paso 2.
Paso 2. Resuelva el problema (2.27), es decir encontrar una k. Encuentra el siguiente punto, pon k=k+1 y ve al paso 1.
Paso 3 Completa los cálculos poniendo X * = X k, f * = f(X k).
Minimizar función
f(x)=x 1 2 +4x 2 2 -6x 1 -8x 2 +13; (2.28)
Resolvamos el problema primero. clásico método. Escribamos un sistema de ecuaciones que represente las condiciones necesarias extremo incondicional

Resuelto, obtenemos un punto estacionario X*=(3;1). A continuación, verifiquemos la ejecución. condición suficiente, para lo cual encontramos la matriz de segundas derivadas
Dado que, según el criterio de Sylvester, esta matriz es definida positiva para ", entonces el punto encontrado X* es el punto mínimo de la función f(X). El valor mínimo f *=f(X*)=0. Esta es la solución exacta al problema (11).
Realicemos una iteración del método. descenso de gradiente para (2.28). Elijamos el punto de partida X 0 =(1;0), establezcamos el paso inicial a=1 y el parámetro l=0.5. Calculemos f(X 0)=8.
Encontremos el gradiente de la función f(X) en el punto X 0
(X 0)= = (2.29)
Definamos un nuevo punto X=X 0 -a· (X 0) calculando sus coordenadas
x1 = 
x2 =  (2.30)
(2.30)
Calculemos f(X)= f(X 0 -a· (X 0))=200. Como f(X)>f(X 0), dividimos el paso, asumiendo a=a·l=1·0.5=0.5. Calculamos nuevamente usando las fórmulas (2.30) x 1 =1+4a=3; x 2 =8a=4 y encuentre el valor f(X)=39. Dado que f(X)>f(X 0) nuevamente, reducimos aún más el tamaño del paso, estableciendo a=a·l=0.5·0.5=0.25. Calculamos un nuevo punto con coordenadas x 1 =1+4·0.25=2; x 2 =8·0.25=2 y el valor de la función en este punto f(X)=5. Dado que la condición para disminuir f(X) Realicemos una iteración usando el método. descenso más empinado para (2.28) con el mismo punto inicial X 0 =(1;0). Usando el gradiente ya encontrado (2.29), encontramos X= X 0 -a· (X 0) y construye la función j 0 (a)=f(X 0 -a· (X 0))=(4a-2) 2 +4(8a-1) 2. Minimizándolo utilizando la condición necesaria. j 0 ¢(a)=8·(4a - 2)+64·(8a - 1)=0 encontramos el valor óptimo del tamaño del paso a 0 =5/34. Determinar el punto de la secuencia minimizadora. X 1 = X 0 -a 0 · (X 0) El gradiente de la función diferenciable f(x) en el punto X llamado norte-vector dimensional f(x))
, cuyos componentes son derivadas parciales de la función f(x), calculado en el punto X, es decir. f"(x ) = (gl(x)/dh 1 , …, df(x)/dx n) T . Este vector es perpendicular al plano que pasa por el punto X, y tangente a la superficie nivelada de la función. f(x), pasando por un punto X.En cada punto de dicha superficie la función f(x) toma el mismo valor. Igualando la función a varios valores constantes C 0 , C 1 , ..., obtenemos una serie de superficies que caracterizan su topología (Fig. 2.8). El vector gradiente se dirige en la dirección del aumento más rápido de la función en un punto dado. Vector opuesto al gradiente (-f’(x))
, llamado anti-gradiente y está dirigido a la disminución más rápida de la función. En el punto mínimo, el gradiente de la función es cero. Los métodos de primer orden, también llamados métodos de gradiente y de minimización, se basan en las propiedades de los gradientes. El uso de estos métodos en el caso general le permite determinar el punto mínimo local de una función. Obviamente, si no hay información adicional, entonces desde el punto de partida X es sabio ir al grano X, que se encuentra en la dirección del antigradiente: la disminución más rápida de la función. Elegir como dirección de descenso. R[k] anti-gradiente - f'(x[k] )
