Introducción
¿Los fenómenos aleatorios están sujetos a alguna ley? Sí, pero estas leyes son diferentes a las que estamos acostumbrados. leyes fisicas. Los valores de SV no se pueden predecir ni siquiera en condiciones experimentales conocidas; sólo podemos indicar las probabilidades de que SV tome uno u otro valor. Pero conociendo la distribución de probabilidad de los SV, podemos sacar conclusiones sobre los eventos en los que participan estas variables aleatorias. Es cierto que estas conclusiones también serán de naturaleza probabilística.
Dejemos que algún SV sea discreto, es decir Solo se pueden tomar valores fijos Xi. En este caso, la serie de valores de probabilidad P(Xi) para todos (i=1…n) valores permisibles de esta cantidad se denomina ley de distribución.
La ley de distribución de SV es una relación que establece una conexión entre los posibles valores de SV y las probabilidades con las que se aceptan esos valores. La ley de distribución caracteriza completamente al SV.
al construir modelo matemático para comprobar hipótesis estadística es necesario introducir una suposición matemática sobre la ley de distribución de SV (forma paramétrica de construir el modelo).
El enfoque no paramétrico para describir el modelo matemático (SV no tiene una ley de distribución paramétrica) es menos preciso, pero tiene un alcance más amplio.
Al igual que para la probabilidad de un evento aleatorio, para la ley de distribución de SV sólo hay dos formas de encontrarla. O construimos un diagrama de un evento aleatorio y encontramos una expresión analítica (fórmula) para calcular la probabilidad (¡tal vez alguien ya lo haya hecho o lo hará por nosotros!), o tendremos que usar un experimento y, en base a las frecuencias de observaciones, hacer algunas suposiciones (presentar hipótesis) sobre las distribuciones de leyes.
Por supuesto, para cada una de las distribuciones "clásicas", este trabajo se ha realizado durante mucho tiempo: las distribuciones binomiales y polinómicas, geométricas e hipergeométricas, de Pascal y Poisson, y muchas otras, son ampliamente conocidas y muy utilizadas en estadística aplicada.
Para casi todas las distribuciones clásicas, se construyeron y publicaron inmediatamente tablas estadísticas especiales, que se perfeccionaron a medida que aumentaba la precisión de los cálculos. Sin el uso de muchos volúmenes de estas tablas, sin entrenamiento en las reglas para usarlas, el uso práctico de la estadística ha sido imposible durante los últimos dos siglos.
Hoy la situación ha cambiado: no es necesario almacenar datos de cálculo mediante fórmulas (¡por muy complejas que sean estas últimas!), el tiempo para utilizar la ley de distribución en la práctica se ha reducido a minutos o incluso segundos. Para estos fines ya existe un número suficiente de diferentes paquetes de software de aplicación.
Entre todas las distribuciones de probabilidad, existen aquellas que se utilizan con especial frecuencia en la práctica. Estas distribuciones se han estudiado en detalle y sus propiedades son bien conocidas. Muchas de estas distribuciones subyacen a campos completos del conocimiento, como la teoría hacer cola, teoría de la confiabilidad, control de calidad, teoría de juegos, etc.
Entre ellos, no se puede dejar de prestar atención a los trabajos de Poisson (1781-1840), quien demostró una forma más general de la ley de los grandes números que Jacob Bernoulli, y también aplicó por primera vez la teoría de la probabilidad a problemas de disparo. . El nombre de Poisson está asociado a una de las leyes de la distribución, que juega un papel importante en la teoría de la probabilidad y sus aplicaciones.
Es a esta ley de distribución a la que está dedicado este artículo. trabajo del curso. Se trata de directamente sobre la ley, sobre sus características matemáticas, propiedades especiales, conexión con la distribución binomial. Se dirán algunas palabras sobre la aplicación práctica y se darán varios ejemplos de la práctica.
El propósito de nuestro ensayo es aclarar la esencia de los teoremas de distribución de Bernoulli y Poisson.
La tarea es estudiar y analizar la literatura sobre el tema del ensayo.
1. Distribución binomial (distribución de Bernoulli)
Distribución binomial (distribución de Bernoulli): distribución de probabilidad del número de ocurrencias de algún evento repetido pruebas independientes, si la probabilidad de ocurrencia de este evento en cada ensayo es p (0
Se dice que SV X está distribuido según la ley de Bernoulli con parámetro p si toma valores 0 y 1 con probabilidades pX(x)ºP(X=x) = pxq1-x; p+q=1; x=0,1.
La distribución binomial surge en los casos en que se plantea la pregunta: ¿cuántas veces ocurre un determinado evento en una serie de un cierto número de observaciones (experimentos) independientes realizadas en las mismas condiciones?
Por conveniencia y claridad, asumiremos que conocemos el valor p - la probabilidad de que un visitante que ingrese a la tienda resulte ser un comprador y (1- p) = q - la probabilidad de que un visitante que ingrese a la tienda no sea un comprador.
Si X es el número de compradores del número total de n visitantes, entonces la probabilidad de que haya k compradores entre los n visitantes es igual a
P(X= k) = , donde k=0,1,…n 1)
La fórmula (1) se llama fórmula de Bernoulli. Con un gran número de pruebas, la distribución binomial tiende a ser normal.

Una prueba de Bernoulli es un experimento de probabilidad con dos resultados, que generalmente se denominan "éxito" (generalmente indicado por el símbolo 1) y "fracaso" (indicados respectivamente por 0). La probabilidad de éxito generalmente se indica con la letra p, el fracaso, con la letra q; por supuesto q=1-p. El valor p se denomina parámetro de prueba de Bernoulli.
Las variables aleatorias binomiales, geométricas, pascales y binomiales negativas se obtienen a partir de una secuencia de ensayos independientes de Bernoulli si la secuencia termina de una manera u otra, por ejemplo después del enésimo ensayo o del xésimo éxito. Comúnmente se utiliza la siguiente terminología:
– parámetro de prueba de Bernoulli (probabilidad de éxito en una sola prueba);
– número de pruebas;
– número de éxitos;
– número de fallos.
Variable aleatoria binomial (m|n,p): el número de m éxitos en n ensayos.
Variable aleatoria geométrica G(m|p): el número m de ensayos hasta el primer éxito (incluido el primer éxito).
Variable aleatoria Pascal C(m|x,p): el número m de ensayos hasta el x-ésimo éxito (sin incluir, por supuesto, el x-ésimo éxito en sí).
Variable aleatoria binomial negativa Y(m|x,p): el número m de fracasos antes del x-ésimo éxito (sin incluir el x-ésimo éxito).
