परिचय
क्या यादृच्छिक घटनाएं किसी कानून के अधीन हैं? हाँ, लेकिन ये कानून उन कानूनों से भिन्न हैं जिनके हम आदी हैं भौतिक नियम. ज्ञात प्रायोगिक स्थितियों के तहत भी एसवी के मूल्यों की भविष्यवाणी नहीं की जा सकती है; हम केवल संभावनाओं को इंगित कर सकते हैं कि एसवी एक या दूसरा मान लेगा। लेकिन एसवी के संभाव्यता वितरण को जानकर, हम उन घटनाओं के बारे में निष्कर्ष निकाल सकते हैं जिनमें ये यादृच्छिक चर भाग लेते हैं। सच है, ये निष्कर्ष भी संभाव्य प्रकृति के होंगे।
कुछ एसवी को अलग होने दें, यानी केवल निश्चित मान Xi ले सकते हैं। इस मामले में, इस मात्रा के सभी (i=1…n) अनुमेय मूल्यों के लिए संभाव्यता मान P(Xi) की श्रृंखला को इसका वितरण कानून कहा जाता है।
एसवी के वितरण का नियम एक ऐसा संबंध है जो एसवी के संभावित मूल्यों और उन संभावनाओं के बीच संबंध स्थापित करता है जिनके साथ इन मूल्यों को स्वीकार किया जाता है। वितरण कानून पूरी तरह से एसवी की विशेषता बताता है।
निर्माण करते समय गणित का मॉडलजाँच के लिए सांख्यिकीय परिकल्पनाएसवी के वितरण के नियम (मॉडल के निर्माण का पैरामीट्रिक तरीका) के बारे में गणितीय धारणा पेश करना आवश्यक है।
गणितीय मॉडल का वर्णन करने के लिए गैर-पैरामीट्रिक दृष्टिकोण (एसवी में पैरामीट्रिक वितरण कानून नहीं है) कम सटीक है, लेकिन इसका दायरा व्यापक है।
किसी यादृच्छिक घटना की संभावना की तरह, एसवी के वितरण कानून के लिए इसे खोजने के केवल दो तरीके हैं। या तो हम एक यादृच्छिक घटना का आरेख बनाएं और संभाव्यता की गणना के लिए एक विश्लेषणात्मक अभिव्यक्ति (सूत्र) ढूंढें (शायद किसी ने पहले ही हमारे लिए ऐसा किया है या करेगा!), या हमें एक प्रयोग का उपयोग करना होगा और, आवृत्तियों के आधार पर अवलोकनों के अनुसार, कानून वितरण के बारे में कुछ धारणाएँ बनाएं (परिकल्पनाएँ सामने रखें)।
बेशक, प्रत्येक "शास्त्रीय" वितरण के लिए यह काम लंबे समय से किया गया है - द्विपद और बहुपद वितरण, ज्यामितीय और हाइपरजियोमेट्रिक, पास्कल और पॉइसन वितरण और कई अन्य व्यापक रूप से ज्ञात हैं और लागू आंकड़ों में अक्सर उपयोग किए जाते हैं।
लगभग सभी शास्त्रीय वितरणों के लिए, विशेष सांख्यिकीय तालिकाओं का तुरंत निर्माण और प्रकाशन किया गया, जैसे-जैसे गणना की सटीकता बढ़ी, उन्हें परिष्कृत किया गया। इन तालिकाओं के कई खंडों के उपयोग के बिना, उनके उपयोग के नियमों के प्रशिक्षण के बिना, पिछली दो शताब्दियों से सांख्यिकी का व्यावहारिक उपयोग असंभव रहा है।
आज स्थिति बदल गई है - सूत्रों का उपयोग करके गणना डेटा को संग्रहीत करने की कोई आवश्यकता नहीं है (चाहे बाद वाला कितना भी जटिल क्यों न हो!), अभ्यास के लिए वितरण कानून का उपयोग करने का समय मिनटों या सेकंड तक कम हो गया है। इन उद्देश्यों के लिए पहले से ही पर्याप्त संख्या में विभिन्न एप्लिकेशन सॉफ़्टवेयर पैकेज मौजूद हैं।
सभी संभाव्यता वितरणों में से कुछ ऐसे वितरण भी हैं जिनका व्यवहार में विशेष रूप से अक्सर उपयोग किया जाता है। इन वितरणों का विस्तार से अध्ययन किया गया है और उनके गुण सर्वविदित हैं। इनमें से कई वितरण ज्ञान के संपूर्ण क्षेत्रों का आधार हैं, जैसे कि सिद्धांत कतार, विश्वसनीयता सिद्धांत, गुणवत्ता नियंत्रण, खेल सिद्धांत, आदि।
उनमें से, कोई भी पॉइसन (1781-1840) के कार्यों पर ध्यान दिए बिना नहीं रह सकता, जिन्होंने जैकब बर्नौली की तुलना में बड़ी संख्या के कानून का अधिक सामान्य रूप साबित किया, और पहली बार शूटिंग समस्याओं के लिए संभाव्यता के सिद्धांत को भी लागू किया। . पॉइसन का नाम वितरण के एक नियम से जुड़ा है, जो संभाव्यता सिद्धांत और उसके अनुप्रयोगों में महत्वपूर्ण भूमिका निभाता है।
यह वितरण कानून है जिसके लिए यह लेख समर्पित है। पाठ्यक्रम कार्य. इसके बारे मेंसीधे कानून के बारे में, इसकी गणितीय विशेषताओं, विशेष गुणों, द्विपद वितरण के साथ संबंध के बारे में। व्यावहारिक अनुप्रयोग के बारे में कुछ शब्द कहे जाएंगे और अभ्यास से कई उदाहरण दिए जाएंगे।
हमारे निबंध का उद्देश्य बर्नौली और पॉइसन वितरण प्रमेयों के सार को स्पष्ट करना है।
कार्य निबंध के विषय पर साहित्य का अध्ययन और विश्लेषण करना है।
1. द्विपद वितरण (बर्नौली वितरण)
द्विपद वितरण (बर्नौली वितरण) - किसी घटना के बार-बार घटित होने की संख्या का संभाव्यता वितरण स्वतंत्र परीक्षण, यदि प्रत्येक परीक्षण में इस घटना के घटित होने की संभावना p (0) है
SV पी+क्यू=1; एक्स=0.1.
द्विपद वितरण उन मामलों में उत्पन्न होता है जहां प्रश्न पूछा जाता है: समान परिस्थितियों में किए गए एक निश्चित संख्या में स्वतंत्र अवलोकनों (प्रयोगों) की श्रृंखला में एक निश्चित घटना कितनी बार घटित होती है।
सुविधा और स्पष्टता के लिए, हम मान लेंगे कि हम मान पी जानते हैं - संभावना है कि स्टोर में प्रवेश करने वाला आगंतुक खरीदार बन जाएगा और (1- पी) = क्यू - संभावना है कि स्टोर में प्रवेश करने वाला आगंतुक खरीदार नहीं होगा एक खरीदार.
यदि X, n आगंतुकों की कुल संख्या में से खरीदारों की संख्या है, तो संभावना है कि n आगंतुकों के बीच k खरीदार थे, बराबर है
P(X= k) = , जहां k=0,1,…n 1)
सूत्र (1) को बर्नौली का सूत्र कहा जाता है। बड़ी संख्या में परीक्षणों के साथ, द्विपद वितरण सामान्य हो जाता है।

बर्नौली परीक्षण दो परिणामों के साथ एक संभाव्यता प्रयोग है, जिसे आमतौर पर "सफलता" (आमतौर पर प्रतीक 1 द्वारा दर्शाया जाता है) और "असफलता" (क्रमशः 0 द्वारा दर्शाया जाता है) कहा जाता है। सफलता की संभावना को आमतौर पर अक्षर p, विफलता - अक्षर q द्वारा दर्शाया जाता है; बेशक q=1-p. मान p को बर्नौली परीक्षण पैरामीटर कहा जाता है।
द्विपद, ज्यामितीय, पास्कल और नकारात्मक द्विपद यादृच्छिक चर स्वतंत्र बर्नौली परीक्षणों के अनुक्रम से प्राप्त किए जाते हैं यदि अनुक्रम एक या दूसरे तरीके से समाप्त हो जाता है, उदाहरण के लिए nth परीक्षण या xth सफलता के बाद। निम्नलिखित शब्दावली आमतौर पर प्रयोग की जाती है:
- बर्नौली परीक्षण पैरामीटर (एकल परीक्षण में सफलता की संभावना);
- परीक्षणों की संख्या;
– सफलताओं की संख्या;
- विफलताओं की संख्या.
