Kriteria Fisher
Kriteria Fisher digunakan untuk menguji hipotesis yang variansinya dua populasi umum, didistribusikan menurut hukum normal. Ini adalah kriteria parametrik.
Uji Fisher F disebut rasio varians karena dibentuk sebagai rasio dari dua estimasi varians yang tidak bias yang dibandingkan.
Misalkan diperoleh dua sampel sebagai hasil observasi. Dari mereka varians dan  memiliki
memiliki  Dan
Dan  derajat kebebasan. Kita asumsikan sampel pertama diambil dari populasi yang mempunyai varians
derajat kebebasan. Kita asumsikan sampel pertama diambil dari populasi yang mempunyai varians  , dan yang kedua dari populasi umum dengan varians
, dan yang kedua dari populasi umum dengan varians  . Hipotesis nol diajukan tentang persamaan dua varians, yaitu. H0:
. Hipotesis nol diajukan tentang persamaan dua varians, yaitu. H0:  atau . Untuk menolak hipotesis ini, perlu dibuktikan signifikansi perbedaannya pada tingkat signifikansi tertentu
atau . Untuk menolak hipotesis ini, perlu dibuktikan signifikansi perbedaannya pada tingkat signifikansi tertentu  .
.
Nilai kriteria dihitung dengan menggunakan rumus:
Jelasnya, jika variansnya sama, nilai kriterianya akan sama dengan satu. Dalam kasus lain akan lebih besar (kurang) dari satu.
Tes ini memiliki distribusi Fisher  . Uji Fisher - uji dua sisi, dan hipotesis nol
. Uji Fisher - uji dua sisi, dan hipotesis nol  ditolak demi alternatif lain
ditolak demi alternatif lain  Jika . Disini dimana
Jika . Disini dimana  – masing-masing volume sampel pertama dan kedua.
– masing-masing volume sampel pertama dan kedua.
Sistem STATISTICA menerapkan uji Fisher satu sisi, yaitu. varians maksimum selalu dianggap sebagai kualitas. Dalam hal ini, hipotesis nol ditolak dan digantikan dengan alternatif jika.
Contoh
Biarkan tugas ditetapkan untuk membandingkan efektivitas mengajar dua kelompok siswa. Tingkat pencapaian mencirikan tingkat pengelolaan proses pembelajaran, dan penyebarannya mencirikan kualitas pengelolaan pembelajaran, derajat pengorganisasian proses pembelajaran. Kedua indikator tersebut bersifat independen dan kasus umum harus dipertimbangkan bersama. Tingkat prestasi akademik (ekspektasi matematis) setiap kelompok siswa dicirikan oleh rata-rata aritmatika  dan , dan kualitas dicirikan oleh varians sampel estimasi yang sesuai: dan . Saat menilai tingkat kinerja saat ini, ternyata sama untuk kedua siswa:
dan , dan kualitas dicirikan oleh varians sampel estimasi yang sesuai: dan . Saat menilai tingkat kinerja saat ini, ternyata sama untuk kedua siswa:  = = 4.0. Varians sampel:
= = 4.0. Varians sampel: 
 Dan
Dan  . Jumlah derajat kebebasan yang sesuai dengan perkiraan ini:
. Jumlah derajat kebebasan yang sesuai dengan perkiraan ini:  Dan
Dan  . Dari sini untuk mengetahui perbedaan efektivitas pembelajaran dapat menggunakan stabilitas prestasi akademik, yaitu. Mari kita uji hipotesisnya.
. Dari sini untuk mengetahui perbedaan efektivitas pembelajaran dapat menggunakan stabilitas prestasi akademik, yaitu. Mari kita uji hipotesisnya.
Mari kita hitung  (harus ada selisih yang besar pada pembilangnya), . Menurut tabel ( STATISTIK –
KemungkinanDistribusiKalkulator)
kami menemukan , yang lebih kecil dari yang dihitung, oleh karena itu hipotesis nol harus ditolak demi alternatifnya. Kesimpulan ini mungkin tidak memuaskan peneliti, karena dia tertarik pada nilai sebenarnya dari rasio tersebut
(harus ada selisih yang besar pada pembilangnya), . Menurut tabel ( STATISTIK –
KemungkinanDistribusiKalkulator)
kami menemukan , yang lebih kecil dari yang dihitung, oleh karena itu hipotesis nol harus ditolak demi alternatifnya. Kesimpulan ini mungkin tidak memuaskan peneliti, karena dia tertarik pada nilai sebenarnya dari rasio tersebut  (kami selalu memiliki varians yang besar pada pembilangnya). Saat memeriksa kriteria satu sisi, kami memperoleh nilai yang lebih kecil dari nilai yang dihitung di atas. Jadi, hipotesis nol harus ditolak demi alternatifnya.
(kami selalu memiliki varians yang besar pada pembilangnya). Saat memeriksa kriteria satu sisi, kami memperoleh nilai yang lebih kecil dari nilai yang dihitung di atas. Jadi, hipotesis nol harus ditolak demi alternatifnya.
Tes Fisher dalam program STATISTICA di lingkungan Windows
Untuk contoh pengujian hipotesis (kriteria Fisher), kami menggunakan (membuat) file dengan dua variabel (fisher.sta):
Beras. 1. Tabel dengan dua variabel independen
Untuk menguji hipotesis diperlukan statistik dasar ( DasarStatistikDanTabel) pilih uji-t untuk variabel independen. ( uji-t, independen, berdasarkan variabel).

Beras. 2. Menguji hipotesis parametrik
Setelah memilih variabel dan menekan tombol Ringkasan Nilai simpangan baku dan kriteria Fisher dihitung. Selain itu, tingkat signifikansinya ditentukan P, yang perbedaannya tidak signifikan.

Beras. 3. Hasil Uji Hipotesis (Uji F)
Menggunakan KemungkinanKalkulator dan dengan mengatur nilai parameter, Anda dapat membuat grafik distribusi Fisher dengan nilai terhitung yang ditandai.

Beras. 4. Daerah penerimaan (penolakan) hipotesis (kriteria F)
Sumber.
Menguji hipotesis tentang hubungan antara dua varians
URL: /tryfonov3/terms3/testdi.htm
Kuliah 6. :8080/resources/math/mop/lections/lection_6.htm
F – Kriteria Fisher
URL: /home/portal/applications/Multivariatadvisor/F-Fisher/F-Fisheer.htm
Teori dan praktek penelitian statistik probabilistik.
URL: /aktif/referats/read/doc-3663-1.html
F – Kriteria Fisher
Kriteria Fisher memungkinkan Anda membandingkan varians sampel dari dua sampel independen. Untuk menghitung F emp, Anda perlu mencari perbandingan varians dua sampel, sehingga varians yang lebih besar ada di pembilangnya, dan varians yang lebih kecil ada di penyebutnya. Rumus untuk menghitung kriteria Fisher adalah:
di mana masing-masing varians sampel pertama dan kedua.
Karena menurut syarat kriteria, nilai pembilang harus lebih besar atau sama dengan nilai penyebut, maka nilai F emp akan selalu lebih besar atau sama dengan satu.
Besarnya derajat kebebasan juga ditentukan secara sederhana:
k 1 =n aku - 1 untuk sampel pertama (yaitu untuk sampel yang variansnya lebih besar) dan k 2 = N 2 - 1 untuk sampel kedua.
Pada Lampiran 1, nilai kritis kriteria Fisher ditentukan oleh nilai k 1 (baris atas tabel) dan k 2 (kolom kiri tabel).
Jika t em >t krit, maka hipotesis nol diterima, sebaliknya alternatif diterima.
Contoh 3. Pengujian dilakukan di dua kelas tiga perkembangan mental sepuluh siswa pada tes TURMSH. Nilai rata-rata yang diperoleh tidak berbeda secara signifikan, namun psikolog tertarik pada pertanyaan apakah terdapat perbedaan derajat homogenitas indikator perkembangan mental antar kelas.