Nota: a veces la distribución binomial negativa se denomina distribución de Pascal y viceversa.
distribución de veneno
2.1. Definición de la ley de Poisson
En muchos problemas prácticos hay que tratar con variables aleatorias distribuidas según una ley peculiar, que se llama ley de Poisson.
Consideremos una variable aleatoria discontinua X, que sólo puede tomar valores enteros, no negativos: 0, 1, 2,..., m,...; y la secuencia de estos valores es teóricamente ilimitada. Se dice que una variable aleatoria X está distribuida según la ley de Poisson si la probabilidad de que tome un determinado valor m se expresa mediante la fórmula:
![]()
donde a es una cantidad positiva llamada parámetro de la ley de Poisson.
Rango de distribución variable aleatoria X, distribuido según la ley de Poisson, tiene el siguiente aspecto:
| xm | … | metro | … | |||
| Pm | e-a | … | … |
2.2.Principales características de la distribución de Poisson
Primero, asegurémonos de que la secuencia de probabilidades pueda ser una serie de distribución, es decir, que la suma de todas las probabilidades Рm es igual a uno.
![]()
Usamos la expansión de la función ex en la serie de Maclaurin:
![]()
Se sabe que esta serie converge para cualquier valor de x, por lo tanto, tomando x = a, obtenemos
![]()
por eso
![]()
Definamos las características principales: valor esperado y varianza: una variable aleatoria X distribuida según la ley de Poisson. La expectativa matemática de una variable aleatoria discreta es la suma de los productos de todos sus valores posibles y sus probabilidades. Por definición, cuando una variable aleatoria discreta toma un conjunto contable de valores:
![]()
El primer término de la suma (correspondiente a m=0) es igual a cero, por lo tanto, la sumatoria puede comenzar con m=1:
Por tanto, el parámetro a no es más que la expectativa matemática de la variable aleatoria X.
La varianza de una variable aleatoria X es la expectativa matemática de la desviación al cuadrado de una variable aleatoria de su expectativa matemática:
Sin embargo, es más conveniente calcularlo mediante la fórmula:
Por lo tanto, busquemos primero el segundo. momento inicial valores X:

Según lo demostrado previamente
![]()
Además,
![]()
2.3.Características adicionales de la distribución de Poisson
I. El momento inicial de orden k de una variable aleatoria X es la esperanza matemática del valor Xk:
En particular, el momento inicial de primer orden es igual a la expectativa matemática:
II. El momento central de orden k de una variable aleatoria X es la expectativa matemática del valor k:
En particular, el momento central de primer orden es 0:
µ1=M=0,
el momento central de segundo orden es igual a la dispersión:
µ2=M2=a.
III. Para una variable aleatoria X distribuida según la ley de Poisson, encontramos la probabilidad de que tome un valor no menor que el k dado. Esta probabilidad la denotamos por Rk:
![]()
Obviamente, la probabilidad Rk se puede calcular como la suma
![]()
Sin embargo, es mucho más fácil determinarlo a partir de la probabilidad. evento opuesto:
![]()
En particular, la probabilidad de que el valor de X tome un valor positivo se expresa mediante la fórmula
![]()
Como ya se mencionó, muchos problemas de práctica dan como resultado una distribución de Poisson. Consideremos uno de los problemas típicos de este tipo.
|

Deje que los puntos se distribuyan aleatoriamente en el eje x Ox (Fig. 2). Supongamos que la distribución aleatoria de puntos satisface siguientes condiciones:
1) La probabilidad de que un número particular de puntos caiga en un segmento l depende únicamente de la longitud de este segmento, pero no depende de su posición en el eje de abscisas. En otras palabras, los puntos se distribuyen en el eje x con la misma densidad promedio. Denotemos esta densidad, es decir Expectativa matemática del número de puntos por unidad de longitud, expresada a través de λ.
2) Los puntos se distribuyen en el eje x independientemente unos de otros, es decir la probabilidad de que un número particular de puntos caiga en un segmento dado no depende de cuántos de ellos caigan en cualquier otro segmento que no se superponga con él.
3) La probabilidad de que dos o más puntos caigan en un área pequeña Δx es insignificante en comparación con la probabilidad de que caiga un punto (esta condición significa la imposibilidad práctica de que dos o más puntos coincidan).
Seleccionemos un determinado segmento de longitud l en el eje de abscisas y consideremos una variable aleatoria discreta X: el número de puntos que caen en este segmento. Valores posibles los valores serán 0,1,2,...,m,... Dado que los puntos caen en el segmento independientemente unos de otros, es teóricamente posible que haya tantos como se desee, es decir, estas series continúa indefinidamente.
Demostremos que la variable aleatoria X se distribuye según la ley de Poisson. Para hacer esto, es necesario calcular la probabilidad Pm de que exactamente m puntos caigan en el segmento.
Primero resolvamos más. Tarea simple. Consideremos un área pequeña Δx en el eje Ox y calculemos la probabilidad de que al menos un punto caiga en esta área. Razonaremos de la siguiente manera. La expectativa matemática del número de puntos que caen en esta sección es obviamente igual a λ·Δх (ya que en promedio λ puntos caen por unidad de longitud). Según la condición 3, para un segmento pequeño Δx podemos despreciar la posibilidad de que dos o más puntos caigan sobre él. Por lo tanto, la expectativa matemática λ·Δх del número de puntos que caen sobre el área Δх será aproximadamente igual a la probabilidad de que un punto caiga sobre ella (o, lo que es equivalente en estas condiciones, al menos uno).
Así, hasta un valor infinitesimal orden superior, para Δх→0 podemos considerar que la probabilidad de que un (al menos un) punto caiga en la sección Δх es igual a λ·Δх, y la probabilidad de que ninguno caiga igual a 1-c·Δх.
Usemos esto para calcular la probabilidad Pm de que exactamente m puntos caigan en el segmento l. Dividamos el segmento l en n partes iguales de longitud. Acordamos llamar al segmento elemental Δx “vacío” si no contiene un solo punto, y “ocupado” si al menos uno ocurre. De acuerdo con lo anterior, la probabilidad de que el segmento Δх sea “ocupado” es aproximadamente igual a λ·Δх= ; la probabilidad de que esté "vacío" es 1-. Dado que, según la condición 2, los puntos que caen en segmentos que no se superponen son independientes, entonces nuestros n segmentos pueden considerarse como n "experimentos" independientes, en cada uno de los cuales el segmento puede "ocuparse" con probabilidad p=. Encontremos la probabilidad de que entre n segmentos haya exactamente m "ocupados". Según el teorema de los ensayos independientes repetidos, esta probabilidad es igual a
![]() ,
,
o denotemos λl=a:
![]() .
