Interval spolehlivosti pro matematické očekávání - jedná se o interval vypočítaný z údajů, které se známou pravděpodobností obsahují matematické očekávání běžné populace. Přirozeným odhadem matematického očekávání je aritmetický průměr jeho pozorovaných hodnot. Proto v celé lekci budeme používat termíny „průměr“ a „průměrná hodnota“. V problémech s výpočtem intervalu spolehlivosti je nejčastěji vyžadována odpověď něco jako „Interval spolehlivosti střední hodnoty [hodnoty v konkrétním problému] je od [menší hodnoty] do [větší hodnoty]. Pomocí intervalu spolehlivosti můžete vyhodnotit nejen průměrné hodnoty, ale také podíl konkrétní charakteristiky v obecné populaci. Průměrné hodnoty, rozptyl, směrodatná odchylka a chyba, pomocí kterých dospějeme k novým definicím a vzorcům, jsou probrány v lekci Charakteristika vzorku a populace .
Bodové a intervalové odhady průměru
Pokud je průměrná hodnota populace odhadnuta číslem (bodem), pak se jako odhad neznámé průměrné hodnoty populace bere konkrétní průměr, který se vypočítá ze vzorku pozorování. V tomto případě je hodnota výběrového průměru náhodná proměnná- neshoduje se s průměrnou hodnotou obyv. Proto při indikaci střední hodnoty vzorku musíte současně uvést chybu vzorku. Mírou výběrové chyby je standardní chyba, která je vyjádřena ve stejných jednotkách jako průměr. Proto se často používá následující zápis: .
Pokud je třeba odhad průměru spojit s určitou pravděpodobností, pak je třeba parametr zájmu v populaci odhadnout nikoli jedním číslem, ale intervalem. Interval spolehlivosti je interval, ve kterém s určitou pravděpodobností P je zjištěna hodnota odhadovaného ukazatele počtu obyvatel. Interval spolehlivosti, ve kterém je to pravděpodobné P = 1 - α náhodná proměnná je nalezena, vypočítaná takto:
![]() ,
,
α = 1 - P, kterou najdete v příloze téměř každé knihy o statistice.
V praxi průměr a rozptyl populace nejsou známy, takže rozptyl populace je nahrazen rozptylem výběru a průměr populace průměrem vzorku. Interval spolehlivosti se tedy ve většině případů vypočítá takto:
![]() .
.
Vzorec intervalu spolehlivosti lze použít k odhadu střední hodnoty populace, jestliže
- je známa standardní odchylka základního souboru;
- nebo standardní odchylka populace není známa, ale velikost vzorku je větší než 30.
Výběrový průměr je nestranný odhad průměru populace. Na druhé straně, rozptyl vzorku  není nestranný odhad rozptylu populace. Chcete-li získat nezkreslený odhad rozptylu populace ve vzorci rozptylu vzorku, velikost vzorku n by měl být nahrazen n-1.
není nestranný odhad rozptylu populace. Chcete-li získat nezkreslený odhad rozptylu populace ve vzorci rozptylu vzorku, velikost vzorku n by měl být nahrazen n-1.
Příklad 1 Ze 100 náhodně vybraných kaváren v určitém městě byla shromážděna informace, že průměrný počet zaměstnanců v nich je 10,5 se směrodatnou odchylkou 4,6. Definovat interval spolehlivosti 95 % pracovníků kaváren.
kde je kritická hodnota standardního normálního rozdělení pro hladinu významnosti α = 0,05 .
95% interval spolehlivosti průměrného počtu zaměstnanců kavárny se tedy pohyboval v rozmezí 9,6 až 11,4.
Příklad 2 Pro náhodný vzorek z populace 64 pozorování byly vypočteny následující celkové hodnoty:
součet hodnot v pozorováních,
součet čtverců odchylek hodnot od průměru ![]() .
.
Vypočítejte 95% interval spolehlivosti pro matematické očekávání.
Pojďme vypočítat směrodatnou odchylku:
 ,
,
Vypočítejme průměrnou hodnotu:
![]() .
.
Hodnoty dosadíme do výrazu pro interval spolehlivosti:
kde je kritická hodnota standardního normálního rozdělení pro hladinu významnosti α = 0,05 .
Dostaneme:
95% interval spolehlivosti pro matematické očekávání tohoto vzorku se tedy pohyboval od 7,484 do 11,266.
Příklad 3 Pro náhodný vzorek populace 100 pozorování je vypočtený průměr 15,2 a standardní odchylka je 3,2. Vypočítejte 95% interval spolehlivosti pro očekávanou hodnotu a poté 99% interval spolehlivosti. Pokud výkon vzorku a jeho variace zůstanou nezměněny a koeficient spolehlivosti se zvýší, bude se interval spolehlivosti zužovat nebo rozšiřovat?
Tyto hodnoty dosadíme do výrazu pro interval spolehlivosti:
kde je kritická hodnota standardního normálního rozdělení pro hladinu významnosti α = 0,05 .
Dostaneme:
![]() .
.
95% interval spolehlivosti pro průměr tohoto vzorku se tedy pohyboval od 14,57 do 15,82.
Tyto hodnoty opět dosadíme do výrazu pro interval spolehlivosti:
kde je kritická hodnota standardního normálního rozdělení pro hladinu významnosti α = 0,01 .
Dostaneme:
![]() .
.
99% interval spolehlivosti pro průměr tohoto vzorku se tedy pohyboval od 14,37 do 16,02.