Larutan. Untuk uji Fisher, perlu dilakukan perbandingan varians nilai tes pada kedua kelas. Hasil pengujian disajikan dalam tabel:
Tabel 3.
|
Jumlah siswa |
Kelas satu |
Kelas kedua |
Setelah menghitung varians variabel X dan Y, diperoleh:
S X 2 =572,83; S kamu 2 =174,04
Kemudian, dengan menggunakan rumus (8) untuk perhitungan menggunakan kriteria F Fisher, kita menemukan:
![]()
Berdasarkan tabel Lampiran 1 untuk kriteria F dengan derajat kebebasan pada kedua kasus sama dengan k = 10 - 1 = 9, kita peroleh F crit = 3,18 (<3.29), следовательно, в терминах статистических гипотез можно утверждать, что Н 0 (гипотеза о сходстве) может быть отвергнута на уровне 5%, а принимается в этом случае гипотеза Н 1 . Иcследователь может утверждать, что по степени однородности такого показателя, как умственное развитие, имеется различие между выборками из двух классов.
6.2 Tes nonparametrik
Dengan membandingkan secara kasat mata (dalam persentase) hasil sebelum dan sesudah dampak apa pun, peneliti sampai pada kesimpulan bahwa jika ada perbedaan yang diamati, maka ada perbedaan dalam sampel yang dibandingkan. Pendekatan ini secara kategoris tidak dapat diterima, karena tidak mungkin menentukan tingkat keandalan perbedaan berdasarkan persentase. Persentase yang diambil sendiri tidak memungkinkan kita untuk menarik kesimpulan yang dapat diandalkan secara statistik. Untuk membuktikan efektivitas intervensi apa pun, perlu untuk mengidentifikasi tren bias (pergeseran) indikator yang signifikan secara statistik. Untuk mengatasi masalah tersebut, seorang peneliti dapat menggunakan sejumlah kriteria diskriminasi. Di bawah ini kita akan membahas uji non-parametrik: uji tanda dan uji chi-kuadrat.
)Perhitungan kriteria φ*
1. Tentukan nilai-nilai atribut yang akan menjadi kriteria untuk membagi subjek menjadi yang “berpengaruh” dan yang “tidak berpengaruh”. Jika karakteristik diukur secara kuantitatif, gunakan kriteria λ untuk mencari titik pisah optimal.
2. Gambarlah tabel empat sel (sinonim: empat bidang) yang terdiri dari dua kolom dan dua baris. Kolom pertama adalah “ada efek”; kolom kedua - “tidak berpengaruh”; baris pertama dari atas - 1 grup (sampel); baris kedua - grup 2 (sampel).
4. Hitung jumlah subjek dalam sampel pertama yang “tidak berpengaruh” dan masukkan nomor ini di sel kanan atas tabel. Hitung jumlah dua sel teratas. Jumlahnya harus sesuai dengan jumlah mata pelajaran pada kelompok pertama.
6. Hitung jumlah subjek dalam sampel kedua yang “tidak berpengaruh” dan masukkan nomor ini di sel kanan bawah tabel. Hitung jumlah dua sel yang lebih rendah. Harus sesuai dengan jumlah subjek pada kelompok kedua (sampel).
7. Menentukan persentase subjek yang “berpengaruh” dengan menghubungkan jumlah subjek dengan jumlah subjek dalam suatu kelompok (sampel) tertentu. Tuliskan persentase yang dihasilkan masing-masing di sel kiri atas dan kiri bawah tabel dalam tanda kurung, agar tidak tertukar dengan nilai absolut.
8. Periksa apakah salah satu persentase yang dibandingkan sama dengan nol. Jika demikian, coba ubah dengan memindahkan titik pemisahan grup ke satu arah atau lainnya. Jika hal ini tidak mungkin atau tidak diinginkan, tinggalkan kriteria φ* dan gunakan kriteria χ2.
9. Tentukan berdasarkan Tabel. XII Lampiran 1 sudut φ untuk masing-masing persentase yang dibandingkan.
dimana: φ1 - sudut yang sesuai dengan persentase yang lebih besar;
φ2 - sudut yang sesuai dengan persentase yang lebih kecil;
N1 - jumlah observasi pada sampel 1;
N2 - jumlah observasi pada sampel 2.
11. Bandingkan nilai yang diperoleh φ* dengan nilai kritis: φ* ≤1.64 (p<0,05) и φ* ≤2,31 (р<0,01).
Jika φ*emp ≤φ*cr. H0 ditolak.
Jika perlu, tentukan tingkat signifikansi yang tepat dari φ*emp yang dihasilkan sesuai Tabel. XIII Lampiran 1.
Metode ini dijelaskan dalam banyak manual (Plokhinsky N.A., 1970; Gubler E.V., 1978; Ivanter E.V., Korosov A.V., 1992, dll.) Uraian ini didasarkan pada versi metode yang dikembangkan dan disajikan oleh E.V. Gubler.
Tujuan kriteria φ*
Kriteria Fisher dimaksudkan untuk membandingkan dua sampel menurut frekuensi terjadinya efek (indikator) yang menarik bagi peneliti. Semakin besar, semakin dapat diandalkan perbedaannya.
Deskripsi kriteria
Kriteria tersebut mengevaluasi keandalan perbedaan antara persentase dua sampel di mana efek (indikator) yang menarik bagi kami dicatat. Secara kiasan, kami membandingkan 2 potongan terbaik yang dipotong dari 2 pai dan memutuskan mana yang benar-benar lebih besar.
Inti dari transformasi sudut Fisher adalah mengubah persentase menjadi nilai sudut pusat, yang diukur dalam radian. Persentase yang lebih besar akan menunjukkan sudut φ yang lebih besar, dan persentase yang lebih kecil akan menunjukkan sudut yang lebih kecil, namun hubungan di sini tidak linier:
dimana P adalah persentase yang dinyatakan dalam pecahan suatu satuan (lihat Gambar 5.1).
Dengan meningkatnya perbedaan antara sudut φ 1 dan φ 2 dan bertambahnya jumlah sampel maka nilai kriterianya pun bertambah. Semakin besar nilai φ* maka semakin besar kemungkinan terjadinya perbedaan yang signifikan.
Hipotesis
H 0 : Proporsi orang, di mana efek yang dipelajari memanifestasikan dirinya, tidak ada lagi di sampel 1 daripada di sampel 2.
H 1 : Proporsi individu yang menunjukkan efek yang diteliti lebih besar pada sampel 1 dibandingkan sampel 2.
Representasi grafis dari kriteria φ*
Metode transformasi sudut agak lebih abstrak dibandingkan kriteria lainnya.
Rumus yang diikuti oleh EV Gubler ketika menghitung nilai φ mengasumsikan bahwa 100% membentuk sudut φ=3,142, yaitu nilai yang dibulatkan π=3,14159... Hal ini memungkinkan kami untuk menyajikan sampel yang dibandingkan dalam bentuk dua setengah lingkaran yang masing-masing melambangkan 100% populasi sampelnya. Persentase subjek dengan “efek” akan direpresentasikan sebagai sektor yang dibentuk oleh sudut pusat φ. Pada Gambar. Gambar 5.2 menunjukkan dua setengah lingkaran yang mengilustrasikan Contoh 1. Pada sampel pertama, 60% subjek menyelesaikan soal. Persentase ini sesuai dengan sudut φ=1,772. Pada sampel kedua, 40% subjek menyelesaikan masalahnya. Persentase ini sesuai dengan sudut φ =1,369.
Kriteria φ* memungkinkan Anda menentukan apakah salah satu sudut memang secara statistik lebih besar dibandingkan sudut lainnya untuk ukuran sampel tertentu.
Keterbatasan kriteria φ*
1. Tak satu pun dari proporsi yang dibandingkan harus nol. Secara formal, tidak ada kendala dalam penerapan metode dalam kasus di mana proporsi pengamatan pada salah satu sampel sama dengan 0. Namun, dalam kasus ini, hasilnya mungkin meningkat secara tidak wajar (Gubler E.V., 1978, hal. .86).
2. Atas tidak ada batasan dalam kriteria φ - sampel bisa sebesar yang diinginkan.
Lebih rendah batasnya adalah 2 pengamatan di salah satu sampel. Namun perbandingan jumlah dua sampel berikut harus diperhatikan:
a) jika satu sampel hanya memiliki 2 observasi, maka sampel kedua harus memiliki minimal 30:
b) jika salah satu sampel hanya memiliki 3 observasi, maka sampel kedua harus memiliki minimal 7:
c) jika salah satu sampel hanya memiliki 4 observasi, maka sampel kedua harus memiliki minimal 5:
d) diN 1 , N 2 ≥ 5 Perbandingan apa pun bisa dilakukan.
