के लिए आत्मविश्वास अंतराल गणितीय अपेक्षा - यह डेटा से गणना किया गया एक अंतराल है, जिसमें ज्ञात संभावना के साथ, सामान्य जनसंख्या की गणितीय अपेक्षा शामिल होती है। गणितीय अपेक्षा के लिए एक प्राकृतिक अनुमान उसके देखे गए मूल्यों का अंकगणितीय माध्य है। इसलिए, पूरे पाठ में हम "औसत" और "औसत मूल्य" शब्दों का उपयोग करेंगे। आत्मविश्वास अंतराल की गणना करने की समस्याओं में, सबसे अधिक बार एक उत्तर की आवश्यकता होती है जैसे "माध्य का विश्वास अंतराल [किसी विशेष समस्या में मूल्य] [छोटे मूल्य] से [बड़े मूल्य] तक होता है।" आत्मविश्वास अंतराल का उपयोग करके, आप न केवल औसत मूल्यों का मूल्यांकन कर सकते हैं, बल्कि सामान्य जनसंख्या की किसी विशेष विशेषता के अनुपात का भी मूल्यांकन कर सकते हैं। औसत मान, फैलाव, मानक विचलन और त्रुटि, जिसके माध्यम से हम नई परिभाषाओं और सूत्रों पर पहुंचेंगे, पाठ में चर्चा की गई है नमूने और जनसंख्या के लक्षण .
माध्य के बिंदु और अंतराल अनुमान
यदि जनसंख्या के औसत मूल्य का अनुमान किसी संख्या (बिंदु) द्वारा लगाया जाता है, तो एक विशिष्ट औसत, जिसकी गणना टिप्पणियों के नमूने से की जाती है, को जनसंख्या के अज्ञात औसत मूल्य के अनुमान के रूप में लिया जाता है। इस मामले में, नमूना औसत का मूल्य है अनियमित परिवर्तनशील वस्तु- जनसंख्या के औसत मूल्य से मेल नहीं खाता। इसलिए, नमूना माध्य इंगित करते समय, आपको साथ ही नमूना त्रुटि भी इंगित करनी होगी। नमूनाकरण त्रुटि का माप मानक त्रुटि है, जिसे माध्य के समान इकाइयों में व्यक्त किया जाता है। इसलिए, निम्नलिखित संकेतन का अक्सर उपयोग किया जाता है: .
यदि औसत का अनुमान एक निश्चित संभावना से जुड़ा होना चाहिए, तो जनसंख्या में रुचि के पैरामीटर का आकलन एक संख्या से नहीं, बल्कि एक अंतराल से किया जाना चाहिए। एक विश्वास अंतराल एक ऐसा अंतराल है जिसमें, एक निश्चित संभावना के साथ पीअनुमानित जनसंख्या सूचक का मान ज्ञात किया जाता है। कॉन्फिडेंस इंटरवल जिसमें यह संभावित है पी = 1 - α यादृच्छिक चर पाया जाता है, जिसकी गणना निम्नानुसार की जाती है:
![]() ,
,
α = 1 - पी, जो सांख्यिकी पर लगभग किसी भी पुस्तक के परिशिष्ट में पाया जा सकता है।
व्यवहार में, जनसंख्या माध्य और विचरण ज्ञात नहीं हैं, इसलिए जनसंख्या विचरण को नमूना विचरण से और जनसंख्या माध्य को नमूना माध्य से प्रतिस्थापित कर दिया जाता है। इस प्रकार, अधिकांश मामलों में विश्वास अंतराल की गणना निम्नानुसार की जाती है:
![]() .
.
जनसंख्या माध्य का अनुमान लगाने के लिए आत्मविश्वास अंतराल सूत्र का उपयोग किया जा सकता है
- जनसंख्या का मानक विचलन ज्ञात है;
- या जनसंख्या का मानक विचलन अज्ञात है, लेकिन नमूना आकार 30 से अधिक है।
नमूना माध्य जनसंख्या माध्य का निष्पक्ष अनुमान है। बदले में, नमूना विचरण  जनसंख्या भिन्नता का निष्पक्ष अनुमान नहीं है। नमूना विचरण सूत्र, नमूना आकार में जनसंख्या विचरण का निष्पक्ष अनुमान प्राप्त करने के लिए एनद्वारा प्रतिस्थापित किया जाना चाहिए एन-1.
जनसंख्या भिन्नता का निष्पक्ष अनुमान नहीं है। नमूना विचरण सूत्र, नमूना आकार में जनसंख्या विचरण का निष्पक्ष अनुमान प्राप्त करने के लिए एनद्वारा प्रतिस्थापित किया जाना चाहिए एन-1.
उदाहरण 1।एक निश्चित शहर में यादृच्छिक रूप से चयनित 100 कैफे से जानकारी एकत्र की गई कि उनमें कर्मचारियों की औसत संख्या 4.6 के मानक विचलन के साथ 10.5 है। परिभाषित करना विश्वास अंतराल 95% कैफे कर्मचारी।
महत्व स्तर के लिए मानक सामान्य वितरण का महत्वपूर्ण मूल्य कहां है α = 0,05 .
इस प्रकार, कैफे कर्मचारियों की औसत संख्या के लिए 95% विश्वास अंतराल 9.6 से 11.4 तक था।
उदाहरण 2. 64 अवलोकनों की जनसंख्या से एक यादृच्छिक नमूने के लिए, निम्नलिखित कुल मूल्यों की गणना की गई:
प्रेक्षणों में मानों का योग,
औसत से मूल्यों के वर्ग विचलन का योग ![]() .
.
गणितीय अपेक्षा के लिए 95% विश्वास अंतराल की गणना करें।
आइए मानक विचलन की गणना करें:
 ,
,
आइए औसत मूल्य की गणना करें:
![]() .
.
हम विश्वास अंतराल के लिए अभिव्यक्ति में मानों को प्रतिस्थापित करते हैं:
महत्व स्तर के लिए मानक सामान्य वितरण का महत्वपूर्ण मूल्य कहां है α = 0,05 .
हम पाते हैं:
इस प्रकार, इस नमूने की गणितीय अपेक्षा के लिए 95% विश्वास अंतराल 7.484 से 11.266 तक था।
उदाहरण 3. 100 अवलोकनों के यादृच्छिक जनसंख्या नमूने के लिए, परिकलित माध्य 15.2 है और मानक विचलन 3.2 है। अपेक्षित मूल्य के लिए 95% विश्वास अंतराल की गणना करें, फिर 99% विश्वास अंतराल की। यदि नमूना शक्ति और इसकी भिन्नता अपरिवर्तित रहती है और आत्मविश्वास गुणांक बढ़ता है, तो क्या आत्मविश्वास अंतराल संकीर्ण या चौड़ा होगा?
हम इन मानों को विश्वास अंतराल के लिए अभिव्यक्ति में प्रतिस्थापित करते हैं:
महत्व स्तर के लिए मानक सामान्य वितरण का महत्वपूर्ण मूल्य कहां है α = 0,05 .
हम पाते हैं:
![]() .
.
इस प्रकार, इस नमूने के माध्य के लिए 95% विश्वास अंतराल 14.57 से 15.82 तक था।
हम फिर से इन मानों को विश्वास अंतराल के लिए अभिव्यक्ति में प्रतिस्थापित करते हैं:
महत्व स्तर के लिए मानक सामान्य वितरण का महत्वपूर्ण मूल्य कहां है α = 0,01 .
हम पाते हैं:
![]() .