Jak vidíme, jak se koeficient spolehlivosti zvyšuje, kritická hodnota standardního normálního rozdělení také roste a v důsledku toho jsou počáteční a koncové body intervalu umístěny dále od průměru, a proto se interval spolehlivosti pro matematické očekávání zvyšuje. .
Bodové a intervalové odhady měrné hmotnosti
Podíl některého atributu vzorku lze interpretovat jako bodový odhad specifická gravitace p stejné vlastnosti v běžné populaci. Pokud je třeba tuto hodnotu spojit s pravděpodobností, měl by se vypočítat interval spolehlivosti specifické hmotnosti p charakteristika v populaci s pravděpodobností P = 1 - α :
 .
.
Příklad 4. V některém městě jsou dva kandidáti A A B kandidují na starostu. Náhodně bylo dotázáno 200 obyvatel města, z nichž 46 % odpovědělo, že by kandidáta volili A, 26 % - pro kandidáta B a 28 % neví, koho budou volit. Určete 95% interval spolehlivosti pro podíl obyvatel města podporujících kandidáta A.
Jakýkoli vzorek poskytuje pouze přibližnou představu o obecné populaci a všechny statistické charakteristiky vzorku (průměr, modus, rozptyl...) jsou určitou aproximací nebo řekněme odhadem obecných parametrů, které ve většině případů není možné vypočítat kvůli k nepřístupnosti běžné populace (obrázek 20) .
Obrázek 20. Chyba vzorkování
Můžete ale určit interval, ve kterém s určitou mírou pravděpodobnosti leží skutečná (obecná) hodnota statistické charakteristiky. Tento interval se nazývá d interval spolehlivosti (CI).
Obecná průměrná hodnota s pravděpodobností 95 % tedy leží uvnitř
od do, (20)
Kde t – tabulková hodnota Studentův t test pro α = 0,05 a F= n-1
V tomto případě lze také nalézt 99% CI t vybráno pro α =0,01.
Jaký je praktický význam intervalu spolehlivosti?
Široký interval spolehlivosti ukazuje, že průměr vzorku neodráží přesně průměr populace. To je obvykle způsobeno nedostatečnou velikostí vzorku, případně jeho heterogenitou, tzn. velký rozptyl. Dávají obojí velká chyba průměr, a tedy i širší CI. A to je základ pro návrat do fáze plánování výzkumu.
Horní a dolní hranice CI poskytují odhad, zda budou výsledky klinicky významné
Zastavme se poněkud podrobněji u otázky statistické a klinické významnosti výsledků studia skupinových vlastností. Připomeňme, že úkolem statistiky je na základě výběrových dat odhalit alespoň nějaké rozdíly v obecných populacích. Výzvou pro klinické lékaře je odhalit rozdíly (ne ledajaké), které pomohou při diagnostice nebo léčbě. A statistické závěry nejsou vždy základem pro klinické závěry. Statisticky významný pokles hemoglobinu o 3 g/l tedy není důvodem k obavám. A naopak, pokud nějaký problém v lidském těle není rozšířen na úrovni celé populace, není to důvod se tímto problémem nezabývat.
|
Podívejme se na tuto situaci příklad. Vědci si kladli otázku, zda chlapci, kteří prodělali nějakou infekční chorobu, nezaostávají v růstu za svými vrstevníky. Za tímto účelem byla provedena výběrové šetření, kterého se zúčastnilo 10 chlapců, kteří prodělali toto onemocnění. Výsledky jsou uvedeny v tabulce 23. Tabulka 23. Výsledky statistického zpracování
Z těchto výpočtů vyplývá, že vzorek průměrná výška chlapci 10 let, kteří trpěli infekce, téměř normální (132,5 cm). Spodní hranice intervalu spolehlivosti (126,6 cm) však ukazuje, že existuje 95% pravděpodobnost, že skutečná průměrná výška těchto dětí odpovídá pojmu „nízká výška“, tzn. tyto děti jsou zakrnělé. V tomto příkladu jsou výsledky výpočtů intervalu spolehlivosti klinicky významné. |
|||||||||||||||||||
Jednou z metod řešení statistických problémů je výpočet intervalu spolehlivosti. Používá se jako výhodnější alternativa bodový odhad s malou velikostí vzorku. Je třeba poznamenat, že samotný proces výpočtu intervalu spolehlivosti je poměrně složitý. Nástroje Excelu to ale poněkud usnadňují. Pojďme zjistit, jak se to dělá v praxi.
Tato metoda se používá pro intervalové odhady různých statistické veličiny. Hlavním úkolem tohoto výpočtu je zbavit se nejistot bodového odhadu.
V Excelu existují dvě hlavní možnosti pro provádění výpočtů pomocí tato metoda: když je rozptyl znám a když není znám. V prvním případě se funkce používá pro výpočty DŮVĚŘOVAT.NORM a ve druhém - DŮVĚRNÍK.STUDENT.
Metoda 1: Funkce CONFIDENCE NORM
Operátor DŮVĚŘOVAT.NORM, který patří do statistické skupiny funkcí, se poprvé objevil v Excelu 2010. Dřívější verze tohoto programu používají jeho analog DŮVĚRA. Účelem tohoto operátoru je vypočítat normálně rozdělený interval spolehlivosti pro průměr populace.
Jeho syntaxe je následující:
CONFIDENCE.NORM(alfa;standardní_vypnuto;velikost)
"alfa"— argument udávající hladinu významnosti, která se používá k výpočtu hladiny spolehlivosti. Úroveň spolehlivosti se rovná následujícímu výrazu:
(1-"Alfa")*100
« Standardní odchylka» - To je argument, jehož podstata je zřejmá z názvu. Toto je standardní odchylka navrhovaného vzorku.