Pada prinsipnya, sampel yang tidak memenuhi kondisi ini juga dapat dibandingkan, misalnya dengan relasiN 1 =2, N 2 = 15, namun dalam kasus ini perbedaan yang signifikan tidak dapat diidentifikasi.
Kriteria φ* tidak memiliki batasan lain.
Mari kita lihat beberapa contoh untuk mengilustrasikan kemungkinannyakriteria φ*.
Contoh 1: perbandingan sampel menurut karakteristik yang ditentukan secara kualitatif.
Contoh 2: perbandingan sampel menurut karakteristik yang diukur secara kuantitatif.
Contoh 3: perbandingan sampel baik berdasarkan tingkat maupun sebaran suatu karakteristik.
Contoh 4: Menggunakan kriteria φ* yang digabungkan dengan kriteriaX Kolmogorov-Smirnov untuk mencapai hasil yang paling akurat.
Contoh 1 - perbandingan sampel menurut karakteristik yang ditentukan secara kualitatif
Dalam penggunaan kriteria ini, kami membandingkan persentase subjek dalam satu sampel yang memiliki kualitas tertentu dengan persentase subjek dalam sampel lain yang memiliki kualitas yang sama.
Katakanlah kita tertarik pada apakah dua kelompok siswa berbeda dalam keberhasilan mereka dalam memecahkan masalah eksperimen baru. Pada kelompok pertama yang terdiri dari 20 orang, 12 orang mengatasinya, dan pada sampel kedua yang terdiri dari 25 orang - 10. Dalam kasus pertama, persentase mereka yang menyelesaikan masalah adalah 20/12·100%=60%, dan pada 25/10·100%= 40% kedua. Apakah persentase ini berbeda secara signifikan berdasarkan data yang ada?N 1 DanN 2 ?
Tampaknya bahkan “dengan mata” seseorang dapat menentukan bahwa 60% jauh lebih tinggi dari 40%. Namun, pada kenyataannya, perbedaan-perbedaan ini, mengingat datanyaN 1 , N 2 tidak bisa diandalkan.
Mari kita periksa. Karena kita tertarik pada fakta pemecahan suatu masalah, kita akan menganggap keberhasilan dalam memecahkan masalah eksperimental sebagai “efek”, dan kegagalan dalam menyelesaikannya sebagai tidak adanya efek.
Mari kita merumuskan hipotesis.
H 0 : Proporsi orangJumlah orang yang menyelesaikan tugas pada kelompok pertama tidak lebih banyak dibandingkan pada kelompok kedua.
H 1 : Proporsi orang yang menyelesaikan tugas pada kelompok pertama lebih besar dibandingkan pada kelompok kedua.
Sekarang mari kita buat apa yang disebut tabel empat sel, atau empat bidang, yang sebenarnya merupakan tabel frekuensi empiris untuk dua nilai atribut: "ada efek" - "tidak ada efek".
Tabel 5.1
Tabel empat sel untuk menghitung kriteria ketika membandingkan dua kelompok mata pelajaran menurut persentase mereka yang memecahkan masalah.
Grup | “Ada efeknya”: masalah terpecahkan | "Tidak berpengaruh": masalah tidak terpecahkan | Jumlah |
||||
Kuantitas mata pelajaran | % membagikan | Kuantitas mata pelajaran | % membagikan | ||||
1 kelompok | (60%) | (40%) | |||||
kelompok ke-2 | (40%) | (60%) | |||||
Jumlah | |||||||
Dalam tabel empat sel, biasanya, kolom "Ada efek" dan "Tidak ada efek" ditandai di bagian atas, dan baris "Grup 1" dan "Grup 2" ada di sebelah kiri. Faktanya, hanya bidang (sel) A dan B yang terlibat dalam perbandingan, yaitu persentase di kolom “Ada pengaruhnya”.
Menurut Tabel.XIILampiran 1 menentukan nilai φ yang sesuai dengan persentase bagian di masing-masing kelompok.
Sekarang mari kita hitung nilai empiris φ* menggunakan rumus:
di mana φ 1 - sudut yang sesuai dengan % bagian yang lebih besar;
φ 2 - sudut yang sesuai dengan % bagian yang lebih kecil;
N 1 - jumlah observasi pada sampel 1;
N 2 - jumlah observasi pada sampel 2.
Pada kasus ini:
Menurut Tabel.XIIIDalam Lampiran 1 kita menentukan tingkat signifikansi yang sesuai dengan φ* em=1,34:
p = 0,09
Dimungkinkan juga untuk menetapkan nilai kritis φ* sesuai dengan tingkat yang diterima dalam psikologi signifikansi statistik:
Mari kita membangun "sumbu signifikansi".
Nilai empiris yang diperoleh φ* berada pada zona tidak signifikan.
Menjawab: H 0 diterima. Persentase orang yang menyelesaikan tugasVkelompok pertama tidak lebih dari kelompok kedua.
Seseorang hanya dapat bersimpati dengan peneliti yang menganggap perbedaan 20% dan bahkan 10% signifikan tanpa memeriksa keandalannya menggunakan kriteria *. Dalam kasus ini, misalnya, hanya perbedaan minimal 24,3% yang dianggap signifikan.
Tampaknya ketika membandingkan dua sampel berdasarkan kualitatif apa pun, kriteria φ bisa membuat kita sedih daripada bahagia. Apa yang tampak signifikan mungkin tidak demikian jika dilihat dari sudut pandang statistik.
Kriteria Fisher memiliki lebih banyak peluang untuk menyenangkan peneliti ketika kita membandingkan dua sampel menurut karakteristik yang diukur secara kuantitatif dan dapat memvariasikan “efeknya”.
Contoh 2 - perbandingan dua sampel menurut karakteristik yang diukur secara kuantitatif
Dalam penggunaan kriteria ini, kami membandingkan persentase subjek dalam satu sampel yang mencapai tingkat nilai atribut tertentu dengan persentase subjek yang mencapai tingkat tersebut di sampel lain.
Dalam penelitian yang dilakukan oleh G. A. Tlegenova (1990), dari 70 siswa muda sekolah kejuruan berusia 14 sampai 16 tahun, dipilih 10 mata pelajaran dengan nilai skala Agresi tinggi dan 11 mata pelajaran dengan nilai skala Agresi rendah. dari survei menggunakan Kuesioner Kepribadian Freiburg. Penting untuk mengetahui apakah kelompok remaja putra yang agresif dan non-agresif berbeda dalam hal jarak yang mereka pilih secara spontan dalam percakapan dengan sesama siswa. Data G. A. Tlegenova disajikan pada Tabel. 5.2. Anda dapat memperhatikan bahwa remaja putra yang agresif lebih sering memilih jarak 50cm atau bahkan kurang, sedangkan anak laki-laki yang tidak agresif lebih sering memilih jarak lebih dari 50 cm.
Sekarang kita dapat menganggap jarak 50 cm sebagai jarak kritis dan berasumsi bahwa jika jarak yang dipilih oleh subjek kurang dari atau sama dengan 50 cm, maka “ada efek”, dan jika jarak yang dipilih lebih besar dari 50 cm, maka “tidak ada efeknya.” Kita melihat bahwa pada kelompok remaja putra yang agresif, efeknya diamati pada 7 dari 10, yaitu pada 70% kasus, dan pada kelompok remaja putra yang tidak agresif - pada 2 dari 11, yaitu pada 18,2% kasus. . Persentase ini dapat dibandingkan dengan menggunakan metode φ* untuk menentukan signifikansi perbedaan di antara keduanya.