द्विपद यादृच्छिक चर (एम|एन,पी) - एन परीक्षणों में एम सफलताओं की संख्या।
ज्यामितीय यादृच्छिक चर G(m|p) - पहली सफलता तक परीक्षणों की संख्या m (पहली सफलता सहित)।
पास्कल यादृच्छिक चर C(m|x,p) - x-वें सफलता तक परीक्षणों की संख्या m (निश्चित रूप से, x-वें सफलता को शामिल नहीं)।
नकारात्मक द्विपद यादृच्छिक चर Y(m|x,p) - x-वें सफलता से पहले विफलताओं की संख्या m (x-वें सफलता को शामिल नहीं)।
नोट: कभी-कभी ऋणात्मक द्विपद वितरण को पास्कल वितरण कहा जाता है और इसके विपरीत।
पॉसों वितरण
2.1. पॉइसन के नियम की परिभाषा
कई व्यावहारिक समस्याओं में व्यक्ति को एक विशिष्ट नियम के अनुसार वितरित यादृच्छिक चर से निपटना पड़ता है, जिसे पॉइसन का नियम कहा जाता है।
आइए एक असंतत यादृच्छिक चर X पर विचार करें, जो केवल पूर्णांक, गैर-नकारात्मक मान ले सकता है: 0, 1, 2, ..., m, ...; इसके अलावा, इन मूल्यों का क्रम सैद्धांतिक रूप से असीमित है। एक यादृच्छिक चर
![]()
जहां a कुछ सकारात्मक मात्रा है जिसे पॉइसन का नियम पैरामीटर कहा जाता है।
वितरण सीमा अनियमित परिवर्तनशील वस्तुएक्स, पॉइसन के नियम के अनुसार वितरित, इस तरह दिखता है:
| एक्सएम | … | एम | … | |||
| बजे | ई-ए | … | … |
2.2.पॉइसन वितरण की मुख्य विशेषताएँ
सबसे पहले, आइए सुनिश्चित करें कि संभावनाओं का क्रम एक वितरण श्रृंखला हो सकता है, यानी। कि सभी संभावनाओं का योग Рm एक के बराबर है।
![]()
हम मैकलॉरिन श्रृंखला में फ़ंक्शन पूर्व के विस्तार का उपयोग करते हैं:
![]()
यह ज्ञात है कि यह श्रृंखला x के किसी भी मान के लिए अभिसरण करती है, इसलिए, x = a लेने पर, हमें मिलता है
![]()
इस तरह
![]()
आइए मुख्य विशेषताओं को परिभाषित करें - अपेक्षित मूल्यऔर विचरण - पॉइसन के नियम के अनुसार वितरित एक यादृच्छिक चर X। एक असतत यादृच्छिक चर की गणितीय अपेक्षा उसके सभी संभावित मूल्यों और उनकी संभावनाओं के उत्पादों का योग है। परिभाषा के अनुसार, जब एक असतत यादृच्छिक चर मानों का एक गणनीय सेट लेता है:
![]()
योग का पहला पद (m=0 के अनुरूप) शून्य के बराबर है, इसलिए, योग m=1 से शुरू हो सकता है:
इस प्रकार, पैरामीटर a यादृच्छिक चर X की गणितीय अपेक्षा से अधिक कुछ नहीं है।
एक यादृच्छिक चर X का प्रसरण उसकी गणितीय अपेक्षा से एक यादृच्छिक चर के वर्ग विचलन की गणितीय अपेक्षा है:
हालाँकि, सूत्र का उपयोग करके इसकी गणना करना अधिक सुविधाजनक है:
इसलिए, आइए पहले दूसरा खोजें आरंभिक क्षणएक्स मान:

पूर्व सिद्ध के अनुसार
![]()
अलावा,
![]()
2.3.पॉइसन वितरण की अतिरिक्त विशेषताएँ
I. एक यादृच्छिक चर X के क्रम k का प्रारंभिक क्षण मान Xk की गणितीय अपेक्षा है:
विशेष रूप से, पहले क्रम का प्रारंभिक क्षण गणितीय अपेक्षा के बराबर है:
द्वितीय. यादृच्छिक चर X के क्रम k का केंद्रीय क्षण मान k की गणितीय अपेक्षा है:
विशेष रूप से, प्रथम क्रम का केंद्रीय क्षण 0 है:
μ1=एम=0,
दूसरे क्रम का केंद्रीय क्षण फैलाव के बराबर है:
μ2=M2=a.
तृतीय. पॉइसन के नियम के अनुसार वितरित एक यादृच्छिक चर X के लिए, हम संभावना पाते हैं कि यह दिए गए k से कम मान नहीं लेगा। हम इस संभावना को Rk द्वारा निरूपित करते हैं:
![]()
जाहिर है, संभावना Rk की गणना योग के रूप में की जा सकती है
![]()
हालाँकि, संभाव्यता से इसका निर्धारण करना बहुत आसान है विपरीत घटना:
![]()
विशेष रूप से, X का मान सकारात्मक मान लेने की संभावना सूत्र द्वारा व्यक्त की जाती है
![]()
जैसा कि पहले ही उल्लेख किया गया है, कई अभ्यास समस्याओं के परिणामस्वरूप पॉइसन वितरण होता है। आइए इस प्रकार की विशिष्ट समस्याओं में से एक पर विचार करें।
|

मान लीजिए बिंदुओं को x-अक्ष ऑक्स पर यादृच्छिक रूप से वितरित किया गया है (चित्र 2)। आइए मान लें कि अंकों का यादृच्छिक वितरण संतुष्ट करता है निम्नलिखित शर्तें:
1) खंड l पर एक निश्चित संख्या में बिंदुओं के गिरने की संभावना केवल इस खंड की लंबाई पर निर्भर करती है, लेकिन भुज अक्ष पर इसकी स्थिति पर निर्भर नहीं करती है। दूसरे शब्दों में, बिंदु समान औसत घनत्व के साथ एक्स-अक्ष पर वितरित किए जाते हैं। आइए हम इस घनत्व को निरूपित करें, अर्थात। प्रति इकाई लंबाई बिंदुओं की संख्या की गणितीय अपेक्षा, λ के माध्यम से व्यक्त की गई।
2) बिंदु x-अक्ष पर एक दूसरे से स्वतंत्र रूप से वितरित होते हैं, अर्थात। किसी दिए गए खंड पर एक विशेष संख्या में अंक गिरने की संभावना इस बात पर निर्भर नहीं करती है कि उनमें से कितने किसी अन्य खंड पर आते हैं जो इसके साथ ओवरलैप नहीं होता है।
3) एक छोटे क्षेत्र Δx में दो या दो से अधिक बिंदुओं के गिरने की संभावना एक बिंदु के गिरने की संभावना की तुलना में नगण्य है (इस स्थिति का अर्थ है दो या दो से अधिक बिंदुओं के संयोग की व्यावहारिक असंभवता)।
आइए हम भुज अक्ष पर लंबाई l के एक निश्चित खंड का चयन करें और एक असतत यादृच्छिक चर X पर विचार करें - इस खंड पर पड़ने वाले बिंदुओं की संख्या। संभावित मानमान 0,1,2,...,m,... होंगे क्योंकि बिंदु एक दूसरे से स्वतंत्र रूप से खंड पर आते हैं, यह सैद्धांतिक रूप से संभव है कि उनमें से उतने ही होंगे जितने वांछित होंगे, अर्थात। यह शृंखलाअनिश्चित काल तक जारी है.
आइए हम सिद्ध करें कि यादृच्छिक चर X को पॉइसन के नियम के अनुसार वितरित किया जाता है। ऐसा करने के लिए, आपको संभावना Pm की गणना करने की आवश्यकता है कि खंड पर बिल्कुल m अंक गिरेंगे।
पहले आइए और अधिक समाधान करें सरल कार्य. आइए ऑक्स अक्ष पर एक छोटे से क्षेत्र Δx पर विचार करें और इस संभावना की गणना करें कि कम से कम एक बिंदु इस क्षेत्र पर पड़ेगा। हम इस प्रकार तर्क करेंगे। इस खंड पर पड़ने वाले अंकों की संख्या की गणितीय अपेक्षा स्पष्ट रूप से λ·Δх के बराबर है (क्योंकि औसतन λ अंक प्रति इकाई लंबाई में आते हैं)। शर्त 3 के अनुसार, एक छोटे खंड Δx के लिए हम उस पर पड़ने वाले दो या दो से अधिक बिंदुओं की संभावना को नजरअंदाज कर सकते हैं। इसलिए, क्षेत्र Δх पर पड़ने वाले बिंदुओं की संख्या की गणितीय अपेक्षा λ·Δх लगभग उस पर पड़ने वाले एक बिंदु की संभावना के बराबर होगी (या, जो इन स्थितियों में, कम से कम एक के बराबर है)।
इस प्रकार, अतिसूक्ष्म तक उच्च क्रम, Δх→0 के लिए हम इस संभावना पर विचार कर सकते हैं कि अनुभाग पर एक (कम से कम एक) बिंदु गिरेगा Δх λ·Δх के बराबर है, और संभावना है कि कोई भी 1-c·Δх के बराबर नहीं गिरेगा।
आइए इसका उपयोग खंड एल पर पड़ने वाले बिल्कुल एम बिंदुओं की संभावना पीएम की गणना करने के लिए करें। आइए खंड l को लंबाई के n बराबर भागों में विभाजित करें। हम प्राथमिक खंड Δx को "खाली" कहने के लिए सहमत हैं यदि इसमें एक भी बिंदु नहीं है, और यदि कम से कम एक होता है तो इसे "कब्जा कर लिया गया" कहते हैं। उपरोक्त के अनुसार, खंड Δх पर "कब्जा" होने की संभावना लगभग λ·Δх= के बराबर है; इसके "खाली" होने की प्रायिकता 1- है। चूँकि, शर्त 2 के अनुसार, गैर-अतिव्यापी खंडों में आने वाले बिंदु स्वतंत्र हैं, तो हमारे n खंडों को n स्वतंत्र "प्रयोगों" के रूप में माना जा सकता है, जिनमें से प्रत्येक खंड को प्रायिकता p= के साथ "कब्जा" किया जा सकता है। आइए इसकी प्रायिकता ज्ञात करें कि n खंडों के बीच बिल्कुल m का "कब्जा" होगा। बार-बार स्वतंत्र परीक्षणों के प्रमेय के अनुसार, यह संभावना बराबर है
![]() ,
,
या आइए हम λl=a को निरूपित करें:
![]() .