"Velikost"— argument definující velikost vzorku.
Všechny argumenty pro tento operátor jsou povinné.
Funkce DŮVĚRA má úplně stejné argumenty a možnosti jako předchozí. Jeho syntaxe je:
TRUST(alfa; standardní_vypnuto; velikost)
Jak vidíte, rozdíly jsou pouze ve jménu operátora. Zadaná funkce z důvodu kompatibility ponecháno v Excelu 2010 a novějších verzích ve speciální kategorii "Kompatibilita". Ve verzích Excelu 2007 a starších je přítomen v hlavní skupině statistických operátorů.
Limit intervalu spolehlivosti se určuje pomocí následujícího vzorce:
X+(-)SEVĚDOMÍ NORM
Kde X je průměrná hodnota vzorku, která se nachází uprostřed zvoleného rozsahu.
Nyní se podíváme na to, jak vypočítat interval spolehlivosti pomocí konkrétního příkladu. Bylo provedeno 12 testů, jejichž výsledkem byly různé výsledky, uvedené v tabulce. Tohle je naše totalita. Standardní odchylka je 8. Potřebujeme vypočítat interval spolehlivosti na hladině spolehlivosti 97 %.
- Vyberte buňku, kde se zobrazí výsledek zpracování dat. Klikněte na tlačítko "Vložit funkci".
- Objeví se Průvodce funkcí. Přejít do kategorie "Statistický" a zvýrazněte jméno "TRUST.NORM". Poté klikněte na tlačítko "OK".
- Otevře se okno s argumenty. Jeho pole přirozeně odpovídají názvům argumentů.
Umístěte kurzor do prvního pole - "alfa". Zde bychom měli uvést úroveň významnosti. Jak si pamatujeme, naše úroveň důvěry je 97 %. Zároveň jsme řekli, že se to počítá takto:(1-úroveň důvěryhodnosti)/100
To znamená, že dosazením hodnoty získáme:
Jednoduchými výpočty zjistíme, že argument "alfa" rovná se 0,03 . Zadejte tuto hodnotu do pole.
Jak je známo, podle podmínky je standardní odchylka rovna 8 . Proto v terénu "Standardní odchylka" stačí napsat toto číslo.
V terénu "Velikost" musíte zadat počet provedených testovacích prvků. Jak si pamatujeme, jejich 12 . Abychom ale vzorec zautomatizovali a neupravovali ho pokaždé, když provádíme nový test, nastavme tuto hodnotu ne obyčejným číslem, ale pomocí operátoru ŠEK. Umístíme tedy kurzor do pole "Velikost" a poté klikněte na trojúhelník, který se nachází vlevo od řádku vzorců.
Zobrazí se seznam naposledy použitých funkcí. Pokud operátor ŠEK byl vámi nedávno použit, měl by být na tomto seznamu. V tomto případě stačí kliknout na jeho název. V opačném případě, pokud to nenajdete, přejděte k věci "Další funkce...".
- Objeví se již známý Průvodce funkcí. Vraťme se znovu ke skupině "Statistický". Jméno tam zvýrazníme "ŠEK". Klikněte na tlačítko "OK".
- Zobrazí se okno argumentů pro výše uvedený příkaz. Tato funkce je určena k výpočtu počtu buněk v určeném rozsahu, které obsahují číselné hodnoty. Jeho syntaxe je následující:
POČET(hodnota1;hodnota2;…)
Skupina argumentů "hodnoty" je odkaz na rozsah, ve kterém chcete vypočítat počet buněk vyplněných číselnými údaji. Takových argumentů může být celkem až 255, ale v našem případě potřebujeme pouze jeden.
Umístěte kurzor do pole "Hodnota 1" a podržením levého tlačítka myši vyberte na listu řadu, která obsahuje naši kolekci. Poté se v poli zobrazí jeho adresa. Klikněte na tlačítko "OK".
- Poté aplikace provede výpočet a zobrazí výsledek v buňce, kde se nachází. V našem konkrétním případě vzorec vypadal takto:
CONFIDENCE NORM(0,03;8;POČET(B2:B13))
Celkový výsledek výpočtů byl 5,011609 .
- Ale to není vše. Jak si pamatujeme, mez intervalu spolehlivosti se vypočítává přičtením a odečtením výsledku výpočtu od průměru vzorku DŮVĚŘOVAT.NORM. Tímto způsobem se vypočítá pravá a levá hranice intervalu spolehlivosti. Samotný výběrový průměr lze vypočítat pomocí operátoru PRŮMĚRNÝ.
Tento operátor je určen k výpočtu aritmetického průměru vybraného rozsahu čísel. Má následující poměrně jednoduchou syntaxi:
AVERAGE(číslo1,číslo2,…)
Argument "Číslo" mohou být buď oddělené číselná hodnota a odkaz na buňky nebo dokonce celé rozsahy, které je obsahují.
Vyberte tedy buňku, ve které se zobrazí výpočet průměrné hodnoty, a klikněte na tlačítko "Vložit funkci".
- Otevře se Průvodce funkcí. Návrat ke kategorii "Statistický" a vyberte jméno ze seznamu "PRŮMĚRNÝ". Jako vždy klikněte na tlačítko "OK".