Tabel 5.2
Indikator jarak (dalam cm) yang dipilih oleh remaja putra agresif dan non-agresif dalam percakapan dengan sesama siswa (menurut G.A. Tlegenova, 1990)
Kelompok 1: anak laki-laki dengan skor tinggi pada skala AgresiFPI- R (N 1 =10) | Kelompok 2: anak laki-laki dengan nilai skala Agresi yang rendahFPI- R (N 2 =11) |
|||
d(c M ) | % membagikan | d(c M ) | % membagikan |
|
"Makan Memengaruhi" D≤50cm | ||||
18,2% |
||||
"TIDAK memengaruhi" d>50 cm | ||||
80 QO | 81,8% |
|||
Jumlah | 100% | 100% |
||
Rata-rata | 5b:o | 77.3 | ||
Mari kita merumuskan hipotesis.
H 0 D ≤ 50 cm, pada kelompok anak laki-laki agresif jumlahnya tidak lebih banyak dibandingkan pada kelompok anak laki-laki non-agresif.
H 1 : Proporsi masyarakat yang memilih jarakD≤ 50 cm, lebih banyak pada kelompok remaja putra agresif dibandingkan pada kelompok remaja putra non agresif. Sekarang mari kita buat apa yang disebut tabel empat sel.
Tabel 53
Tabel empat sel untuk menghitung kriteria φ* saat membandingkan kelompok agresif (nf=10) dan remaja putra yang tidak agresif (n2=11)
Grup | "Ada efeknya": D≤50 | "Tidak berpengaruh." D>50 | Jumlah |
||||
Jumlah mata pelajaran | (% membagikan) | Jumlah mata pelajaran | (% membagikan) | ||||
Grup 1 - pria muda yang agresif | (70%) | (30%) | |||||
Kelompok 2 - remaja putra yang tidak agresif | (180%) | (81,8%) | |||||
Jumlah | |||||||
Menurut Tabel.XIILampiran 1 menentukan nilai φ yang sesuai dengan persentase bagian “efek” di masing-masing kelompok.
Nilai empiris φ* yang diperoleh berada pada zona signifikansi.
Menjawab: H 0 ditolak. DiterimaH 1 . Proporsi orang yang memilih jarak percakapan kurang dari atau sama dengan 50 cm lebih besar pada kelompok remaja putra agresif dibandingkan pada kelompok remaja putra non-agresif.
Berdasarkan hasil yang diperoleh, dapat disimpulkan bahwa remaja putra yang lebih agresif lebih sering memilih jarak kurang dari setengah meter, sedangkan remaja putra yang tidak agresif lebih sering memilih jarak lebih dari setengah meter. Kita melihat bahwa remaja putra yang agresif sebenarnya berkomunikasi di perbatasan antara zona intim (0-46 cm) dan zona pribadi (dari 46 cm). Namun, kita ingat bahwa jarak intim antar pasangan bukan hanya merupakan hak prerogatif dari hubungan yang dekat dan baik, tetapi juga merupakan hak prerogratif dari hubungan yang dekat dan baikDanpertarungan tangan kosong (AulaE. T., 1959).
Contoh 3 - perbandingan sampel baik berdasarkan tingkat maupun sebaran karakteristiknya.
Dalam kasus penggunaan ini, pertama-tama kita dapat menguji apakah kelompok-kelompok tersebut berbeda dalam tingkat beberapa sifat dan kemudian membandingkan distribusi sifat dalam dua sampel. Tugas seperti itu mungkin relevan ketika menganalisis perbedaan dalam rentang atau bentuk distribusi penilaian yang diperoleh subjek dengan menggunakan teknik baru.
Dalam studi yang dilakukan oleh R. T. Chirkina (1995), untuk pertama kalinya, kuesioner digunakan yang bertujuan untuk mengidentifikasi kecenderungan untuk menyembunyikan fakta, nama, niat dan metode tindakan dari ingatan karena kompleks pribadi, keluarga dan profesional. Kuesioner dibuat dengan partisipasi EV Sidorenko berdasarkan bahan dari buku 3. Freud “Psychopathology of Everyday Life”. Sampel sebanyak 50 mahasiswa Institut Pedagogis, belum menikah, tanpa anak, berusia 17 hingga 20 tahun, diperiksa dengan menggunakan kuesioner ini, serta teknik Menester-Corzini untuk mengidentifikasi intensitas perasaan kekurangan pribadi,atau"kompleks inferioritas" (ManajerG. J., KorsiniR. J., 1982).
Hasil survei disajikan pada Tabel. 5.4.
Bisakah kita mengatakan bahwa ada hubungan yang signifikan antara indikator energi represi yang didiagnosis dengan kuesioner dan indikator intensitas perasaan kekurangan diri?
Tabel 5.4
Indikator intensitas perasaan kekurangan pribadi pada kelompok siswa dengan tinggi (nj=18) dan energi perpindahan rendah (n2=24).
Kelompok 1: energi perpindahan dari 19 ke 31 titik (N 1 =181 | Golongan 2: energi perpindahan dari 7 menjadi 13 titik (N 2 =24) |
|
0; 0; 0; 0; 0 20; 20 30; 30; 30; 30; 30; 30; 30 50; 50 60; 60 | 0; 0 5; 5; 5; 5 10; 10; 10; 10; 10; 10 15; 15 20; 20; 20; 20 30; 30; 30; 30; 30; 30 |
|
Jumlah Rata-rata | 26,11 | 15,42 |
Terlepas dari kenyataan bahwa nilai rata-rata pada kelompok dengan represi yang lebih energik lebih tinggi, 5 nilai nol juga diamati di dalamnya. Jika kita membandingkan histogram distribusi peringkat dalam dua sampel, terdapat perbedaan yang mencolok di antara keduanya (Gbr. 5.3).
Untuk membandingkan dua distribusi kita dapat menerapkan pengujianχ 2 atau kriteriaλ , tetapi untuk ini kita harus memperbesar peringkatnya, dan sebagai tambahan, di kedua sampelN <30.
Kriteria φ* akan memungkinkan kita untuk memeriksa pengaruh perbedaan antara dua distribusi yang diamati pada grafik jika kita setuju untuk berasumsi bahwa “ada pengaruh” jika indikator perasaan tidak mencukupi sangat rendah (0) atau, sebaliknya. , nilai yang sangat tinggi (S30), dan “tidak ada pengaruhnya” jika indikator perasaan tidak mencukupi mengambil nilai rata-rata, dari 5 hingga 25.
Mari kita merumuskan hipotesis.
H 0 : Nilai ekstrim dari indeks defisiensi (baik 0 atau 30 atau lebih) pada kelompok dengan represi yang lebih energik tidak lebih umum dibandingkan pada kelompok dengan represi yang kurang energik.
H 1 : Nilai ekstrim dari indeks defisiensi (baik 0 atau 30 atau lebih) pada kelompok dengan represi yang lebih energik lebih sering terjadi dibandingkan pada kelompok dengan represi yang kurang energik.
Mari kita buat tabel empat sel yang sesuai untuk penghitungan kriteria φ* lebih lanjut.
Tabel 5.5
Tabel empat sel untuk menghitung kriteria φ* ketika membandingkan kelompok dengan energi represi lebih tinggi dan lebih rendah berdasarkan rasio indikator ketidakcukupan
Grup | “Ada pengaruh”: indikator defisiensi adalah 0 atau >30 | “Tidak berpengaruh”: indeks kegagalan dari 5 hingga 25 | Jumlah |
||
(88,9%) | (11,1%) | ||||
(33,3%) | (66,7%) | ||||
Jumlah | |||||
Menurut Tabel.XIIDalam Lampiran 1 kami menentukan nilai φ yang sesuai dengan persentase yang dibandingkan:
Mari kita hitung nilai empiris φ*:
Nilai kritis φ* untuk apapunN 1 , N 2 , seperti yang kita ingat dari contoh sebelumnya, adalah:
MejaXIIILampiran 1 memungkinkan kita untuk lebih akurat menentukan tingkat signifikansi dari hasil yang diperoleh: hal<0,001.
Menjawab: H 0 ditolak. DiterimaH 1 . Nilai ekstrim dari indeks defisiensi (0 atau 30 atau lebih) pada kelompok dengan energi represi lebih besar lebih sering terjadi dibandingkan pada kelompok dengan energi represi lebih kecil.
Jadi, subjek dengan energi represi yang lebih besar dapat memiliki indikator perasaan tidak mampu yang sangat tinggi (30 atau lebih) dan sangat rendah (nol). Dapat diasumsikan bahwa mereka menekan ketidakpuasan dan kebutuhan akan kesuksesan dalam hidup. Asumsi ini memerlukan pengujian lebih lanjut.