.
पर्याप्त रूप से बड़े n के लिए, यह संभावना लगभग खंड l पर पड़ने वाले बिल्कुल m बिंदुओं की संभावना के बराबर है खंड Δx पर दो या दो से अधिक बिंदुओं के गिरने की संभावना नगण्य है। खोजने के क्रम में सही मूल्यРm, आपको n→∞ के रूप में सीमा तक जाने की आवश्यकता है:

ध्यान में रख कर
![]()
 ,
,
हम पाते हैं कि वांछित संभाव्यता सूत्र द्वारा व्यक्त की जाती है
जहां a=λl, यानी X का मान पॉइसन के नियम के अनुसार पैरामीटर a=λl के साथ वितरित किया जाता है।
यह ध्यान दिया जाना चाहिए कि अर्थ में मान a प्रति खंड l अंकों की औसत संख्या को दर्शाता है। R1 का मान (संभावना है कि X का मान एक सकारात्मक मान लेगा)। इस मामले मेंसंभावना व्यक्त करता है कि कम से कम एक बिंदु खंड l पर पड़ेगा: R1=1-e-a।
इस प्रकार, हम आश्वस्त हैं कि पॉइसन वितरण तब होता है जहां कुछ बिंदु (या अन्य तत्व) एक दूसरे से स्वतंत्र रूप से यादृच्छिक स्थिति पर कब्जा कर लेते हैं, और किसी क्षेत्र में आने वाले इन बिंदुओं की संख्या की गणना की जाती है। हमारे मामले में, ऐसा क्षेत्र भुज अक्ष पर खंड एल था। हालाँकि, इस निष्कर्ष को समतल (बिंदुओं के यादृच्छिक समतल क्षेत्र) और अंतरिक्ष में (बिंदुओं के यादृच्छिक स्थानिक क्षेत्र) पर बिंदुओं के वितरण के मामले में आसानी से बढ़ाया जा सकता है। यह सिद्ध करना कठिन नहीं है कि यदि शर्तें पूरी होती हैं:
1) अंक औसत घनत्व λ के साथ क्षेत्र में सांख्यिकीय रूप से समान रूप से वितरित किए जाते हैं;
2) अंक स्वतंत्र रूप से गैर-अतिव्यापी क्षेत्रों में आते हैं;
3) बिंदु अकेले दिखाई देते हैं, जोड़े, त्रिक आदि में नहीं।
फिर किसी भी क्षेत्र D (सपाट या स्थानिक) में आने वाले बिंदुओं X की संख्या पॉइसन के नियम के अनुसार वितरित की जाती है:
![]() ,
,
जहां a क्षेत्र D में आने वाले बिंदुओं की औसत संख्या है।
एक समतल मामले के लिए a=SD λ, जहां SD क्षेत्र D का क्षेत्रफल है,
स्थानिक a= VD λ के लिए, जहां VD क्षेत्र D का आयतन है।
किसी खंड या क्षेत्र में आने वाले बिंदुओं की संख्या के पॉइसन वितरण के लिए, निरंतर घनत्व (λ=const) की स्थिति महत्वहीन है। यदि अन्य दो शर्तें पूरी हो जाती हैं, तो पॉइसन का नियम अभी भी कायम है, इसमें केवल पैरामीटर a एक अलग अभिव्यक्ति लेता है: यह केवल घनत्व λ को लंबाई, क्षेत्र या आयतन से गुणा करके नहीं, बल्कि चर घनत्व को एकीकृत करके प्राप्त किया जाता है। खंड, क्षेत्र या आयतन पर।
पॉइसन वितरण चलता है महत्वपूर्ण भूमिकाभौतिकी, संचार सिद्धांत, विश्वसनीयता सिद्धांत, कतारबद्ध सिद्धांत, आदि के कई मुद्दों में। कहीं भी, जहां एक निश्चित अवधि में यादृच्छिक संख्या में घटनाएं (रेडियोधर्मी क्षय, टेलीफोन कॉल, उपकरण विफलता, दुर्घटनाएं, आदि) घटित हो सकती हैं।
आइए सबसे विशिष्ट स्थिति पर विचार करें जिसमें पॉइसन वितरण उत्पन्न होता है। कुछ घटनाओं (दुकान में खरीदारी) को यादृच्छिक समय पर होने दें। आइए 0 से T तक के समय अंतराल में ऐसी घटनाओं की घटित होने वाली संख्या निर्धारित करें।
0 से T तक के समय के दौरान घटित घटनाओं की यादृच्छिक संख्या को पॉइसन के नियम के अनुसार पैरामीटर l=aT के साथ वितरित किया जाता है, जहां a>0 घटनाओं की औसत आवृत्ति को दर्शाने वाला एक समस्या पैरामीटर है। बड़े समय अंतराल (उदाहरण के लिए, एक दिन) में खरीदारी की संभावना k होगी
निष्कर्ष
अंत में, मैं यह नोट करना चाहूंगा कि पॉइसन वितरण एक काफी सामान्य और महत्वपूर्ण वितरण है, जिसका अनुप्रयोग संभाव्यता सिद्धांत और उसके अनुप्रयोगों दोनों में होता है। गणितीय सांख्यिकी.
कई व्यावहारिक समस्याएँ अंततः पॉइसन वितरण में आ जाती हैं। इसकी विशेष संपत्ति, जिसमें गणितीय अपेक्षा और विचरण की समानता शामिल है, का उपयोग अक्सर इस सवाल को हल करने के लिए किया जाता है कि एक यादृच्छिक चर को पॉइसन के नियम के अनुसार वितरित किया जाता है या नहीं।
यह तथ्य भी महत्वपूर्ण है कि पॉइसन का नियम बड़ी संख्या में प्रयोग की पुनरावृत्ति और एक छोटी एकल संभावना के साथ बार-बार स्वतंत्र परीक्षणों में किसी घटना की संभावनाओं को खोजने की अनुमति देता है।
हालाँकि, बर्नौली वितरण का उपयोग आर्थिक गणना के अभ्यास में और विशेष रूप से स्थिरता विश्लेषण में बहुत कम ही किया जाता है। यह कम्प्यूटेशनल कठिनाइयों और बर्नौली वितरण के तथ्य दोनों के कारण है पृथक मात्राएँ, और इस तथ्य के साथ कि शास्त्रीय योजना की शर्तें (स्वतंत्रता, परीक्षणों की गणनीय संख्या, किसी घटना के घटित होने की संभावना को प्रभावित करने वाली स्थितियों की अपरिवर्तनीयता) हमेशा व्यावहारिक स्थितियों में पूरी नहीं होती हैं। बर्नौली योजना के विश्लेषण के क्षेत्र में आगे का शोध 18वीं-19वीं शताब्दी में किया गया। लाप्लास, मोइवर, पॉइसन और अन्य का उद्देश्य अनंत तक बड़ी संख्या में परीक्षणों के मामले में बर्नौली योजना का उपयोग करने की संभावना पैदा करना था।
साहित्य
1. वेंटज़ेल ई.एस. सिद्धांत संभावना। - एम, "हायर स्कूल" 1998
2. गमुरमन वी.ई. संभाव्यता सिद्धांत और गणितीय सांख्यिकी में समस्याओं को हल करने के लिए एक मार्गदर्शिका। - एम, "हायर स्कूल" 1998
3. महाविद्यालयों के लिए गणित की समस्याओं का संग्रह। ईडी। एफिमोवा ए.वी. - एम, विज्ञान 1990
आइए पॉइसन वितरण पर विचार करें, इसकी गणितीय अपेक्षा, विचरण और मोड की गणना करें। MS EXCEL फ़ंक्शन POISSON.DIST() का उपयोग करके, हम वितरण फ़ंक्शन और संभाव्यता घनत्व के ग्राफ़ का निर्माण करेंगे। आइए हम वितरण पैरामीटर, इसकी गणितीय अपेक्षा और मानक विचलन का अनुमान लगाएं।
सबसे पहले, हम वितरण की एक शुष्क औपचारिक परिभाषा देते हैं, फिर हम उन स्थितियों का उदाहरण देते हैं जब पॉसों वितरण(अंग्रेज़ी) प्वासोंवितरण) एक यादृच्छिक चर का वर्णन करने के लिए एक पर्याप्त मॉडल है।
यदि किसी निश्चित समयावधि में (या पदार्थ के एक निश्चित आयतन में) यादृच्छिक घटनाएँ घटित होती हैं औसत आवृत्ति λ( लैम्ब्डा), फिर घटनाओं की संख्या एक्स, इस अवधि के दौरान हुआ होगा पॉसों वितरण.