- Otevře se okno s argumenty. Umístěte kurzor do pole "Číslo 1" a podržením levého tlačítka myši vyberte celý rozsah hodnot. Po zobrazení souřadnic v poli klikněte na tlačítko "OK".
- Potom PRŮMĚRNÝ zobrazí výsledek výpočtu v prvku listu.
- Provádíme kalkulaci pravá hranice interval spolehlivosti. Chcete-li to provést, vyberte samostatnou buňku a vložte znaménko «=»
a sečtěte obsah prvků listu, ve kterých jsou umístěny výsledky výpočtů funkcí PRŮMĚRNÝ A DŮVĚŘOVAT.NORM. Pro provedení výpočtu stiskněte tlačítko Vstupte. V našem případě jsme dostali následující vzorec:
Výsledek výpočtu: 6,953276
- Stejným způsobem vypočítáme levou mez intervalu spolehlivosti, pouze tentokrát z výsledku výpočtu PRŮMĚRNÝ odečtěte výsledek výpočtu operátora DŮVĚŘOVAT.NORM. Výsledný vzorec pro náš příklad je následujícího typu:
Výsledek výpočtu: -3,06994
- Snažili jsme se podrobně popsat všechny kroky pro výpočet intervalu spolehlivosti, proto jsme podrobně popsali každý vzorec. Všechny akce ale můžete spojit do jednoho vzorce. Výpočet pravé hranice intervalu spolehlivosti lze zapsat následovně:
AVERAGE(B2:B13)+CONFIDENCE.NORM(0.03;8;COUNT(B2:B13))
- Podobný výpočet pro levý okraj by vypadal takto:
AVERAGE(B2:B13)-CONFIDENCE.NORM(0.03;8;COUNT(B2:B13))














Metoda 2: Funkce DŮVĚRYHODNÝ STUDENT
Kromě toho má Excel další funkci, která je spojena s výpočtem intervalu spolehlivosti - DŮVĚRNÍK.STUDENT. Objevil se pouze v Excelu 2010. Tento operátor počítá interval spolehlivosti populace pomocí Studentova rozdělení. Je velmi vhodné použít, když rozptyl a tedy i směrodatná odchylka nejsou známy. Syntaxe operátoru je:
CONFIDENCE.STUDENT(alfa;standardní_off;velikost)
Jak je vidět, jména operátorů zůstala v tomto případě nezměněna.
Podívejme se, jak vypočítat hranice intervalu spolehlivosti s neznámou směrodatnou odchylkou na příkladu stejné populace, kterou jsme uvažovali v předchozí metodě. Vezměme úroveň důvěry jako minule na 97 %.
- Vyberte buňku, ve které bude výpočet proveden. Klikněte na tlačítko "Vložit funkci".
- V otevřeném Průvodce funkcí přejděte do kategorie "Statistický". Vyberte jméno "DŮVĚRYHODNÝ STUDENT". Klikněte na tlačítko "OK".
- Otevře se okno argumentů pro zadaný operátor.
V terénu "alfa", vzhledem k tomu, že hladina spolehlivosti je 97 %, zapíšeme si číslo 0,03 . Podruhé se nebudeme zdržovat principy výpočtu tohoto parametru.
Poté umístěte kurzor do pole "Standardní odchylka". Tentokrát nám tento ukazatel není znám a je potřeba jej spočítat. To se provádí pomocí speciální funkce - STDEV.V. Chcete-li otevřít okno tohoto operátoru, klikněte na trojúhelník vlevo od řádku vzorců. Pokud nenajdeme požadované jméno v seznamu, který se otevře, přejděte na položku "Další funkce...".
- Začíná Průvodce funkcí. Přesun do kategorie "Statistický" a označte v něm jméno "STDEV.B". Poté klikněte na tlačítko "OK".
- Otevře se okno s argumenty. Úkol operátora STDEV.V je určit směrodatnou odchylku vzorku. Jeho syntaxe vypadá takto:
STANDARDNÍ ODCHYLKA.B(číslo1;číslo2;…)
Není těžké uhodnout, že argument "Číslo" je adresa prvku výběru. Pokud je výběr umístěn v jediném poli, můžete použít pouze jeden argument k poskytnutí odkazu na tento rozsah.
Umístěte kurzor do pole "Číslo 1" a jako vždy podržením levého tlačítka myši vyberte kolekci. Jakmile jsou souřadnice v poli, nespěchejte se stisknutím tlačítka "OK", protože výsledek bude nesprávný. Nejprve se musíme vrátit do okna argumentů operátora DŮVĚRNÍK.STUDENT přidat poslední argument. Chcete-li to provést, klikněte na odpovídající název v řádku vzorců.
- Znovu se otevře okno argumentů pro již známou funkci. Umístěte kurzor do pole "Velikost". Opět kliknutím na trojúhelník, který již známe, přejdeme k výběru operátorů. Jak jste pochopili, potřebujeme jméno "ŠEK". Od té doby, co jsme použili tuto funkci při výpočtu v předchozí metodě je přítomen v tomto seznamu, takže na něj stačí kliknout. Pokud jej nenajdete, postupujte podle algoritmu popsaného v první metodě.
- Jednou v okně argumentů ŠEK, umístěte kurzor do pole "Číslo 1" a při stisknutém tlačítku myši vyberte kolekci. Poté klikněte na tlačítko "OK".
- Poté program provede výpočet a zobrazí hodnotu intervalu spolehlivosti.