Hasil yang diperoleh, apapun interpretasinya, menegaskan kemampuan kriteria * dalam menilai perbedaan bentuk sebaran suatu sifat pada dua sampel.
Terdapat 50 orang dalam sampel asli, namun 8 orang di antaranya dikeluarkan dari pertimbangan karena memiliki skor rata-rata pada indeks energi represi (14-15). Indikator intensitas perasaan tidak mencukupi juga rata-rata: 6 nilai masing-masing 20 poin dan 2 nilai masing-masing 25 poin.
Kemampuan kuat dari kriteria φ* dapat diverifikasi dengan mengkonfirmasi hipotesis yang sama sekali berbeda ketika menganalisis materi dalam contoh ini. Kita dapat membuktikan, misalnya, bahwa dalam kelompok dengan energi represi yang lebih besar, tingkat insufisiensi masih lebih tinggi, meskipun distribusinya dalam kelompok ini bersifat paradoks.
Mari kita merumuskan hipotesis baru.
H 0 Nilai indeks defisiensi tertinggi (30 atau lebih) pada kelompok dengan energi represi lebih besar tidak lebih umum dibandingkan pada kelompok dengan energi represi lebih kecil.
H 1 : Nilai indeks defisiensi tertinggi (30 atau lebih) pada kelompok dengan energi represi lebih besar lebih sering terjadi dibandingkan pada kelompok dengan energi represi lebih kecil. Mari buat tabel empat bidang menggunakan data di Tabel. 5.4.
Tabel 5.6
Tabel empat sel untuk menghitung kriteria φ* saat membandingkan kelompok dengan energi represi lebih besar dan lebih kecil menurut indikator tingkat ketidakcukupan
Grup | “Ada pengaruhnya”* indikator kegagalan lebih besar atau sama dengan 30 | “Tidak berpengaruh”: tingkat kegagalan lebih rendah 30 | Jumlah |
||
Grup 1 - dengan energi perpindahan lebih besar | (61,1%) | (38.9%) | |||
Grup 2 - dengan energi perpindahan lebih rendah | (25.0%) | (75.0%) | |||
Jumlah | |||||
Menurut Tabel.XIIIPada Lampiran 1 kami menentukan bahwa hasil ini sesuai dengan tingkat signifikansi p = 0,008.
Menjawab: Tapi itu ditolak. DiterimaHj: Indikator defisiensi tertinggi (30 poin atau lebih) dalam kelompokDengandengan energi perpindahan lebih besar lebih sering terjadi dibandingkan kelompok dengan energi perpindahan lebih kecil (p = 0,008).
Jadi, kami bisa membuktikannyaVkelompokDengandengan represi yang lebih energik, nilai ekstrim dari indikator ketidakcukupan mendominasi, dan fakta bahwa indikator ini melebihi nilainyamencapaitepatnya di grup ini.
Sekarang kita dapat mencoba membuktikan bahwa pada kelompok dengan energi represi yang lebih tinggi, nilai indeks insufisiensi yang lebih rendah lebih umum terjadi, meskipun faktanya nilai rata-rataV kelompok ini memiliki lebih banyak (26,11 berbanding 15,42 dalam kelompokDengan perpindahan yang lebih kecil).
Mari kita merumuskan hipotesis.
H 0 : Tingkat defisiensi terendah (nol) dalam kelompokDengan represi dengan energi yang lebih besar tidak lebih umum terjadi dibandingkan pada kelompokDengan energi perpindahan yang lebih sedikit.
H 1 : Tingkat defisiensi terendah (nol) terjadiV kelompok dengan energi represi lebih besar lebih sering daripada kelompokDengan represi yang kurang energik. Mari kelompokkan data ke dalam tabel empat sel baru.
Tabel 5.7
Tabel empat sel untuk membandingkan kelompok dengan energi represi berbeda berdasarkan frekuensi nilai nol dari indikator defisiensi
Grup | “Ada efek”: indikator kegagalan adalah 0 | "Tidak ada efek" dari ketidakcukupan | indikator tidak sama dengan 0 | Jumlah |
|
Grup 1 - dengan energi perpindahan lebih besar | (27,8%) | (72,2%) | |||
1 kelompok - dengan energi perpindahan yang lebih sedikit | (8,3%) | (91,7%) | |||
Jumlah | |||||
Kita tentukan nilai φ dan hitung nilai φ*:
Menjawab: H 0 ditolak. Indeks ketidakcukupan terendah (nol) pada kelompok dengan energi represi lebih besar lebih umum terjadi dibandingkan pada kelompok dengan energi represi lebih kecil (p<0,05).
Secara total, hasil yang diperoleh dapat dianggap sebagai bukti kebetulan parsial dari konsep kompleks S. Freud dan A. Adler.
Hal ini signifikan bahwa antara indikator energi represi dengan indikator intensitas perasaan tidak mampu pada sampel secara keseluruhan diperoleh korelasi linier positif (p = +0,491, p<0,01). Как мы можем убедиться, применение критерия φ* позволяет проникнуть в более тонкие и содержательно значимые соотношения между этими двумя показателями.
Contoh 4 - menggunakan kriteria φ* yang dikombinasikan dengan kriteria λ Kolmogorov-Smirnov untuk mencapai hasil maksimal tepathasil
Jika sampel dibandingkan menurut indikator apa pun yang diukur secara kuantitatif, maka timbul masalah dalam mengidentifikasi titik distribusi yang dapat digunakan sebagai titik kritis dalam membagi semua subjek menjadi subjek yang “mempunyai pengaruh” dan subjek yang “tidak mempunyai pengaruh”.
Pada prinsipnya, titik di mana kita akan membagi kelompok menjadi subkelompok di mana terdapat pengaruh dan tidak ada pengaruh dapat dipilih secara sewenang-wenang. Kita bisa tertarik pada efek apa pun dan, oleh karena itu, kita bisa membagi kedua sampel menjadi dua bagian kapan saja, asalkan masuk akal.
Namun, untuk memaksimalkan kekuatan uji φ*, perlu untuk memilih titik di mana perbedaan antara dua kelompok yang dibandingkan paling besar. Paling akurat, kita dapat melakukan ini dengan menggunakan algoritma untuk menghitung kriteriaλ , memungkinkan Anda mendeteksi titik perbedaan maksimum antara dua sampel.
Kemungkinan menggabungkan kriteria φ* danλ dijelaskan oleh E.V. Gubler (1978, hlm. 85-88). Mari kita coba menggunakan cara ini untuk menyelesaikan soal berikut.
Dalam studi bersama oleh M.A. Kurochkina, E.V. Sidorenko dan Yu.A. Churakov (1992) di Inggris melakukan survei terhadap dokter umum di Inggris dalam dua kategori: a) dokter yang mendukung reformasi medis dan telah mengubah kantor penerimaan mereka menjadi organisasi pemegang dana dengan anggaran mereka sendiri; b) dokter yang kantornya masih belum mempunyai dana sendiri dan seluruhnya ditanggung oleh APBN. Kuesioner dikirim ke sampel 200 dokter, yang mewakili populasi umum dokter Inggris dalam hal keterwakilan orang-orang dari berbagai jenis kelamin, usia, masa kerja dan tempat kerja - di kota-kota besar atau di provinsi.
Kuesioner dijawab oleh 78 orang dokter, 50 orang di antaranya bekerja di ruang tunggu dengan dana dan 28 orang di ruang tunggu tanpa dana. Masing-masing dokter harus memperkirakan berapa porsi penerimaan dana pada tahun depan, 1993. Hanya 70 dokter dari 78 dokter yang mengirimkan jawaban yang menjawab pertanyaan ini. Distribusi prakiraannya disajikan pada Tabel. 5.8 terpisah untuk kelompok dokter yang memiliki dana dan kelompok dokter yang tidak memiliki dana.
Apakah prognosis dokter yang memiliki dana dan dokter yang tidak memiliki dana berbeda?