.
इस प्रकार, इस नमूने के माध्य के लिए 99% विश्वास अंतराल 14.37 से 16.02 तक था।
जैसा कि हम देखते हैं, जैसे-जैसे विश्वास गुणांक बढ़ता है, मानक सामान्य वितरण का महत्वपूर्ण मूल्य भी बढ़ता है, और परिणामस्वरूप, अंतराल के शुरुआती और समाप्ति बिंदु माध्य से आगे स्थित होते हैं, और इस प्रकार गणितीय अपेक्षा के लिए विश्वास अंतराल बढ़ता है .
विशिष्ट गुरुत्व के बिंदु और अंतराल अनुमान
कुछ नमूना विशेषता के हिस्से की व्याख्या एक बिंदु अनुमान के रूप में की जा सकती है विशिष्ट गुरुत्व पीसामान्य जनसंख्या में समान विशेषताएँ। यदि इस मान को संभाव्यता के साथ संबद्ध करने की आवश्यकता है, तो विशिष्ट गुरुत्व के विश्वास अंतराल की गणना की जानी चाहिए पीसंभाव्यता के साथ जनसंख्या में विशेषता पी = 1 - α :
 .
.
उदाहरण 4.किसी शहर में दो उम्मीदवार हैं एऔर बीमेयर के लिए दौड़ रहे हैं. 200 शहर निवासियों का यादृच्छिक सर्वेक्षण किया गया, जिनमें से 46% ने जवाब दिया कि वे उम्मीदवार को वोट देंगे ए, 26% - उम्मीदवार के लिए बीऔर 28% को नहीं पता कि वे किसे वोट देंगे। उम्मीदवार का समर्थन करने वाले शहर निवासियों के अनुपात के लिए 95% विश्वास अंतराल निर्धारित करें ए.
कोई भी नमूना केवल सामान्य जनसंख्या का एक अनुमानित विचार देता है, और सभी नमूना सांख्यिकीय विशेषताएँ (माध्य, मोड, विचरण...) कुछ सन्निकटन हैं या कहें कि सामान्य मापदंडों का एक अनुमान है, जिसकी ज्यादातर मामलों में गणना करना संभव नहीं है। सामान्य जनसंख्या की दुर्गमता के लिए (चित्र 20)।
चित्र 20. नमूनाकरण त्रुटि
लेकिन आप उस अंतराल को निर्दिष्ट कर सकते हैं जिसमें, एक निश्चित डिग्री की संभावना के साथ, सांख्यिकीय विशेषता का सही (सामान्य) मान निहित है। इस अंतराल को कहा जाता है डी आत्मविश्वास अंतराल (सीआई)।
तो 95% की संभावना के साथ सामान्य औसत मूल्य भीतर निहित है
से, (20)
कहाँ टी – तालिका मानछात्र का टी टेस्ट α =0.05 और एफ= एन-1
इस मामले में 99% सीआई भी पाया जा सकता है टी के लिए चयनित α =0,01.
कॉन्फिडेंस इंटरवल का व्यावहारिक महत्व क्या है?
एक विस्तृत आत्मविश्वास अंतराल इंगित करता है कि नमूना माध्य जनसंख्या माध्य को सटीक रूप से प्रतिबिंबित नहीं करता है। यह आमतौर पर अपर्याप्त नमूना आकार, या इसकी विविधता के कारण होता है, अर्थात। बड़ा फैलाव. वे दोनों देते हैं बड़ी गलतीऔसत और, तदनुसार, एक व्यापक सीआई। और यही अनुसंधान योजना चरण पर लौटने का आधार है।
सीआई की ऊपरी और निचली सीमाएं यह अनुमान प्रदान करती हैं कि परिणाम चिकित्सकीय रूप से महत्वपूर्ण होंगे या नहीं
आइए समूह गुणों के अध्ययन के परिणामों के सांख्यिकीय और नैदानिक महत्व के प्रश्न पर कुछ विस्तार से ध्यान दें। आइए याद रखें कि सांख्यिकी का कार्य नमूना डेटा के आधार पर सामान्य आबादी में कम से कम कुछ अंतरों का पता लगाना है। चिकित्सकों के लिए चुनौती अंतर का पता लगाना है (सिर्फ कोई नहीं) जो निदान या उपचार में सहायता करेगा। और सांख्यिकीय निष्कर्ष हमेशा नैदानिक निष्कर्षों का आधार नहीं होते हैं। इस प्रकार, हीमोग्लोबिन में 3 ग्राम/लीटर की सांख्यिकीय रूप से महत्वपूर्ण कमी चिंता का कारण नहीं है। और, इसके विपरीत, यदि मानव शरीर में कोई समस्या पूरी आबादी के स्तर पर व्यापक नहीं है, तो यह इस समस्या से न निपटने का कोई कारण नहीं है।
|
आइए इस स्थिति पर नजर डालें उदाहरण. शोधकर्ताओं को आश्चर्य हुआ कि क्या जो लड़के किसी प्रकार की संक्रामक बीमारी से पीड़ित हैं, वे विकास में अपने साथियों से पीछे रह जाते हैं। इसी उद्देश्य से इसे अंजाम दिया गया नमूना सर्वेक्षणजिसमें इस बीमारी से पीड़ित 10 लड़कों ने हिस्सा लिया। परिणाम तालिका 23 में प्रस्तुत किए गए हैं। तालिका 23. सांख्यिकीय प्रसंस्करण के परिणाम
इन गणनाओं से यह निष्कर्ष निकलता है कि नमूना औसत ऊंचाई 10 साल के लड़के जिन्हें कुछ तकलीफ़ हुई संक्रमण, सामान्य के करीब (132.5 सेमी)। हालाँकि, आत्मविश्वास अंतराल की निचली सीमा (126.6 सेमी) इंगित करती है कि 95% संभावना है कि इन बच्चों की वास्तविक औसत ऊंचाई "छोटी ऊंचाई" की अवधारणा से मेल खाती है, अर्थात। ये बच्चे अविकसित हैं। इस उदाहरण में, विश्वास अंतराल गणना के परिणाम चिकित्सकीय रूप से महत्वपूर्ण हैं। |
|||||||||||||||||||
सांख्यिकीय समस्याओं को हल करने के तरीकों में से एक आत्मविश्वास अंतराल की गणना करना है। इसे अधिक बेहतर विकल्प के रूप में उपयोग किया जाता है बिंदु लागतएक छोटे से नमूना आकार के साथ. यह ध्यान दिया जाना चाहिए कि विश्वास अंतराल की गणना करने की प्रक्रिया स्वयं काफी जटिल है। लेकिन एक्सेल टूल इसे कुछ हद तक आसान बनाते हैं। आइए जानें कि व्यवहार में यह कैसे किया जाता है।
इस विधि का उपयोग विभिन्न के अंतराल अनुमान के लिए किया जाता है सांख्यिकीय मात्राएँ. इस गणना का मुख्य कार्य बिंदु अनुमान की अनिश्चितताओं से छुटकारा पाना है।
एक्सेल में, गणना करने के लिए दो मुख्य विकल्प हैं यह विधि: कब विचरण ज्ञात है और कब अज्ञात है। पहले मामले में, फ़ंक्शन का उपयोग गणना के लिए किया जाता है विश्वास.मानदंड, और दूसरे में - ट्रस्टी.छात्र.