- Pro určení hranic budeme opět muset vypočítat výběrový průměr. Ale vzhledem k tomu, že výpočetní algoritmus pomocí vzorce PRŮMĚRNÝ stejně jako u předchozího způsobu a ani výsledek se nezměnil, nebudeme se tím podruhé podrobně zabývat.
- Sčítání výsledků výpočtu PRŮMĚRNÝ A DŮVĚRNÍK.STUDENT, získáme pravou hranici intervalu spolehlivosti.
- Odečtením od výsledků výpočtu operátora PRŮMĚRNÝ výsledek výpočtu DŮVĚRNÍK.STUDENT, máme levou mez intervalu spolehlivosti.
- Pokud je výpočet zapsán v jednom vzorci, bude výpočet pravé hranice v našem případě vypadat takto:
AVERAGE(B2:B13)+CONFIDENCE.STUDENT(0,03;STDEV.B(B2:B13);COUNT(B2:B13))
- Podle toho bude vzorec pro výpočet levého okraje vypadat takto:
AVERAGE(B2:B13)-CONFIDENCE.STUDENT(0,03;STDEV.B(B2:B13);COUNT(B2:B13))













Jak vidíte, nástroje Excel programy umožňují výrazně zjednodušit výpočet intervalu spolehlivosti a jeho hranic. Pro tyto účely se používají samostatné operátory pro vzorky, jejichž rozptyl je známý a neznámý.
cílová– naučit studenty algoritmy pro výpočet intervalů spolehlivosti statistických parametrů.
Při statistickém zpracování dat by vypočítaný aritmetický průměr, variační koeficient, korelační koeficient, rozdílová kritéria a další bodové statistiky měly obdržet kvantitativní meze spolehlivosti, které indikují možné kolísání ukazatele v menším i větším směru v rámci intervalu spolehlivosti.
Příklad 3.1
.
Distribuce vápníku v krevním séru opic, jak bylo dříve stanoveno, je charakterizována následujícími ukazateli vzorku: = 11,94 mg%;  = 0,127 mg%; n= 100. Je nutné určit interval spolehlivosti pro obecný průměr (
= 0,127 mg%; n= 100. Je nutné určit interval spolehlivosti pro obecný průměr (  ) s pravděpodobností spolehlivosti P
= 0,95.
) s pravděpodobností spolehlivosti P
= 0,95.
Obecný průměr se s určitou pravděpodobností nachází v intervalu:
 , Kde
, Kde 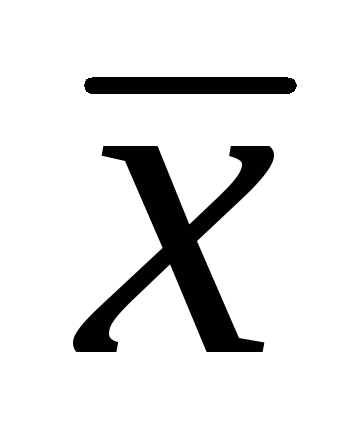 – výběrový aritmetický průměr; t- studentský test;
– výběrový aritmetický průměr; t- studentský test;  – chyba aritmetického průměru.
– chyba aritmetického průměru.
Pomocí tabulky „Hodnoty studentského t-testu“ zjistíme hodnotu
 s pravděpodobností spolehlivosti 0,95 a počtem stupňů volnosti k= 100-1 = 99. Rovná se 1,982. Spolu s hodnotami aritmetického průměru a statistické chyby dosadíme do vzorce:
s pravděpodobností spolehlivosti 0,95 a počtem stupňů volnosti k= 100-1 = 99. Rovná se 1,982. Spolu s hodnotami aritmetického průměru a statistické chyby dosadíme do vzorce:
nebo 11.69  12,19
12,19
S pravděpodobností 95 % lze tedy konstatovat, že obecný průměr tohoto normálního rozdělení se pohybuje mezi 11,69 a 12,19 mg %.
Příklad 3.2
. Určete meze 95% intervalu spolehlivosti pro obecný rozptyl ( ) distribuce vápníku v krvi opic, pokud je známo, že
) distribuce vápníku v krvi opic, pokud je známo, že  = 1,60, at n
= 100.
= 1,60, at n
= 100.
K vyřešení problému můžete použít následující vzorec:
Kde  – statistická chyba rozptylu.
– statistická chyba rozptylu.
Chybu výběrového rozptylu najdeme pomocí vzorce:  . Je roven 0,11. Význam t- kritérium s pravděpodobností spolehlivosti 0,95 a počtem stupňů volnosti k= 100–1 = 99 je známo z předchozího příkladu.
. Je roven 0,11. Význam t- kritérium s pravděpodobností spolehlivosti 0,95 a počtem stupňů volnosti k= 100–1 = 99 je známo z předchozího příkladu.
Použijeme vzorec a dostaneme:
nebo 1,38  1,82
1,82
Přesněji, interval spolehlivosti obecného rozptylu lze konstruovat pomocí  (chí-kvadrát) - Pearsonův test. Kritické body pro toto kritérium jsou uvedeny ve speciální tabulce. Při použití kritéria
(chí-kvadrát) - Pearsonův test. Kritické body pro toto kritérium jsou uvedeny ve speciální tabulce. Při použití kritéria  Pro konstrukci intervalu spolehlivosti se používá oboustranná hladina významnosti. Pro spodní hranici se hladina významnosti vypočítá pomocí vzorce
Pro konstrukci intervalu spolehlivosti se používá oboustranná hladina významnosti. Pro spodní hranici se hladina významnosti vypočítá pomocí vzorce  , na začátek -
, na začátek -  . Například pro úroveň spolehlivosti
. Například pro úroveň spolehlivosti  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Tedy podle tabulky rozdělení kritických hodnot
= 0,990. Tedy podle tabulky rozdělení kritických hodnot  s vypočítanými hladinami spolehlivosti a počtem stupňů volnosti k= 100 – 1= 99, najděte hodnoty
s vypočítanými hladinami spolehlivosti a počtem stupňů volnosti k= 100 – 1= 99, najděte hodnoty  A
A  . Dostaneme
. Dostaneme  rovná se 135,80 a
rovná se 135,80 a  rovná se 70,06.
rovná se 70,06.