Tabel 5.8
Distribusi perkiraan dari dokter umum tentang berapa porsi dana gawat darurat pada tahun 1993
Bagian yang diproyeksikan | |||
ruang resepsi dengan dana | dokter dengan dana (N 1 =45) | dokter tanpa dana (N 2 =25) | Jumlah |
1. dari 0 hingga 20% | 4 | 5 | 9 |
2. dari 21 hingga 40% | 15 | DAN | 26 |
3. dari 41 menjadi 60% | 18 | 5 | 23 |
4. dari 61 menjadi 80% | 7 | 4 | DAN |
5. dari 81 hingga 100% | 1 | 0 | 1 |
Jumlah | 45 | 25 | 70 |
Mari kita tentukan titik perbedaan maksimum antara dua distribusi respon menggunakan Algoritma 15 dari ayat 4.3 (lihat Tabel 5.9).
Tabel 5.9
Perhitungan perbedaan maksimum akumulasi frekuensi dalam distribusi perkiraan dokter dari dua kelompok
Proyeksi bagian penerimaan dengan dana (%) | Frekuensi pilihan empiris untuk kategori respons tertentu | Frekuensi empiris | Frekuensi empiris kumulatif | Perbedaan (D) |
|||
dokter dengan dana tersebut(N 1 =45) | dokter tanpa dana (N 2 =25) | F* eh 1 | F* a2 | ∑F* e1 | ∑F* a1 |
||
1. dari 0 hingga 20% 2. dari 21 hingga 40% 3. dari 41 menjadi 60% 4. dari 61 menjadi 80% 5. dari 81 hingga 100% | 4 15 18 7 1 | 5 11 5 4 0 | 0,089 0,333 0,400 0,156 0,022 | 0,200 0,440 0,200 0,160 0 | 0,089 0,422 0,822 0,978 1,000 | 0,200 0,640 0,840 1,000 1,000 | 0111 0,218 0,018 0,022 0 |
Perbedaan maksimum yang terdeteksi antara dua frekuensi empiris yang terakumulasi adalah0,218.
Perbedaan ini ternyata diakumulasikan pada kategori perkiraan kedua. Mari kita coba menggunakan batas atas kategori ini sebagai kriteria untuk membagi kedua sampel menjadi subgrup yang “ada pengaruhnya” dan subgrup yang “tidak ada pengaruhnya”. Kami akan berasumsi bahwa ada “efek” jika dokter tertentu memperkirakan 41 hingga 100% penerimaan dengan dana di1993 tahun, dan “tidak ada efek” jika dokter tertentu memperkirakan 0 hingga 40% penerimaan dengan dana di1993 tahun. Kami menggabungkan kategori perkiraan 1 dan 2 di satu sisi, dan kategori perkiraan 3, 4, dan 5 di sisi lain. Distribusi prakiraan yang dihasilkan disajikan pada Tabel. 5.10.
Tabel 5.10
Distribusi prakiraan dokter dengan dana dan dokter tanpa dana
Proyeksi bagian penerimaan dengan dana (%1 | Frekuensi empiris untuk memilih kategori perkiraan tertentu | Jumlah |
|
dokter dengan dana tersebut(N 1 =45) | dokter tanpa dana(N 2 =25) |
||
1. dari 0 hingga 40% | 19 | 16 | 35 |
2. dari 41 hingga 100% | 26 | 9 | 35 |
Jumlah | 45 | 25 | 70 |
Kita dapat menggunakan tabel yang dihasilkan (Tabel 5.10) untuk menguji hipotesis yang berbeda dengan membandingkan dua sel mana pun. Kita ingat bahwa inilah yang disebut tabel empat sel, atau empat bidang.
Di sini, kami tertarik pada apakah dokter yang sudah memiliki dana memperkirakan pertumbuhan gerakan ini di masa depan yang lebih besar dibandingkan dokter yang tidak memiliki dana. Oleh karena itu, kami secara kondisional mempertimbangkan bahwa “ada pengaruhnya” ketika perkiraan berada dalam kategori 41 hingga 100%. Untuk menyederhanakan perhitungan, sekarang kita perlu memutar meja 90°, memutarnya searah jarum jam. Anda bahkan dapat melakukan ini secara harfiah dengan membalik buku beserta mejanya. Sekarang kita dapat beralih ke lembar kerja untuk menghitung kriteria φ* - Transformasi Sudut Fisher.
Meja 5.11
Tabel empat sel untuk menghitung uji φ* Fisher untuk mengidentifikasi perbedaan perkiraan dua kelompok dokter umum
Kelompok | Ada efeknya - perkiraan dari 41 hingga 100% | Tidak ada efek - perkiraan dari 0 hingga 40% | Total |
SAYAkelompok - dokter yang mengambil dana tersebut | 26 (57.8%) | 19 (42.2%) | 45 |
IIkelompok - dokter yang tidak mengambil dana | 9 (36.0%) | 16 (64.0%) | 25 |
Total | 35 | 35 | 70 |
Mari kita merumuskan hipotesis.
H 0 : Proporsi orangmemperkirakan penyebaran dana sebesar 41%-100% dari seluruh praktik dokter, pada kelompok dokter yang memiliki dana tidak lebih banyak dibandingkan pada kelompok dokter yang tidak memiliki dana.
H 1 : Proporsi masyarakat yang memperkirakan penyebaran dana sebesar 41%-100% dari seluruh penerimaan lebih besar pada kelompok dokter yang memiliki dana dibandingkan pada kelompok dokter tanpa dana.
Menentukan nilai φ 1 dan φ 2 menurut TabelXIILampiran 1. Ingatlah bahwa φ 1 selalu merupakan sudut yang sesuai dengan persentase yang lebih besar.
Sekarang mari kita tentukan nilai empiris kriteria φ*:
Menurut Tabel.XIIIDalam Lampiran 1 kita menentukan tingkat signifikansi yang sesuai dengan nilai ini: p = 0,039.
Dengan menggunakan tabel yang sama di Lampiran 1, Anda dapat menentukan nilai kritis kriteria φ*:
Menjawab: Namun ditolak (p=0,039). Jumlah orang yang memperkirakan penyebaran dana ke41-100 % seluruh penerimaan pada kelompok dokter yang mengambil dana melebihi bagiannya pada kelompok dokter yang tidak mengambil dana.
Dengan kata lain, dokter yang sudah bekerja di ruang tunggu dengan anggaran terpisah memperkirakan penyebaran praktik ini akan lebih luas pada tahun ini dibandingkan dokter yang belum setuju untuk beralih ke anggaran mandiri. Ada banyak interpretasi mengenai hasil ini. Misalnya, dapat diasumsikan bahwa dokter di setiap kelompok secara tidak sadar menganggap perilaku mereka lebih khas. Hal ini juga dapat berarti bahwa para dokter yang telah menerapkan pendanaan mandiri cenderung membesar-besarkan cakupan gerakan ini, karena mereka perlu memberikan alasan atas keputusan mereka. Perbedaan yang teridentifikasi juga dapat berarti sesuatu yang sepenuhnya berada di luar cakupan pertanyaan yang diajukan dalam penelitian. Misalnya, aktivitas dokter yang bekerja dengan anggaran mandiri ikut mempertajam perbedaan posisi kedua kelompok. Mereka lebih aktif ketika mereka setuju untuk mengambil dana, mereka lebih aktif ketika mereka bersusah payah menjawab kuesioner melalui pos; mereka lebih aktif ketika memperkirakan dokter lain akan lebih aktif menerima dana.
Dengan satu atau lain cara, kita dapat yakin bahwa tingkat perbedaan statistik yang terdeteksi adalah semaksimal mungkin untuk data nyata ini. Kami menetapkan menggunakan kriteriaλ titik divergensi maksimum antara kedua distribusi, dan pada titik inilah sampel dibagi menjadi dua bagian.
tandamu.
Fungsi FISCHER mengembalikan transformasi argumen Fisher ke X . Transformasi ini menghasilkan fungsi yang mempunyai distribusi normal dan bukan distribusi miring. Fungsi FISCHER digunakan untuk menguji hipotesis dengan menggunakan koefisien korelasi.