विधि 1: कॉन्फिडेंस नॉर्म फ़ंक्शन
ऑपरेटर विश्वास.मानदंड, जो फ़ंक्शन के सांख्यिकीय समूह से संबंधित है, पहली बार Excel 2010 में दिखाई दिया। इस प्रोग्राम के पुराने संस्करण इसके एनालॉग का उपयोग करते हैं विश्वास. इस ऑपरेटर का उद्देश्य जनसंख्या माध्य के लिए सामान्य रूप से वितरित आत्मविश्वास अंतराल की गणना करना है।
इसका सिंटैक्स इस प्रकार है:
कॉन्फिडेंस.नॉर्म(अल्फा;standard_off;आकार)
"अल्फ़ा"- महत्व स्तर को इंगित करने वाला एक तर्क जिसका उपयोग आत्मविश्वास स्तर की गणना के लिए किया जाता है। आत्मविश्वास का स्तर निम्नलिखित अभिव्यक्ति के बराबर है:
(1-"अल्फा")*100
« मानक विचलन» - यह एक तर्क है, जिसका सार नाम से ही स्पष्ट है। यह प्रस्तावित नमूने का मानक विचलन है.
"आकार"- नमूना आकार को परिभाषित करने वाला तर्क।
इस ऑपरेटर के लिए सभी तर्क आवश्यक हैं.
समारोह विश्वासइसमें पिछले वाले के समान ही तर्क और संभावनाएँ हैं। इसका सिंटैक्स है:
विश्वास(अल्फा, मानक_बंद, आकार)
जैसा कि आप देख सकते हैं, अंतर केवल ऑपरेटर के नाम में है। निर्दिष्ट फ़ंक्शनअनुकूलता कारणों से, Excel 2010 और नए संस्करणों में एक विशेष श्रेणी में छोड़ दिया गया है "संगतता". एक्सेल 2007 और इससे पहले के संस्करणों में, यह सांख्यिकीय ऑपरेटरों के मुख्य समूह में मौजूद है।
विश्वास अंतराल सीमा निम्न सूत्र का उपयोग करके निर्धारित की जाती है:
X+(-)आत्मविश्वास मानदंड
कहाँ एक्सऔसत नमूना मान है, जो चयनित श्रेणी के मध्य में स्थित है।
आइए अब देखें कि एक विशिष्ट उदाहरण का उपयोग करके आत्मविश्वास अंतराल की गणना कैसे करें। 12 परीक्षण किए गए, जिसके परिणामस्वरूप तालिका में अलग-अलग परिणाम सामने आए। यह हमारी समग्रता है. मानक विचलन 8 है। हमें 97% विश्वास स्तर पर विश्वास अंतराल की गणना करने की आवश्यकता है।
- उस सेल का चयन करें जहां डेटा प्रोसेसिंग का परिणाम प्रदर्शित किया जाएगा। बटन पर क्लिक करें "सम्मिलित करें फ़ंक्शन".
- प्रकट होता है फ़ंक्शन विज़ार्ड. श्रेणी पर जाएँ "सांख्यिकीय"और नाम हाइलाइट करें "भरोसा.मानदंड". इसके बाद बटन पर क्लिक करें "ठीक है".
- तर्क विंडो खुलती है. इसके क्षेत्र स्वाभाविक रूप से तर्कों के नाम से मेल खाते हैं।
कर्सर को पहले फ़ील्ड में रखें - "अल्फ़ा". यहां हमें महत्व के स्तर का संकेत देना चाहिए। जैसा कि हमें याद है, हमारे भरोसे का स्तर 97% है। साथ ही, हमने कहा कि इसकी गणना इस प्रकार की जाती है:(1-विश्वास स्तर)/100
अर्थात्, मान को प्रतिस्थापित करने पर, हमें प्राप्त होता है:
सरल गणनाओं द्वारा हम यह पता लगाते हैं कि तर्क "अल्फ़ा"के बराबर होती है 0,03 . इस मान को फ़ील्ड में दर्ज करें.
जैसा कि ज्ञात है, शर्त के अनुसार मानक विचलन बराबर है 8 . इसलिए, क्षेत्र में "मानक विचलन"बस इस नंबर को लिख लें.
खेत मेँ "आकार"आपको निष्पादित परीक्षण तत्वों की संख्या दर्ज करनी होगी। जैसा कि हमें याद है, उनके 12 . लेकिन सूत्र को स्वचालित करने और हर बार जब हम कोई नया परीक्षण करते हैं तो इसे संपादित नहीं करने के लिए, आइए इस मान को किसी सामान्य संख्या से नहीं, बल्कि ऑपरेटर का उपयोग करके सेट करें जाँच करना. तो, चलिए कर्सर को फ़ील्ड में रखें "आकार", और फिर त्रिभुज पर क्लिक करें, जो सूत्र पट्टी के बाईं ओर स्थित है।
हाल ही में उपयोग किए गए फ़ंक्शंस की एक सूची दिखाई देती है। यदि ऑपरेटर जाँच करनाआपके द्वारा हाल ही में उपयोग किया गया है, यह इस सूची में होना चाहिए। ऐसे में आपको बस इसके नाम पर क्लिक करना होगा। नहीं तो नहीं मिला तो मुद्दे पर आइये "अन्य कार्य...".
- एक पहले से ही परिचित व्यक्ति प्रकट होता है फ़ंक्शन विज़ार्ड. चलिए फिर से ग्रुप में वापस चलते हैं "सांख्यिकीय". हम वहां नाम हाइलाइट करते हैं "जाँच करना". बटन पर क्लिक करें "ठीक है".
- उपरोक्त कथन के लिए तर्क विंडो प्रकट होती है। यह फ़ंक्शन एक निर्दिष्ट श्रेणी में कोशिकाओं की संख्या की गणना करने के लिए डिज़ाइन किया गया है जिसमें संख्यात्मक मान शामिल हैं। इसका सिंटैक्स इस प्रकार है:
गिनती(मान1,मान2,...)
तर्क समूह "मूल्य"उस श्रेणी का संदर्भ है जिसमें आप संख्यात्मक डेटा से भरी कोशिकाओं की संख्या की गणना करना चाहते हैं। कुल मिलाकर ऐसे 255 तर्क हो सकते हैं, लेकिन हमारे मामले में हमें केवल एक की आवश्यकता है।
कर्सर को फ़ील्ड में रखें "मान 1"और, बाईं माउस बटन को दबाए रखते हुए, शीट पर उस श्रेणी का चयन करें जिसमें हमारा संग्रह शामिल है। फिर उसका पता फ़ील्ड में प्रदर्शित होगा। बटन पर क्लिक करें "ठीक है".
- इसके बाद, एप्लिकेशन गणना करेगा और उस सेल में परिणाम प्रदर्शित करेगा जहां वह स्थित है। हमारे विशेष मामले में, सूत्र इस तरह दिखता था:
आत्मविश्वास मानदंड(0.03,8,गिनती(बी2:बी13))
गणना का समग्र परिणाम था 5,011609 .
- लेकिन यह बिलकुल भी नहीं है। जैसा कि हमें याद है, आत्मविश्वास अंतराल सीमा की गणना नमूना माध्य से गणना परिणाम को जोड़कर और घटाकर की जाती है विश्वास.मानदंड. इस प्रकार, क्रमशः आत्मविश्वास अंतराल की दाईं और बाईं सीमाओं की गणना की जाती है। नमूना माध्य की गणना ऑपरेटर का उपयोग करके की जा सकती है औसत.