Chcete-li najít limity spolehlivosti pro obecný rozptyl pomocí  Použijme vzorce: pro spodní hranici
Použijme vzorce: pro spodní hranici  , pro horní hranici
, pro horní hranici  . Nahraďte nalezené hodnoty za problémová data
. Nahraďte nalezené hodnoty za problémová data  do vzorců:
do vzorců:  =
1,17;
=
1,17; = 2,26. Tedy s pravděpodobností spolehlivosti P= 0,99 nebo 99% obecný rozptyl bude ležet v rozmezí od 1,17 do 2,26 mg% včetně.
= 2,26. Tedy s pravděpodobností spolehlivosti P= 0,99 nebo 99% obecný rozptyl bude ležet v rozmezí od 1,17 do 2,26 mg% včetně.
Příklad 3.3 . Mezi 1000 semeny pšenice ze šarže přijaté do výtahu bylo nalezeno 120 semen infikovaných námelem. Je nutné stanovit pravděpodobné hranice obecného podílu infikovaných semen v dané partii pšenice.
Je vhodné určit meze spolehlivosti pro obecný podíl pro všechny jeho možné hodnoty pomocí vzorce:
 ,
,
Kde n – počet pozorování; m– absolutní velikost jedné ze skupin; t– normalizovaná odchylka.
Vzorkový podíl infikovaných semen je  nebo 12 %. S jistotou pravděpodobnosti R= 95% normalizovaná odchylka ( t-Studentský test v k
=
nebo 12 %. S jistotou pravděpodobnosti R= 95% normalizovaná odchylka ( t-Studentský test v k
=
 )t
= 1,960.
)t
= 1,960.
Dostupná data dosadíme do vzorce:
Hranice intervalu spolehlivosti jsou tedy rovné  = 0,122–0,041 = 0,081 nebo 8,1 %;
= 0,122–0,041 = 0,081 nebo 8,1 %;  = 0,122 + 0,041 = 0,163 nebo 16,3 %.
= 0,122 + 0,041 = 0,163 nebo 16,3 %.
S pravděpodobností 95 % lze tedy konstatovat, že obecný podíl infikovaných semen se pohybuje mezi 8,1 a 16,3 %.
Příklad 3.4 . Variační koeficient charakterizující variaci vápníku (mg %) v krevním séru opic byl roven 10,6 %. Velikost vzorku n= 100. Pro obecný parametr je nutné určit hranice 95% intervalu spolehlivosti Životopis.
Meze intervalu spolehlivosti pro obecný variační koeficient Životopis se určují podle následujících vzorců:
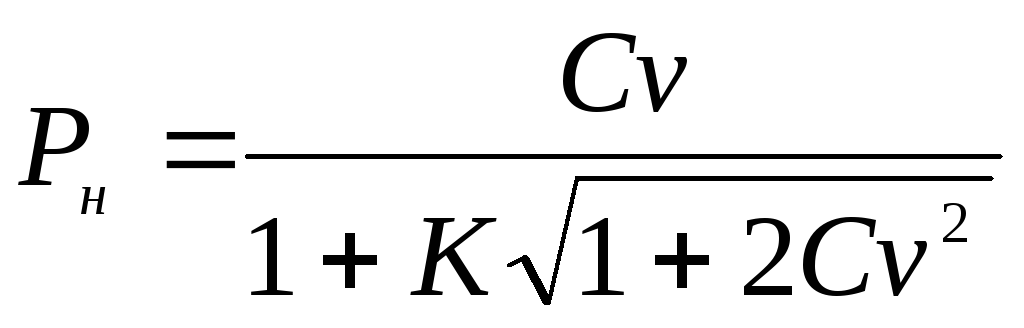 A
A  , Kde K
mezihodnota vypočtená podle vzorce
, Kde K
mezihodnota vypočtená podle vzorce  .
.
Vědět to s jistotou pravděpodobnosti R= 95% normalizovaná odchylka (Studentův test at k
=
 )t
= 1,960, nejprve vypočítejme hodnotu NA:
)t
= 1,960, nejprve vypočítejme hodnotu NA:
 .
.
 nebo 9,3 %
nebo 9,3 %
 nebo 12,3 %
nebo 12,3 %
Obecný variační koeficient s 95% hladinou spolehlivosti tedy leží v rozmezí od 9,3 do 12,3 %. U opakovaných vzorků variační koeficient nepřesáhne 12,3 % a nebude pod 9,3 % v 95 případech ze 100.
Otázky pro sebeovládání:

Problémy k samostatnému řešení.
1. Průměrné procento tuku v mléce během laktace krav kříženek Kholmogory bylo následující: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Stanovte intervaly spolehlivosti pro obecný průměr na 95% hladině spolehlivosti (20 bodů).