Deskripsi fungsi FISCHER di Excel
Saat bekerja dengan fungsi ini, Anda harus menetapkan nilai variabel. Perlu segera dicatat bahwa ada beberapa situasi di mana fungsi ini tidak akan membuahkan hasil. Hal ini dimungkinkan jika variabel:
- bukanlah sebuah angka. Dalam situasi seperti ini, fungsi FISCHER akan mengembalikan nilai kesalahan #VALUE!;
- memiliki nilai kurang dari -1 atau lebih besar dari 1. Dalam hal ini, fungsi FISCHER akan mengembalikan nilai kesalahan #NUM!.
Persamaan yang digunakan untuk menggambarkan fungsi FISCHER secara matematis adalah:
Z"=1/2*ln(1+x)/(1-x)
Mari pertimbangkan penggunaan fungsi ini menggunakan 3 contoh spesifik.
Estimasi hubungan antara keuntungan dan biaya menggunakan fungsi FISHER
Contoh 1. Dengan menggunakan data aktivitas organisasi komersial, perlu dilakukan penilaian terhadap hubungan antara laba Y (juta rubel) dan biaya X (juta rubel) yang digunakan untuk pengembangan produk (ditunjukkan pada Tabel 1).
Tabel 1 – Data awal:
| № | X | Y |
| 1 | 210.000.000,00 RUR | 95.000.000,00 RUR |
| 2 | Rp1.068.000.000,00 | 76.000.000,00 RUR |
| 3 | Rp1.005.000.000,00 | 78.000.000,00 RUR |
| 4 | 610.000.000,00 RUR | 89.000.000,00 RUR |
| 5 | 768.000.000,00 RUR | 77.000.000,00 RUR |
| 6 | 799.000.000,00 RUR | 85.000.000,00 RUR |
Skema penyelesaian masalah tersebut adalah sebagai berikut:
- Dihitung koefisien linier korelasi r xy ;
- Signifikansi koefisien korelasi linier diperiksa berdasarkan uji-t Student. Dalam hal ini hipotesis diajukan dan diuji bahwa koefisien korelasi sama dengan nol. Statistik-t digunakan untuk menguji hipotesis ini. Jika hipotesis terkonfirmasi, maka statistik-t mempunyai distribusi Student. Jika nilai hitung t p > t cr, maka hipotesis ditolak, yang menunjukkan signifikansi koefisien korelasi linier, dan oleh karena itu signifikansi statistik dari hubungan antara X dan Y;
- Estimasi interval ditentukan untuk koefisien korelasi linier yang signifikan secara statistik.
- Estimasi interval untuk koefisien korelasi linier ditentukan berdasarkan transformasi z Fisher terbalik;
- Kesalahan standar koefisien korelasi linier dihitung.
Hasil penyelesaian masalah ini dengan fungsi-fungsi yang digunakan di Excel ditunjukkan pada Gambar 1.
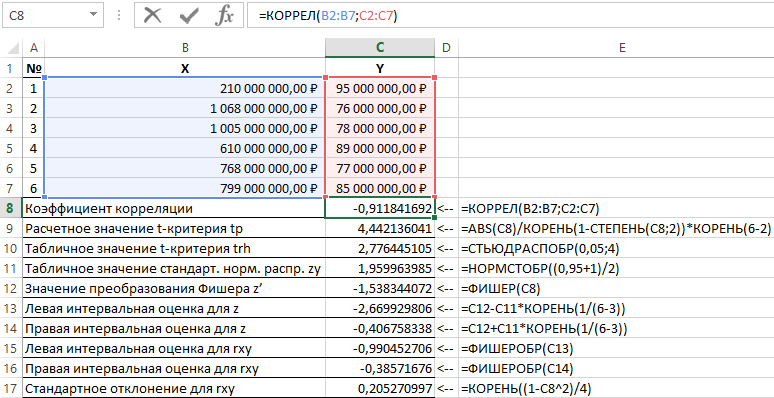
Gambar 1 – Contoh perhitungan.
| TIDAK. | Nama indikator | Rumus perhitungan |
| 1 | Koefisien korelasi | =CORREL(B2:B7,C2:C7) |
| 2 | Dihitung nilai uji t tp | =ABS(C8)/SQRT(1-DAYA(C8,2))*SQRT(6-2) |
| 3 | Tabel nilai uji t trh | =BELAJAR(0,05,4) |
| 4 | Tabel nilai standar distribusi normal zy | =NORMSINV((0,95+1)/2) |
| 5 | Nilai transformasi Fisher z’ | =NELAYAN(C8) |
| 6 | Perkiraan interval kiri untuk z | =C12-C11*AKAR(1/(6-3)) |
| 7 | Estimasi interval yang tepat untuk z | =C12+C11*AKAR(1/(6-3)) |
| 8 | Estimasi interval kiri untuk rxy | =NELAYAN(C13) |
| 9 | Perkiraan interval yang tepat untuk rxy | =NELAYAN(C14) |
| 10 | Deviasi standar untuk rxy | =ROOT((1-C8^2)/4) |
Jadi, dengan probabilitas 0,95, koefisien korelasi linier berada pada kisaran (–0,386) hingga (–0,990) dengan standar error 0,205.
Memeriksa signifikansi statistik regresi menggunakan fungsi FASTER
Contoh 2: Uji signifikansi statistik persamaan tersebut regresi berganda Dengan menggunakan uji F Fisher, buatlah kesimpulan.
Untuk memeriksa signifikansi persamaan secara keseluruhan, kami mengajukan hipotesis H 0 tentang tidak signifikannya statistik koefisien determinasi dan hipotesis sebaliknya H 1 tentang signifikansi statistik koefisien determinasi:
H 1 : R 2 ≠ 0.
Mari kita uji hipotesis menggunakan uji F Fisher. Indikatornya ditunjukkan pada Tabel 2.
Tabel 2 - Data awal
Untuk melakukan ini, kami menggunakan fungsi di Excel:
LEBIH CEPAT (α;p;n-p-1)
- α adalah probabilitas yang terkait dengan distribusi tertentu;
- p dan n masing-masing adalah pembilang dan penyebut derajat kebebasan.
Mengetahui bahwa α = 0,05, p = 2 dan n = 53, kita memperoleh nilai F crit berikut (lihat Gambar 2).
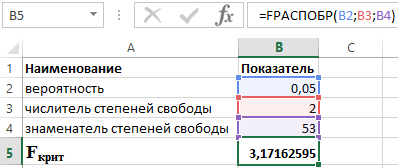
Gambar 2 – Contoh perhitungan.
Dengan demikian dapat dikatakan bahwa F hitung > F kritis. Hasilnya, hipotesis H 1 tentang signifikansi statistik koefisien determinasi diterima.
Menghitung nilai indikator korelasi di Excel
Contoh 3. Menggunakan data dari 23 perusahaan tentang: X adalah harga produk A, ribuan rubel; Y adalah keuntungan perusahaan perdagangan, juta rubel; ketergantungan mereka sedang dipelajari. Nilai model regresi memberikan yang berikut: ∑(yi-yx) 2 = 50000; ∑(yi-yср) 2 = 130000. Indikator korelasi apa yang dapat ditentukan dari data tersebut? Hitung nilai indikator korelasi dan, dengan menggunakan kriteria Fisher, buat kesimpulan tentang kualitas model regresi.
Mari kita tentukan F crit dari ekspresi:
F dihitung = R 2 /23*(1-R 2)
dimana R adalah koefisien determinasi sebesar 0,67.
Jadi, nilai hitung F kal = 46.
Untuk menentukan F crit kita menggunakan distribusi Fisher (lihat Gambar 3).

Gambar 3 – Contoh perhitungan.
Dengan demikian, estimasi persamaan regresi yang dihasilkan dapat diandalkan.
Signifikansi persamaan regresi berganda secara keseluruhan, serta regresi berpasangan, dinilai menggunakan kriteria Fisher:
 ,
(2.22)
,
(2.22)
Di mana  – jumlah faktor kuadrat per derajat kebebasan;
– jumlah faktor kuadrat per derajat kebebasan;  – jumlah sisa kuadrat per derajat kebebasan;
– jumlah sisa kuadrat per derajat kebebasan;  – koefisien (indeks) determinasi berganda;
– koefisien (indeks) determinasi berganda;  – jumlah parameter untuk variabel
– jumlah parameter untuk variabel  (V regresi linier bertepatan dengan jumlah faktor yang dimasukkan dalam model);
(V regresi linier bertepatan dengan jumlah faktor yang dimasukkan dalam model);  – jumlah observasi.