पॉइसन वितरण का अनुप्रयोग
उदाहरण जब पॉसों वितरणएक पर्याप्त मॉडल है:
- एक निश्चित अवधि में टेलीफोन एक्सचेंज पर प्राप्त कॉलों की संख्या;
- एक निश्चित अवधि में रेडियोधर्मी क्षय से गुजरने वाले कणों की संख्या;
- एक निश्चित लंबाई के कपड़े के टुकड़े में दोषों की संख्या।
पॉसों वितरणयदि निम्नलिखित शर्तें पूरी होती हैं तो यह एक पर्याप्त मॉडल है:
- घटनाएँ एक दूसरे से स्वतंत्र रूप से घटित होती हैं, अर्थात् अगली घटना की संभावना पिछली घटना पर निर्भर नहीं करती;
- औसत घटना दर स्थिर है. परिणामस्वरूप, किसी घटना की संभावना अवलोकन अंतराल की लंबाई के समानुपाती होती है;
- दो घटनाएँ एक ही समय में घटित नहीं हो सकतीं;
- घटनाओं की संख्या का मान 0 होना चाहिए; 1; 2…
टिप्पणी: एक अच्छा सुराग यह है कि प्रेक्षित यादृच्छिक चर है पॉसों वितरण,तथ्य यह है कि यह लगभग बराबर है (नीचे देखें)।
नीचे उन स्थितियों के उदाहरण दिए गए हैं जहां पॉसों वितरण नही सकतालागू हो जाए:
- एक घंटे के भीतर विश्वविद्यालय छोड़ने वाले छात्रों की संख्या (चूंकि छात्रों का औसत प्रवाह स्थिर नहीं है: कक्षाओं के दौरान कुछ छात्र होते हैं, और कक्षाओं के बीच ब्रेक के दौरान छात्रों की संख्या तेजी से बढ़ जाती है);
- कैलिफ़ोर्निया में प्रति वर्ष 5 अंक के आयाम वाले भूकंपों की संख्या (चूंकि एक भूकंप समान आयाम के झटके पैदा कर सकता है - घटनाएं स्वतंत्र नहीं हैं);
- मरीजों द्वारा विभाग में बिताए गए दिनों की संख्या गहन देखभाल(क्योंकि गहन देखभाल इकाई में मरीज़ों द्वारा बिताए गए दिनों की संख्या हमेशा 0 से अधिक होती है)।
टिप्पणी: पॉसों वितरणअधिक सटीक का एक अनुमान है असतत वितरण: और ।
टिप्पणी: रिश्ते के बारे में पॉसों वितरणऔर द्विपद वितरणलेख में पढ़ा जा सकता है. रिश्ते के बारे में पॉसों वितरणऔर घातांकी रूप से वितरणके बारे में लेख में पढ़ा जा सकता है।
एमएस एक्सेल में पॉइसन वितरण
MS EXCEL में, संस्करण 2010 से प्रारंभ करते हुए वितरण प्वासोंएक फ़ंक्शन POISSON.DIST() है, अंग्रेजी नाम- POISSON.DIST(), जो आपको न केवल एक निश्चित अवधि में क्या होगा इसकी संभावना की गणना करने की अनुमति देता है एक्सघटनाएँ (फ़ंक्शन संभावित गहराईपी(एक्स), ऊपर सूत्र देखें), लेकिन यह भी (संभावना है कि किसी निश्चित अवधि के दौरान कम से कम एक्सआयोजन)।
MS EXCEL 2010 से पहले, EXCEL में POISSON() फ़ंक्शन था, जो आपको गणना करने की भी अनुमति देता है वितरण समारोहऔर संभावित गहराईपी(एक्स). अनुकूलता के लिए MS EXCEL 2010 में POISSON() को छोड़ दिया गया है।
उदाहरण फ़ाइल में ग्राफ़ हैं संभाव्यता घनत्व वितरणऔर संचयी वितरण कार्य.

पॉसों वितरणइसका आकार तिरछा है (संभावना फ़ंक्शन के दाईं ओर एक लंबी पूंछ), लेकिन जैसे-जैसे पैरामीटर λ बढ़ता है, यह अधिक से अधिक सममित हो जाता है।
टिप्पणी: औसतऔर फैलाव(वर्ग) पैरामीटर के बराबर हैं पॉसों वितरण- λ (देखें उदाहरण शीट फ़ाइल उदाहरण).
काम
ठेठ आवेदन पॉइसन वितरणगुणवत्ता नियंत्रण में किसी उपकरण या डिवाइस में दिखाई देने वाले दोषों की संख्या का एक मॉडल होता है।
उदाहरण के लिए, एक चिप λ (लैम्ब्डा) में दोषों की औसत संख्या 4 के बराबर होने पर, यादृच्छिक रूप से चयनित चिप में 2 या उससे कम दोष होने की संभावना है: = POISSON.DIST(2,4,TRUE)=0.2381
फ़ंक्शन में तीसरा पैरामीटर = TRUE सेट है, इसलिए फ़ंक्शन वापस आ जाएगा संचयी वितरण कार्य, यानी, संभावना है कि यादृच्छिक घटनाओं की संख्या 0 से 4 तक की सीमा में होगी।
इस मामले में गणना सूत्र के अनुसार की जाती है:
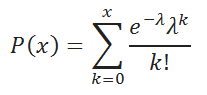
संभावना है कि यादृच्छिक रूप से चयनित माइक्रोक्रिकिट में बिल्कुल 2 दोष होंगे: = POISSON.DIST(2,4,FALSE)=0.1465
फ़ंक्शन में तीसरा पैरामीटर = FALSE सेट है, इसलिए फ़ंक्शन संभाव्यता घनत्व लौटाएगा।
यादृच्छिक रूप से चयनित माइक्रोक्रिकिट में 2 से अधिक दोष होने की संभावना बराबर है: =1-पॉइसन.जिला(2,4,सत्य) =0.8535
टिप्पणी: अगर एक्सएक पूर्णांक नहीं है, तो सूत्र की गणना करते समय। सूत्रों =POISSON.DIST( 2 ; 4; झूठ)और =POISSON.DIST( 2,9 ; 4; झूठ)वही परिणाम लौटाएगा.
यादृच्छिक संख्या निर्माण और λ अनुमान
λ के मानों के लिए >15 , पॉसों वितरणअच्छी तरह से अनुमानित सामान्य वितरण निम्नलिखित मापदंडों के साथ: μ =λ , σ 2 =λ .