.
Para un n suficientemente grande, esta probabilidad es aproximadamente igual a la probabilidad de que exactamente m puntos caigan en el segmento l, ya que la probabilidad de que dos o más puntos caigan en el segmento Δx es insignificante. Para encontrar valor exactoРm, necesitas ir al límite como n→∞:

Teniendo en cuenta que
![]()
 ,
,
encontramos que la probabilidad deseada se expresa mediante la fórmula
donde a=λl, es decir el valor de X se distribuye según la ley de Poisson con el parámetro a=λl.
Cabe señalar que el valor a en significado representa el número promedio de puntos por segmento l. El valor de R1 (la probabilidad de que el valor de X tome un valor positivo) en en este caso expresa la probabilidad de que al menos un punto caiga en el segmento l: R1=1-e-a.
Por tanto, estamos convencidos de que la distribución de Poisson se produce cuando algunos puntos (u otros elementos) ocupan una posición aleatoria independientemente unos de otros, y se cuenta el número de estos puntos que caen en un área determinada. En nuestro caso, dicha área era el segmento l en el eje de abscisas. Sin embargo, esta conclusión puede extenderse fácilmente al caso de distribución de puntos en el plano (campo plano aleatorio de puntos) y en el espacio (campo espacial aleatorio de puntos). No es difícil demostrar que si se cumplen las condiciones:
1) los puntos se distribuyen estadísticamente uniformemente en el campo con una densidad promedio λ;
2) los puntos caen independientemente en regiones que no se superponen;
3) los puntos aparecen solos y no en pares, trillizos, etc.,
entonces el número de puntos X que caen en cualquier región D (plana o espacial) se distribuye según la ley de Poisson:
![]() ,
,
donde a es el número promedio de puntos que caen en el área D.
Para un caso plano a=SD λ, donde SD es el área de la región D,
para espacial a= VD λ, donde VD es el volumen de la región D.
Para una distribución de Poisson del número de puntos que caen en un segmento o región, la condición de densidad constante (λ=const) no es importante. Si se cumplen las otras dos condiciones, entonces la ley de Poisson sigue siendo válida, solo que el parámetro a adquiere una expresión diferente: se obtiene no simplemente multiplicando la densidad λ por la longitud, el área o el volumen, sino integrando la densidad variable. sobre el segmento, área o volumen.
La distribución de Poisson juega papel importante en una serie de temas de física, teoría de la comunicación, teoría de la confiabilidad, teoría de colas, etc. Cualquier lugar donde pueda ocurrir un número aleatorio de eventos (desintegraciones radiactivas, llamadas telefónicas, fallas de equipos, accidentes, etc.) durante un período de tiempo determinado.
Consideremos la situación más típica en la que surge la distribución de Poisson. Deje que algunos eventos (compras en tiendas) ocurran en momentos aleatorios. Determinemos el número de ocurrencias de tales eventos en el intervalo de tiempo de 0 a T.
El número aleatorio de eventos que ocurrieron durante el tiempo de 0 a T se distribuye de acuerdo con la ley de Poisson con el parámetro l=aT, donde a>0 es un parámetro del problema que refleja la frecuencia promedio de eventos. La probabilidad de realizar k compras durante un intervalo de tiempo grande (por ejemplo, un día) será
Conclusión
En conclusión, me gustaría señalar que la distribución de Poisson es una distribución bastante común e importante, que tiene aplicación tanto en la teoría de la probabilidad como en sus aplicaciones, y en estadística matemática.
En última instancia, muchos problemas prácticos se reducen a la distribución de Poisson. Su propiedad especial, que consiste en la igualdad de la expectativa y la varianza matemática, se utiliza a menudo en la práctica para resolver la cuestión de si una variable aleatoria se distribuye según la ley de Poisson o no.
También es importante el hecho de que la ley de Poisson permite encontrar las probabilidades de un evento en ensayos independientes repetidos con un gran número de repeticiones del experimento y una probabilidad única pequeña.
Sin embargo, la distribución de Bernoulli se utiliza muy raramente en la práctica de los cálculos económicos y, en particular, en el análisis de estabilidad. Esto se debe tanto a dificultades computacionales como al hecho de que la distribución de Bernoulli es para cantidades discretas, y con el hecho de que las condiciones del esquema clásico (independencia, número contable de pruebas, invariancia de las condiciones que afectan la posibilidad de que ocurra un evento) no siempre se cumplen en situaciones prácticas. Más investigaciones en el campo del análisis del esquema de Bernoulli, realizadas en los siglos XVIII-XIX. Laplace, Moivre, Poisson y otros tenían como objetivo crear la posibilidad de utilizar el esquema de Bernoulli en el caso de un gran número de pruebas que tienden al infinito.
Literatura
1. Ventzel E.S. Teoría de probabilidad. - M, "Escuela Superior" 1998
2. Gmurman V.E. Una guía para resolver problemas en teoría de probabilidad y estadística matemática. - M, "Escuela Superior" 1998
3. Colección de problemas de matemáticas para colegios. Ed. Efimova A.V. - M, Ciencias 1990
Consideremos la distribución de Poisson, calculemos su expectativa matemática, varianza y moda. Usando la función de MS EXCEL POISSON.DIST(), construiremos gráficas de la función de distribución y la densidad de probabilidad. Estimemos el parámetro de distribución, su expectativa matemática y su desviación estándar.
Primero, damos una definición formal seca de distribución, luego damos ejemplos de situaciones en las que distribución de veneno(Inglés) Poisondistribución) es un modelo adecuado para describir una variable aleatoria.
Si ocurren eventos aleatorios en un período de tiempo determinado (o en un cierto volumen de materia) con frecuencia promedio λ( lambda), entonces el número de eventos X, ocurrido durante este período de tiempo tendrá distribución de veneno.
Aplicación de la distribución de Poisson
Ejemplos cuando distribución de veneno es un modelo adecuado:
- el número de llamadas recibidas en la central telefónica durante un determinado período de tiempo;
- la cantidad de partículas que han sufrido desintegración radiactiva durante un cierto período de tiempo;
- Número de defectos en un trozo de tela de longitud fija.
distribución de veneno Es un modelo adecuado si se cumplen las siguientes condiciones:
- Los eventos ocurren independientemente unos de otros, es decir. la probabilidad de un evento posterior no depende del anterior;
- la tasa promedio de eventos es constante. Como consecuencia, la probabilidad de un evento es proporcional a la duración del intervalo de observación;
- dos acontecimientos no pueden ocurrir al mismo tiempo;
- el número de eventos debe tomar el valor 0; 1; 2…
Nota: Una buena pista es que la variable aleatoria observada tiene Distribución de veneno, es el hecho de que es aproximadamente igual (ver más abajo).