– jumlah observasi.
Signifikansi tidak hanya persamaan secara keseluruhan yang dinilai, tetapi juga faktor tambahan yang dimasukkan dalam model regresi. Perlunya penilaian tersebut karena tidak semua faktor yang dimasukkan dalam model dapat secara signifikan meningkatkan proporsi variasi yang dapat dijelaskan pada sifat yang dihasilkan. Selain itu, jika terdapat beberapa faktor dalam model, faktor-faktor tersebut dapat dimasukkan ke dalam model dalam urutan yang berbeda. Karena adanya korelasi antar faktor, signifikansi faktor yang sama mungkin berbeda tergantung pada urutan pemasukannya ke dalam model. Ukuran untuk menilai masuknya suatu faktor ke dalam model adalah privat  -kriteria, yaitu
-kriteria, yaitu  .
.
Pribadi  -kriteria didasarkan pada perbandingan peningkatan varians faktor akibat pengaruh faktor tambahan yang dimasukkan dengan varians sisa per satu derajat kebebasan untuk model regresi secara keseluruhan. DI DALAM pandangan umum untuk faktor
-kriteria didasarkan pada perbandingan peningkatan varians faktor akibat pengaruh faktor tambahan yang dimasukkan dengan varians sisa per satu derajat kebebasan untuk model regresi secara keseluruhan. DI DALAM pandangan umum untuk faktor  pribadi
pribadi  -kriterianya akan ditentukan sebagai
-kriterianya akan ditentukan sebagai
 ,
(2.23)
,
(2.23)
Di mana  – koefisien determinasi berganda untuk model dengan serangkaian faktor lengkap,
– koefisien determinasi berganda untuk model dengan serangkaian faktor lengkap,  – indikator yang sama, namun tanpa menyertakan faktor dalam model
– indikator yang sama, namun tanpa menyertakan faktor dalam model  ,
, – jumlah observasi,
– jumlah observasi,  – jumlah parameter dalam model (tanpa suku bebas).
– jumlah parameter dalam model (tanpa suku bebas).
Nilai sebenarnya dari hasil bagi  - kriteria dibandingkan dengan tabel pada tingkat signifikansi
- kriteria dibandingkan dengan tabel pada tingkat signifikansi  dan jumlah derajat kebebasan: 1 dan
dan jumlah derajat kebebasan: 1 dan  . Jika nilai sebenarnya
. Jika nilai sebenarnya  melebihi
melebihi  , lalu penyertaan tambahan faktor tersebut
, lalu penyertaan tambahan faktor tersebut  ke dalam model dibenarkan secara statistik dan koefisien regresi murni
ke dalam model dibenarkan secara statistik dan koefisien regresi murni  di faktor
di faktor  signifikan secara statistik. Jika nilai sebenarnya
signifikan secara statistik. Jika nilai sebenarnya  kurang dari nilai tabel, maka penambahan faktor tersebut dimasukkan ke dalam model
kurang dari nilai tabel, maka penambahan faktor tersebut dimasukkan ke dalam model  tidak secara signifikan meningkatkan proporsi variasi yang dijelaskan dalam suatu sifat
tidak secara signifikan meningkatkan proporsi variasi yang dijelaskan dalam suatu sifat  , oleh karena itu, tidak tepat untuk memasukkannya ke dalam model; Koefisien regresi faktor ini dalam hal ini tidak signifikan secara statistik.
, oleh karena itu, tidak tepat untuk memasukkannya ke dalam model; Koefisien regresi faktor ini dalam hal ini tidak signifikan secara statistik.
Untuk persamaan dua faktor, hasil bagi  -kriteria berbentuk:
-kriteria berbentuk:
 ,
, . (2.23a)
. (2.23a)
Menggunakan pribadi  -kriteria, seseorang dapat memeriksa signifikansi semua koefisien regresi dengan asumsi bahwa setiap faktor berhubungan
-kriteria, seseorang dapat memeriksa signifikansi semua koefisien regresi dengan asumsi bahwa setiap faktor berhubungan  dimasukkan ke dalam persamaan regresi berganda terakhir.
dimasukkan ke dalam persamaan regresi berganda terakhir.
Tes -Student untuk persamaan regresi berganda.
Pribadi  -kriteria mengevaluasi signifikansi koefisien regresi murni. Mengetahui besarnya
-kriteria mengevaluasi signifikansi koefisien regresi murni. Mengetahui besarnya  , adalah mungkin untuk menentukan
, adalah mungkin untuk menentukan  -kriteria koefisien regresi pada
-kriteria koefisien regresi pada  -m faktor,
-m faktor,  , yaitu:
, yaitu:
 .
(2.24)
.
(2.24)
Menilai signifikansi koefisien regresi murni dengan  -Uji-t siswa dapat dilakukan tanpa menghitung parsial
-Uji-t siswa dapat dilakukan tanpa menghitung parsial  -kriteria. Dalam hal ini, seperti halnya regresi berpasangan, rumus yang digunakan untuk setiap faktor:
-kriteria. Dalam hal ini, seperti halnya regresi berpasangan, rumus yang digunakan untuk setiap faktor:
 ,
(2.25)
,
(2.25)
Di mana  – koefisien regresi murni pada faktor tersebut
– koefisien regresi murni pada faktor tersebut  ,
, – kesalahan kuadrat rata-rata (standar) dari koefisien regresi
– kesalahan kuadrat rata-rata (standar) dari koefisien regresi  .
.
Untuk persamaan regresi berganda, mean square error dari koefisien regresi dapat ditentukan dengan rumus berikut:
 ,
(2.26)
,
(2.26)
Di mana 
 ,
, – deviasi standar untuk karakteristik
– deviasi standar untuk karakteristik  ,
, – koefisien determinasi untuk persamaan regresi berganda,
– koefisien determinasi untuk persamaan regresi berganda,  – koefisien determinasi ketergantungan faktor
– koefisien determinasi ketergantungan faktor  dengan semua faktor lain dalam persamaan regresi berganda;
dengan semua faktor lain dalam persamaan regresi berganda;  – jumlah derajat kebebasan untuk jumlah sisa simpangan kuadrat.
– jumlah derajat kebebasan untuk jumlah sisa simpangan kuadrat.
Seperti yang Anda lihat, untuk menggunakan rumus ini, Anda memerlukan matriks korelasi antarfaktor dan perhitungan koefisien determinasi yang sesuai dengan menggunakannya.  . Jadi, untuk persamaannya
. Jadi, untuk persamaannya  penilaian signifikansi koefisien regresi
penilaian signifikansi koefisien regresi  ,
, ,
, melibatkan perhitungan tiga koefisien determinasi antarfaktor:
melibatkan perhitungan tiga koefisien determinasi antarfaktor:  ,
, ,
, .
.
Hubungan antar indikator koefisien korelasi parsial bersifat parsial  -kriteria dan
-kriteria dan  -Uji-t Student untuk koefisien regresi murni dapat digunakan dalam prosedur pemilihan faktor. Penghapusan faktor-faktor ketika membangun persamaan regresi dengan metode eliminasi secara praktis dapat dilakukan tidak hanya dengan koefisien korelasi parsial, tidak termasuk pada setiap langkah faktor dengan nilai koefisien korelasi parsial terkecil yang tidak signifikan, tetapi juga dengan nilai-nilai.
-Uji-t Student untuk koefisien regresi murni dapat digunakan dalam prosedur pemilihan faktor. Penghapusan faktor-faktor ketika membangun persamaan regresi dengan metode eliminasi secara praktis dapat dilakukan tidak hanya dengan koefisien korelasi parsial, tidak termasuk pada setiap langkah faktor dengan nilai koefisien korelasi parsial terkecil yang tidak signifikan, tetapi juga dengan nilai-nilai.  Dan
Dan  .
Pribadi
.
Pribadi  -kriteria banyak digunakan ketika membangun model menggunakan metode inklusi variabel dan metode regresi bertahap.
-kriteria banyak digunakan ketika membangun model menggunakan metode inklusi variabel dan metode regresi bertahap.