en el punto X[k], obtenemos un proceso iterativo de la forma X[ k+ 1] = X[k]-akf"(x[k] )
,
y k > 0; k=0, 1, 2, ... En forma de coordenadas, este proceso se escribe de la siguiente manera: x yo [ k+1]=xyo[k] - akf(x)[k] )
/x yo yo = 1, ..., norte; k= 0, 1, 2,... Como criterio para detener el proceso iterativo, ya sea el cumplimiento de la condición de pequeño incremento del argumento || X[k+l] -X[k] || <= e
,
либо выполнение условия малости градиента || f'(x[k+l] )
|| <= g
, Aquí e y g reciben pequeñas cantidades. También es posible un criterio combinado, consistente en el cumplimiento simultáneo de las condiciones especificadas. Los métodos de gradiente se diferencian entre sí en la forma en que eligen el tamaño del paso. y k. En el método con paso constante, se selecciona un determinado valor de paso constante para todas las iteraciones. Un paso bastante pequeño y k asegurará que la función disminuya, es decir, la desigualdad f(x[ k+1])
= f(x)[k] – akf’(x[k] ))
< f(x)[k] )
. Sin embargo, esto puede llevar a la necesidad de realizar un número inaceptablemente grande de iteraciones para alcanzar el punto mínimo. Por otro lado, un paso demasiado grande puede provocar un aumento inesperado de la función o provocar oscilaciones alrededor del punto mínimo (cíclico). Debido a la dificultad de obtener la información necesaria para seleccionar el tamaño del paso, en la práctica rara vez se utilizan métodos con pasos constantes. Los gradientes son más económicos en términos de número de iteraciones y confiabilidad. métodos de paso variable, cuando, dependiendo de los resultados de los cálculos, el tamaño del paso cambia de alguna manera. Consideremos las variantes de tales métodos utilizados en la práctica. Cuando se utiliza el método de descenso más pronunciado en cada iteración, el tamaño del paso y k se selecciona de la condición mínima de la función f(x) en la dirección de descenso, es decir Esta condición significa que el movimiento a lo largo del antigradiente ocurre siempre que el valor de la función f(x) disminuye. Desde un punto de vista matemático, en cada iteración es necesario resolver el problema de minimización unidimensional según A funciones El algoritmo del método de descenso más pronunciado es el siguiente. 1. Establecer las coordenadas del punto de partida. X.
2. En el punto X[k],
k = 0, 1, 2, ... calcula el valor del gradiente f'(x[k])
. 3. Se determina el tamaño del paso. a k, por minimización unidimensional sobre A funciones j (a) = f(x)[k]-af"(x[k])).
4. Se determinan las coordenadas del punto. X[k+ 1]: x yo [ k+ 1]= xi[k]– a k f’ i (x[k]), i = 1,..., pág. 5. Se verifican las condiciones para detener el proceso de esteración. Si se cumplen, los cálculos se detienen. De lo contrario, vaya al paso 1. En el método considerado, la dirección del movimiento desde el punto X[k] toca la línea de nivel en el punto X[k+ 1] (Figura 2.9). La trayectoria de descenso es en zigzag, con enlaces en zigzag adyacentes ortogonales entre sí. De hecho, un paso a k se elige minimizando por A funciones? (a) = f(x)[k] -af"(x[k]))
. Condición necesaria para el mínimo de una función. d j (a)/da = 0. Habiendo calculado la derivada de una función compleja, obtenemos la condición para la ortogonalidad de los vectores de direcciones de descenso en puntos vecinos: DJ (a)/da = -f’(x[k+ 1]f'(x[k])
= 0.