यह ऑपरेटर संख्याओं की चयनित श्रेणी के अंकगणितीय माध्य की गणना करने के लिए डिज़ाइन किया गया है। इसमें निम्नलिखित काफी सरल वाक्यविन्यास है:
औसत(नंबर1,नंबर2,...)
तर्क "संख्या"या तो अलग हो सकता है अंकीय मूल्य, और कोशिकाओं या यहां तक कि संपूर्ण श्रेणियों का एक लिंक जिसमें वे शामिल हैं।
तो, उस सेल का चयन करें जिसमें औसत मूल्य की गणना प्रदर्शित की जाएगी, और बटन पर क्लिक करें "सम्मिलित करें फ़ंक्शन".
- खुलती फ़ंक्शन विज़ार्ड. श्रेणी पर वापस जा रहे हैं "सांख्यिकीय"और सूची से एक नाम चुनें "औसत". हमेशा की तरह, बटन पर क्लिक करें "ठीक है".
- तर्क विंडो खुलती है. कर्सर को फ़ील्ड में रखें "नंबर 1"और बाईं माउस बटन को दबाकर, मानों की संपूर्ण श्रृंखला का चयन करें। फ़ील्ड में निर्देशांक प्रदर्शित होने के बाद, बटन पर क्लिक करें "ठीक है".
- इसके बाद औसतगणना परिणाम को एक शीट तत्व में प्रदर्शित करता है।
- हम गणना करते हैं दाहिनी सीमाविश्वास अंतराल। ऐसा करने के लिए, एक अलग सेल का चयन करें और चिह्न लगाएं «=»
और शीट तत्वों की सामग्री को जोड़ें जिसमें फ़ंक्शन गणना के परिणाम स्थित हैं औसतऔर विश्वास.मानदंड. गणना करने के लिए, बटन दबाएँ प्रवेश करना. हमारे मामले में, हमें निम्नलिखित सूत्र मिला:
गणना परिणाम: 6,953276
- उसी तरह हम विश्वास अंतराल की बाईं सीमा की गणना करते हैं, केवल इस बार गणना के परिणाम से औसतऑपरेटर गणना के परिणाम को घटाएं विश्वास.मानदंड. हमारे उदाहरण के लिए परिणामी सूत्र निम्न प्रकार का है:
गणना परिणाम: -3,06994
- हमने कॉन्फिडेंस इंटरवल की गणना के सभी चरणों का विस्तार से वर्णन करने का प्रयास किया, इसलिए हमने प्रत्येक सूत्र का विस्तार से वर्णन किया। लेकिन आप सभी क्रियाओं को एक सूत्र में जोड़ सकते हैं। विश्वास अंतराल की सही सीमा की गणना इस प्रकार लिखी जा सकती है:
औसत(बी2:बी13)+आत्मविश्वास.मानदंड(0.03,8,गणना(बी2:बी13))
- बाईं सीमा के लिए एक समान गणना इस तरह दिखेगी:
औसत(बी2:बी13)-आत्मविश्वास.मानदंड(0.03,8,गणना(बी2:बी13))














विधि 2: ट्रस्ट.स्टूडेंट फ़ंक्शन
इसके अलावा, एक्सेल का एक और कार्य है जो कॉन्फिडेंस अंतराल की गणना से जुड़ा है - ट्रस्टी.छात्र. यह केवल Excel 2010 में दिखाई दिया। यह ऑपरेटर छात्र वितरण का उपयोग करके जनसंख्या विश्वास अंतराल की गणना करता है। जब विचरण और, तदनुसार, मानक विचलन अज्ञात हो तो इसका उपयोग करना बहुत सुविधाजनक होता है। ऑपरेटर सिंटैक्स है:
आत्मविश्वास.छात्र(अल्फा,standard_off,आकार)
जैसा कि आप देख सकते हैं, इस मामले में ऑपरेटरों के नाम अपरिवर्तित रहे।
आइए देखें कि उसी जनसंख्या के उदाहरण का उपयोग करके अज्ञात मानक विचलन के साथ विश्वास अंतराल की सीमाओं की गणना कैसे करें जिसे हमने पिछली पद्धति में माना था। चलिए विश्वास का स्तर पिछली बार की तरह 97% पर लेते हैं।
- उस सेल का चयन करें जिसमें गणना की जाएगी। बटन पर क्लिक करें "सम्मिलित करें फ़ंक्शन".
- खुले में फ़ंक्शन विज़ार्डश्रेणी पर जाएँ "सांख्यिकीय". एक नाम चुनें "विश्वसनीय छात्र". बटन पर क्लिक करें "ठीक है".
- निर्दिष्ट ऑपरेटर के लिए तर्क विंडो लॉन्च की गई है।
खेत मेँ "अल्फ़ा", यह देखते हुए कि आत्मविश्वास का स्तर 97% है, हम संख्या लिखते हैं 0,03 . दूसरी बार हम इस पैरामीटर की गणना के सिद्धांतों पर ध्यान नहीं देंगे।
इसके बाद कर्सर को फील्ड में रखें "मानक विचलन". इस बार यह सूचक हमारे लिए अज्ञात है और इसकी गणना करने की आवश्यकता है। यह एक विशेष फ़ंक्शन का उपयोग करके किया जाता है - एसटीडीईवी.वी. इस ऑपरेटर की विंडो खोलने के लिए फॉर्मूला बार के बाईं ओर त्रिकोण पर क्लिक करें। यदि खुलने वाली सूची में हमें वांछित नाम नहीं मिलता है, तो आइटम पर जाएं "अन्य कार्य...".
- प्रारंभ होगा फ़ंक्शन विज़ार्ड. श्रेणी में जा रहे हैं "सांख्यिकीय"और उसमें नाम अंकित करें "एसटीडीईवी.बी". फिर बटन पर क्लिक करें "ठीक है".
- तर्क विंडो खुलती है. संचालक का कार्य एसटीडीईवी.वीकिसी नमूने का मानक विचलन निर्धारित करना है। इसका सिंटैक्स इस प्रकार दिखता है:
मानक विचलन.बी(नंबर1;नंबर2;…)
इस तर्क का अंदाजा लगाना मुश्किल नहीं है "संख्या"चयन तत्व का पता है. यदि चयन को एक ही सरणी में रखा गया है, तो आप इस श्रेणी का लिंक प्रदान करने के लिए केवल एक तर्क का उपयोग कर सकते हैं।
कर्सर को फ़ील्ड में रखें "नंबर 1"और, हमेशा की तरह, बाईं माउस बटन को दबाकर, संग्रह का चयन करें। निर्देशांक फ़ील्ड में आने के बाद, बटन दबाने में जल्दबाजी न करें "ठीक है", क्योंकि परिणाम गलत होगा। सबसे पहले हमें ऑपरेटर तर्क विंडो पर वापस जाना होगा ट्रस्टी.छात्रअंतिम तर्क जोड़ने के लिए. ऐसा करने के लिए, फॉर्मूला बार में संबंधित नाम पर क्लिक करें।
- पहले से परिचित फ़ंक्शन के लिए तर्क विंडो फिर से खुलती है। कर्सर को फ़ील्ड में रखें "आकार". पुनः, ऑपरेटरों के चयन पर जाने के लिए उस त्रिभुज पर क्लिक करें जिससे हम पहले से ही परिचित हैं। जैसा कि आप समझते हैं, हमें एक नाम की आवश्यकता है "जाँच करना". चूँकि हमने प्रयोग किया है यह फ़ंक्शनपिछली पद्धति में गणना करते समय, यह इस सूची में मौजूद है, इसलिए बस इस पर क्लिक करें। यदि आपको यह नहीं मिलता है, तो पहली विधि में वर्णित एल्गोरिदम का पालन करें।
- एक बार तर्क विंडो में जाँच करना, कर्सर को फ़ील्ड में रखें "नंबर 1"और माउस बटन को दबाकर रखें, संग्रह का चयन करें। फिर बटन पर क्लिक करें "ठीक है".