इन वितरणों के बीच संबंध के बारे में अधिक विवरण लेख में पाया जा सकता है। सन्निकटन के उदाहरण भी हैं, और यह कब संभव है और कितनी सटीकता के साथ संभव है इसकी शर्तें बताई गई हैं।
सलाह: आप लेख में अन्य MS EXCEL वितरणों के बारे में पढ़ सकते हैं।
कई व्यावहारिक रूप से महत्वपूर्ण अनुप्रयोगों में, पॉइसन वितरण एक महत्वपूर्ण भूमिका निभाता है। कई संख्यात्मक असतत मात्राएँ पॉइसन प्रक्रिया का कार्यान्वयन हैं, जिसमें निम्नलिखित गुण हैं:
- हम इस बात में रुचि रखते हैं कि किसी दिए गए क्षेत्र में कोई निश्चित घटना कितनी बार घटित होती है संभावित नतीजेयादृच्छिक प्रयोग. संभावित परिणामों का क्षेत्र एक समय अंतराल, एक खंड, एक सतह आदि हो सकता है।
- किसी दी गई घटना की संभावना संभावित परिणामों के सभी क्षेत्रों के लिए समान है।
- संभावित परिणामों के एक क्षेत्र में होने वाली घटनाओं की संख्या अन्य क्षेत्रों में होने वाली घटनाओं की संख्या से स्वतंत्र होती है।
- किसी दी गई घटना के संभावित परिणामों के एक ही क्षेत्र में एक से अधिक बार घटित होने की संभावना शून्य हो जाती है क्योंकि संभावित परिणामों का क्षेत्र घट जाता है।
पॉइसन प्रक्रिया के अर्थ को और समझने के लिए, मान लीजिए कि हम दोपहर के भोजन के दौरान केंद्रीय व्यापार जिले में स्थित एक बैंक शाखा में आने वाले ग्राहकों की संख्या की जांच करते हैं, यानी। 12 से 13 बजे तक. मान लीजिए आप एक मिनट में आने वाले ग्राहकों की संख्या निर्धारित करना चाहते हैं। क्या इस स्थिति में ऊपर सूचीबद्ध विशेषताएं हैं? सबसे पहले, जिस घटना में हमारी रुचि है वह एक ग्राहक का आगमन है, और संभावित परिणामों की सीमा एक मिनट का अंतराल है। एक मिनट में कितने ग्राहक बैंक में आएंगे - कोई नहीं, एक, दो या अधिक? दूसरे, यह मान लेना उचित है कि एक मिनट के भीतर ग्राहक के आने की संभावना सभी एक मिनट के अंतराल के लिए समान है। तीसरा, किसी एक मिनट के अंतराल के दौरान एक ग्राहक का आगमन किसी अन्य एक मिनट के अंतराल के दौरान किसी अन्य ग्राहक के आगमन से स्वतंत्र है। और अंत में, यदि समय अंतराल शून्य हो जाता है, उदाहरण के लिए, 0.1 सेकंड से कम हो जाता है, तो बैंक में एक से अधिक ग्राहकों के आने की संभावना शून्य हो जाती है। तो, एक मिनट के भीतर दोपहर के भोजन के दौरान बैंक में आने वाले ग्राहकों की संख्या को पॉइसन वितरण द्वारा वर्णित किया गया है।
पॉइसन वितरण में एक पैरामीटर होता है, जिसे प्रतीक λ (ग्रीक अक्षर "लैम्ब्डा") द्वारा दर्शाया जाता है - संभावित परिणामों के किसी दिए गए क्षेत्र में सफल परीक्षणों की औसत संख्या। पॉइसन वितरण का विचरण भी λ है, और इसका मानक विचलन है। सफल परीक्षणों की संख्या एक्सपॉइसन यादृच्छिक चर 0 से अनंत तक भिन्न होता है। पॉइसन वितरण सूत्र द्वारा वर्णित है:

कहाँ पी(एक्स)- संभावना एक्ससफल परीक्षण, λ - सफलताओं की अपेक्षित संख्या, इ- आधार प्राकृतिक, 2.71828 के बराबर, एक्स- समय की प्रति इकाई सफलताओं की संख्या।
आइए अपने उदाहरण पर वापस लौटें। मान लीजिए कि लंच ब्रेक के दौरान प्रति मिनट औसतन तीन ग्राहक बैंक आते हैं। इसकी क्या प्रायिकता है कि एक निश्चित समय पर दो ग्राहक बैंक में आएंगे? इसकी क्या संभावना है कि दो से अधिक ग्राहक बैंक में आएंगे?
आइए पैरामीटर λ = 3 के साथ सूत्र (1) लागू करें। फिर एक निश्चित मिनट के भीतर दो ग्राहकों के बैंक में आने की संभावना बराबर है
दो से अधिक ग्राहकों के बैंक में आने की संभावना P(X > 2) = P(X = 3) + P(X = 4) + … + P(X = ∞) के बराबर है। चूँकि सभी संभावनाओं का योग 1 के बराबर होना चाहिए, सूत्र के दाईं ओर श्रृंखला के पद घटना X ≤ 2 के जुड़ने की संभावना को दर्शाते हैं। दूसरे शब्दों में, इस श्रृंखला का योग 1 के बराबर है - पी(एक्स ≤ 2). इस प्रकार, P(X>2) = 1 – P(X≤2) = 1 – [P(X = 0) + P(X = 1) + P(X = 2)]। अब, सूत्र (1) का उपयोग करके, हम पाते हैं:
इस प्रकार, एक मिनट के भीतर दो से अधिक ग्राहकों के बैंक में आने की संभावना 0.423 (या 42.3%) है, और एक मिनट के भीतर दो से अधिक ग्राहकों के बैंक में आने की संभावना 0.577 (या 57.7%) है।
ऐसी गणनाएँ कठिन लग सकती हैं, खासकर यदि पैरामीटर λ काफी बड़ा है। जटिल गणनाओं से बचने के लिए, कई पॉइसन संभावनाएं विशेष तालिकाओं में पाई जा सकती हैं (चित्र 1)। उदाहरण के लिए, एक निश्चित मिनट में दो ग्राहकों के बैंक में आने की संभावना, यदि प्रति मिनट औसतन तीन ग्राहक बैंक में आते हैं, तो लाइन के चौराहे पर है एक्स= 2 और कॉलम λ = 3. इस प्रकार, यह 0.2240 या 22.4% के बराबर है।

चावल। 1. λ = 3 पर पॉइसन संभावना
आजकल, यह संभावना नहीं है कि यदि Excel अपने =POISSON.DIST() फ़ंक्शन के साथ मौजूद है तो कोई भी तालिकाओं का उपयोग करेगा (चित्र 2)। इस फ़ंक्शन के तीन पैरामीटर हैं: सफल परीक्षणों की संख्या एक्स, सफल परीक्षणों की औसत अपेक्षित संख्या λ, पैरामीटर अभिन्न, दो मान लेते हुए: गलत - इस मामले में सफल परीक्षणों की संख्या की संभावना की गणना की जाती है एक्स(केवल X), सत्य - इस मामले में सफल परीक्षणों की संख्या की संभावना 0 से है एक्स।

चावल। 2. λ = 3 पर पॉइसन वितरण की संभावनाओं की एक्सेल में गणना
पॉइसन वितरण का उपयोग करके द्विपद वितरण का अनुमान
यदि संख्या एनबड़ी और संख्या है आर- छोटा, द्विपद वितरण का अनुमान पॉइसन वितरण का उपयोग करके लगाया जा सकता है। कैसे बड़ी संख्या एनऔर कम संख्या आर, सन्निकटन सटीकता जितनी अधिक होगी। द्विपद वितरण का अनुमान लगाने के लिए निम्नलिखित पॉइसन मॉडल का उपयोग किया जाता है।

कहाँ पी(एक्स)- संभावना एक्सदिए गए मापदंडों के साथ सफलता एनऔर आर, एन- नमूने का आकार, आर- सफलता की सच्ची संभावना, इ- प्राकृतिक लघुगणक का आधार, एक्स- नमूने में सफलताओं की संख्या (X = 0, 1, 2,…, एन).
सैद्धांतिक रूप से, पॉइसन वितरण वाला एक यादृच्छिक चर 0 से ∞ तक मान लेता है। हालाँकि, उन स्थितियों में जहां पॉइसन वितरण का उपयोग द्विपद वितरण का अनुमान लगाने के लिए किया जाता है, पॉइसन यादृच्छिक चर बीच में सफलताओं की संख्या है एनअवलोकन - संख्या से अधिक नहीं हो सकते एन. सूत्र (2) से यह पता चलता है कि बढ़ती संख्या के साथ एनऔर संख्या में कमी आरबड़ी संख्या में सफलताओं का पता लगाने की संभावना कम हो जाती है और शून्य हो जाती है।
जैसा कि ऊपर उल्लेख किया गया है, पॉइसन वितरण की अपेक्षा µ और विचरण σ 2 λ के बराबर हैं। इसलिए, पॉइसन वितरण का उपयोग करके द्विपद वितरण का अनुमान लगाते समय, गणितीय अपेक्षा का अनुमान लगाने के लिए सूत्र (3) का उपयोग किया जाना चाहिए।
(3) µ = ई(एक्स) = λ =एन.पी.