A continuación se muestran ejemplos de situaciones en las que distribución de veneno no puedo se aplicado:
- el número de estudiantes que abandonan la universidad en una hora (ya que el flujo promedio de estudiantes no es constante: durante las clases hay pocos estudiantes y durante el descanso entre clases el número de estudiantes aumenta considerablemente);
- número de terremotos de magnitud 5 por año en California (ya que un terremoto puede causar réplicas de amplitud similar; los eventos no son independientes);
- número de días que los pacientes pasan en el departamento cuidados intensivos(porque el número de días que los pacientes pasan en la unidad de cuidados intensivos es siempre mayor que 0).
Nota: distribución de veneno es una aproximación más precisa distribuciones discretas: Y .
Nota: Sobre la relación distribución de veneno Y Distribución binomial se puede leer en el artículo. sobre la relación distribución de veneno Y Distribución exponencial se puede leer en el artículo sobre.
Distribución de Poisson en MS EXCEL
En MS EXCEL, a partir de la versión 2010, para Distribuciones Poison hay una función POISSON.DIST(), nombre inglés- POISSON.DIST(), que le permite calcular no solo la probabilidad de lo que sucederá en un período de tiempo determinado X eventos (función densidad de probabilidad p(x), ver fórmula arriba), pero también (la probabilidad de que durante un período de tiempo determinado al menos X eventos).
Antes de MS EXCEL 2010, EXCEL tenía la función POISSON(), que también permite calcular función de distribución Y densidad de probabilidad p(x). POISSON() se deja en MS EXCEL 2010 por compatibilidad.
El archivo de ejemplo contiene gráficos. distribución de densidad de probabilidad Y función de distribución acumulativa.

distribución de veneno tiene una forma sesgada (una cola larga en el lado derecho de la función de probabilidad), pero a medida que aumenta el parámetro λ, se vuelve cada vez más simétrico.
Nota: Promedio Y dispersión(cuadrado) son iguales al parámetro distribución de veneno– λ (ver ejemplo de archivo de hoja Ejemplo).
Tarea
Aplicación tipica Distribuciones de Poisson En control de calidad es un modelo del número de defectos que pueden aparecer en un instrumento o dispositivo.
Por ejemplo, con un número promedio de defectos en un chip λ (lambda) igual a 4, la probabilidad de que un chip seleccionado al azar tenga 2 o menos defectos es: = DISTR.POISSON(2,4,VERDADERO)=0.2381
El tercer parámetro de la función se establece = VERDADERO, por lo que la función devolverá función de distribución acumulativa, es decir, la probabilidad de que el número de eventos aleatorios esté en el rango de 0 a 4 inclusive.
Los cálculos en este caso se realizan según la fórmula:
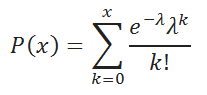
La probabilidad de que un microcircuito seleccionado al azar tenga exactamente 2 defectos es: = DISTR.POISSON(2,4,FALSO)=0,1465
El tercer parámetro de la función se establece = FALSO, por lo que la función devolverá la densidad de probabilidad.
La probabilidad de que un microcircuito seleccionado al azar tenga más de 2 defectos es igual a: =1-DIST.POISSON(2,4,VERDADERO) =0.8535
Nota: Si X no es un número entero, entonces al calcular la fórmula. Fórmulas =DIST.POISSON( 2 ; 4; MENTIR) Y =DIST.POISSON( 2,9 ; 4; MENTIR) devolverá el mismo resultado.
Generación de números aleatorios y estimación de λ.
Para valores de λ >15 , distribución de veneno bien aproximado Distribución normal con los siguientes parámetros: μ =λ , s 2 =λ .
Se pueden encontrar más detalles sobre la relación entre estas distribuciones en el artículo. También hay ejemplos de aproximación y se explican las condiciones sobre cuándo es posible y con qué precisión.
CONSEJO: Puede leer sobre otras distribuciones de MS EXCEL en el artículo.
En muchas aplicaciones prácticamente importantes, la distribución de Poisson juega un papel importante. Muchas de las cantidades numéricas discretas son implementaciones de un proceso de Poisson, que tiene las siguientes propiedades:
- Nos interesa saber cuántas veces ocurre un determinado evento en un área determinada. posibles resultados experimento aleatorio. El área de posibles resultados puede ser un intervalo de tiempo, un segmento, una superficie, etc.
- La probabilidad de un evento dado es la misma para todas las áreas de resultados posibles.
- La cantidad de eventos que ocurren en un área de posibles resultados es independiente de la cantidad de eventos que ocurren en otras áreas.
- La probabilidad de que un evento determinado ocurra más de una vez en la misma área de resultados posibles tiende a cero a medida que disminuye el área de resultados posibles.
Para comprender mejor el significado del proceso de Poisson, supongamos que examinamos el número de clientes que visitan una sucursal bancaria ubicada en el distrito central de negocios durante el almuerzo, es decir, de 12 a 13 horas. Suponga que desea determinar la cantidad de clientes que llegan en un minuto. ¿Tiene esta situación las características enumeradas anteriormente? Primero, el evento que nos interesa es la llegada de un cliente, y el rango de resultados posibles es un intervalo de un minuto. ¿Cuántos clientes acudirán al banco en un minuto: ninguno, uno, dos o más? En segundo lugar, es razonable suponer que la probabilidad de que un cliente llegue en un minuto es la misma en todos los intervalos de un minuto. En tercer lugar, la llegada de un cliente durante cualquier intervalo de un minuto es independiente de la llegada de cualquier otro cliente durante cualquier otro intervalo de un minuto. Y finalmente, la probabilidad de que más de un cliente acuda al banco tiende a cero si el intervalo de tiempo tiende a cero, por ejemplo, se vuelve inferior a 0,1 s. Entonces, la distribución de Poisson describe el número de clientes que vienen al banco durante el almuerzo en un minuto.
La distribución de Poisson tiene un parámetro, denotado por el símbolo λ (letra griega "lambda"): el número promedio de pruebas exitosas en una región determinada de resultados posibles. La varianza de la distribución de Poisson también es λ y su desviación estándar es . Número de ensayos exitosos X La variable aleatoria de Poisson varía de 0 a infinito. La distribución de Poisson se describe mediante la fórmula:

Dónde P(X)- probabilidad X ensayos exitosos, λ - número esperado de éxitos, mi- base logaritmo natural, igual a 2,71828, X- número de éxitos por unidad de tiempo.