- इसके बाद, प्रोग्राम एक गणना करता है और कॉन्फिडेंस इंटरवल वैल्यू प्रदर्शित करता है।
- सीमाएँ निर्धारित करने के लिए, हमें फिर से नमूना माध्य की गणना करने की आवश्यकता होगी। लेकिन, यह देखते हुए कि गणना एल्गोरिथ्म सूत्र का उपयोग कर रहा है औसतपिछली विधि के समान ही, और परिणाम भी नहीं बदला है, हम दूसरी बार इस पर विस्तार से ध्यान नहीं देंगे।
- गणना परिणामों को जोड़ना औसतऔर ट्रस्टी.छात्र, हम विश्वास अंतराल की सही सीमा प्राप्त करते हैं।
- ऑपरेटर के गणना परिणामों से घटाना औसतगणना परिणाम ट्रस्टी.छात्र, हमारे पास विश्वास अंतराल की बाईं सीमा है।
- यदि गणना एक सूत्र में लिखी गई है, तो हमारे मामले में सही सीमा की गणना इस तरह दिखेगी:
औसत(बी2:बी13)+आत्मविश्वास.छात्र(0.03,एसटीडीईवी.बी(बी2:बी13),गणना(बी2:बी13))
- तदनुसार, बाईं सीमा की गणना का सूत्र इस तरह दिखेगा:
औसत(बी2:बी13)-आत्मविश्वास.छात्र(0.03,एसटीडीईवी.बी(बी2:बी13),गणना(बी2:बी13))













जैसा कि आप देख सकते हैं, उपकरण एक्सेल प्रोग्रामविश्वास अंतराल और उसकी सीमाओं की गणना को महत्वपूर्ण रूप से सरल बनाना संभव बनाता है। इन उद्देश्यों के लिए, नमूनों के लिए अलग-अलग ऑपरेटरों का उपयोग किया जाता है जिनका विचरण ज्ञात और अज्ञात है।
लक्ष्य- सांख्यिकीय मापदंडों के आत्मविश्वास अंतराल की गणना के लिए छात्रों को एल्गोरिदम सिखाएं।
डेटा को सांख्यिकीय रूप से संसाधित करते समय, गणना किए गए अंकगणित माध्य, भिन्नता का गुणांक, सहसंबंध गुणांक, अंतर मानदंड और अन्य बिंदु आँकड़ों को मात्रात्मक विश्वास सीमाएँ प्राप्त होनी चाहिए, जो विश्वास अंतराल के भीतर छोटी और बड़ी दिशाओं में संकेतक के संभावित उतार-चढ़ाव का संकेत देती हैं।
उदाहरण 3.1
.
बंदरों के रक्त सीरम में कैल्शियम का वितरण, जैसा कि पहले स्थापित किया गया था, निम्नलिखित नमूना संकेतकों द्वारा विशेषता है: = 11.94 मिलीग्राम%;  = 0.127 मिलीग्राम%; एन= 100। सामान्य औसत के लिए विश्वास अंतराल निर्धारित करना आवश्यक है (
= 0.127 मिलीग्राम%; एन= 100। सामान्य औसत के लिए विश्वास अंतराल निर्धारित करना आवश्यक है (  ) आत्मविश्वास की संभावना के साथ पी
= 0,95.
) आत्मविश्वास की संभावना के साथ पी
= 0,95.
सामान्य औसत अंतराल में एक निश्चित संभावना के साथ स्थित होता है:
 , कहाँ
, कहाँ 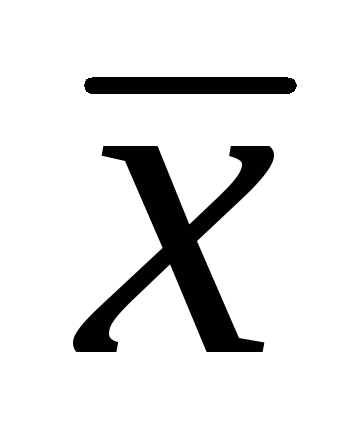 - नमूना अंकगणितीय माध्य; टी- छात्र का परीक्षण;
- नमूना अंकगणितीय माध्य; टी- छात्र का परीक्षण;  – अंकगणित माध्य की त्रुटि.
– अंकगणित माध्य की त्रुटि.
तालिका "छात्र के टी-परीक्षण मान" का उपयोग करके हम मान ज्ञात करते हैं
 0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ क= 100-1 = 99. यह 1.982 के बराबर है। अंकगणित माध्य और सांख्यिकीय त्रुटि के मूल्यों के साथ, हम इसे सूत्र में प्रतिस्थापित करते हैं:
0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ क= 100-1 = 99. यह 1.982 के बराबर है। अंकगणित माध्य और सांख्यिकीय त्रुटि के मूल्यों के साथ, हम इसे सूत्र में प्रतिस्थापित करते हैं:
या 11.69  12,19
12,19
इस प्रकार, 95% की संभावना के साथ, यह कहा जा सकता है कि इस सामान्य वितरण का सामान्य औसत 11.69 और 12.19 मिलीग्राम% के बीच है।
उदाहरण 3.2
. के लिए 95% विश्वास अंतराल की सीमा निर्धारित करें सामान्य विचरण ( ) बंदरों के रक्त में कैल्शियम का वितरण, यदि यह ज्ञात हो
) बंदरों के रक्त में कैल्शियम का वितरण, यदि यह ज्ञात हो  = 1.60, पर एन
= 100.
= 1.60, पर एन
= 100.
समस्या को हल करने के लिए आप निम्न सूत्र का उपयोग कर सकते हैं:
कहाँ  - फैलाव की सांख्यिकीय त्रुटि.
- फैलाव की सांख्यिकीय त्रुटि.
हम सूत्र का उपयोग करके नमूना विचरण त्रुटि पाते हैं:  . यह 0.11 के बराबर है. अर्थ टी- 0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ मानदंड क= 100-1 = 99 पिछले उदाहरण से ज्ञात होता है।
. यह 0.11 के बराबर है. अर्थ टी- 0.95 की आत्मविश्वास संभावना और स्वतंत्रता की डिग्री की संख्या के साथ मानदंड क= 100-1 = 99 पिछले उदाहरण से ज्ञात होता है।
आइए सूत्र का उपयोग करें और प्राप्त करें:
या 1.38  1,82
1,82
अधिक सटीक रूप से, सामान्य विचरण के विश्वास अंतराल का उपयोग करके निर्माण किया जा सकता है  (ची-स्क्वायर) - पियर्सन परीक्षण। इस मानदंड के लिए महत्वपूर्ण बिंदु एक विशेष तालिका में दिए गए हैं। मानदंड का उपयोग करते समय
(ची-स्क्वायर) - पियर्सन परीक्षण। इस मानदंड के लिए महत्वपूर्ण बिंदु एक विशेष तालिका में दिए गए हैं। मानदंड का उपयोग करते समय  आत्मविश्वास अंतराल के निर्माण के लिए, दो-तरफा महत्व स्तर का उपयोग किया जाता है। निचली सीमा के लिए, महत्व स्तर की गणना सूत्र का उपयोग करके की जाती है
आत्मविश्वास अंतराल के निर्माण के लिए, दो-तरफा महत्व स्तर का उपयोग किया जाता है। निचली सीमा के लिए, महत्व स्तर की गणना सूत्र का उपयोग करके की जाती है  , शीर्ष के लिए -
, शीर्ष के लिए -  . उदाहरण के लिए, आत्मविश्वास के स्तर के लिए
. उदाहरण के लिए, आत्मविश्वास के स्तर के लिए  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. तदनुसार, महत्वपूर्ण मूल्यों के वितरण की तालिका के अनुसार
= 0.990. तदनुसार, महत्वपूर्ण मूल्यों के वितरण की तालिका के अनुसार  , गणना किए गए आत्मविश्वास के स्तर और स्वतंत्रता की डिग्री की संख्या के साथ क= 100 – 1= 99, मान ज्ञात कीजिए
, गणना किए गए आत्मविश्वास के स्तर और स्वतंत्रता की डिग्री की संख्या के साथ क= 100 – 1= 99, मान ज्ञात कीजिए  और
और  . हम पाते हैं
. हम पाते हैं  135.80 के बराबर है, और
135.80 के बराबर है, और  70.06 के बराबर है.