2. Na 400 hybridních rostlinách žita se první květy objevily v průměru 70,5 dne po zasetí. Standardní odchylka byla 6,9 dne. Určete chybu průměru a intervalu spolehlivosti pro obecný průměr a rozptyl na hladině významnosti W= 0,05 a W= 0,01 (25 bodů).
3. Při studiu délky listů 502 exemplářů jahodníku zahradního byly získány následující údaje:
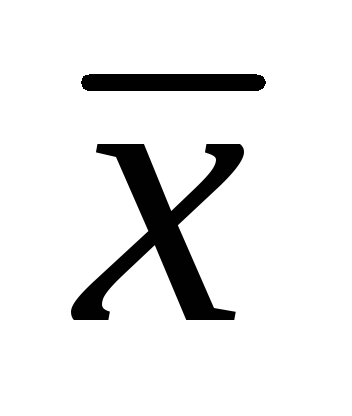 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  =± 0,06 cm Určete intervaly spolehlivosti pro aritmetický průměr populace s hladinami významnosti 0,01; 0,02; 0,05. (25 bodů).
=± 0,06 cm Určete intervaly spolehlivosti pro aritmetický průměr populace s hladinami významnosti 0,01; 0,02; 0,05. (25 bodů).
4. Ve studii 150 dospělých mužů byla průměrná výška 167 cm, a σ = 6 cm Jaké jsou meze obecného průměru a obecného rozptylu s pravděpodobností spolehlivosti 0,99 a 0,95? (25 bodů).
5. Distribuce vápníku v krevním séru opic je charakterizována následujícími selektivními ukazateli:
 = 11,94 mg %, σ
= 1,27, n
= 100. Sestrojte 95% interval spolehlivosti pro obecný průměr tohoto rozdělení. Vypočítejte variační koeficient (25 bodů).
= 11,94 mg %, σ
= 1,27, n
= 100. Sestrojte 95% interval spolehlivosti pro obecný průměr tohoto rozdělení. Vypočítejte variační koeficient (25 bodů).
6. Byl studován obecný obsah dusíku v krevní plazmě albínských potkanů ve věku 37 a 180 dnů. Výsledky jsou vyjádřeny v gramech na 100 cm 3 plazmy. Ve věku 37 dnů mělo 9 potkanů: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Ve věku 180 dnů mělo 8 potkanů: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Nastavte intervaly spolehlivosti pro rozdíl na úrovni spolehlivosti 0,95 (50 bodů).
7. Určete hranice 95% intervalu spolehlivosti pro obecný rozptyl distribuce vápníku (mg %) v krevním séru opic, pokud je pro tuto distribuci velikost vzorku n = 100, statistická chyba rozptylu vzorku s σ 2 = 1,60 (40 bodů).
8. Určete hranice 95% intervalu spolehlivosti pro obecný rozptyl distribuce 40 klásků pšenice po délce (σ 2 = 40,87 mm 2). (25 bodů).
9. Kouření je považováno za hlavní faktor predisponující k obstrukčním plicním chorobám. Pasivní kouření se za takový faktor nepovažuje. Vědci pochybovali o neškodnosti pasivního kouření a zkoumali propustnost dýchací trakt u nekuřáků, pasivních a aktivních kuřáků. Abychom charakterizovali stav dýchacího traktu, vzali jsme jeden z funkčních indikátorů vnější dýchání– maximální střední exspirační průtok. Pokles tohoto ukazatele je známkou obstrukce dýchacích cest. Údaje z průzkumu jsou uvedeny v tabulce.
|
Počet vyšetřených osob |
Maximální střední exspirační průtok, l/s |
||
|
Standardní odchylka |
|||
|
Nekuřáci |
|||
|
pracovat v nekuřáckém prostoru | |||
|
pracovat v zakouřené místnosti | |||
|
Kouření |
|||
|
vykouřit malé množství cigaret | |||
|
průměrný počet kuřáků cigaret | |||
|
kouřit velké množství cigaret | |||
Pomocí údajů z tabulky najděte 95% intervaly spolehlivosti pro celkový průměr a celkový rozptyl pro každou skupinu. Jaké jsou rozdíly mezi skupinami? Výsledky prezentujte graficky (25 bodů).
10. Určete hranice 95% a 99% intervalů spolehlivosti pro obecný rozptyl v počtu selat v 64 porodech, pokud statistická chyba rozptylu vzorku s σ 2 = 8,25 (30 bodů).
11. Je známo, že průměrná hmotnost králíků je 2,1 kg. Určete hranice 95% a 99% intervalu spolehlivosti pro obecný průměr a rozptyl při n= 30, σ = 0,56 kg (25 bodů).
12. Obsah zrn v klasu byl změřen pro 100 klasů ( X), délka ucha ( Y) a hmotnost zrna v klasu ( Z). Najděte intervaly spolehlivosti pro obecný průměr a rozptyl při P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 pokud
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064, (25 bodů).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064, (25 bodů).
13. U 100 náhodně vybraných klasů ozimé pšenice byl spočítán počet klásků. Vzorová populace byla charakterizována následujícími ukazateli:
 = 15 klásků a σ = 2,28 ks. Určete, s jakou přesností byl průměrný výsledek získán (
= 15 klásků a σ = 2,28 ks. Určete, s jakou přesností byl průměrný výsledek získán (  ) a sestrojte interval spolehlivosti pro obecný průměr a rozptyl na hladinách významnosti 95 % a 99 % (30 bodů).
) a sestrojte interval spolehlivosti pro obecný průměr a rozptyl na hladinách významnosti 95 % a 99 % (30 bodů).