Volvamos a nuestro ejemplo. Digamos que durante la pausa del almuerzo, una media de tres clientes por minuto llegan al banco. ¿Cuál es la probabilidad de que dos clientes acudan al banco en un momento dado? ¿Cuál es la probabilidad de que acudan más de dos clientes al banco?
Apliquemos la fórmula (1) con el parámetro λ = 3. Entonces la probabilidad de que dos clientes acudan al banco en un minuto determinado es igual a
La probabilidad de que acudan más de dos clientes al banco es igual a P(X > 2) = P(X = 3) + P(X = 4) + … + P(X = ∞). Dado que la suma de todas las probabilidades debe ser igual a 1, los términos de la serie en el lado derecho de la fórmula representan la probabilidad de suma al evento X ≤ 2. En otras palabras, la suma de esta serie es igual a 1 – P(X ≤ 2). Así, P(X>2) = 1 – P(X≤2) = 1 – [P(X = 0) + P(X = 1) + P(X = 2)]. Ahora, usando la fórmula (1), obtenemos:
Así, la probabilidad de que no más de dos clientes acudan al banco en un minuto es de 0,423 (o 42,3%), y la probabilidad de que más de dos clientes acudan al banco en un minuto es de 0,577 (o 57,7%).
Estos cálculos pueden parecer tediosos, especialmente si el parámetro λ es lo suficientemente grande. Para evitar cálculos complejos, muchas probabilidades de Poisson se pueden encontrar en tablas especiales (Fig. 1). Por ejemplo, la probabilidad de que dos clientes vengan al banco en un minuto determinado, si en promedio vienen tres clientes al banco por minuto, está en la intersección de la línea X= 2 y columna λ = 3. Por tanto, es igual a 0,2240 o 22,4%.

Arroz. 1. Probabilidad de Poisson en λ = 3
Hoy en día, es poco probable que alguien utilice tablas si dispone de Excel con su función =POISSON.DIST() (Fig. 2). Esta función tiene tres parámetros: número de pruebas exitosas X, número promedio esperado de ensayos exitosos λ, parámetro Integral, tomando dos valores: FALSO – en este caso se calcula la probabilidad del número de intentos exitosos X(solo X), VERDADERO: en este caso, la probabilidad del número de intentos exitosos de 0 a X.

Arroz. 2. Cálculo en Excel de las probabilidades de la distribución de Poisson en λ = 3
Aproximación de la distribución binomial mediante la distribución de Poisson
si el numero norte es grande y el numero R- pequeña, la distribución binomial se puede aproximar utilizando la distribución de Poisson. Cómo numero mayor norte y menos numero R, mayor será la precisión de la aproximación. Se utiliza el siguiente modelo de Poisson para aproximar la distribución binomial.

Dónde P(X)- probabilidad Xéxito con los parámetros dados norte Y R, norte- tamaño de la muestra, R- verdadera probabilidad de éxito, mi- la base del logaritmo natural, X- número de éxitos en la muestra (X = 0, 1, 2,…, norte).
Teóricamente, una variable aleatoria con distribución de Poisson toma valores de 0 a ∞. Sin embargo, en situaciones donde se utiliza la distribución de Poisson para aproximar la distribución binomial, la variable aleatoria de Poisson es el número de éxitos entre norte observaciones - no puede exceder el número norte. De la fórmula (2) se deduce que a medida que aumenta el número norte y una disminución en el número R la probabilidad de detectar una gran cantidad de éxitos disminuye y tiende a cero.
Como se mencionó anteriormente, la expectativa µ y la varianza σ 2 de la distribución de Poisson son iguales a λ. Por lo tanto, al aproximar la distribución binomial utilizando la distribución de Poisson, se debe utilizar la fórmula (3) para aproximar la expectativa matemática.
(3) µ = E(X) = λ =notario público.
Para aproximar la desviación estándar, se utiliza la fórmula (4).
![]()
Tenga en cuenta que la desviación estándar calculada con la fórmula (4) tiende a Desviación Estándar en el modelo binomial – cuando la probabilidad de éxito pag tiende a cero y, en consecuencia, la probabilidad de falla 1-pag tiende a la unidad.
Supongamos que el 8% de los neumáticos producidos en una determinada planta están defectuosos. Para ilustrar el uso de la distribución de Poisson para aproximar la distribución binomial, calculemos la probabilidad de encontrar una llanta defectuosa en una muestra de 20 llantas. Apliquemos la fórmula (2), obtenemos

Si tuviéramos que calcular la distribución binomial verdadera en lugar de su aproximación, obtendríamos el siguiente resultado:

Sin embargo, estos cálculos son bastante tediosos. Sin embargo, si utiliza Excel para calcular probabilidades, utilizar la aproximación de distribución de Poisson se vuelve redundante. En la Fig. La Figura 3 muestra que la complejidad de los cálculos en Excel es la misma. Sin embargo, esta sección, en mi opinión, es útil para comprender que bajo algunas condiciones la distribución binomial y la distribución de Poisson dan resultados similares.

Arroz. 3. Comparación de la complejidad de los cálculos en Excel: (a) distribución de Poisson; (b) distribución binomial
Así, en esta y dos notas anteriores, se consideraron tres distribuciones numéricas discretas: , y Poisson. Para comprender mejor cómo se relacionan estas distribuciones entre sí, presentamos un pequeño árbol de preguntas (Fig. 4).

Arroz. 4. Clasificación de distribuciones de probabilidad discretas.
Se utilizan materiales del libro Levin et al. – M.: Williams, 2004. – pág. 320–328
Distribución de veneno.
Consideremos la situación más típica en la que surge la distribución de Poisson. deja que el evento A Aparece un número determinado de veces en un área fija del espacio (intervalo, área, volumen) o en un período de tiempo con intensidad constante. Para ser específico, considere la ocurrencia secuencial de eventos a lo largo del tiempo, llamada secuencia de eventos. Gráficamente, el flujo de eventos se puede ilustrar mediante muchos puntos ubicados en el eje del tiempo.
Esto podría ser un flujo de llamadas en el sector de servicios (reparación electrodomésticos, llamar a una ambulancia, etc.), el flujo de llamadas a la central telefónica, fallo de algunas partes del sistema, desintegración radiactiva, trozos de tela o láminas de metal y el número de defectos en cada uno de ellos, etc. La distribución de Poisson Es más útil en aquellas tareas donde se requiere determinar sólo el número de resultados positivos (“éxitos”).
Imaginemos un bollo con pasas, dividido en pequeños trozos de igual tamaño. Debido a distribución aleatoria pasas, no se puede esperar que todas las piezas contengan la misma cantidad de pasas. Cuando se conoce el número promedio de pasas contenidas en estas piezas, entonces la distribución de Poisson da la probabilidad de que cualquier pieza dada contenga X=k(k= 0,1,2,...,)número de pasas.