70.06 के बराबर है.
सामान्य विचरण के लिए विश्वास सीमा का उपयोग करना  आइए सूत्रों का उपयोग करें: निचली सीमा के लिए
आइए सूत्रों का उपयोग करें: निचली सीमा के लिए  , ऊपरी सीमा के लिए
, ऊपरी सीमा के लिए  . आइए समस्या डेटा के लिए पाए गए मानों को प्रतिस्थापित करें
. आइए समस्या डेटा के लिए पाए गए मानों को प्रतिस्थापित करें  सूत्रों में:
सूत्रों में:  =
1,17;
=
1,17; = 2.26. इस प्रकार, आत्मविश्वास की संभावना के साथ पी= 0.99 या 99% सामान्य विचरण 1.17 से 2.26 मिलीग्राम% समावेशी सीमा में होगा।
= 2.26. इस प्रकार, आत्मविश्वास की संभावना के साथ पी= 0.99 या 99% सामान्य विचरण 1.17 से 2.26 मिलीग्राम% समावेशी सीमा में होगा।
उदाहरण 3.3 . लिफ्ट में प्राप्त बैच के 1000 गेहूं के बीजों में से 120 बीज एर्गोट से संक्रमित पाए गए। गेहूं के दिए गए बैच में संक्रमित बीजों के सामान्य अनुपात की संभावित सीमाओं को निर्धारित करना आवश्यक है।
सूत्र का उपयोग करके इसके सभी संभावित मूल्यों के लिए सामान्य शेयर की विश्वास सीमा निर्धारित करना उचित है:
 ,
,
कहाँ एन - अवलोकनों की संख्या; एम- समूहों में से एक का पूर्ण आकार; टी- सामान्यीकृत विचलन.
संक्रमित बीजों का नमूना अनुपात है  या 12%. आत्मविश्वास की संभावना के साथ आर= 95% सामान्यीकृत विचलन ( टी-छात्र का परीक्षण क
=
या 12%. आत्मविश्वास की संभावना के साथ आर= 95% सामान्यीकृत विचलन ( टी-छात्र का परीक्षण क
=
 )टी
= 1,960.
)टी
= 1,960.
हम उपलब्ध डेटा को सूत्र में प्रतिस्थापित करते हैं:
अत: विश्वास अंतराल की सीमाएँ बराबर हैं  = 0.122–0.041 = 0.081, या 8.1%;
= 0.122–0.041 = 0.081, या 8.1%;  = 0.122 + 0.041 = 0.163, या 16.3%।
= 0.122 + 0.041 = 0.163, या 16.3%।
इस प्रकार, 95% की विश्वास संभावना के साथ यह कहा जा सकता है कि संक्रमित बीजों का सामान्य अनुपात 8.1 और 16.3% के बीच है।
उदाहरण 3.4 . बंदरों के रक्त सीरम में कैल्शियम (मिलीग्राम%) की भिन्नता को दर्शाने वाला भिन्नता गुणांक 10.6% के बराबर था। नमूने का आकार एन= 100. सामान्य पैरामीटर के लिए 95% विश्वास अंतराल की सीमाओं को निर्धारित करना आवश्यक है सीवी.
भिन्नता के सामान्य गुणांक के लिए विश्वास अंतराल की सीमाएँ सीवी निम्नलिखित सूत्रों द्वारा निर्धारित किए जाते हैं:
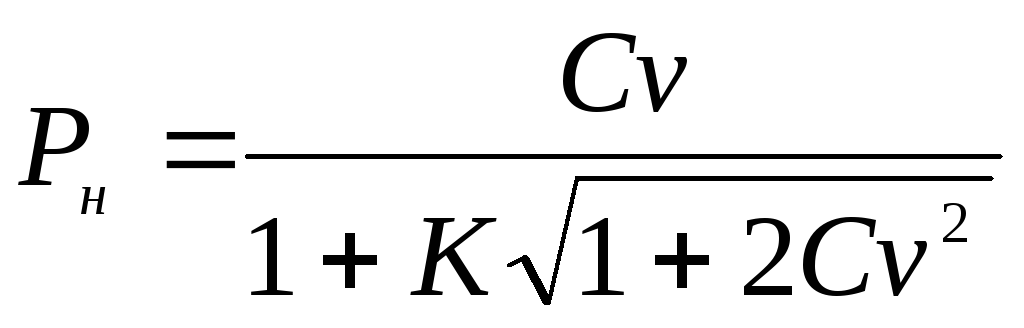 और
और  , कहाँ क
मध्यवर्ती मूल्य की गणना सूत्र द्वारा की जाती है
, कहाँ क
मध्यवर्ती मूल्य की गणना सूत्र द्वारा की जाती है  .
.
यह जानने की संभावना निश्चित रूप से है आर= 95% सामान्यीकृत विचलन (छात्र का परीक्षण)। क
=
 )टी
= 1.960, आइए पहले मान की गणना करें को:
)टी
= 1.960, आइए पहले मान की गणना करें को:
 .
.
 या 9.3%
या 9.3%
 या 12.3%
या 12.3%
इस प्रकार, 95% आत्मविश्वास स्तर के साथ भिन्नता का सामान्य गुणांक 9.3 से 12.3% की सीमा में है। बार-बार नमूनों के साथ, भिन्नता का गुणांक 12.3% से अधिक नहीं होगा और 100 में से 95 मामलों में 9.3% से कम नहीं होगा।
आत्म-नियंत्रण के लिए प्रश्न:

स्वतंत्र समाधान के लिए समस्याएँ.
1. खोल्मोगोरी संकर गायों के स्तनपान के दौरान दूध में वसा का औसत प्रतिशत इस प्रकार था: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. 95% आत्मविश्वास स्तर (20 अंक) पर सामान्य माध्य के लिए विश्वास अंतराल स्थापित करें।
2. 400 संकर राई पौधों पर, पहला फूल बुआई के औसतन 70.5 दिन बाद दिखाई दिया। मानक विचलन 6.9 दिन था। महत्व स्तर पर सामान्य माध्य और विचरण के लिए माध्य और आत्मविश्वास अंतराल की त्रुटि निर्धारित करें डब्ल्यू= 0.05 और डब्ल्यू= 0.01 (25 अंक).