Los métodos de gradiente convergen a un mínimo a alta velocidad (velocidad de progresión geométrica) para funciones convexas suaves. Tales funciones tienen la mayor METRO y menos metro valores propios de la matriz de segundas derivadas (matriz de Hesse) difieren poco entre sí, es decir matriz norte(x) bien acondicionado. Recuerde que los valores propios l i, i
=1, …, norte, las matrices son las raíces de la ecuación característica Sin embargo, en la práctica, por regla general, las funciones que se minimizan tienen matrices de segundas derivadas mal condicionadas. (t/m<<
1). Los valores de tales funciones en algunas direcciones cambian mucho más rápido (a veces en varios órdenes de magnitud) que en otras direcciones. Sus superficies niveladas en el caso más simple están muy alargadas (Fig. 2.10), y en casos más complejos se doblan y parecen barrancos. Las funciones con tales propiedades se llaman quebrada. La dirección del antigradiente de estas funciones (ver Fig. 2.10) se desvía significativamente de la dirección al punto mínimo, lo que conduce a una desaceleración en la velocidad de convergencia. La tasa de convergencia de los métodos de gradiente también depende significativamente de la precisión de los cálculos de gradiente. La pérdida de precisión, que suele ocurrir en las proximidades de puntos mínimos o en una situación de barrancos, generalmente puede alterar la convergencia del proceso de descenso del gradiente. Por las razones anteriores, los métodos de gradiente se utilizan a menudo en combinación con otros métodos más eficaces en la etapa inicial de resolución de un problema. En este caso, el punto X está lejos del punto mínimo, y los pasos en la dirección del antigradiente permiten lograr una disminución significativa de la función. Los métodos de gradiente discutidos anteriormente encuentran el punto mínimo de una función en el caso general solo en un número infinito de iteraciones. El método del gradiente conjugado genera direcciones de búsqueda que son más consistentes con la geometría de la función que se minimiza. Esto aumenta significativamente la velocidad de su convergencia y permite, por ejemplo, minimizar la función cuadrática. f(x) = (x, Hx) + (b, x) + a con una matriz definida positiva simétrica norte en un número finito de pasos PAG, igual al número de variables de función. Cualquier función suave en las proximidades del punto mínimo puede aproximarse bien mediante una función cuadrática, por lo que los métodos de gradiente conjugado se utilizan con éxito para minimizar funciones no cuadráticas. En este caso dejan de ser finitos y se vuelven iterativos. Por definición, dos norte-vector dimensional X Y en llamado conjugado relativo a la matriz h(o h-conjugado), si el producto escalar (X, Bueno) = 0. Aquí norte - matriz definida positiva simétrica de tamaño PAG X PAG. Uno de los problemas más importantes en los métodos de gradiente conjugado es el problema de construir direcciones de manera eficiente. El método Fletcher-Reeves resuelve este problema transformando el antigradiente en cada paso. -f(x[k])
en la dirección pag[k],
h-conjugar con direcciones encontradas previamente R, R, ..., R[k-1]. Consideremos primero este método en relación con el problema de minimización.. función cuadrática R[k Direcciones ] se calcula utilizando las fórmulas: k] = -f'(x[k])
pag[ pag[k+bk-1 k>= 1; -l], pag = -’(X)
. F k valores b pag[k], R[k-1 se eligen para que las direcciones h-1] eran :
(pag[k], -conjugado[caballos de fuerza 1])= 0.
k- Como resultado, para la función cuadrática el proceso de minimización iterativo tiene la forma k+l] X[[k]=x[k], +a k p R[k] -
Dónde caballos de fuerza dirección de descenso a m paso; y k- Numero de pie. Este último se selecciona de la condición mínima de la función. A f(x) f(x[ k] + Por[k])
= f(x)[k] + en la dirección del movimiento, es decir, como resultado de resolver el problema de minimización unidimensional: [k])
. a k r Arkansas Para una función cuadrática X El algoritmo del método del gradiente conjugado de Fletcher-Reeves es el siguiente. pag = -f'(x)
. 1. En el punto caballos de fuerza calculado A 2. encendido .