En otras palabras, la distribución de Poisson determina qué parte de una larga serie de piezas contendrá igual a 0, 1, 2, etc. número de puntos destacados.
Hagamos las siguientes suposiciones.
1. La probabilidad de que ocurra un cierto número de eventos en un intervalo de tiempo determinado depende únicamente de la duración de este intervalo y no de su posición en el eje del tiempo. Ésta es la propiedad de la estacionariedad.
2. La ocurrencia de más de un evento en un período de tiempo suficientemente corto es prácticamente imposible, es decir la probabilidad condicional de que ocurra otro evento en el mismo intervalo tiende a cero cuando ® 0. Ésta es la propiedad de la normalidad.
3. La probabilidad de que ocurra un número determinado de eventos en un período de tiempo fijo no depende del número de eventos que aparecen en otros períodos de tiempo. Ésta es la propiedad de la falta de efecto posterior.
Un flujo de eventos que satisface las proposiciones anteriores se llama lo más simple.
Consideremos un período de tiempo bastante corto. Según la propiedad 2, el evento puede aparecer una vez en este intervalo o no aparecer en absoluto. Denotemos la probabilidad de que ocurra un evento por R, y la no aparición - a través de q = 1-pag. Probabilidad R es constante (propiedad 3) y depende sólo del valor (propiedad 1). La expectativa matemática del número de ocurrencias de un evento en el intervalo será igual a 0× q+ 1× pag = pag. Entonces, el número promedio de ocurrencias de eventos por unidad de tiempo se llama intensidad del flujo y se denota por a, aquellos. a = .
Considere un período de tiempo finito t y dividirlo por norte partes = . Las ocurrencias de eventos en cada uno de estos intervalos son independientes (propiedad 2). Determinemos la probabilidad de que en un período de tiempo t a intensidad de flujo constante A el evento aparecerá exactamente X = k no volverá a aparecer n-k. Dado que un evento puede en cada uno de norte los espacios aparecen no más de 1 vez, luego por su apariencia k una vez en un segmento de duración t debería aparecer en cualquier k intervalos del total norte. Hay un total de combinaciones de este tipo y la probabilidad de cada una es igual. En consecuencia, por el teorema de la suma de probabilidades obtenemos para la probabilidad deseada fórmula bien conocida Bernoulli
Esta igualdad se escribe como aproximada, ya que la premisa inicial para su derivación fue la propiedad 2, que se cumple con mayor precisión cuanto menor. Para obtener la igualdad exacta, pasemos al límite en ® 0 o, lo que es lo mismo, norte® . Lo recibiremos después del reemplazo.
PAG = a= y q = 1 – .
Introduzcamos un nuevo parámetro = en, es decir, el número promedio de ocurrencias de un evento en un segmento t. Luego de simples transformaciones y pasando al límite en los factores, obtenemos.
![]() = 1, = ,
= 1, = ,
Finalmente conseguimos
, k = 0, 1, 2, ...
mi = 2.718... es la base del logaritmo natural.
Definición. Valor aleatorio X, que toma solo valores enteros positivos 0, 1, 2, ... tiene una ley de distribución de Poisson con parámetro si
![]() Para k = 0, 1, 2, ...
Para k = 0, 1, 2, ...
La distribución de Poisson fue propuesta por el matemático francés S.D. Poison (1781-1840). Se utiliza para resolver problemas de cálculo de probabilidades de eventos relativamente raros, aleatorios y mutuamente independientes por unidad de tiempo, longitud, área y volumen.
Para el caso en que a) es grande y b) k= , la fórmula de Stirling es válida:
Para calcular los valores posteriores, se utiliza una fórmula recurrente.
PAG(k + 1) = PAG(k).
Ejemplo 1. ¿Cuál es la probabilidad de que de 1000 personas en un día determinado nacieran: a) ninguna, b) una, c) dos, d) tres personas?
Solución. Porque pag= 1/365, entonces q= 1 – 1/365 = 364/365 "1.
Entonces ![]()
A) ![]() ,
,
b) ![]() ,
,
V) ![]() ,
,
GRAMO) ![]() .
.
Por tanto, si hay muestras de 1000 personas, entonces el número medio de personas que nacieron en un día determinado será, por tanto, 65; 178; 244; 223.
Ejemplo 2. Determine el valor al cual con probabilidad R el evento apareció al menos una vez.
Solución. Evento A= (aparece al menos una vez) y = (no aparece ni una sola vez). Por eso .
De aquí ![]() Y .
Y .
Por ejemplo, para R= 0,5, para R= 0,95 .
Ejemplo 3. En los telares operados por un solo tejedor, se producen 90 roturas de hilo en una hora. Encuentre la probabilidad de que ocurra al menos una rotura de hilo en 4 minutos.
Solución. Por condición t= 4 min. y el número medio de descansos por minuto, de donde ![]() . La probabilidad requerida es .
. La probabilidad requerida es .
Propiedades. La expectativa matemática y la varianza de una variable aleatoria que tiene una distribución de Poisson con parámetro son iguales a:
METRO(X) = D(X) = .
Estas expresiones se obtienen mediante cálculos directos:
Aquí es donde se hizo el reemplazo. norte = k– 1 y el hecho de que .
Realizando transformaciones similares a las utilizadas en la salida. METRO(X), obtenemos
![]()
La distribución de Poisson se utiliza para aproximar la distribución binomial en general. norte
Mayoría caso general varios tipos Las distribuciones de probabilidad son distribuciones binomiales. Usemos su versatilidad para determinar los tipos particulares de distribuciones más comunes que se encuentran en la práctica.
Distribución binomial
Sea algún evento A. La probabilidad de ocurrencia del evento A es igual a pag, la probabilidad de que no ocurra el evento A es 1 pag, a veces se designa como q. Dejar norte número de pruebas, metro frecuencia de ocurrencia del evento A en estos norte pruebas.
Se sabe que la probabilidad total de todas las combinaciones posibles de resultados es igual a uno, es decir:
1 = pag norte + norte · pag norte 1 (1 pag) + C norte norte 2 · pag norte 2 (1 pag) 2 + + C norte metro · pag metro· (1 pag) norte metro+ + (1 pag) norte .
|
pag norte probabilidad de que en nortenorte una vez; norte · pag norte 1 (1 pag) probabilidad de que en nortenorte 1) una vez y no sucederá 1 vez; C norte norte 2 · pag norte 2 (1 pag) 2 probabilidad de que en norte pruebas, ocurrirá el evento A ( norte 2) veces y no sucederá 2 veces; PAG metro = C norte metro · pag metro· (1 pag) norte metro probabilidad de que en norte pruebas, el evento A ocurrirá metro nunca ocurrirá ( norte metro) una vez; (1 pag) norte probabilidad de que en norte en los ensayos, el evento A no ocurrirá ni una sola vez; número de combinaciones de norte Por metro . |
Valor esperado METRO la distribución binomial es igual a:
METRO = norte · pag ,
Dónde norte número de pruebas, pag probabilidad de ocurrencia del evento A.