3. उद्यान स्ट्रॉबेरी के 502 नमूनों की पत्तियों की लंबाई का अध्ययन करते समय, निम्नलिखित डेटा प्राप्त हुए:
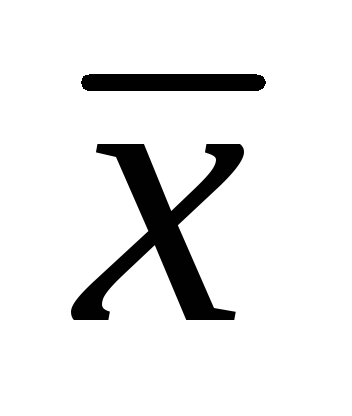 = 7.86 सेमी; σ = 1.32 सेमी,
= 7.86 सेमी; σ = 1.32 सेमी,  =±0.06 सेमी. 0.01 के महत्व स्तर के साथ अंकगणितीय जनसंख्या माध्य के लिए आत्मविश्वास अंतराल निर्धारित करें; 0.02; 0.05. (25 अंक).
=±0.06 सेमी. 0.01 के महत्व स्तर के साथ अंकगणितीय जनसंख्या माध्य के लिए आत्मविश्वास अंतराल निर्धारित करें; 0.02; 0.05. (25 अंक).
4. 150 वयस्क पुरुषों के एक अध्ययन में, औसत ऊंचाई 167 सेमी थी, और σ = 6 सेमी. 0.99 और 0.95 की आत्मविश्वास संभावना के साथ सामान्य माध्य और सामान्य विचरण की सीमाएँ क्या हैं? (25 अंक).
5. बंदरों के रक्त सीरम में कैल्शियम का वितरण निम्नलिखित चयनात्मक संकेतकों द्वारा विशेषता है:
 = 11.94 मिलीग्राम%, σ
= 1,27, एन
= 100. इस वितरण के सामान्य माध्य के लिए 95% विश्वास अंतराल का निर्माण करें। भिन्नता के गुणांक (25 अंक) की गणना करें।
= 11.94 मिलीग्राम%, σ
= 1,27, एन
= 100. इस वितरण के सामान्य माध्य के लिए 95% विश्वास अंतराल का निर्माण करें। भिन्नता के गुणांक (25 अंक) की गणना करें।
6. अध्ययन किया गया है सामान्य सामग्री 37 और 180 दिन की आयु वाले अल्बिनो चूहों के रक्त प्लाज्मा में नाइट्रोजन। परिणाम प्लाज्मा के प्रति 100 सेमी 3 ग्राम में व्यक्त किए जाते हैं। 37 दिन की उम्र में, 9 चूहों में: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. 180 दिन की उम्र में, 8 चूहों में: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. 0.95 (50 अंक) के आत्मविश्वास स्तर पर अंतर के लिए आत्मविश्वास अंतराल निर्धारित करें।
7. बंदरों के रक्त सीरम में कैल्शियम (मिलीग्राम%) के वितरण के सामान्य विचरण के लिए 95% विश्वास अंतराल की सीमाएँ निर्धारित करें, यदि इस वितरण के लिए नमूना आकार n = 100 है, तो नमूना विचरण की सांख्यिकीय त्रुटि एस σ 2 = 1.60 (40 अंक).
8. लंबाई (σ 2 = 40.87 मिमी 2) के साथ 40 गेहूं स्पाइकलेट के वितरण के सामान्य भिन्नता के लिए 95% विश्वास अंतराल की सीमाएं निर्धारित करें। (25 अंक).
9. धूम्रपान को प्रतिरोधी फुफ्फुसीय रोगों का मुख्य कारण माना जाता है। निष्क्रिय धूम्रपान को ऐसा कारक नहीं माना जाता है। वैज्ञानिकों ने निष्क्रिय धूम्रपान की हानिरहितता पर संदेह किया और पारगम्यता की जांच की श्वसन तंत्रधूम्रपान न करने वालों, निष्क्रिय और सक्रिय धूम्रपान करने वालों में। श्वसन पथ की स्थिति को चिह्नित करने के लिए, हमने फ़ंक्शन संकेतकों में से एक लिया बाह्य श्वसन- अधिकतम मध्य-निःश्वसन प्रवाह दर। इस सूचक में कमी वायुमार्ग में रुकावट का संकेत है। सर्वेक्षण डेटा तालिका में दिखाया गया है।
|
जांच किये गये लोगों की संख्या |
अधिकतम मध्य-निःश्वसन प्रवाह दर, एल/एस |
||
|
मानक विचलन |
|||
|
धूम्रपान न करने वालों |
|||
|
धूम्रपान रहित क्षेत्र में काम करें | |||
|
धुएँ से भरे कमरे में काम करना | |||
|
धूम्रपान |
|||
|
कम संख्या में सिगरेट पियें | |||
|
सिगरेट पीने वालों की औसत संख्या | |||
|
बड़ी संख्या में सिगरेट पीना | |||
तालिका डेटा का उपयोग करके, प्रत्येक समूह के लिए समग्र माध्य और समग्र भिन्नता के लिए 95% विश्वास अंतराल खोजें। समूहों के बीच क्या अंतर हैं? परिणामों को ग्राफ़िक रूप से प्रस्तुत करें (25 अंक)।
10. यदि नमूना विचरण की सांख्यिकीय त्रुटि है, तो 64 खेतों में पिगलेट की संख्या में सामान्य भिन्नता के लिए 95% और 99% विश्वास अंतराल की सीमाएं निर्धारित करें एस σ 2 = 8.25 (30 अंक).
11. यह ज्ञात है कि खरगोशों का औसत वजन 2.1 किलोग्राम होता है। सामान्य माध्य और विचरण के लिए 95% और 99% विश्वास अंतराल की सीमाएं निर्धारित करें एन= 30, σ = 0.56 किग्रा (25 अंक)।
12. बालियों में दाने की मात्रा 100 बालियों के लिए मापी गई ( एक्स), कान की लंबाई ( वाई) और कान में अनाज का द्रव्यमान ( जेड). सामान्य माध्य और विचरण के लिए विश्वास अंतराल खोजें पी 1
= 0,95, पी 2
= 0,99, पी 3
= 0.999 यदि
 = 19, = 6.766 सेमी, = 0.554 ग्राम; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 अंक)।
= 19, = 6.766 सेमी, = 0.554 ग्राम; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 अंक)।
13. शीतकालीन गेहूं की 100 बेतरतीब ढंग से चुनी गई बालियों में स्पाइकलेट्स की संख्या की गणना की गई। नमूना जनसंख्या को निम्नलिखित संकेतकों द्वारा चित्रित किया गया था:
 = 15 स्पाइकलेट और σ = 2.28 पीसी। निर्धारित करें कि औसत परिणाम किस सटीकता से प्राप्त किया गया था (
= 15 स्पाइकलेट और σ = 2.28 पीसी। निर्धारित करें कि औसत परिणाम किस सटीकता से प्राप्त किया गया था (  ) और 95% और 99% महत्व स्तरों (30 अंक) पर सामान्य माध्य और विचरण के लिए एक विश्वास अंतराल का निर्माण करें।
) और 95% और 99% महत्व स्तरों (30 अंक) पर सामान्य माध्य और विचरण के लिए एक विश्वास अंतराल का निर्माण करें।
14. जीवाश्म मोलस्क के गोले पर पसलियों की संख्या ऑर्थम्बोनाइट्स सुलेख:
ह ज्ञात है कि एन = 19, σ = 4.25. महत्व स्तर पर सामान्य माध्य और सामान्य विचरण के लिए विश्वास अंतराल की सीमाएं निर्धारित करें डब्ल्यू = 0.01 (25 अंक).