m paso, usando las fórmulas anteriores, el paso se determina X[k+ 1]. k f(x)[k+1])
y punto f'(x[k+1])
. 3. Se calculan los valores. f'(x)
Y X[k 4. Si = 0, entonces punto+1] es el punto mínimo de la función pag[k f(x). De lo contrario, se determina una nueva dirección. PAG+l] de la relación y se lleva a cabo la transición a la siguiente iteración. Este procedimiento encontrará el mínimo de una función cuadrática en no más de pasos. X Al minimizar funciones no cuadráticas, el método de Fletcher-Reeves pasa de ser finito a iterativo. En este caso, después X[PAG(p+ el proceso de minimización iterativo tiene la forma k+l] La 1)ª iteración del procedimiento 1-4 se repite cíclicamente con reemplazo[k]=x[k],
] se calcula utilizando las fórmulas: k] en[k])+
+1] y los cálculos terminan en , donde es un número determinado. En este caso, se utiliza la siguiente modificación del método: caballos de fuerza 1 pag[k+bk-1 k>= 1; =x X); f(x[ k] + = -f’(x[k])
= f(x)[k] b[k];
p = -f'( a k p+ap a k p Aquí I- muchos índices: PAG= (0, norte, 2 p, salario, ...), es decir, el método se actualiza cada X pasos. R = Significado geométrico El método del gradiente conjugado es el siguiente (Fig. 2.11). Desde un punto de partida determinado X El descenso se realiza en dirección. -f"(x). En el punto X es el punto mínimo de la función en la dirección R,
Eso f'(x)
ortogonal al vector R. Entonces se encuentra el vector R , h-conjugado a R. A continuación, encontramos el mínimo de la función a lo largo de la dirección R etc. Los métodos de dirección conjugada se encuentran entre los más eficaces para resolver problemas de minimización. Sin embargo, cabe señalar que son sensibles a los errores que se producen durante el proceso de conteo. Con una gran cantidad de variables, el error puede aumentar tanto que el proceso deberá repetirse incluso para una función cuadrática, es decir, el proceso no siempre encaja en PAG= (0, norte, 2 El método de descenso más pronunciado (en la literatura inglesa “método de descenso más pronunciado”) es un método numérico iterativo (primer orden) para resolver problemas de optimización, que permite determinar el extremo (mínimo o máximo) de la función objetivo: De acuerdo con el método considerado, el extremo (máximo o mínimo) de la función objetivo se determina en la dirección del aumento (disminución) más rápido de la función, es decir en la dirección del gradiente (antigradiente) de la función. Función de gradiente en un punto donde i, j,…, n son vectores unitarios paralelos a los ejes de coordenadas. gradiente en el punto base El método de descenso más pronunciado es mayor desarrollo método de descenso de gradiente. En general, el proceso de encontrar el extremo de una función es un procedimiento iterativo, que se escribe de la siguiente manera: donde el signo "+" se usa para encontrar el máximo de una función y el signo "-" se usa para encontrar el mínimo de una función; Vector de dirección unitario, que está determinado por la fórmula: Una constante que determina el tamaño del paso y es la misma para todas las i-ésimas direcciones. El tamaño del paso se selecciona a partir de la condición del mínimo de la función objetivo f(x) en la dirección del movimiento, es decir, como resultado de resolver el problema de optimización unidimensional en la dirección del gradiente o antigradiente: En otras palabras, el tamaño del paso se determina resolviendo esta ecuación: Así, el paso de cálculo se elige de forma que el movimiento se realice hasta que la función mejore, llegando así en algún momento a un extremo. En este punto se vuelve a determinar la dirección de búsqueda (utilizando el gradiente) y se busca un nuevo punto óptimo de la función objetivo, etc. Por tanto, en este método, la búsqueda se produce en pasos más grandes y el gradiente de la función se calcula en un número menor de puntos. En el caso de una función de dos variables. este método tiene la siguiente interpretación geométrica: la dirección del movimiento desde un punto toca la línea de nivel en el