मानक विचलन का अनुमान लगाने के लिए सूत्र (4) का उपयोग किया जाता है।
![]()
कृपया ध्यान दें कि सूत्र (4) का उपयोग करके गणना की गई मानक विचलन की प्रवृत्ति होती है मानक विचलनद्विपद मॉडल में - जब सफलता की संभावना पीशून्य हो जाता है, और, तदनुसार, विफलता की संभावना 1 - पीएकता की ओर प्रवृत्त होता है।
आइए मान लें कि एक निश्चित संयंत्र में उत्पादित 8% टायर ख़राब हैं। द्विपद वितरण का अनुमान लगाने के लिए पॉइसन वितरण के उपयोग को स्पष्ट करने के लिए, आइए 20 टायरों के नमूने में एक दोषपूर्ण टायर खोजने की संभावना की गणना करें। आइए हम सूत्र (2) लागू करें, हमें प्राप्त होता है

यदि हम इसके सन्निकटन के बजाय वास्तविक द्विपद वितरण की गणना करें, तो हमें निम्नलिखित परिणाम मिलेगा:

हालाँकि, ये गणनाएँ काफी कठिन हैं। हालाँकि, यदि आप संभावनाओं की गणना के लिए एक्सेल का उपयोग करते हैं, तो पॉइसन वितरण सन्निकटन का उपयोग करना अनावश्यक हो जाता है। चित्र में. चित्र 3 दर्शाता है कि एक्सेल में गणना की जटिलता समान है। हालाँकि, यह खंड, मेरी राय में, यह समझने में उपयोगी है कि कुछ स्थितियों में द्विपद वितरण और पॉइसन वितरण समान परिणाम देते हैं।

चावल। 3. एक्सेल में गणनाओं की जटिलता की तुलना: (ए) पॉइसन वितरण; (बी) द्विपद वितरण
तो, इस और पिछले दो नोटों में, तीन अलग-अलग संख्यात्मक वितरणों पर विचार किया गया था:, और पॉइसन। यह बेहतर ढंग से समझने के लिए कि ये वितरण एक-दूसरे से कैसे संबंधित हैं, हम प्रश्नों का एक छोटा पेड़ प्रस्तुत करते हैं (चित्र 4)।

चावल। 4. असतत संभाव्यता वितरण का वर्गीकरण
लेविन एट अल पुस्तक से सामग्री। प्रबंधकों के लिए सांख्यिकी का उपयोग किया जाता है। - एम.: विलियम्स, 2004. - पी. 320-328
पॉसों वितरण।
आइए सबसे विशिष्ट स्थिति पर विचार करें जिसमें पॉइसन वितरण उत्पन्न होता है। चलो घटना एअंतरिक्ष के एक निश्चित क्षेत्र (अंतराल, क्षेत्र, आयतन) या समय की अवधि में निरंतर तीव्रता के साथ एक निश्चित संख्या में दिखाई देता है। विशिष्ट होने के लिए, समय के साथ घटनाओं की क्रमिक घटना पर विचार करें, जिसे घटनाओं की एक धारा कहा जाता है। ग्राफ़िक रूप से, घटनाओं के प्रवाह को समय अक्ष पर स्थित कई बिंदुओं द्वारा चित्रित किया जा सकता है।
यह सेवा क्षेत्र (मरम्मत) में कॉल की एक धारा हो सकती है घर का सामान, एम्बुलेंस को कॉल करना, आदि), टेलीफोन एक्सचेंज में कॉल का प्रवाह, सिस्टम के कुछ हिस्सों की विफलता, रेडियोधर्मी क्षय, कपड़े या धातु की चादरों के टुकड़े और उनमें से प्रत्येक पर दोषों की संख्या, आदि। पॉइसन वितरण उन कार्यों में सबसे उपयोगी है जहां केवल सकारात्मक परिणामों ("सफलताओं") की संख्या निर्धारित करना आवश्यक है।
आइए किशमिश के साथ एक रोटी की कल्पना करें, जो समान आकार के छोटे टुकड़ों में विभाजित है। इस कारण यादृच्छिक वितरणकिशमिश, आप यह उम्मीद नहीं कर सकते कि सभी टुकड़ों में समान संख्या में किशमिश हों। जब इन टुकड़ों में किशमिश की औसत संख्या ज्ञात होती है, तो पॉइसन वितरण यह संभावना देता है कि किसी दिए गए टुकड़े में किशमिश है एक्स=क(क= 0,1,2,...,)किशमिशों की संख्या.
दूसरे शब्दों में, पॉइसन वितरण यह निर्धारित करता है कि टुकड़ों की लंबी श्रृंखला के किस भाग में 0, या 1, या 2, या आदि के बराबर होगा। हाइलाइट्स की संख्या.
आइए निम्नलिखित धारणाएँ बनाएँ।
1. किसी दिए गए समय अंतराल में निश्चित संख्या में घटनाओं के घटित होने की संभावना केवल इस अंतराल की लंबाई पर निर्भर करती है, न कि समय अक्ष पर इसकी स्थिति पर। यह स्थिरता का गुण है.
2. पर्याप्त रूप से कम समय में एक से अधिक घटनाओं का घटित होना व्यावहारिक रूप से असंभव है, अर्थात। समान अंतराल में किसी अन्य घटना के घटित होने की सशर्त संभावना ® 0 के रूप में शून्य हो जाती है। यह सामान्यता का गुण है।
3. किसी निश्चित समयावधि में घटित होने वाली घटनाओं की संख्या की संभावना अन्य समयावधियों में घटित होने वाली घटनाओं की संख्या पर निर्भर नहीं करती है। यह परिणाम न होने का गुण है।
उपरोक्त प्रस्तावों को संतुष्ट करने वाली घटनाओं का प्रवाह कहलाता है सबसे आसान.
आइए काफी कम समयावधि पर विचार करें। गुण 2 के आधार पर, घटना इस अंतराल में एक बार प्रकट हो सकती है या बिल्कुल भी प्रकट नहीं हो सकती है। आइए हम किसी घटना के घटित होने की प्रायिकता को निरूपित करें आर, और गैर-उपस्थिति - के माध्यम से क्यू = 1-पी।संभावना आरस्थिर है (संपत्ति 3) और केवल मूल्य (संपत्ति 1) पर निर्भर करता है। अंतराल में किसी घटना के घटित होने की संख्या की गणितीय अपेक्षा 0× के बराबर होगी क्यू+ 1× पी = पी. तब प्रति इकाई समय में घटनाओं के घटित होने की औसत संख्या को प्रवाह तीव्रता कहा जाता है और इसे इसके द्वारा निरूपित किया जाता है ए,वे। ए = .
समय की एक सीमित अवधि पर विचार करें टीऔर इसे विभाजित करें एनभाग = . इनमें से प्रत्येक अंतराल में घटनाओं की घटनाएँ स्वतंत्र हैं (संपत्ति 2)। आइए हम किसी समयावधि में इसकी प्रायिकता निर्धारित करें टीनिरंतर प्रवाह तीव्रता पर एघटना हूबहू दिखाई देगी एक्स = केदोबारा दिखाई नहीं देगा एन-के. चूँकि प्रत्येक में एक घटना हो सकती है एनअंतराल 1 बार से अधिक प्रकट नहीं होते हैं, फिर इसकी उपस्थिति के लिए कअवधि के एक खंड में एक बार टीयह किसी में भी दिखना चाहिए ककुल से अंतराल एन।ऐसे कुल संयोजन हैं, और प्रत्येक की संभावना बराबर है। परिणामस्वरूप, संभाव्यता के योग प्रमेय द्वारा हम वांछित संभाव्यता प्राप्त करते हैं सुप्रसिद्ध सूत्र Bernoulli
यह समानता एक अनुमानित के रूप में लिखी गई है, क्योंकि इसकी व्युत्पत्ति का प्रारंभिक आधार संपत्ति 2 था, जो कि छोटे से अधिक सटीक रूप से पूरा होता है। सटीक समानता प्राप्त करने के लिए, आइए हम ® 0 पर सीमा पार करें या, जो समान है, एन® . प्रतिस्थापन के बाद हम इसे प्राप्त कर लेंगे
पी = ए= और क्यू = 1 – .
आइए एक नया पैरामीटर पेश करें = पर, जिसका अर्थ है किसी खंड में किसी घटना के घटित होने की औसत संख्या टी. सरल परिवर्तनों और कारकों में सीमा तक जाने के बाद, हम प्राप्त करते हैं।
![]() = 1, = ,
= 1, = ,
अंततः हम पाते हैं
, क = 0, 1, 2, ...
ई = 2.718... प्राकृतिक लघुगणक का आधार है।
परिभाषा. यादृच्छिक मूल्य एक्स, जो केवल पूर्णांक लेता है, सकारात्मक मान 0, 1, 2, ... पैरामीटर के साथ एक पॉइसन वितरण कानून है यदि
![]() के लिए क = 0, 1, 2, ...
के लिए क = 0, 1, 2, ...
पॉइसन वितरण फ्रांसीसी गणितज्ञ एस.डी. द्वारा प्रस्तावित किया गया था। पॉइसन (1781-1840)। इसका उपयोग समय, लंबाई, क्षेत्रफल और आयतन की प्रति इकाई अपेक्षाकृत दुर्लभ, यादृच्छिक, परस्पर स्वतंत्र घटनाओं की संभावनाओं की गणना करने की समस्याओं को हल करने के लिए किया जाता है।
उस स्थिति के लिए जब a) बड़ा हो और b) क=, स्टर्लिंग सूत्र मान्य है:
बाद के मानों की गणना करने के लिए, एक आवर्ती सूत्र का उपयोग किया जाता है
पी(क + 1) = पी(क).
उदाहरण 1. इसकी क्या प्रायिकता है कि किसी दिए गए दिन 1000 लोगों में से: a) कोई नहीं, b) एक, c) दो, d) तीन लोग पैदा हुए?
समाधान। क्योंकि पी= 1/365, फिर क्यू= 1 - 1/365 = 364/365 "1.
तब ![]()
ए) ![]() ,
,
बी) ![]() ,
,
वी) ![]() ,
,
जी) ![]() .
.
इसलिए, यदि 1000 लोगों के नमूने हैं, तो किसी विशेष दिन में पैदा हुए लोगों की औसत संख्या तदनुसार 65 होगी; 178; 244; 223.
उदाहरण 2. संभाव्यता के साथ वह मान निर्धारित करें जिस पर आरघटना कम से कम एक बार सामने आई।
समाधान। आयोजन ए= (कम से कम एक बार प्रकट) और = (एक बार भी प्रकट नहीं)। इस तरह ।
यहाँ से ![]() और ।
और ।
उदाहरण के लिए, के लिए आर= 0.5, के लिए आर= 0,95 .