15. एक व्यावसायिक डेयरी फार्म पर दूध की उपज निर्धारित करने के लिए प्रतिदिन 15 गायों की उत्पादकता निर्धारित की जाती थी। वर्ष के आंकड़ों के अनुसार, प्रत्येक गाय औसतन प्रति दिन निम्नलिखित मात्रा में दूध देती है (एल): 22; 19; 25; 20; 27; 17; तीस; 21; 18; 24; 26; 23; 25; 20; 24. सामान्य विचरण और अंकगणितीय माध्य के लिए विश्वास अंतराल का निर्माण करें। क्या हम उम्मीद कर सकते हैं कि प्रति गाय औसत वार्षिक दूध उपज 10,000 लीटर होगी? (50 अंक).
16. कृषि उद्यम के लिए औसत गेहूं की उपज निर्धारित करने के लिए, 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 और 2 हेक्टेयर के परीक्षण भूखंडों पर कटाई की गई। भूखंडों से उत्पादकता (सी/हेक्टेयर) 39.4 थी; 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; क्रमशः 29. सामान्य विचरण और अंकगणितीय माध्य के लिए विश्वास अंतराल का निर्माण करें। क्या हम उम्मीद कर सकते हैं कि औसत कृषि उपज 42 सी/हेक्टेयर होगी? (50 अंक).
कॉन्फिडेंस इंटरवल हमें सांख्यिकी के क्षेत्र से मिलता है। यह एक निश्चित सीमा है जो उच्च स्तर की विश्वसनीयता के साथ एक अज्ञात पैरामीटर का अनुमान लगाने का कार्य करती है। इसे समझाने का सबसे आसान तरीका एक उदाहरण है।
मान लीजिए कि आपको कुछ यादृच्छिक चर का अध्ययन करने की आवश्यकता है, उदाहरण के लिए, क्लाइंट अनुरोध पर सर्वर की प्रतिक्रिया गति। हर बार जब कोई उपयोगकर्ता किसी विशिष्ट साइट का पता टाइप करता है, तो सर्वर अलग-अलग गति से प्रतिक्रिया देता है। इस प्रकार, अध्ययन के तहत प्रतिक्रिया समय यादृच्छिक है। इसलिए, आत्मविश्वास अंतराल हमें इस पैरामीटर की सीमाओं को निर्धारित करने की अनुमति देता है, और फिर हम कह सकते हैं कि 95% संभावना के साथ सर्वर हमारे द्वारा गणना की गई सीमा में होगा।
या आपको यह पता लगाना होगा कि कितने लोग इसके बारे में जानते हैं ट्रेडमार्ककंपनियां. जब विश्वास अंतराल की गणना की जाती है, तो उदाहरण के लिए, यह कहना संभव होगा कि 95% संभावना के साथ इसके बारे में जागरूक उपभोक्ताओं की हिस्सेदारी 27% से 34% तक है।
इस शब्द का निकटता से संबंध मात्रा से है आत्मविश्वास की संभावना. यह इस संभावना का प्रतिनिधित्व करता है कि वांछित पैरामीटर विश्वास अंतराल में शामिल है। हमारी वांछित सीमा कितनी बड़ी होगी यह इस मान पर निर्भर करता है। यह जितना बड़ा मूल्य लेता है, विश्वास अंतराल उतना ही संकीर्ण हो जाता है, और इसके विपरीत। आमतौर पर इसे 90%, 95% या 99% पर सेट किया जाता है। 95% मूल्य सबसे लोकप्रिय है।
यह सूचक अवलोकनों के फैलाव से भी प्रभावित होता है और इसकी परिभाषा इस धारणा पर आधारित है कि अध्ययन के तहत विशेषता का पालन किया जाता है। इस कथन को गॉस के नियम के रूप में भी जाना जाता है। उनके अनुसार, सामान्य एक सतत यादृच्छिक चर की सभी संभावनाओं का वितरण है जिसे संभाव्यता घनत्व द्वारा वर्णित किया जा सकता है। यदि के बारे में धारणा सामान्य वितरणग़लत निकला, मूल्यांकन गलत हो सकता है।
सबसे पहले, आइए जानें कि आत्मविश्वास अंतराल की गणना कैसे करें यहां दो संभावित मामले हैं। फैलाव (यादृच्छिक चर के प्रसार की डिग्री) ज्ञात हो भी सकता है और नहीं भी। यदि यह ज्ञात है, तो हमारे आत्मविश्वास अंतराल की गणना निम्न सूत्र का उपयोग करके की जाती है:
xsr - t*σ / (sqrt(n))<= α <= хср + t*σ / (sqrt(n)), где
α - संकेत,
टी - लाप्लास वितरण तालिका से पैरामीटर,
σ विचरण का वर्गमूल है।
यदि विचरण अज्ञात है, तो इसकी गणना तब की जा सकती है जब हम वांछित विशेषता के सभी मान जानते हों। इसके लिए निम्नलिखित सूत्र का उपयोग किया जाता है:
σ2 = х2ср - (хср)2, कहाँ
х2ср - अध्ययन की गई विशेषता के वर्गों का औसत मूल्य,
(хср)2 इस विशेषता का वर्ग है।
इस मामले में विश्वास अंतराल की गणना करने का सूत्र थोड़ा बदल जाता है:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n)), где
एक्सएसआर - नमूना औसत,
α - संकेत,
t एक पैरामीटर है जो छात्र वितरण तालिका t = t(ɣ;n-1) का उपयोग करके पाया जाता है,
sqrt(n) - कुल नमूना आकार का वर्गमूल,
s प्रसरण का वर्गमूल है.
इस उदाहरण पर विचार करें. मान लीजिए कि 7 मापों के परिणामों के आधार पर, अध्ययन की गई विशेषता 30 के बराबर और नमूना भिन्नता 36 के बराबर निर्धारित की गई थी। 99% की संभावना के साथ, एक आत्मविश्वास अंतराल ढूंढना आवश्यक है जिसमें सत्य शामिल है मापे गए पैरामीटर का मान.
सबसे पहले, आइए निर्धारित करें कि t किसके बराबर है: t = t (0.99; 7-1) = 3.71। उपरोक्त सूत्र का उपयोग करके, हम पाते हैं:
xsr - t*s / (sqrt(n))<= α <= хср + t*s / (sqrt(n))
30 - 3.71*36 / (वर्ग(7))<= α <= 30 + 3.71*36 / (sqrt(7))
21.587 <= α <= 38.413
विचरण के लिए विश्वास अंतराल की गणना ज्ञात माध्य के मामले में की जाती है और जब गणितीय अपेक्षा पर कोई डेटा नहीं होता है, और केवल विचरण के बिंदु निष्पक्ष अनुमान का मूल्य ज्ञात होता है। हम यहां इसकी गणना के लिए सूत्र नहीं देंगे, क्योंकि वे काफी जटिल हैं और यदि चाहें तो हमेशा इंटरनेट पर पाए जा सकते हैं।
आइए हम केवल इस बात पर ध्यान दें कि एक्सेल या नेटवर्क सेवा का उपयोग करके विश्वास अंतराल निर्धारित करना सुविधाजनक है, जिसे इस तरह कहा जाता है।