punto . La trayectoria de descenso es en zigzag, con enlaces en zigzag adyacentes ortogonales entre sí. La condición para la ortogonalidad de los vectores de direcciones de descenso en puntos vecinos se escribe mediante la siguiente expresión: La trayectoria de movimiento hasta el punto extremo utilizando el método de descenso más pronunciado, que se muestra en la gráfica de la línea de igual nivel de la función f(x) La búsqueda de una solución óptima finaliza en el paso de cálculo iterativo (varios criterios): La trayectoria de búsqueda permanece en una pequeña vecindad del punto de búsqueda actual: El incremento de la función objetivo no cambia: El gradiente de la función objetivo en el punto mínimo local se vuelve cero: Cabe señalar que el método de descenso de gradiente resulta muy lento cuando se avanza por un barranco, y a medida que aumenta el número de variables en la función objetivo, este comportamiento del método se vuelve típico. El barranco es una depresión cuyas líneas de nivel tienen aproximadamente la forma de elipses con semiejes que difieren muchas veces. En presencia de un barranco, la trayectoria de descenso toma la forma de una línea en zigzag con un pequeño paso, por lo que la velocidad de descenso resultante al mínimo se ralentiza considerablemente. Esto se explica por el hecho de que la dirección del antigradiente de estas funciones se desvía significativamente de la dirección al punto mínimo, lo que provoca un retraso adicional en el cálculo. Como resultado, el algoritmo pierde eficiencia computacional. Función de barranco El método del gradiente, junto con sus numerosas modificaciones, está muy extendido y método efectivo buscando el óptimo de los objetos en estudio. La desventaja de la búsqueda de gradiente (así como los métodos discutidos anteriormente) es que cuando se usa, solo se puede detectar el extremo local de la función. para encontrar otros extremos locales es necesario buscar desde otros puntos de partida. También la velocidad de convergencia. métodos de gradiente También depende significativamente de la precisión de los cálculos del gradiente. La pérdida de precisión, que suele ocurrir en las proximidades de puntos mínimos o en una situación de barrancos, generalmente puede alterar la convergencia del proceso de descenso del gradiente. Método de cálculo Paso 1: Definición de expresiones analíticas (en forma simbólica) para calcular el gradiente de una función. Paso 2: establece la aproximación inicial Paso 3: Se determina la necesidad de reiniciar el procedimiento algorítmico para restablecer la última dirección de búsqueda. Como resultado del reinicio, se vuelve a buscar en la dirección del descenso más rápido.
 .
.
f(x)[k]–a k f’(x[k]))
= f(x)[k] – af"(x[k]))
.
j (a) = f(x)[k]-af"(x[k]))
.




![]() ,
,![]()
 .
.
![]() son los valores del argumento de la función (parámetros controlados) en el dominio real.
son los valores del argumento de la función (parámetros controlados) en el dominio real.![]() es un vector cuyas proyecciones sobre los ejes de coordenadas son las derivadas parciales de la función con respecto a las coordenadas:
es un vector cuyas proyecciones sobre los ejes de coordenadas son las derivadas parciales de la función con respecto a las coordenadas:![]() es estrictamente ortogonal a la superficie, y su dirección muestra la dirección del aumento más rápido de la función, y la dirección opuesta (antigradiente), respectivamente, muestra la dirección del descenso más rápido de la función.
es estrictamente ortogonal a la superficie, y su dirección muestra la dirección del aumento más rápido de la función, y la dirección opuesta (antigradiente), respectivamente, muestra la dirección del descenso más rápido de la función.

![]() - el módulo de gradiente determina la tasa de aumento o disminución de la función en la dirección del gradiente o antigradiente:
- el módulo de gradiente determina la tasa de aumento o disminución de la función en la dirección del gradiente o antigradiente:
![]()
![]()

![]()