उदाहरण 3. एक बुनकर द्वारा संचालित करघे पर एक घंटे के भीतर 90 धागे टूट जाते हैं। प्रायिकता ज्ञात कीजिए कि 4 मिनट में कम से कम एक धागा टूट जाएगा।
समाधान। शर्त से टी = 4 मिनट. और प्रति मिनट ब्रेक की औसत संख्या, कहां से ![]() . अभीष्ट प्रायिकता है।
. अभीष्ट प्रायिकता है।
गुण. पैरामीटर के साथ पॉइसन वितरण वाले एक यादृच्छिक चर की गणितीय अपेक्षा और भिन्नता इसके बराबर है:
एम(एक्स) = डी(एक्स) = .
ये अभिव्यक्तियाँ प्रत्यक्ष गणना द्वारा प्राप्त की जाती हैं:
यहीं पर प्रतिस्थापन किया गया था एन = क– 1 और तथ्य यह है कि.
आउटपुट में उपयोग किए गए परिवर्तनों के समान परिवर्तन करके एम(एक्स), हम पाते हैं
![]()
पॉइसन वितरण का उपयोग बड़े पैमाने पर द्विपद वितरण का अनुमान लगाने के लिए किया जाता है एन
अधिकांश सामान्य मामला विभिन्न प्रकारसंभाव्यता वितरण द्विपद वितरण हैं। आइए हम व्यवहार में आने वाले सबसे सामान्य विशेष प्रकार के वितरणों को निर्धारित करने के लिए इसकी बहुमुखी प्रतिभा का उपयोग करें।
द्विपद वितरण
चलो कोई इवेंट ए हो. घटना A के घटित होने की प्रायिकता बराबर है पी, घटना A के घटित न होने की प्रायिकता 1 है पी, कभी-कभी इसे इस रूप में निर्दिष्ट किया जाता है क्यू. होने देना एनपरीक्षणों की संख्या, एमइनमें घटना A के घटित होने की आवृत्ति एनपरीक्षण.
यह ज्ञात है कि परिणामों के सभी संभावित संयोजनों की कुल संभावना एक के बराबर है, अर्थात:
1 = पी एन + एन · पी एन 11 पी) + सी एन एन 2 · पी एन 2(1 पी) 2 + + सी एन एम · पी एम· (1 पी) एन एम+ + (1 पी) एन .
|
पी एनसंभावना है कि में एनएनएक बार; एन · पी एन 11 पी) संभावना है कि में एनएन 1) एक बार और 1 बार नहीं होगा; सी एन एन 2 · पी एन 2(1 पी) 2 संभावना है कि में एनपरीक्षण, घटना ए घटित होगी ( एन 2) बार और 2 बार नहीं होगा; पी एम = सी एन एम · पी एम· (1 पी) एन एम संभावना है कि में एनपरीक्षण, घटना ए घटित होगी एमकभी नहीं होगा ( एन एम) एक बार; (1 पी) एनसंभावना है कि में एनपरीक्षणों में, घटना A एक बार भी घटित नहीं होगी; के संयोजनों की संख्या एनद्वारा एम . |
अपेक्षित मूल्य एमद्विपद वितरण इसके बराबर है:
एम = एन · पी ,
कहाँ एनपरीक्षणों की संख्या, पीघटना A के घटित होने की संभावना.
मानक विचलन σ :
σ = sqrt( एन · पी· (1 पी)) .
उदाहरण 1। उस घटना की प्रायिकता की गणना करें जिसकी प्रायिकता है पी= 0.5, इंच एन= 10 ट्रायल होंगे एम= 1 बार. हमारे पास है: सी 10 1 = 10, और आगे: पी 1 = 10 0.5 1 (1 0.5) 10 1 = 10 0.5 10 = 0.0098. जैसा कि हम देख सकते हैं, इस घटना के घटित होने की संभावना काफी कम है। इसे, सबसे पहले, इस तथ्य से समझाया गया है कि यह बिल्कुल स्पष्ट नहीं है कि घटना घटित होगी या नहीं, क्योंकि संभावना 0.5 है और यहां संभावना "50 से 50" है; और दूसरी बात, यह गणना करना आवश्यक है कि घटना दस में से ठीक एक बार (न अधिक और न कम) घटित होगी।
उदाहरण 2. उस घटना की प्रायिकता की गणना करें जिसकी प्रायिकता है पी= 0.5, इंच एन= 10 ट्रायल होंगे एम= 2 बार. हमारे पास है: सी 10 2 = 45, और आगे: पी 2 = 45 0.5 2 (1 0.5) 10 2 = 45 0.5 10 = 0.044. इस घटना के घटित होने की संभावना बढ़ गई है!
उदाहरण 3. आइए घटना के घटित होने की संभावना को बढ़ाएँ। आइए इसे और अधिक संभावित बनाएं। उस घटना की प्रायिकता की गणना करें जिसकी प्रायिकता है पी= 0.8, इंच एन= 10 ट्रायल होंगे एम= 1 बार. हमारे पास है: सी 10 1 = 10, और आगे: पी 1 = 10 0.8 1 (1 0.8) 10 1 = 10 0.8 1 0.2 9 = 0.000004. संभावना पहले उदाहरण की तुलना में कम हो गई है! उत्तर, पहली नज़र में, अजीब लगता है, लेकिन चूंकि घटना की संभावना काफी अधिक है, इसलिए इसके केवल एक बार घटित होने की संभावना नहीं है। इसकी अधिक संभावना है कि ऐसा एक से अधिक बार होगा। दरअसल, गिनती पी 0 , पी 1 , पी 2 , पी 3, , पी 10 (संभावना है कि एक घटना में एन= 10 परीक्षण 0, 1, 2, 3, 10 बार होंगे), हम देखेंगे:
सी 10 0 = 1
,
सी 10 1 = 10
,
सी 10 2 = 45
,
सी 10 3 = 120
,
सी 10 4 = 210
,
सी 10 5 = 252
,
सी 10 6 = 210
,
सी 10 7 = 120
,
सी 10 8 = 45
,
सी 10 9 = 10
,
सी 10 10 = 1
;
पी 0 = 1 0.8 0 (1 0.8) 10 0 = 1 1 0.2 10 = 0.0000;
पी 1 = 10 0.8 1 (1 0.8) 10 1 = 10 0.8 1 0.2 9 = 0.0000;
पी 2 = 45 0.8 2 (1 0.8) 10 2 = 45 0.8 2 0.2 8 = 0.0000;
पी 3 = 120 0.8 3 (1 0.8) 10 3 = 120 0.8 3 0.2 7 = 0.0008;
पी 4 = 210 0.8 4 (1 0.8) 10 4 = 210 0.8 4 0.2 6 = 0.0055;
पी 5 = 252 0.8 5 (1 0.8) 10 5 = 252 0.8 5 0.2 5 = 0.0264;
पी 6 = 210 0.8 6 (1 0.8) 10 6 = 210 0.8 6 0.2 4 = 0.0881;
पी 7 = 120 0.8 7 (1 0.8) 10 7 = 120 0.8 7 0.2 3 = 0.2013;
पी 8 = 45 0.8 8 (1 0.8) 10 8 = 45 0.8 8 0.2 2 = 0.3020(उच्चतम संभावना!);
पी 9 = 10 0.8 9 (1 0.8) 10 9 = 10 0.8 9 0.2 1 = 0.2684;
पी 10 = 1 0.8 10 (1 0.8) 10 10 = 1 0.8 10 0.2 0 = 0.1074
बिल्कुल पी 0 + पी 1 + पी 2 + पी 3 + पी 4 + पी 5 + पी 6 + पी 7 + पी 8 + पी 9 + पी 10 = 1 .
सामान्य वितरण
यदि हम मात्राओं का चित्रण करें पी 0 , पी 1 , पी 2 , पी 3, , पी 10, जिसे हमने उदाहरण 3 में गणना की है, ग्राफ़ पर, यह पता चलता है कि उनके वितरण का रूप सामान्य वितरण कानून के करीब है (चित्र 27.1 देखें) (व्याख्यान 25 देखें। सामान्य रूप से वितरित यादृच्छिक चर की मॉडलिंग)।
p = 0.8, n = 10 पर भिन्न m के लिए संभावनाएँ
यदि घटना A के घटित होने और न होने की संभावनाएँ लगभग समान हों, तो द्विपद नियम सामान्य हो जाता है, अर्थात हम सशर्त रूप से लिख सकते हैं: पी≈ (1 पी) . उदाहरण के लिए, आइए लेते हैं एन= 10 और पी= 0.5 (अर्थात पी= 1 पी = 0.5 ).