14. Počet žeber na schránkách fosilních měkkýšů Orthamboniti kaligramma:
Je známo že n = 19, σ = 4,25. Určete hranice intervalu spolehlivosti pro obecný průměr a obecný rozptyl na hladině významnosti W = 0,01 (25 bodů).
15. Pro stanovení mléčné užitkovosti na komerční mléčné farmě byla denně stanovena užitkovost 15 krav. Podle údajů za rok dávala každá kráva v průměru za den následující množství mléka (l): 22; 19; 25; 20; 27; 17; třicet; 21; 18; 24; 26; 23; 25; 20; 24. Sestrojte intervaly spolehlivosti pro obecný rozptyl a aritmetický průměr. Můžeme očekávat průměrnou roční dojivost na krávu 10 000 litrů? (50 bodů).
16. Pro zjištění průměrného výnosu pšenice pro zemědělský podnik byla provedena kosba na zkušebních pozemcích o výměře 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 a 2 ha. Produktivita (c/ha) z ploch byla 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 resp. Sestrojte intervaly spolehlivosti pro obecný rozptyl a aritmetický průměr. Dá se očekávat, že průměrný zemědělský výnos bude 42 c/ha? (50 bodů).
Interval spolehlivosti k nám přichází z oblasti statistiky. Jedná se o určitý rozsah, který slouží k odhadu neznámého parametru s vysokou mírou spolehlivosti. Nejjednodušší způsob, jak to vysvětlit, je na příkladu.
Předpokládejme, že potřebujete prostudovat nějakou náhodnou veličinu, například rychlost odezvy serveru na požadavek klienta. Pokaždé, když uživatel zadá adresu konkrétního webu, server odpoví různou rychlostí. Zkoumaná doba odezvy je tedy náhodná. Interval spolehlivosti nám tedy umožňuje určit hranice tohoto parametru a pak můžeme říci, že s 95% pravděpodobností bude server v rozsahu, který jsme vypočítali.
Nebo potřebujete zjistit, kolik lidí o tom ví ochranná známka společnosti. Při výpočtu intervalu spolehlivosti bude možné například říci, že s 95% pravděpodobností se podíl spotřebitelů, kteří si to uvědomují, pohybuje v rozmezí od 27 % do 34 %.
S tímto pojmem úzce souvisí množství pravděpodobnost spolehlivosti. Představuje pravděpodobnost, že je požadovaný parametr zahrnut do intervalu spolehlivosti. Jak velký bude náš požadovaný rozsah, závisí na této hodnotě. Čím větší hodnota nabývá, tím užší je interval spolehlivosti a naopak. Obvykle je nastavena na 90 %, 95 % nebo 99 %. Hodnota 95 % je nejoblíbenější.
Tento ukazatel je také ovlivněn rozptylem pozorování a jeho definice je založena na předpokladu, že se studovaná charakteristika řídí tímto tvrzením, také známým jako Gaussův zákon. Normál je podle něj rozložení všech pravděpodobností spojité náhodné veličiny, které lze popsat hustotou pravděpodobnosti. Pokud je předpoklad o normální distribuce se ukázalo jako chybné, posouzení může být nesprávné.
Nejprve zjistíme, jak vypočítat interval spolehlivosti pro Existují dva možné případy. Disperze (míra šíření náhodné veličiny) může, ale nemusí být známa. Pokud je znám, pak se náš interval spolehlivosti vypočítá pomocí následujícího vzorce:
xsr - t*σ / (sqrt(n))<= α <= хср + t*σ / (sqrt(n)), где
α - znak,
t - parametr z Laplaceovy distribuční tabulky,
σ je druhá odmocnina z rozptylu.
Pokud je rozptyl neznámý, lze jej vypočítat, pokud známe všechny hodnoty požadovaného prvku. Chcete-li to provést, použijte následující vzorec:
σ2 = х2ср - (хср)2, kde
х2ср - průměrná hodnota druhých mocnin studované charakteristiky,
(хср)2 je druhá mocnina této charakteristiky.
Vzorec, podle kterého se interval spolehlivosti počítá, se v tomto případě mírně mění:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n)), где
xsr - průměr vzorku,
α - znak,
t je parametr, který se nachází pomocí Studentovy distribuční tabulky t = t(ɣ;n-1),
sqrt(n) - druhá odmocnina z celkové velikosti vzorku,
s je druhá odmocnina rozptylu.
Zvažte tento příklad. Předpokládejme, že na základě výsledků 7 měření byla stanovena studovaná charakteristika rovna 30 a výběrový rozptyl rovna 36. Je nutné najít s pravděpodobností 99 % interval spolehlivosti, který obsahuje skutečnou hodnotu hodnotu měřeného parametru.
Nejprve určíme, čemu se t rovná: t = t (0,99; 7-1) = 3,71. Pomocí výše uvedeného vzorce dostaneme:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n))
30 – 3,71*36 / (sqrt(7))<= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
Interval spolehlivosti pro rozptyl se počítá jak v případě známého průměru, tak v případě, kdy nejsou k dispozici údaje o matematickém očekávání a je známa pouze hodnota bodového nezkresleného odhadu rozptylu. Vzorce pro jeho výpočet zde nebudeme uvádět, protože jsou poměrně složité a v případě potřeby je lze vždy najít na internetu.
Poznamenejme pouze, že je vhodné určit interval spolehlivosti pomocí Excelu nebo síťové služby, která se tak nazývá.