Desviación Estándar σ :
σ = raíz cuadrada ( norte · pag· (1 pag)) .
Ejemplo 1. Calcular la probabilidad de que un evento que tiene una probabilidad pag= 0,5, en norte= 10 pruebas ocurrirán metro= 1 vez. Tenemos: C 10 1 = 10, y más: PAG 1 = 10 0,5 1 (1 0,5) 10 1 = 10 0,5 10 = 0,0098. Como podemos ver, la probabilidad de que ocurra este evento es bastante baja. Esto se explica, en primer lugar, por el hecho de que no está del todo claro si el evento ocurrirá o no, ya que la probabilidad es 0,5 y las posibilidades aquí son “50 a 50”; y en segundo lugar, se requiere calcular que el evento ocurrirá exactamente una vez (ni más ni menos) de cada diez.
Ejemplo 2. Calcular la probabilidad de que un evento que tiene una probabilidad pag= 0,5, en norte= 10 pruebas ocurrirán metro= 2 veces. Tenemos: C 10 2 = 45, y más: PAG 2 = 45 0,5 2 (1 0,5) 10 2 = 45 0,5 10 = 0,044. ¡La probabilidad de que ocurra este evento ha aumentado!
Ejemplo 3. Aumentemos la probabilidad de que ocurra el evento en sí. Hagámoslo más probable. Calcular la probabilidad de que un evento que tiene una probabilidad pag= 0,8, en norte= 10 pruebas ocurrirán metro= 1 vez. Tenemos: C 10 1 = 10, y más: PAG 1 = 10 0,8 1 (1 0,8) 10 1 = 10 0,8 1 0,2 9 = 0,000004. ¡La probabilidad se ha vuelto menor que en el primer ejemplo! La respuesta, a primera vista, parece extraña, pero dado que el evento tiene una probabilidad bastante alta, es poco probable que ocurra solo una vez. Es más probable que suceda más de una vez. De hecho, contando PAG 0 , PAG 1 , PAG 2 , PAG 3, , PAG 10 (probabilidad de que un evento en norte= 10 ensayos sucederán 0, 1, 2, 3, , 10 veces), veremos:
C 10 0 = 1
,
C 10 1 = 10
,
C 10 2 = 45
,
C 10 3 = 120
,
C 10 4 = 210
,
C 10 5 = 252
,
C 10 6 = 210
,
C 10 7 = 120
,
C 10 8 = 45
,
C 10 9 = 10
,
C 10 10 = 1
;
PAG 0 = 1 0,8 0 (1 0,8) 10 0 = 1 1 0,2 10 = 0,0000
;
PAG 1 = 10 0,8 1 (1 0,8) 10 1 = 10 0,8 1 0,2 9 = 0,0000
;
PAG 2 = 45 0,8 2 (1 0,8) 10 2 = 45 0,8 2 0,2 8 = 0,0000
;
PAG 3 = 120 0,8 3 (1 0,8) 10 3 = 120 0,8 3 0,2 7 = 0,0008
;
PAG 4 = 210 0,8 4 (1 0,8) 10 4 = 210 0,8 4 0,2 6 = 0,0055
;
PAG 5 = 252 0,8 5 (1 0,8) 10 5 = 252 0,8 5 0,2 5 = 0,0264
;
PAG 6 = 210 0,8 6 (1 0,8) 10 6 = 210 0,8 6 0,2 4 = 0,0881
;
PAG 7 = 120 0,8 7 (1 0,8) 10 7 = 120 0,8 7 0,2 3 = 0,2013
;
PAG 8 = 45 0,8 8 (1 0,8) 10 8 = 45 0,8 8 0,2 2 = 0,3020
(¡la mayor probabilidad!);
PAG 9 = 10 0,8 9 (1 0,8) 10 9 = 10 0,8 9 0,2 1 = 0,2684
;
PAG 10 = 1 0,8 10 (1 0,8) 10 10 = 1 0,8 10 0,2 0 = 0,1074
Por supuesto PAG 0 + PAG 1 + PAG 2 + PAG 3 + PAG 4 + PAG 5 + PAG 6 + PAG 7 + PAG 8 + PAG 9 + PAG 10 = 1 .
Distribución normal
Si representamos las cantidades PAG 0 , PAG 1 , PAG 2 , PAG 3, , PAG 10, que calculamos en el ejemplo 3, en el gráfico, resulta que su distribución tiene una forma cercana a la ley de distribución normal (ver Fig. 27.1) (ver Conferencia 25. Modelado de variables aleatorias distribuidas normalmente).
probabilidades para diferentes m en p = 0,8, n = 10
La ley binomial se vuelve normal si las probabilidades de ocurrencia y no ocurrencia del evento A son aproximadamente las mismas, es decir, podemos escribir condicionalmente: pag≈ (1 pag) . Por ejemplo, tomemos norte= 10 y pag= 0,5 (es decir pag= 1 pag = 0.5 ).
Llegaremos a este problema de manera significativa si, por ejemplo, queremos calcular teóricamente cuántos niños y cuántas niñas habrá de cada 10 niños nacidos en una maternidad el mismo día. Más precisamente, no contaremos niños y niñas, sino la probabilidad de que solo nazcan niños, de que nazcan 1 niño y 9 niñas, de que nazcan 2 niños y 8 niñas, etc. Para simplificar, supongamos que la probabilidad de tener un niño y una niña es la misma e igual a 0,5 (pero en realidad, para ser honesto, este no es el caso, consulte el curso "Modelado de sistemas de inteligencia artificial").
Está claro que la distribución será simétrica, ya que la probabilidad de tener 3 niños y 7 niñas es igual a la probabilidad de tener 7 niños y 3 niñas. La mayor probabilidad de nacimiento será de 5 niños y 5 niñas. Esta probabilidad es 0,25, por cierto, no es tan grande. valor absoluto. Además, la probabilidad de que nazcan 10 o 9 niños a la vez es mucho menor que la probabilidad de que nazcan 5 ± 1 niño entre 10 niños. La distribución binomial nos ayudará a realizar este cálculo. Entonces.