हम ऐसी समस्या पर सार्थक रूप से आएंगे यदि, उदाहरण के लिए, हम सैद्धांतिक रूप से गणना करना चाहते हैं कि एक ही दिन में प्रसूति अस्पताल में पैदा हुए 10 बच्चों में से कितने लड़के और कितनी लड़कियां होंगी। अधिक सटीक रूप से, हम लड़कों और लड़कियों को नहीं, बल्कि केवल लड़कों के पैदा होने की संभावना को गिनेंगे, कि 1 लड़का और 9 लड़कियाँ पैदा होंगी, कि 2 लड़के और 8 लड़कियाँ पैदा होंगी, इत्यादि। आइए सरलता के लिए मान लें कि एक लड़का और एक लड़की होने की संभावना समान है और 0.5 के बराबर है (लेकिन वास्तव में, ईमानदारी से कहें तो, यह मामला नहीं है, पाठ्यक्रम "मॉडलिंग आर्टिफिशियल इंटेलिजेंस सिस्टम" देखें)।
यह स्पष्ट है कि वितरण सममित होगा, क्योंकि 3 लड़के और 7 लड़कियाँ होने की संभावना 7 लड़के और 3 लड़कियाँ होने की संभावना के बराबर है। जन्म की सबसे अधिक संभावना 5 लड़के और 5 लड़कियाँ होंगी। यह संभावना 0.25 है, वैसे, यह उतनी बड़ी नहीं है निरपेक्ष मूल्य. इसके अलावा, यह संभावना कि 10 या 9 लड़के एक साथ पैदा होंगे, इस संभावना से बहुत कम है कि 10 बच्चों में से 5 ± 1 लड़का पैदा होगा। द्विपद वितरण हमें यह गणना करने में मदद करेगा। इसलिए।
सी 10 0 = 1
,
सी 10 1 = 10
,
सी 10 2 = 45
,
सी 10 3 = 120
,
सी 10 4 = 210
,
सी 10 5 = 252
,
सी 10 6 = 210
,
सी 10 7 = 120
,
सी 10 8 = 45
,
सी 10 9 = 10
,
सी 10 10 = 1
;
पी 0 = 1 0.5 0 (1 0.5) 10 0 = 1 1 0.5 10 = 0.000977;
पी 1 = 10 0.5 1 (1 0.5) 10 1 = 10 0.5 10 = 0.009766;
पी 2 = 45 0.5 2 (1 0.5) 10 2 = 45 0.5 10 = 0.043945;
पी 3 = 120 0.5 3 (1 0.5) 10 3 = 120 0.5 10 = 0.117188;
पी 4 = 210 0.5 4 (1 0.5) 10 4 = 210 0.5 10 = 0.205078;
पी 5 = 252 0.5 5 (1 0.5) 10 5 = 252 0.5 10 = 0.246094;
पी 6 = 210 0.5 6 (1 0.5) 10 6 = 210 0.5 10 = 0.205078;
पी 7 = 120 0.5 7 (1 0.5) 10 7 = 120 0.5 10 = 0.117188;
पी 8 = 45 0.5 8 (1 0.5) 10 8 = 45 0.5 10 = 0.043945;
पी 9 = 10 0.5 9 (1 0.5) 10 9 = 10 0.5 10 = 0.009766;
पी 10 = 1 0.5 10 (1 0.5) 10 10 = 1 0.5 10 = 0.000977
बिल्कुल पी 0 + पी 1 + पी 2 + पी 3 + पी 4 + पी 5 + पी 6 + पी 7 + पी 8 + पी 9 + पी 10 = 1 .
आइए ग्राफ़ पर मात्राएँ प्रदर्शित करें पी 0 , पी 1 , पी 2 , पी 3, , पी 10 (चित्र 27.2 देखें)।
p = 0.5 और n = 10, इसे सामान्य नियम के करीब लाते हैं
तो, शर्तों के तहत एम ≈ एन/2 और पी≈ 1 पीया पी≈ 0.5 द्विपद वितरण के बजाय, आप सामान्य वितरण का उपयोग कर सकते हैं। बड़े मूल्यों के लिए एनजैसे-जैसे गणितीय अपेक्षा और भिन्नता बढ़ती है, ग्राफ़ दाईं ओर शिफ्ट हो जाता है और अधिक से अधिक सपाट हो जाता है एन : एम = एन · पी , डी = एन · पी· (1 पी) .
वैसे, द्विपद नियम सामान्य और बढ़ने के साथ बढ़ता है एन, जो केंद्रीय सीमा प्रमेय के अनुसार काफी स्वाभाविक है (व्याख्यान 34 देखें। सांख्यिकीय परिणामों को रिकॉर्ड करना और संसाधित करना)।
अब विचार करें कि किसी मामले में द्विपद नियम कैसे बदलता है पी ≠ क्यू, वह है पी> 0 . इस मामले में, सामान्य वितरण की परिकल्पना लागू नहीं की जा सकती है, और द्विपद वितरण पॉइसन वितरण बन जाता है।
पॉसों वितरण
पॉइसन वितरण है विशेष मामलाद्विपद वितरण (साथ) एन>> 0 और पर पी>0 (दुर्लभ घटनाएँ)).
गणित से एक सूत्र ज्ञात होता है जो आपको द्विपद वितरण के किसी भी सदस्य के मूल्य की लगभग गणना करने की अनुमति देता है:
कहाँ ए = एन · पी पॉइसन पैरामीटर (गणितीय अपेक्षा), और विचरण गणितीय अपेक्षा के बराबर है। आइए हम गणितीय गणनाएँ प्रस्तुत करें जो इस संक्रमण की व्याख्या करती हैं। द्विपद वितरण कानून
पी एम = सी एन एम · पी एम· (1 पी) एन एम
यदि आप डालेंगे तो लिखा जा सकता है पी = ए/एन , जैसा
![]()
क्योंकि पीबहुत छोटा है, तभी संख्याओं को ध्यान में रखा जाना चाहिए एम, की तुलना में छोटा एन. काम
एकता के बहुत करीब. यही बात आकार पर भी लागू होती है
परिमाण
बहुत करीब इ ए. यहाँ से हमें सूत्र मिलता है:
उदाहरण। बॉक्स में शामिल है एन= 100 भाग, उच्च गुणवत्ता वाले और दोषपूर्ण दोनों। दोषपूर्ण उत्पाद प्राप्त होने की संभावना है पी= 0.01 . मान लीजिए कि हम एक उत्पाद निकालते हैं, यह निर्धारित करते हैं कि यह दोषपूर्ण है या नहीं, और इसे वापस रख दें। ऐसा करने पर पता चला कि हमने जिन 100 उत्पादों को देखा, उनमें से दो ख़राब निकले। इसकी सम्भावना क्या है?
द्विपद वितरण से हमें प्राप्त होता है:
पॉइसन वितरण से हमें प्राप्त होता है:
जैसा कि आप देख सकते हैं, मान करीब निकले, इसलिए दुर्लभ घटनाओं के मामले में पॉइसन के नियम को लागू करना काफी स्वीकार्य है, खासकर जब से इसमें कम कम्प्यूटेशनल प्रयास की आवश्यकता होती है।
आइए हम ग्राफ़िक रूप से पॉइसन के नियम का रूप दिखाएं। आइए पैरामीटर को एक उदाहरण के रूप में लें पी = 0.05 , एन= 10 . तब:
सी 10 0 = 1
,
सी 10 1 = 10
,
सी 10 2 = 45
,
सी 10 3 = 120
,
सी 10 4 = 210
,
सी 10 5 = 252
,
सी 10 6 = 210
,
सी 10 7 = 120
,
सी 10 8 = 45
,
सी 10 9 = 10
,
सी 10 10 = 1
;
पी 0 = 1 0.05 0 (1 0.05) 10 0 = 1 1 0.95 10 = 0.5987;
पी 1 = 10 0.05 1 (1 0.05) 10 1 = 10 0.05 1 0.95 9 = 0.3151;
पी 2 = 45 0.05 2 (1 0.05) 10 2 = 45 0.05 2 0.95 8 = 0.0746;
पी 3 = 120 0.05 3 (1 0.05) 10 3 = 120 0.05 3 0.95 7 = 0.0105;
पी 4 = 210 0.05 4 (1 0.05) 10 4 = 210 0.05 4 0.95 6 = 0.00096;
पी 5 = 252 0.05 5 (1 0.05) 10 5 = 252 0.05 5 0.95 5 = 0.00006;
पी 6 = 210 0.05 6 (1 0.05) 10 6 = 210 0.05 6 0.95 4 = 0.0000;
पी 7 = 120 0.05 7 (1 0.05) 10 7 = 120 0.05 7 0.95 3 = 0.0000;
पी 8 = 45 0.05 8 (1 0.05) 10 8 = 45 0.05 8 0.95 2 = 0.0000;
पी 9 = 10 0.05 9 (1 0.05) 10 9 = 10 0.05 9 0.95 1 = 0.0000;
पी 10 = 1 0.05 10 (1 0.05) 10 10 = 1 0.05 10 0.95 0 = 0.0000
बिल्कुल पी 0 + पी 1 + पी 2 + पी 3 + पी 4 + पी 5 + पी 6 + पी 7 + पी 8 + पी 9 + पी 10 = 1 .
पर एन> ∞ केंद्रीय सीमा प्रमेय के अनुसार पॉइसन वितरण एक सामान्य कानून में बदल जाता है (देखें)।