C 10 0 = 1
,
C 10 1 = 10
,
C 10 2 = 45
,
C 10 3 = 120
,
C 10 4 = 210
,
C 10 5 = 252
,
C 10 6 = 210
,
C 10 7 = 120
,
C 10 8 = 45
,
C 10 9 = 10
,
C 10 10 = 1
;
PAG 0 = 1 0,5 0 (1 0,5) 10 0 = 1 1 0,5 10 = 0,000977
;
PAG 1 = 10 0,5 1 (1 0,5) 10 1 = 10 0,5 10 = 0,009766
;
PAG 2 = 45 0,5 2 (1 0,5) 10 2 = 45 0,5 10 = 0,043945
;
PAG 3 = 120 0,5 3 (1 0,5) 10 3 = 120 0,5 10 = 0,117188
;
PAG 4 = 210 0,5 4 (1 0,5) 10 4 = 210 0,5 10 = 0,205078
;
PAG 5 = 252 0,5 5 (1 0,5) 10 5 = 252 0,5 10 = 0,246094
;
PAG 6 = 210 0,5 6 (1 0,5) 10 6 = 210 0,5 10 = 0,205078
;
PAG 7 = 120 0,5 7 (1 0,5) 10 7 = 120 0,5 10 = 0,117188
;
PAG 8 = 45 0,5 8 (1 0,5) 10 8 = 45 0,5 10 = 0,043945
;
PAG 9 = 10 0,5 9 (1 0,5) 10 9 = 10 0,5 10 = 0,009766
;
PAG 10 = 1 0,5 10 (1 0,5) 10 10 = 1 0,5 10 = 0,000977
Por supuesto PAG 0 + PAG 1 + PAG 2 + PAG 3 + PAG 4 + PAG 5 + PAG 6 + PAG 7 + PAG 8 + PAG 9 + PAG 10 = 1 .
Visualicemos las cantidades en la gráfica. PAG 0 , PAG 1 , PAG 2 , PAG 3, , PAG 10 (ver figura 27.2).
p = 0,5 y n = 10, acercándolo a la ley normal
Entonces, bajo las condiciones metro ≈ norte/2 y pag≈ 1 pag o pag≈ 0,5 en lugar de la distribución binomial, puedes utilizar la normal. Para valores grandes norte la gráfica se desplaza hacia la derecha y se vuelve cada vez más plana, a medida que la expectativa matemática y la varianza aumentan al aumentar norte : METRO = norte · pag , D = norte · pag· (1 pag) .
Por cierto, la ley binomial tiende a ser normal y al aumentar. norte, lo cual es bastante natural, según el teorema del límite central (ver lección 34. Registro y procesamiento de resultados estadísticos).
Ahora considere cómo cambia la ley del binomio en el caso en que pag ≠ q, eso es pag> 0 . En este caso, no se puede aplicar la hipótesis de distribución normal y la distribución binomial pasa a ser una distribución de Poisson.
distribución de veneno
La distribución de Poisson es caso especial distribución binomial (con norte>> 0 y en pag>0 (eventos raros)).
Se conoce una fórmula en matemáticas que permite calcular aproximadamente el valor de cualquier miembro de la distribución binomial:
Dónde a = norte · pag Parámetro de Poisson (expectativa matemática), y la varianza es igual a la expectativa matemática. Presentemos cálculos matemáticos que expliquen esta transición. Ley de distribución binomial
PAG metro = C norte metro · pag metro· (1 pag) norte metro
se puede escribir si pones pag = a/norte , como
![]()
Porque pag es muy pequeño, entonces sólo se deben tener en cuenta los números metro, pequeño en comparación con norte. Trabajar
muy cerca de la unidad. Lo mismo se aplica al tamaño.
Magnitud
Muy cerca de mi a. De aquí obtenemos la fórmula:
Ejemplo. La caja contiene norte= 100 piezas, tanto de alta calidad como defectuosas. La probabilidad de recibir un producto defectuoso es pag= 0,01. Digamos que sacamos un producto, determinamos si está defectuoso o no y lo devolvemos. Al hacer esto, resultó que de 100 productos que revisamos, dos resultaron defectuosos. ¿Cuál es la probabilidad de que esto ocurra?
De la distribución binomial obtenemos:
De la distribución de Poisson obtenemos:
Como puede ver, los valores resultaron ser cercanos, por lo que en el caso de eventos raros es bastante aceptable aplicar la ley de Poisson, especialmente porque requiere menos esfuerzo computacional.
Mostremos gráficamente la forma de la ley de Poisson. Tomemos los parámetros como ejemplo. pag = 0.05 , norte= 10 . Entonces:
C 10 0 = 1
,
C 10 1 = 10
,
C 10 2 = 45
,
C 10 3 = 120
,
C 10 4 = 210
,
C 10 5 = 252
,
C 10 6 = 210
,
C 10 7 = 120
,
C 10 8 = 45
,
C 10 9 = 10
,
C 10 10 = 1
;
PAG 0 = 1 0,05 0 (1 0,05) 10 0 = 1 1 0,95 10 = 0,5987
;
PAG 1 = 10 0,05 1 (1 0,05) 10 1 = 10 0,05 1 0,95 9 = 0,3151
;
PAG 2 = 45 0,05 2 (1 0,05) 10 2 = 45 0,05 2 0,95 8 = 0,0746
;
PAG 3 = 120 0,05 3 (1 0,05) 10 3 = 120 0,05 3 0,95 7 = 0,0105
;
PAG 4 = 210 0,05 4 (1 0,05) 10 4 = 210 0,05 4 0,95 6 = 0,00096
;
PAG 5 = 252 0,05 5 (1 0,05) 10 5 = 252 0,05 5 0,95 5 = 0,00006
;
PAG 6 = 210 0,05 6 (1 0,05) 10 6 = 210 0,05 6 0,95 4 = 0,0000
;
PAG 7 = 120 0,05 7 (1 0,05) 10 7 = 120 0,05 7 0,95 3 = 0,0000
;
PAG 8 = 45 0,05 8 (1 0,05) 10 8 = 45 0,05 8 0,95 2 = 0,0000
;
PAG 9 = 10 0,05 9 (1 0,05) 10 9 = 10 0,05 9 0,95 1 = 0,0000
;
PAG 10 = 1 0,05 10 (1 0,05) 10 10 = 1 0,05 10 0,95 0 = 0,0000
Por supuesto PAG 0 + PAG 1 + PAG 2 + PAG 3 + PAG 4 + PAG 5 + PAG 6 + PAG 7 + PAG 8 + PAG 9 + PAG 10 = 1 .
En norte> ∞ la distribución de Poisson se convierte en una ley normal, según el teorema del límite central (ver.







